The address space of a process
Whenever we run a program on a modern operating system, the operating system creates a process that encapsulates this running program. Processes are abstractions over the whole hardware of a computer system, with the operating system overseeing processor and memory usage for the process. In this chapter, we will focus on the memory aspect, the processor aspect will be covered in chapter 7.
Through the concept of virtual memory that we learned about in the previous chapter, the operating system can assign each process a unique range of memory. This is the address space of the process, and in it lives all the data that the code in your process can access. For each process, there are several types of data and corresponding regions within the address space that are defined by the operating system. The following image illustrates the common regions of a process in the Linux operating system: (TODO cite from OS book)
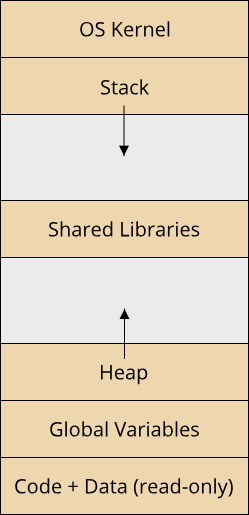
The actual instructions of the process live at the lowest range in the address space, followed by a block containing global variables. After that is a variable-length region called the heap, which grows upwards towards larger addresses. The heap is where we as programmers can obtain memory from to use in our program through a process called dynamic memory allocation. We will see how exactly this works in the next sections. Somewhere in the middle of the address space is a region where code from shared libraries lives. This is code written by other programmers that your program can access, for example the standard library in C. Beyond this section lies a memory region called the stack, which grows from a fixed address down. The stack is important to enable function calls, as it is where local variables reside. Beyond the stack comes the last memory region, which contains the address space of the operating system kernel. Since this region contains critical data and code, user programs are not allowed to read from it or write to it.