Concurrency Part 2
Applied parallelism
Patterns for parallel programming

One problem - Three solutions
- We will look at one specific problem solved in three different ways using the three parallel programming patterns
- The problem: Image Convolutions
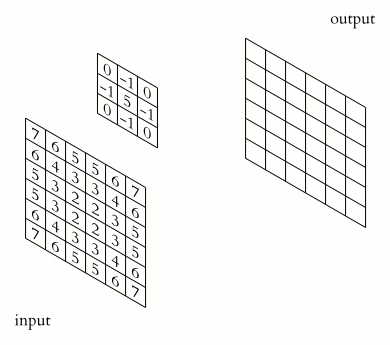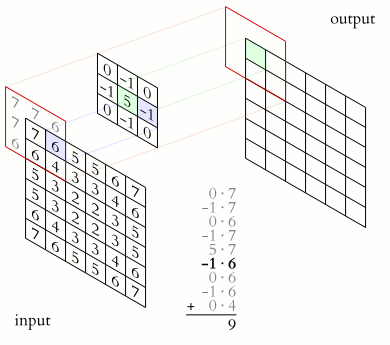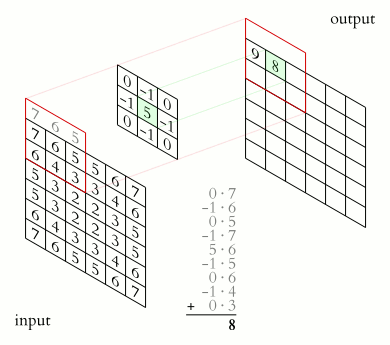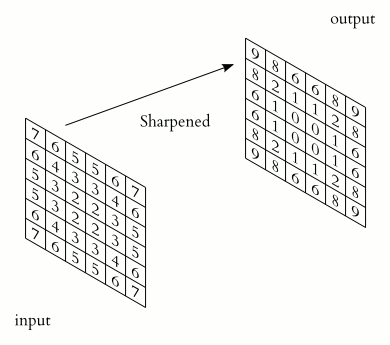
https://en.wikipedia.org/wiki/Kernel_(image_processing)
Convolution Example: Edge Detection

Convolution using Functional Programming

A non-trivial parallelization problem
- Matrix multiplication (a core part of almost all modern ML approaches)
- When done on a GPU, we want high parallelization, i.e. thousands of parallel threads
- We also care for cache locality
- One way: Tiled Matrix Multiplication

https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html
Tiled Matrix Multiplication
- Which parallelisation strategy to use?
- What are good values for
Mtile,Ntile,Ktile? - How would we know?
- We need to measure and will do so in a later lecture, stay tuned ;)
https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html