2.1. Rust as an ahead-of-time compiled language
In this chapter, we will learn about compiled languages and why they are often used for systems programming. We will see that both Rust and C++ are what is known as ahead-of-time compiled languages. We will learn the benefits of ahead-of-time compilation, in particular in terms of program optimization, and also its drawbacks, specifically problems with cross-plattform development and the impact of long compilation times.
Programming languages were invented as a tool for developers to simplify the process of giving instructions to a computer. As such, a programming language can be seen as an abstraction over the actual machine that the code will be executed on. As we have seen in chapter 1.2, programming languages can be classified by their level of abstraction over the underlying hardware. Since ultimately, every program has to be executed on the actual hardware, and the hardware has a fixed set of instructions that it can execute, code written in a programming language has to be translated into hardware instructions at some point prior to execution. This process is known as compilation and the associated tools that perform this translation are called compilers. Any language whose code is executed directly on the underlying hardware is called a compiled languageThe exception to this are assembly languages, which are used to write raw machine instructions. Code in an assembly language is not compiled but rather assembled into an object file which your computer can execute..
At this point, one might wonder if it is possible to execute code on anything else but the underlying hardware of a computer system. To answer this question, it is worth doing a small detour into the domain of theoretical computer science, to gain a better understanding of what code actually is.
Detour - The birth of computer science and the nature of code
In the early 20th century, mathematicians were trying to understand the nature of computation. It had become quite clear that computation was some systematic process with a set of rules whose application enabled humans to solve certain kinds of problems. Basic arithmetic operations, such as addition, subtraction or multiplication, were known to be solvable through applying a set of operations by ancient Babylonian mathematicians. Over time, specific sets of operations for solving several popular problems became known, however it remained unclear whether any possible problem that can be stated mathematically could also be solved through applying a series of well-defined operations. In modern terms, this systematic application of a set of rules is known as an algorithm. The question that vexed early 20th century mathematicians could thus be simplified as:
"For every possible mathematical problem, does there exist an algorithm that solves this problem?"
Finding an answer to this question seems very rewarding. Just imagine for a moment that you were able to show that there exists a systematic set of rules that, when applied, gives you the answer to every possible (mathematical) problem. That does sound very intruiging, does it not?
The main challenge in answering this question was the formalization of what it means to 'solve a mathematical problem', which can be stated as the simple question:
"What is computation?"
In the 1930s, several independent results were published which tried to give an answer to this question. Perhaps the most famous one was given by Alan Turing in 1936 with what is now know as a Turing machine. Turing was able to formalize the process of computation by breaking it down to a series of very simple instructions operating on an abstract machine. A Turing machine can be pictured as an infinitely long tape with a writing head that can manipulate symbols on the tape. The symbols are stored in cells on the tape and the writing head always reads the symbol at the current cell. Based on the current symbol, the writing head writes a specific symbol to the current cell, then moves one step to the left or right. Turing was able to show that this outstandingly simple machine is able to perform any calculation that could be performed by a human on paper or any other arbitrarily complex machine. This statement is now known as the Church-Turing thesis.
So how is this relevant to todays computers, programming languages and systems programming? Turing introduced two important concepts: A set of instructions ("code") to be executed on an abstract machine ("computer"). This definition holds until today, where we refer to code as simply any set of instructions that can be executed on some abstract machine.
It pays off to think about what might constitute such an 'abstract computing machine'. Processors of course come to mind, as they are what we use to run our instructions on. However, humans can also be considered as 'abstract computing machines' in a sense. Whenever we are doing calculations by hand, we apply the same principal of systematic execution of instructions. Indeed, the term computer historically refered to people carrying out computations by hand.
Interpreted languages
Armed with our new knowledge about the history of computers and code, we can now answer our initial question: Is it possible to execute code on anything else but the underlying hardware of a computer system? We already gave the answer in the previous section where we saw that there are many different types of abstract machines that can carry out instructions. From a programmers point of view, there is one category of abstract machine that is worth closer investigation, which is that of emulation.
Consider a C++ program that simulates the rules of a Turing machine. It takes a string of input characters, maybe through the command line, and applies the rules of a Turing machine to this input. This program itself can now be seen as a new abstract machine executing instructions. Instead of executing the rules of a Turing machine on a real physical Turing machine, the rules are executed on the processors of your computer. Your computer thus emulates a Turing machine. Through emulation, computer programs can themselves become abstract machines that can execute instructions. There is a whole category of programming languages that utilize this principle, called interpreted programming languagesWhy interpreted and not emulated? Read on!.
In an interpreted programming language, code is fed to an interpreter, which is a program that parses the code and executes the relevant instructions on the fly. This has some advantages over compiled languages, in particular independence of the underlying hardware and the ability to immediately execute code without waiting on a possibly time-consuming compilation process. At the same time, interpreted languages are often significantly slower than compiled languages because of the overhead of the interpreter and less potential for optimizing the written code ahead of time.
As we have seen, many concepts in computer science are not as binary (pun intended) as they first appear. The concept of interpreted vs. compiled languages is no different: There are interpreted languages which still use a form of compilation to first convert the code into an optimized format for the interpreter, as well as languages which defer the compilation process to the runtime in a process called just-in-time compilation (JIT).
Why ahead-of-time compiled languages are great for systems programming
As one of the main goals of systems programming is to write software that makes efficient use of computer resources, most systems programming is typically done with ahead-of-time compiled languages. There are two reasons for this:
- First, ahead-of-time compiled languages get translated into machine code for specific hardware architectures. This removes any overhead of potential interpretation of code, as the code runs 'close to the metal', i.e. directly on the underlying hardware.
- Second, ahead-of-time compilation enables automatic program optimization through a compiler. Modern compilers are very sophisticated programs that know the innards of various hardware architectures and thus can perform a wide range of optimizations that can make the code substantially faster than what was written by the programmer.
- A third benefit that is related to ahead-of-time compilation is that we can perform correctness checks on the program, more on that in chapter 2.4
This second part - program optimization through the compiler - plays a big role in systems programming. Of course we want our code to be as efficient as possible, however depending on the way we write our code, we might prevent the compiler from applying optimizations that it otherwise could apply. Understanding what typical optimizations are will help us understand how we can write code that is more favorable for the compiler to optimize.
We will now look at how ahead-of-time compilation works in practice, using Rust as an example.
The Rust programming language is an ahead-of-time compiled language built on top of the LLVM compiler project.
The Rust toolchain includes a compiler, rustc, which converts Rust code into machine code, similar to how compilers such as gcc, clang or MSVC convert C and C++ code into machine code. While the study of the Rust compiler (and compilers in general) is beyond the scope of this course, it pays off to get a basic understanding of the process of compiling Rust code into an executable programWe will use the term executable code to refer to any code that can be run on an abstract machine without further preprocessing. The other usage of the term executable is for an executable file and to distinguish it from a library, which is a file that contains executable code, but can't be executed on its own..
When you install Rust, you will get access to cargo, the build system and package manager for Rust. Most of our interaction with the Rust toolchain will be through cargo, which acts as an overseer for many of the other tools in the Rust ecosystem. Most importantly for now, cargo controls the Rust compiler, rustc. You can of course invoke rustc yourself, generally though we will resort to calls such as cargo build for invoking the compiler. Suppose you have written some rust code in a file called hello.rs (.rs is the extension for files containing Rust code) and you run rustc on this file to convert it into an executable. The following image gives an overview of the process of compiling your source file hello.rs into an executable:
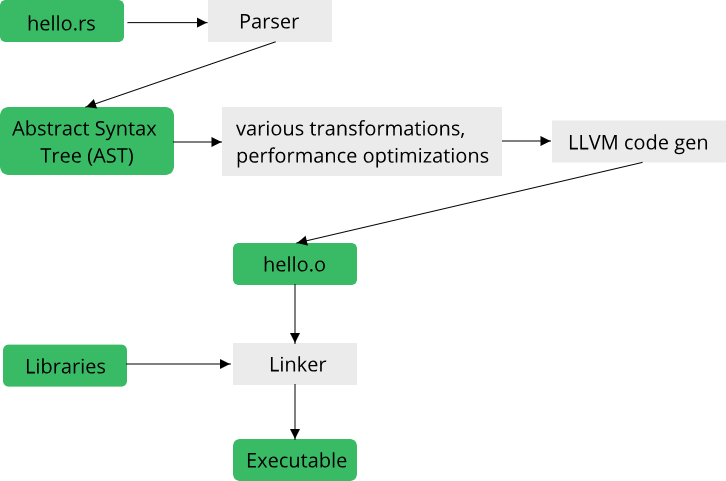
Your code in its textual representation is first parsed and converted into an abstract syntax tree (AST). This is essentially a data structure that the represents your program in a way that the compiler can easily work with. From there, a bunch of transformations and optimizations are applied to the code, which is then ultimately fed into the LLVM code generator, which is responsible for converting your code into something that your CPU understands. The output of this stage are called object files, as indicated by the .o file extension (or .obj on Windows). Your code might reference other code written by other people, in the form of libraries. Combining your code with the libraries into an executable is the job of the linker.
The Rust compiler (and most other compilers that you will find in the wild) has three main tasks:
-
- It enforces the rules of the programming language. This checks that your code adheres to the syntax and semantics of the programing language
-
- It converts the programming language constructs and syntax into a series of instructions that your CPU can execute (called machine code)
-
- It performs optimizations on the source code to make your program run faster
The only mandatory stage for any compiler is stage 2, the conversion of source code into executable instructions. Stage 1 tends to follow as a direct consequence of the task of stage 2: In order to know how to convert source code into executable instructions, every programming language has to define some syntax (things like if, for, while etc.) which dictates the rules of this conversion. In that regard, programming language syntax is nothing more than a list of rules that define which piece of source code maps to which type of runtime behaviour (loops, conditionals, call statements etc.). In applying these rules, compilers implicitly enforce the rules of the programming language, thus implementing stage 1.
The last stage - program optimization - is not necessary, however it has become clear that this is a stage which, if implemented, makes the compiler immensely more powerful. Recall what we have learned about abstractions in chapter 1: Abstraction is information-hiding. A programming language is an abstraction for computation, an abstraction which might be missing some crucial information that would improve performance. Because compilers can optimize our written code, we can thus gain back some information (albeit only indirectly) that was lost in the abstraction. In practice this means we can write code at a fairly high level of abstraction and can count on the compiler to fill in the missing information to make our code run efficiently on the target hardware. While this process is far from perfect, we will see that it can lead to substantial performance improvements in many situations.
Compiler Explorer: A handy tool to understand compiler optimizations
When studying systems programming, it can sometimes be helpful to understand just what exactly the compiler did to your source code. While it is possible to get your compiler to output annotated assembly code (which shows the machine-level instructions that your code was converted into), doing this by hand can become quite tedious, especially in a bigger project where you might only be interested in just a single function. Luckily, there exists a tremendously helpful tool called Compiler Explorer which we will use throughout this course. Compiler Explorer is a web-application that lets you input code in one of several programming languages (including C++ and Rust) and immediately shows you the corresponding compiler output for that code. It effectively automates the process of calling the compiler with the right arguments by hand and instead gives us a nice user interface to work with. Here is what Compiler Explorer looks like:
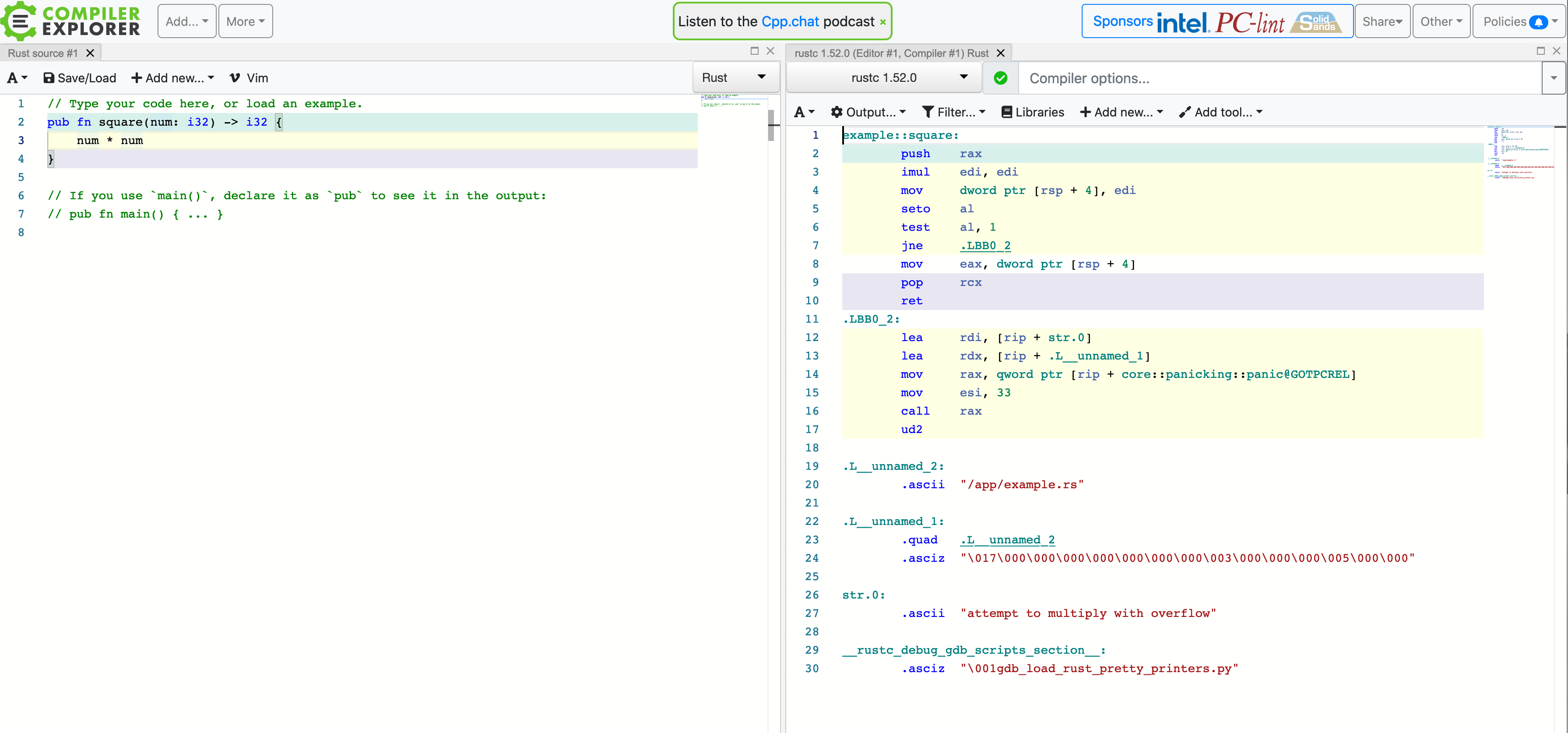
On the left you input your code, choose the appropriate programming language and on the right you will find the compiler output for that piece of code. You can select which compiler to use, and provide arguments to the compiler. Here is an example of the same piece of code, compiled with the compiler argument -O, which tells the compiler to optimize the code:

Notice how much less code there is once the compiler applied its optimizations! We will use Compiler Explorer whenever we want to understand how the compiler acts on our code.
The dark side of compilers
While compilers are these quasi-magical tools that take our code and convert it into an efficient machine-level representation, there are also downsides to using ahead-of-time compiled languages. Perhaps the largest downside is the time that it takes to compile code. All these transformations and optimizations that a compiler performs can be quite complex. A compiler is nothing more than a program itself, so it is bound by the same rules as any program, namely: Complex processes take time. For sophisticated programming languages, such as Rust or C++, compiling even moderately-sized projects can take minutes, with some of the largest projects taking hours to compile. Compared to interpreted languages such as Python or JavaScript, where code can be run almost instantaneuously, this difference in time for a single "write-code-then-run-it" iteration is what caused the notion of compiled languages being 'less productive' than interpreted languages.
Looking at Rust, fast compilation times are not one of its strong sides, unfortunately. You will find plenty of criticism for Rust due to its sometimes very poor compile times, as well as lots of tips on how to reduce compile times.
At the same time, most of the criticism deals with the speed of "clean builds", that is compiling all code from scratch. Most compilers support what is know as incremental builds, where only those files which have changed since the last compilation are recompiled. In practice, this makes working with ahead-of-time compiled languages quite fast. Nonetheless, it is worth keeping compilation times in mind and, when necessary, adapt your code once things get out of hand.
Recap
In this section, we learned about the difference between compiled languages and interpreted languages. Based on a historical example, the Turing machine, we learned about the concept of abstract machines which can execute code. We saw that for systems programming, it is benefitial to have an abstract machine that matches the underlying hardware closely, to get fine-grained control over the hardware and to achieve good performance. We learned about compilers, which are tools that translate source code from one language into executable code for an abstract machine, and looked at one specific compiler, rustc, for the Rust programming language. Lastly, we learned that the process of compiling code can quite slow due to the various transformations and optimizations that a compiler might apply to source code.
In the next chapter, we will look more closely at the Rust programming language and learn about its major features. Here, we will learn the concept of language paradigms.