The Heap
The heap refers to a memory region from which programs can obtain variable-sized memory regions dynamically. We call this process dynamic memory allocation or dynamic allocation for short. Dynamic in this context refers to two things: First, the lifetime of the acquired memory region is dynamic in that it does not depend on any programing-language construct (such as scopes), but instead depends purely on the programmer. Second, the size of the memory region can be specified fully at runtime and thus is also dynamic.
Before we look at how to use the heap, here is an example that illustrates why working with only the stack can get very difficult.
Heap motivation: Dynamically-sized memory
Suppose you were to write a program in C++ or Rust that prompts the user to input any number of integers and, once the user has finished, outputs all the strings in lasecnding order. One option would be to first ask the user how many integers they want to input, then prompt for input this many times, storing them in an array on the stack and sorting this array. Here is how we would write such a program in C++:
#include <iostream>
#include <algorithm>
int main() {
std::cout << "How many integers do you want to input?\n";
int count;
std::cin >> count;
std::cout << "Please enter " << count << " strings:\n";
int numbers[count];
for(int idx = 0; idx < count; ++idx) {
std::cin >> numbers[idx];
}
std::sort(numbers, numbers + count);
for(auto num : numbers) {
std::cout << num << std::endl;
}
return 0;
}
The interesting part is this line right here:
int numbers[count];
With this line, we allocate a dynamic amount of memory on the stack, which has the size count * sizeof(int). Depending on your compiler, this example might or might not compile. The problem here is that we are trying to create an array on the stack with a size that is not a constant expression, which effectively means the size is not known at compile-time. The GCC compiler provides an extension that makes it possible to use some non-constant value for the array size, the MSVC compiler does not support this. The Rust programming language also does not allow non-constant expressions for the array size.
What could we do in this case? Do we have to resort to writing assembly code to manipulate the stack ourselves? After all, if we examine the assembly code that GCC generates for our example, we will find an instruction that manipulates the stack pointer manually:
sub rsp, rax ; rax contains the dynamic size of our array
On a Linux system, there is a corresponding function, called alloca for allocating a dynamic amount of memory on the stack:
int* numbers = static_cast<int*>(alloca(count * sizeof(int)));
This memory is automatically freed once we exit the function that called alloca, so that sounds like a good candidate?! The problem with alloca (besides being an OS-specific function which might not be available on non-Linux systems) is that it is very unsafe. The stack is very limited in its size, and calling alloca with more requested memory than there is available on the stack is undefined behaviour, which is to say: Anything can happen in your program, good or bad. For this reason, programmers are discouraged from relying on alloca too much. Even disregarding the safety aspect, alloca has the same lifetime problem that local variables have, namely that they get freed automatically once a certain scope is exited. If we want to move the piece of code that allocates memory for our numbers into a separate function, we can't use alloca anymore.
What we really want is a way to safely obtain a region of memory with an arbitrary size, and fully decide on when and where we release this memory again. This is why the heap exists!
Using the heap
So how do we as programmers make use of the heap? From an operating system perspective, the heap is just one large memory region associated with a process. On Linux, the heap starts at a specific address based on the size of code and the amount of global variables of the current process, and extends upwards to a specific address called the program break. All memory between these two addresses is freely accessible by the process, and the operating system does not care how the process uses it. If the process needs more memory, the program break can be moved to a higher address using the brk and sbrk functions. brk moves the program break to the given address, sbrk increments the program break by the given number of bytes. With this, we get truly dynamic memory allocation:
int* numbers = static_cast<int*>(sbrk(count * sizeof(int)));
Technically, we never have to free this memory manually, because when the process terminates, the address space of the process is destroyed, effectively releasing all memory.
Now, is this the end of the story? sbrk and be done with it? Clearly it is not, depending on your background, you might never have heard of the sbrk function before. Maybe you are used to the new and delete keywords in C++, or the malloc and free functions in C. What's up with those?
To understand this situation, we have to move beyond our simple example with just one dynamic memory allocation, and onto a more realistic example: Dynamically sized arrays!
Using the heap - For real!
What is a dynamically sized array? You might know it as std::vector from C++. It is a contiguous sequence of elements which can grow dynamically. Possibly one of the first datastructures you learned of when starting out programming is the array, a sequence of elements with a fixed size. int arr[42]; Easy. The obivous next question then is: 'What if I want to store more than 42 elements?'. Sure, you can do int arr[43]; and so on, but as we have seen in our previous number-example, there are situations where you do not know upfront how many elements you need. This is where std::vector and its likes in other programming languages (Vec in Rust, ArrayList in Java, list in Python) come in. In Programming 101 you might accept these datastructures as some magical built-in features of the language, but let's try to peek under the hood and see if we can implement something like std::vector ourselves!
The central question of a growable array is: How do we grow the memory region that holds our elements? If we only ever had one single instance of our growable array, we could use sbrk, which does the growing for us. As soon as we have multiple growable arrays with different elements, we can't do this anymore, because growing one array might overwrite the memory of another array:
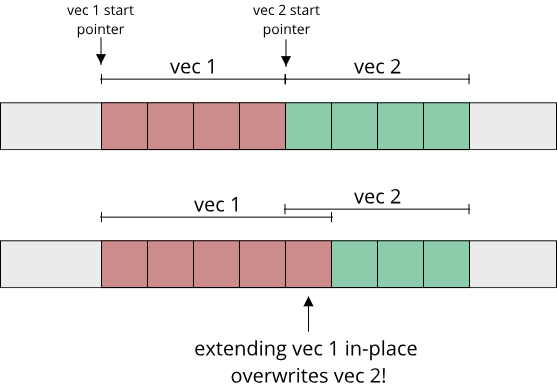
A fundamental property of an array is that all its elements are stored in a contiguous memory region, meaning right next to each other. So we can't say: 'The first N elements are stored at this memory location, the next M elements at this other memory location etc.' Well, we can do that, but this datastructure is not an array anymore but a linked list. So what is left? Try to think on this question for a moment:
Question: How can we grow contiguous memory in a linear address space?
The only viable solution is to allocate a second, larger contiguous memory block and copying all elements from the old memory block to the new memory block. This is exactly what std::vector does. You might think that this is slow, copying all these elements around, and it can be, which is why a good std::vector implementation will grow its memory not by one element at a time (requiring this copy process whenever an element is added), but by multiple elements at a time. You start out with an empty vector that has no memory and when the first element gets added to the vector, instead of allocating just enough memory for one element, you allocate enough for a bunch of elements, for example 4. Then once the fifth element gets added, you don't allocate a new memory block for 5 elements, but for twice as many elements as before, 8 in this case. You can keep doubling the amount of allocated memory in this way, which turns out to be a pretty good strategy to prevent the copying process as much as possible.
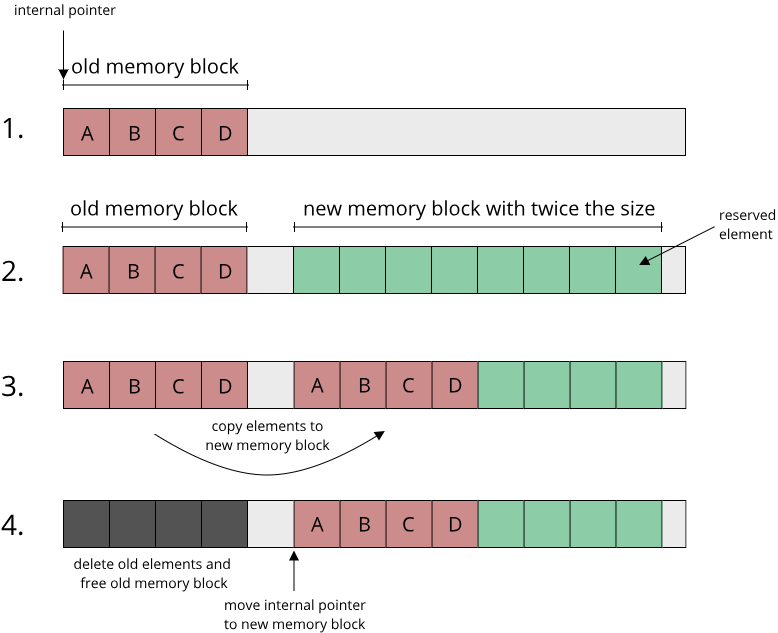
Now we spoke all this time of 'allocating a new memory block'. How exactly does that work though? If there are multiple instances of our growable array in memory, we need some way to keep track of which regions in memory are occupied, and which regions are still free to use.
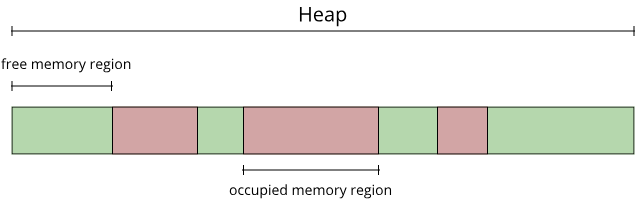
The operating system does not help us here, as we saw it only cares about how large the whole heap section is. This is where malloc and free come in, or in C++ new and delete. malloc and free are functions of the C standard library, and they deal with exactly this problem: Figuring out which regions of the heap are currently in use by our program, and which regions are free. How they do this does not really matter at this point (though we will look at ways for managing this allocated/free section in chapter 3.5), for now all we care about is that by calling malloc, we will get a pointer to a memory region somewhere in the heap that we can use in our program for as long as we like. If we are done using it, we call free to notify the C standard library that this memory region is free to use again. It can then be returned from another call to malloc in the future.
Before looking at this in action, make sure you understand why exactly we have to keep track of allocated and free memory regions! After all, on the stack we didn't really have to do this, our memory just grew and shrank in a linear fashion. The reason heap management is more complicated is that in reality, memory allocation is not always linear. It is not, because not all memory regions have the same lifetime. On the stack, all variables and functions have a hierarchical lifetime, which is to say that for two functions a() and b(), if a() calls b(), the lifetime of b() (and all its associated local variables) is strictly less than the lifetime of a(). This means that memory for all variables in b() is allocated after memory for the variables of a(), and it is released again before the memory for the variables of a() is released! The lifetime of a variable therefore is the time for which the memory of that variable is currently allocated.
In reality, you often have data in your code that gets created within one function, but is used well after the function has been exited, leading to lifetimes that are not hierarchical anymore. This happens as soon as we start to structure our code, moving different functionalities into different functions, namespaces, classes etc. Putting a bit of structure into our number-example already shows this:
#include <iostream>
#include <algorithm>
int* get_user_numbers(int count) {
// The lifetime of 'numbers' is LONGER than the lifetime implied by 'get_user_numbers'!
int* numbers = static_cast<int*>(malloc(count * sizeof(int)));
for(int idx = 0; idx < count; ++idx) {
std::cin >> numbers[idx];
}
return numbers;
}
void sort_and_print(int* numbers, int count) {
std::sort(numbers, numbers + count);
for(int idx = 0; idx < count; ++idx) {
std::cout << numbers[idx] << std::endl;
}
}
int main() {
std::cout << "How many integers do you want to input?\n";
int count;
std::cin >> count;
std::cout << "Please enter " << count << " strings:\n";
int* numbers = get_user_numbers(count);
sort_and_print(numbers, count);
free(numbers);
return 0;
}
This example already shows the usage of malloc and free to manage dynamic memory.
This fine-grained control over the lifetime of memory is one of the main things that sets a systems programming language apart from other more high-level languages!
In the remainder of this chapter, we will look at ways of getting rid of using malloc and free while still maintaining the capability of using dynamic memory allocation.
Recap
Try to answer the following questions for yourself:
- Where do the stack and the heap live within the address space of a process?
- Why do we have both the stack and the heap?
- Could we exclusively use the heap and have no stack at all?