Asynchronous programming using async and await
In this last chapter on fearless concurrency using Rust, we will look at a different approach to concurrent programming which is very helpful for writing I/O heavy code, particular network code. The feature that we are going to look at is called async/.await in Rust, and the broader term is asynchronous programming. Note that several of the examples in this chapter are heavily insipired by the Rust async book, which describes the idea behind asynchronous programming in Rust in a lot of detail.
The problem with threads and I/O heavy code
As we saw, threads are a great way to utilize compute resources efficiently. At the same time, launching a thread takes a bit of time, and each thread has a non-trivial amount of state attached to it (for example its own stack). For that reason, having too many active threads at once is not always the best solution, in particular if each thread does little work. This often happens in scenarios that are heavily I/O bound, in particular when we have to wait for a lot of I/O operations to complete. Network programming is the main example for this, as we often have to wait for our sockets to become ready for reading data that has arrived over a network connection. Let's look at an example:
fn handle_connection(mut connection: TcpStream) { ... } fn main() -> Result<()> { let listener = net::TcpListener::bind("127.0.0.1:9753")?; let mut number_of_connections: usize = 0; for connection in listener.incoming() { let connection = connection.context("Error while accepting TCP connection")?; number_of_connections += 1; println!("Open connections: {}", number_of_connections); // Move connection onto its own thread to be handled there std::thread::spawn(move || { handle_connection(connection); }); } Ok(()) }
This code is pretty similar to the code for our little server application from chapter 6.2, but instead of accepting one connection at a time, we move each connection onto its own thread. This way, our server can deal with lots of connections at once. How many connections? Let's try it out by writing a client application that opens lots of connections to this server (since we probably don't have thousands of machines at hand to test a real situation):
fn main() -> Result<()> { // Open as many connections as possible to the remote host let connections = (0..) .map(|_| TcpStream::connect("127.0.0.1:9753")) .collect::<Result<Vec<_>, _>>()?; // Wait for input, then terminate all connections let _ = std::io::stdin().read(&mut [0u8]).unwrap(); Ok(()) }
If we run the two programs on a 2019 MacBook Pro, this might be an example output of the server application:
...
Open connections: 8188
Open connections: 8189
Open connections: 8190
Open connections: 8191
Open connections: 8192
thread 'main' panicked at 'failed to spawn thread: Os { code: 35, kind: WouldBlock, message: "Resource temporarily unavailable" }', /rustc/0b6f079e4987ded15c13a15b734e7cfb8176839f/library/std/src/thread/mod.rs:624:29
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
So about 8192 simultaneous connections, which seems to be limited by the number of threads that we can create. 8192 seems like a suspicious number (it is a power-of-two after all), and indeed this is the limit of threads for a single process on this machine, as sysctl kern.num_taskthreads tells us:
kern.num_taskthreads: 8192
Whether or not it makes sense to have 10'000 or more open TCP connections for a single process can be debated, it is clear however that we want to utilize our system resources efficiently if we want to write the highest performing software that we can. Within the modern web, handling lots of concurrent connections is very important, so we really would like to have efficient ways of dealing with many connections at once.
So let's take a step back and look at what a network connection actually does. The TcpStream type in the Rust standard library is simply a wrapper around the low-level sockets API of the operating system. In its simplest form, calling read on a TcpStream on a Linux system would result in the recv system call. Part of this system call is its ability to block until data becomes available. Indeed, the documentation of recv states: If no messages are available at the socket, the receive calls wait for a message to arrive [...]. This is why we used one thread per connection: Since reading data from a connection can block the current thread, having one thread per connection ensures that no two connections are blocking each other. If we read further in the documentation of recv, we stumble upon an interesting fact: [...] the receive calls wait for a message to arrive, **unless the socket is nonblocking** [...] The select(2) or poll(2) call may be used to determine when more data arrives. So there are also non-blocking sockets! Let's try to understand how they work.
Non-blocking sockets and I/O multiplexing
The documentation of recv stated that a socket might be non-blocking, in which case calling recv on that socket might result in an error if the socket does not have data available. Which means that we have to make sure that we only call recv when we know that there is data to read from the socket. The POSIX manual even gives us a hint how we can achieve that: Using the select or poll system calls. So suppose we have our socket s and want to read data from it. Instead of calling recv, we set the socket to non-blocking upon initialization, then we call poll with s and once poll returns we know that there is data available on the socket so we can call recvThe reality is a bit more complicated since there are different types of events that can occur on a socket. The event we might be interested in is called POLLIN in POSIX..
But how does this help us? Instead of blocking on recv, we now block on poll, which doesn't seem like much of an improvement. Here comes the interesting part. Take a look at the signature of poll:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
poll actually takes an array of file descriptors to listen on, and will return once an event occured on any of these file descriptors! This means that we can open 10 sockets, set them all to non-blocking and then repeatedly call poll in a loop on all 10 socket file descriptors. Whenever poll returns, it sets a flag in the pollfd structure for each file descriptor that registered an event, so that we can figure out which sockets are ready to read. Then, we can call recv on the corresponding sockets. Now, we can handle multiple connections on a single thread without any two connections interfering with each other! This is called I/O multiplexing and is our first step towards asynchronous programming!
Non-blocking I/O using the mio library
In order to rewrite our connection benchmark from before using I/O multiplexing, we need access to the low-level system calls like poll. Since they are operating-system-specific, we will use a Rust library called mio which gives us access to I/O event polling on all platforms. mio exposes a Poll type to which we can register event sources such as mios TcpListener and TcpStream types, which are special non-blocking variants of the types in std::net. With this we can write a single-threaded server that can accept lots of connections:
fn main() -> Result<()> { let mut poll = mio::Poll::new().expect("Could not create mio::Poll"); let mut events = mio::Events::with_capacity(1024); let mut connections = HashMap::new(); let mut listener = mio::net::TcpListener::bind("127.0.0.1:9753".parse().unwrap())?; const SERVER_TOKEN: mio::Token = mio::Token(0); poll.registry() .register(&mut listener, SERVER_TOKEN, mio::Interest::READABLE)?; loop { poll.poll(&mut events, None)?; for event in events.iter() { match event.token() { SERVER_TOKEN => { handle_incoming_connections(&mut listener, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; } } }
At the heart of asynchronous I/O lies the event loop, which in our case calls poll on the mio::Poll type. This is basically the Rust version of the POSIX system call poll: It waits until one or more events have occurred on any of the registered event sources. To start out, we only register one event source: The TcpListener. We also specify which events we are interested in, which in our case is just mio::Interest::READABLE, meaning we want to be able to read from the TcpListener. Since the Poll type can wait on multiple event sources at once, we need a way to identify the event sources, for which the Token type is used for. It is simply a wrapper around a usize value. Within our event loop, once poll returns, we can iterate over all events that occurred using the Event type. Each event has the associated Token for its source, which we can use to identify whether our TcpListener or some other event source triggered the event. If the TcpListener is ready, we can immediately accept incoming connections, as the handle_incoming_connections function shows:
#![allow(unused)] fn main() { fn handle_incoming_connections( listener: &mut TcpListener, connections: &mut HashMap<Token, TcpStream>, poll: &mut Poll, ) -> Result<()> { loop { match listener.accept() { Ok((connection, _)) => { let token = Token(connections.len() + 1); connections.insert(token, connection); let connection = connections.get_mut(&token).unwrap(); poll.registry() .register(connection, token, Interest::READABLE)?; println!("Got {} open connections", connections.len()); } Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(e) => bail!("TcpListener error {}", e), } } Ok(()) } }
It's a bit more complicated as one might think, but not too terrible. We start in a loop and call listener.accept(), because there might be multiple incoming connections ready. Our exit condition for the loop is when accept() returns with an error whose kind() is equal to std::io::ErrorKind::WouldBlock, which signals that we have accepted all connections that were ready. If we have a ready connection, we memorize it in a HashMap and assign it a unique Token, which we then use to register this TcpStream of the connection with the Poll type as well. Now, the next poll call will listen not only for incoming connections on the TcpListener, but also for incoming data on the TcpStreams.
Back in the main function, we have this piece of code here:
#![allow(unused)] fn main() { match event.token() { SERVER_TOKEN => { handle_incoming_connections(&mut listener, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; }
If the event source is not the TcpListener - which is identified by the SERVER_TOKEN - we know that one of our connections is ready to receive data, which we handle using the handle_readable_connection function:
#![allow(unused)] fn main() { fn handle_readable_connection( token: Token, connections: &mut HashMap<Token, TcpStream>, poll: &mut Poll, ) -> Result<()> { let mut connection_closed = false; if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { Ok(0) => { // Connection is closed by remote connection_closed = true; break; } Ok(n) => println!("[{}]: {:?}", connection.peer_addr().unwrap(), &buffer[0..n]), Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Err(e) => bail!("Connection error {}", e), } } } if connection_closed { let mut connection = connections.remove(&token).unwrap(); poll.registry().deregister(&mut connection)?; } Ok(()) } }
This function is pretty complicated, so let's break it down into its main parts:
#![allow(unused)] fn main() { let mut connection_closed = false; if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { //... } } } }
We first try to obtain the associated TcpStream based on the Token of the event. Then, we prepare a buffer to read data and call read in a loop, since we don't know how much data we can read from the connection. read has a couple of possible return values, which are handled like so:
#![allow(unused)] fn main() { Ok(0) => { // Connection is closed by remote connection_closed = true; break; } Ok(n) => println!("[{}]: {:?}", connection.peer_addr().unwrap(), &buffer[0..n]), Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Err(e) => bail!("Connection error {}", e), }
By definition, if read returns Ok(0) this indicates that the connection has been closed by the remote peer. Since we still hold a borrow to the TcpStream, we can't remove it from the HashMap immediately and have to instead set a flag to clean up the connection later. When Ok(n) is returned with a non-zero n, we just print the data to the standard output. Then, there are three error cases:
- If the error kind is
std::io::ErrorKind::WouldBlock, we have read all the data and can exit the loop, similar to what we did with theTcpListener - If the error kind is
std::io::ErrorKind::Interrupted, it means thereadoperation was interrupted and we just have to try again in the next loop iteration - In all other cases, we treat the error as a critical error and exit the function with the error message
What remains is the closing of a connection from the server-side:
#![allow(unused)] fn main() { if connection_closed { let mut connection = connections.remove(&token).unwrap(); poll.registry().deregister(&mut connection)?; } }
This is as simple as removing the connection from the HashMap and calling deregister on the Poll object.
Putting it all together, we can run this program as our new server with just a single thread and see how many connections we can handle:
...
Got 10485 open connections
Got 10486 open connections
Got 10487 open connections
Error: TcpListener error Too many open files (os error 24)
A little more than before, but now we hit a different operating system limit: Too many open files (os error 24). On the machine that this program was run on, ulimit -n gives 10496, which is the maximum number of open file descriptors for the current user. So a bit more than with out thread-based example, but still not orders of magnitude more. The good news is that we are able to handle more connections than before from just a single thread. The memory usage of the poll-based implementation is also much betterThe amount of residual memory, which is the memory that is actively paged in and in use by the program, is not vastly different between the two solution (about 1MB for the single-threaded solution vs. 8.8MB for the multithreaded solution), but the amount of virtual memory that is allocated is very different! Since each thread needs its own stack space, which on the test machine is 8MiB large, the program allocates 8MiB of virtual memory per thread, for a total of about 64GiB of virtual memory!. The downside is that the code is significantly more complex than what we had in the thread-based implementation.
Besides the pure numbers, the poll-based implementation actually does something remarkable: It runs multiple separate logical flows within a single thread! Notice how each connection encapsulates its own logical flow and is disjoint from all other connections? This is what the term multiplexing actually means: Running multiple signals (our I/O operations on the network connections) over a single shared resource (a single thread). In computer-science terms, we realized concurrent programming using a single thread. We could of course extend our implementation to use multiple threads on top of poll, to make it even more efficient. Still, the fact that we effectively have interwoven multiple logical flows into a single-threaded application is pretty neat!
The road towards asynchronous programming
Where do we go from here? Clearly, the ergonomics of using poll leave a lot to be desired, so maybe we can find a good abstraction for it? Without spoiling too much: Our aim is to 'invent' what is know as asynchronous programming, which Rust has as a core language feature.
The term asynchronous means that we can have multiple concurrent logical flows in the context of one or a handful of threads. We saw that we could achieve this for network connections using poll: Multiple connections were open concurrently, we could even read from them, all from a single thread. As a consequence, we lost the order of operations in our code. What do we mean by that? Suppose we have 4 connections A, B, C, and D. In a synchronous program, we always have an established order in which we read from these connections, for example ABCD. In an asynchronous program, we don't know in which order we will read from these connections. It could be ABCD, but it could also be any other order, such as DCBA or even ABAACAD.
A fundamental property of asynchronous code is the decoupling of computations from their result. In a synchronous program, these two are tied together: We call a function (computation) and once the function exits we get its result. We call read on a TcpStream and get the bytes from the stream. In an asynchronous program, we request the computation, then do something else and only return to the computation once its result is available! This is exactly what we did with poll: We requested to be notified when data is ready to be read from a network connection, but instead of waiting on that specific connection, we might read from another connection that is ready, accept a new connection or do anything else, before finally returning to this specific network connection and reading the data.
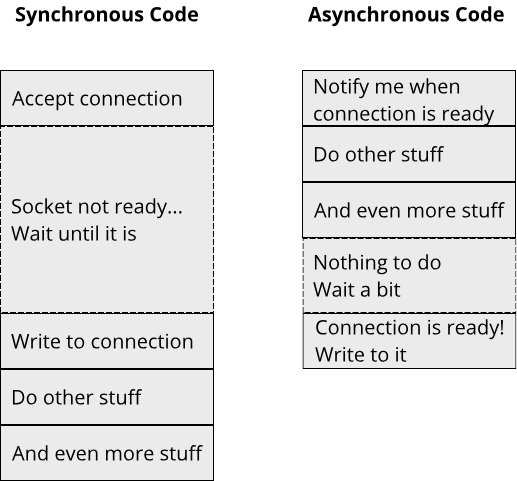
Making our poll based server easier to use
The first step on our journey towards asynchronous programming is to make our previous server code easier to use. We saw that we could use the mio library and handle multiple concurrent connections using the Poll type, but the code itself was pretty complex. The main problem is that the actual reading of data from a TcpStream is now tightly coupled with the event loop. Recall this code:
#![allow(unused)] fn main() { if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { // ... } } } }
If we want to do something with the data that was read, we have to insert this new code right here after the end of this loop, deep within the event loop code. It would be great if we could register a callback function that gets called from this code with the &[u8] buffer containing all read data. Callbacks are a good tool for making asynchronous code possible, because the code within the callback might be called at some later point, but we can write it very close to where we initiate the asynchronous computation.
So let's write a Connection type that provides an asynchronous read method:
#![allow(unused)] fn main() { type OnReadCallback = fn(&[u8]) -> (); /// Wraps a TCP connection and gives it async functions (with callbacks) struct Connection { stream: TcpStream, callbacks: Vec<OnReadCallback>, } impl Connection { pub fn new(stream: TcpStream) -> Self { Self { stream, callbacks: vec![], } } pub fn read_sync(&mut self, buffer: &mut [u8]) -> std::io::Result<usize> { self.stream.read(buffer) } pub fn read_async(&mut self, on_read: OnReadCallback) { self.callbacks.push(on_read); } fn notify_read(&mut self, data: &[u8]) { for callback in self.callbacks.drain(..) { callback(data); } } } }
The Connection type wraps a TcpStream as well as a bunch of callbacks. It provides a read_sync method that just delegates to stream.read, and a read_async method that takes in a callback which will be called once the next data has been read from within the event loop. The event loop needs a way to trigger these callbacks, for which we have the notify_read function. With this, we can change our server function handle_readable_connection a bit to use this new Connection type:
#![allow(unused)] fn main() { fn handle_readable_connection( token: Token, connections: &mut HashMap<Token, Connection>, poll: &mut Poll, ) -> Result<()> { // ... if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; let mut bytes_read = 0; loop { match connection.read_sync(&mut buffer[bytes_read..]) { Ok(n) => { bytes_read += n; if bytes_read == buffer.len() { buffer.resize(buffer.len() + 1024, 0); } } // ... } } if bytes_read != 0 { connection.notify_read(&buffer[..bytes_read]); } } // ... } }
Now, we read all the data into a single buffer and then call notify_read on the Connection object with this buffer. Notice that we changed the HashMap to store Connection objects instead of TcpStreams.
We can do the same thing with our TcpListener and wrap it in a Server type:
#![allow(unused)] fn main() { type OnNewConnectionCallback = fn(&mut Connection) -> (); /// Wraps a TCP connection and gives it async functions (with callbacks) struct Server { listener: TcpListener, callbacks: Vec<OnNewConnectionCallback>, } impl Server { // Assume just one server pub const TOKEN: Token = Token(0); pub fn new(listener: TcpListener, poll: &Poll) -> Result<Self> { let mut ret = Self { listener, callbacks: vec![], }; poll.registry() .register(&mut ret.listener, Self::TOKEN, Interest::READABLE)?; Ok(ret) } pub fn accept_sync(&mut self) -> std::io::Result<(TcpStream, SocketAddr)> { self.listener.accept() } pub fn accept_async(&mut self, on_new_connection: OnNewConnectionCallback) { self.callbacks.push(on_new_connection); } fn notify_new_connection(&mut self, connection: &mut Connection) { for callback in self.callbacks.iter() { callback(connection); } } } }
Here, we created two variants of the TcpListener::accept function: accept_sync just delegates to listener.accept, whereas accept_async takes a callback which will be passed the new Connection object once a connection has been established. Just as before, we also add a notify... method that the event loop can call to trigger all callbacks.
With this, we can rewrite our main method:
fn main() -> Result<()> { let mut poll = Poll::new().expect("Could not create mio::Poll"); let mut events = Events::with_capacity(1024); let mut connections = HashMap::new(); let listener = TcpListener::bind("127.0.0.1:9753".parse().unwrap())?; let mut server = Server::new(listener, &poll)?; // ... Awesome code goes here ... loop { poll.poll(&mut events, None)?; for event in events.iter() { match event.token() { Server::TOKEN => { handle_incoming_connections(&mut server, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; } } }
Again, very similar to before, we just wrap the TcpListener in the Server type and pass this to handle_incoming_connections. Now look what we can do with the Server:
#![allow(unused)] fn main() { server.accept_async(|connection| { connection.read_async(|data| { if let Ok(string) = std::str::from_utf8(data) { println!("Got data from remote: {}", string); } else { println!("Got data from remote (binary): {:?}", data); } }); }); }
We can write asynchronous code which looks almost like synchronous code: Accept a new connection, and if it is ready, read data from the connection, and if the data is ready, do something with the data (print to standard output). The only downside is that the code still does not look super nice, due to all the callbacks we get lots of nesting which can be hard to follow. Let's see how we can fix that!
Future - An abstraction for an asynchronous computation
Let's look at this line of code right here: server.accept_async(|connection| { ... }). It's not unreasonable to say that accept_async is a computation that completes at some point in the future. Because we wanted to write asynchronous code, we couldn't write accept_async as a regular function returning a value - we don't want to block to wait for the value after all! But maybe we could return some sort of proxy object that encapsulates a value that becomes available at some point in the future.
Enter Future, a trait that represents an asynchronous computation which yields some value T at some point in the future. The idea of a Future type exists in many languages: C++ has std::future, JavaScript has a Promise type, C# has Task<T>, to name just a few. Some languages explicitly tie futures to threads (C++ does this), while other languages use a poll-based model (both Rust and JavaScript do this). Here is what the Future trait looks line in Rust:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
It is a bit complicated because it uses a bunch of new types, namely Pin<&mut Self> and the Context<'_> type, but for now we don't have to worry about those to understand what futures do in Rust. A Rust Future<T> provides just one method named poll. We can poll a future to ask if it is already finished, in which case it will return Poll::Ready(T). If it is not finished, Poll::Pending will be returned instead. This is similar to the TcpListener (and TcpStream) type of mio: We called listener.accept() until it returned an error that signalled that the listener is not ready to accept another connection. Instead of calling listener.accept() in a loop until it does not return an error anymore, we used the mio::Poll type to get notified when our listener is ready. Rust futures work in the same way, which is what the Context<'_> type is for. If the future is polled but is not ready, a callback is registered with the Context<'_> type which gets invoked once the future is ready to make progress! This is exactly like what we did in the previous example of our server using mio and callbacks!
The Future type by itself doesn't seem very useful at first: It only has a poll method, and it takes a lot of special parameters. It becomes powerful only in conjunction with a bit of Rust syntactic sugar and an executor. We will look at executors shortly, but first let's look at the syntactic sugar that Rust provides, namely the keywords async and .await!
async and .await in Rust
Recall the Server type that we wrote which has a method to accept connections asynchronously. This is how the method looked like:
#![allow(unused)] fn main() { pub fn accept_async(&mut self, on_new_connection: OnNewConnectionCallback) { self.callbacks.push(on_new_connection); } }
We couldn't return anything from accept_async because the return value (a Connection object) might not be available right now but instead at some point in the future. Notice something? Why not use a Future<Output = Connection> as return value for this function? Since Future is just a trait, we have to return some specific type that implements Future<Output = Connection>. We don't know what that type is at the moment, but let's just assume that we had such a type. Then we could rewrite our function to look like this:
#![allow(unused)] fn main() { pub fn accept_async(&mut self) -> impl Future<Output = Connection> { // magic } }
By itself, that still doesn't look like much, but here is where the .await keyword comes into play. We can write code that looks almost like sequential code but runs asynchronously using Future and .await, like so:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; let connection : Connection = server.accept_async().await; }
The type annotation is not strictly necessary, but illustrates that even though accept_async returns a Future, by using .await, we get back the Connection object from within the future. We can build on this and call multiple asynchronous functions in a row:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; let mut connection : Connection = server.accept_async().await; let data : Vec<u8> = connection.read_async().await; }
Notice how powerful this Rust feature is: We are still writing asynchronous code, so neither accept_async nor read_async will block, but it reads just like sequential code. No more callbacks and very little noise besides the .await call. There are a few caveats however that we have to be aware of.
First, .async is only allowed to be called from within an asynchronous function itself. So this right here won't work:
fn main() { // ... let mut server = Server::new(listener, &poll)?; let mut connection : Connection = server.accept_async().await; let data : Vec<u8> = connection.read_async().await; }
How does Rust know whether a function is asynchronous or not? For this, we have to use the second keyword: async. We can declare a function or a local block as async, turning it into an asynchronous function. So this would work:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; async { let mut connection: Connection = server.accept_async().await; let data: Vec<u8> = connection.read_async().await; }; }
As would this:
#![allow(unused)] fn main() { async fn foo(poll: &Poll) { let mut server = Server::new(listener, &poll).unwrap(); let mut connection: Connection = server.accept_async().await; let data: Vec<u8> = connection.read_async().await; } }
The second caveat becomes clear once we take a closer look at the .await calls. Asynchronous code shouldn't block, after all this was why we tried to do things asynchronously in the first place, so calling .await should not block our program. But we get a result back from our function when we call .await. How does that work, and where did the waiting go?
async and .await together create a state machine under the hood that represents the different stages in which our asynchronous computation can be in. Where previously we used a callback that gets invoked at some point in the future, .await goes the other way around and yields control back to whoever is responsible for managing our asynchronous code. In our callback-based code, we had an event loop that managed all asynchronous computations and called the respective callbacks whenever ready:
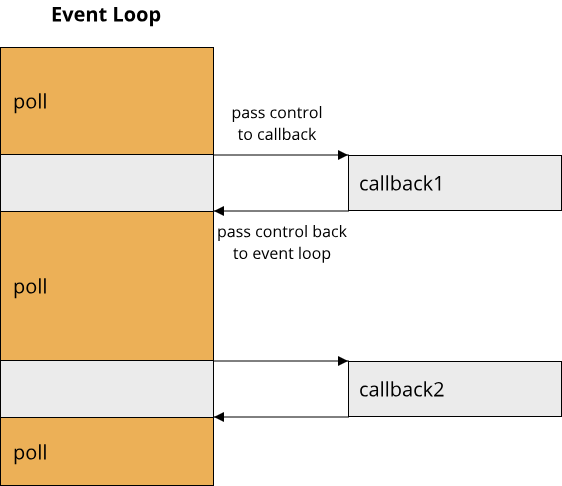
So our overall code was still sequential, we just split it up into the event loop and the various callback-based asynchronous functions. With async and .await, the picture is similar. There has to be a piece of code that drives the asynchronous code (by polling futures), and we call this piece of code the executor of our asynchronous code. This executor runs the code of our async block as far as possible, and whenever an .await statement is reached that is not ready, control is handed back to the executor, which will then continue with some other async block. So for our async-based server code, execution might look like this:
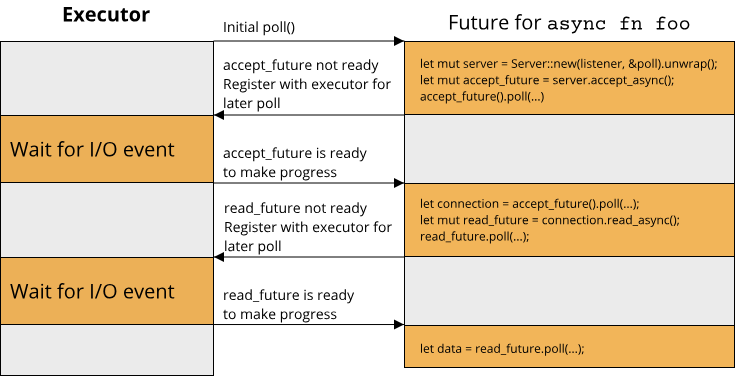
Notice that the code within the async function is made up of multiple Futures: accept_async returns a Future, as does read_async. The whole async function itself also returns a Future. So the .await statements are effectively points at which the execution of our function can halt for it to be resumed at some later point. It's like we had three separate, consecutive functions that read like a single function. This is why async creates a state machine, so that one Future that is 'made up' of other Futures can keep track of where it currently is within its strand of execution.
The whole point of asynchronous code is that we can effectively do multiple things at once. If we only have a single async function that gets executed, this function behaves very similar to the synchronous, blocking version. Only once we have multiple async functions executing at once do we see the benefits of asynchronous code:
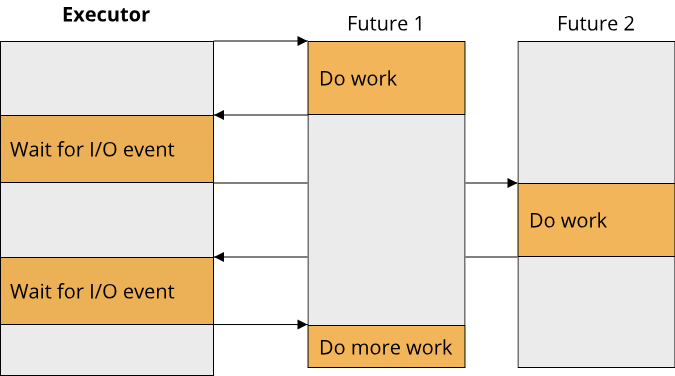
For the sake of completeness, here is how a Future for accepting connections from our Server type might be implemented:
#![allow(unused)] fn main() { struct ServerAccept<'a> { server: &'a mut Server, } impl<'a> Future for ServerAccept<'a> { type Output = Connection; fn poll( mut self: std::pin::Pin<&mut Self>, cx: &mut std::task::Context<'_>, ) -> std::task::Poll<Self::Output> { match self.server.accept_sync() { Ok((stream, _)) => { std::task::Poll::Ready(Connection::new(stream, self.server.executor.clone())) } Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => { // Register callback to get notified if this specific listener is ready to accept another connection let waker = cx.waker().clone(); let executor = self.server.executor.clone(); let token = self.server.token; executor.register_io_event(token, &mut self.as_mut().server.listener, waker); std::task::Poll::Pending } Err(e) => panic!("Error while accepting connection: {}", e), } } } }
Without knowing what exactly the executor does, it is a bit harder to understand, but we will get to executors in the next section. The main point to take away from this piece of code is that within poll, it simply calls the synchronous accept_sync function! Since we are using the mio TcpListener type, this will return an error if it would have to block for data. We can use this error to figure out when the Future is not ready to make progress, and in this case register the Future itself with the executor to continue execution once a certain event has been registered by the executor. Once the executor registers the event in question - in this case that the TcpListener of the Server is ready to read from - it will poll the Future again. Access to the Future is given to the executor through the waker object. So let's look at how an executor might work then!
Executors for asynchronous code
The only missing piece in order to understand asynchronous code in Rust are the executors. An executor is responsible for polling Futures. Remember, by calling poll we make sure that a Future either makes progress or schedules itself to be polled again once it is ready to make progress. Each executor thus has to provide an interface through which asynchronous functions can be registered with it. This way the executor knows which Futures it must poll.
Here is a very simple executor called block_on:
#![allow(unused)] fn main() { use futures::pin_mut; fn block_on<T, F: Future<Output = T>>(f: F) -> T { pin_mut!(f); let mut context = ...; loop { if let Poll::Ready(result) = f.as_mut().poll(&mut context) { return result; } } } }
block_on always executes exactly one asynchronous function and simply blocks the current thread until the function has completed. The asynchronous function is represented by a single value that implements Future, and block_on calls poll on this Future in a loop until Poll::Ready is returned. Since poll has this weird signature that accepts not a &mut self but instead a Pin<&mut Self>, we have to create an appropriate Pin instance from our Future. For this, we can use the pin_mut! macro from the futures crate. We also need a Context to pass to poll. Context itself just acts as wrapper around a Waker object. Waker is the object that provides the wake method, which has to be called by the executor once the Future is ready to make progress. There are many different ways to implement the Waker type, for simplicity we will use the WakerRef type, also from the futures crate. WakerRef introduces another layer of indirection because it wraps a value of type &Arc<W> where W: ArcWake. ArcWake itself is a trait that has a single method wake_by_ref which implements the logic of what happens with a Future if it is waked by its associated Waker.
Quite complicated, so let's work through a bunch of examples. Our block_on executor as it is now has no notion of waking any Futures, because it just calls poll in a busy-loop. We really don't need any Waker behaviour, so let's implement a NoOpWaker:
#![allow(unused)] fn main() { struct NoOpWaker; impl ArcWake for NoOpWaker { fn wake_by_ref(_arc_self: &std::sync::Arc<Self>) {} } }
With this, we can create a Context like so:
#![allow(unused)] fn main() { let noop_waker = Arc::new(NoOpWaker); let waker = waker_ref(&noop_waker); let mut context = Context::from_waker(&waker); }
With block_on, we can already execute async functions and blocks:
fn main() { let connection = block_on(async { let listener = TcpListener::bind("127.0.0.1:9753".parse().unwrap()) .expect("Could not bind TcpListener"); let mut server = Server::new(listener); server.accept_async().await }); println!("Got connection to {}", connection.peer_addr().unwrap()); }
As it stands now, block_on is not great. Compared to simply calling server.accept_sync(), block_on consumes much more CPU resources because it is running a busy-loop. We also don't use the waking functionality that is one of the key parts of Futures in Rust. Because we don't use waiting, we have to busy-loop and call poll constantly - we just have no other way of knowing when our Future might be ready to make progress. For our accept_async function, we would have to implement an executor that uses the mio::Poll type, but instead of doing something so complicated, let's look at a simpler Future that can actually use the waking functionality quite easily: A Timer!
For our purposes, a Timer is a piece of code that calls another piece of code after a given number of seconds have elapsed. When using async code, we don't have to memorize what code we want to call because we can model the Timer as a single Future that completes when the given number of seconds have elapsed. If we .await this Future, any code after the .await will be called once the Timer has finished. So our Timer is a type that implements Future:
#![allow(unused)] fn main() { struct Timer {} impl Timer { pub fn new(duration: Duration) -> Self { std::thread::spawn(move || { std::thread::sleep(duration); // TODO notify that we are ready }); Self {} } } impl Future for Timer { type Output = (); fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { // TODO How do we know that we are ready or not? } } }
We can realize the waiting portion of the Timer with a separate thread using std::thread::sleep, which blocks the thread for the given amount of time. Only, once std::thread::sleep returns, we need a way to signal to our Future that we are ready to progress. Ideally, we would be able to call upon this completion status within the poll method. Since this is a shared piece of information between multiple threads, let's give our Timer some shared state:
#![allow(unused)] fn main() { struct TimerState { ready: bool, } struct Timer { shared_state: Arc<Mutex<TimerState>>, } impl Timer { pub fn new(duration: Duration) -> Self { let state = Arc::new(Mutex::new(TimerState { ready: false, })); let state_clone = state.clone(); std::thread::spawn(move || { std::thread::sleep(duration); let mut state = state_clone.lock().unwrap(); state.ready = true; }); Self { shared_state: state, } } } }
With this shared state, we can check during poll whether the timer has elapsed or not:
#![allow(unused)] fn main() { fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let mut state = self.shared_state.lock().unwrap(); if state.ready { Poll::Ready(()) } else { Poll::Pending } } }
Let's run this code using our block_on executor:
fn main() { println!("Starting to wait..."); block_on(async { timer(Duration::from_secs(1)).await; println!("One second elapsed"); }); }
This prints Starting to wait... and then after about a second One second elapsed. So it works! The thing is, we still are using this busy-loop from within our executor, which takes a lot of CPU resources. Let's try to put our main thread to sleep until the Future is ready to make progress:
#![allow(unused)] fn main() { fn block_on<T, F: Future<Output = T>>(f: F) -> T { // ... loop { if let Poll::Ready(result) = f.as_mut().poll(&mut context) { return result; } std::thread::park(); } } }
We can use std::thread::park to let the current thread sleep util it is woken up by some other thread. This is great, because then the thread won't get scheduled and doesn't take up CPU resources. Now we just need a way for the timer thread to wake up our main thread. This is where the Waker comes in again (the name even begins to make sense now!), because we can write a Waker that can wake up threads:
#![allow(unused)] fn main() { struct ThreadWaker { handle: Thread, } impl ArcWake for ThreadWaker { fn wake_by_ref(arc_self: &Arc<Self>) { arc_self.handle.unpark(); } } }
Our ThreadWaker takes a Thread handle and once it is awoken, it calls unpark on that handle, which in turn will wake up the thread. Now we just need a way to make this ThreadWaker accessible to the timer thread. The only location where our Timer has access to the ThreadWaker is within poll, because here it has access to the Context through which we can retrieve the Waker:
#![allow(unused)] fn main() { fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let mut state = self.shared_state.lock().unwrap(); if state.ready { return Poll::Ready(()); } let waker = cx.waker().clone(); state.waker = Some(waker); Poll::Pending } }
To make sure that the timer thread can access the Waker, we have to extend our shared state to also include an Option<Waker>. We have to use Option because intially, there is no Waker assigned to the Timer.
#![allow(unused)] fn main() { struct TimerState { ready: bool, waker: Option<Waker>, } impl Timer { pub fn new(duration: Duration) -> Self { let state = Arc::new(Mutex::new(TimerState { ready: false, waker: None, })); let state_clone = state.clone(); std::thread::spawn(move || { std::thread::sleep(duration); let mut state = state_clone.lock().unwrap(); state.ready = true; if let Some(waker) = state.waker.take() { // Wake up the other thread through the Waker (which internally is a ThreadWaker!) waker.wake(); } }); Self { shared_state: state, } } } }
Now our block_on executor is much more efficient: It tries to poll the Future and if it is not yet ready, puts itself to sleep until the Future signals that it is ready to make progress using the ThreadWaker, which then wakes up the thread again, causing block_on to loop and call poll again. Neat!
As a closing note: Our block_on function is almost identical to futures::executor::block_on, a very simple executor provided by the futures crate.
More sophisticated executors
block_on is a simple but not terribly useful executor, because it only executes a single future, so we can't really do anything asynchronous with it. In real production code, we want to use a more powerful executor that also supports things like mio::Poll for real asynchronous I/O. There are a bunch of executors available, the two most popular ones are found in the tokio and async_std crates. Since asynchronous applications often want to run everything inside main in an asynchronous manner, both tokio as well as async_std provide macros to turn main into an async function, here shown for tokio:
#[tokio::main] async fn main() { timer(Duration::from_secs(1)).await; }
If you are interested in more details on how the executors in these libraries are built, the Rust async book has some chapters on how to build executors.
Many I/O heavy libraries for writing network applications are built on top of tokio or async_std, at the moment of writing tokio is a bit more popular and has a larger ecosystem though.
Conclusion
This concludes the chapter on asynchronous code, and with it our discussion of fearless concurrency using Rust. In this chapter, we learned a lot about what asynchronous code is and how it differs from writing parallel code. We saw that we can use the technique of I/O mutiplexing to manage multiple I/O operations from a single thread without unnecessarily blocking. Built on top of that is the Rust async/.await construct, which uses the Future trait to turn any synchronous computation into an asynchronous one. To execute Futures, we use executors, for which we saw one simple example (block_on) and the more sophisticated runtimes of tokio and async_std.