5.4. Result<T, E> - Error handling in Rust
As we said, Rust does not support exceptions. Which would leave error codes as the only error handling mechanism, but we already saw that they are hard to use and not really elegant. Rust goes a different route and provides a special type called Result<T, E> for error handling.
To understand how it works, let's think a bit about what it means for an error to occur in the code. Let's take a Rust function foo() that attempts to read a file from disk and returns its contents as a Vec<u8>: fn foo(file_path: &str) -> Vec<u8>{ todo!() }. The signature of such a function is &str -> Vec<u8>, so a function taking a string slice and turning it into a Vec<u8>. Of course there are a million ways to turn a string slice into a Vec<u8> (we could take the bytes of the string, compute a hash, interpret the string as a number and take its bytes etc.), but of course our function has special semantics that are not encoded in the type: It assumes the string is a file path and will return the file contents. We can use a more specific type here for the file path: fn foo(file_path: &Path) -> Vec<u8>{ todo!() }. Now recall what we learned about functions and types: A function is a map between values of certain types. In our case, foo is a map between file paths and byte vectors. Since both Path and Vec<u8> can be arbitrarily large (Path is like a string, which is like a Vec<char>), this is a function mapping an infinite set of paths to an infinite set of vectors. An interesting question to ask is how exactly this mapping behaves: Does every path map to one unique vector? Can two paths map to the same vector? Are there vectors that can never be returned from the function?
Mathematically, this question is equivalent to asking whether the function foo is injective, surjective, or bijective. These three properties of (mathematical) functions define how the elements from the input set (called the domain of the function) map to elements of the output set (called the codomain of the function). Wikipedia has a great image explaining these concepts:
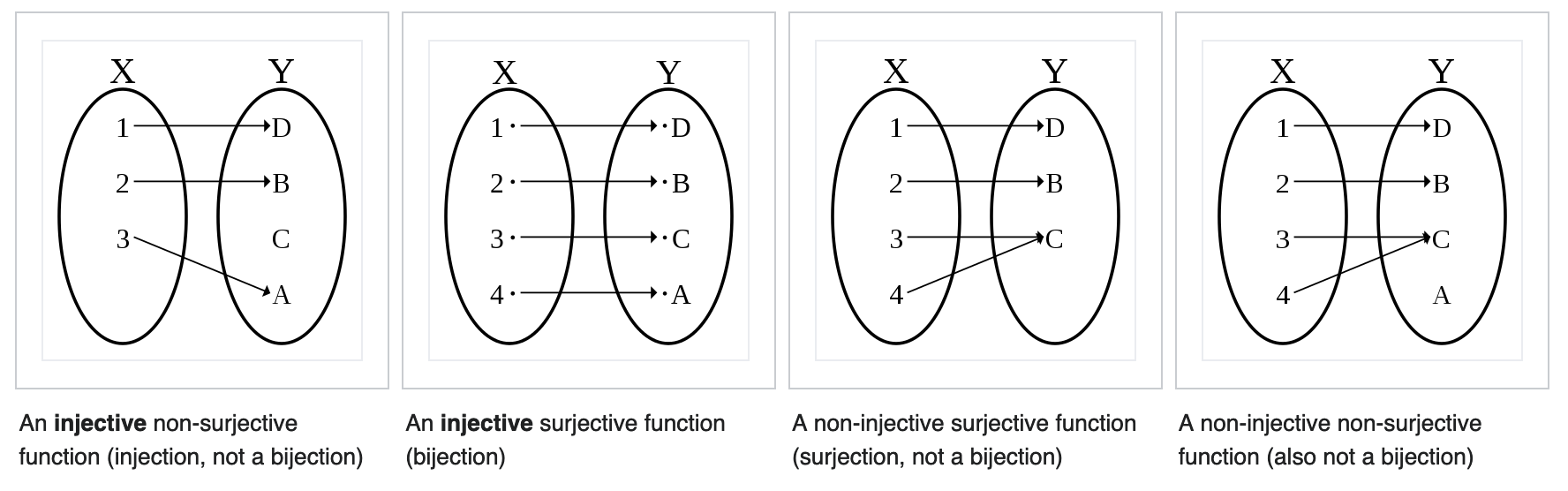
Even though the image depicts finite domains and codomains, the same concept can also be applied to functions with infinite domains and codomains. So which one is our foo function: Injective, surjective, bijective, or none of these? And what does this have to do with errors?
We can have multiple paths pointing to the same file and hence to the same byte vector: On Linux, /bar.txt and /baz/../bar.txt both point to the same file, but are different values for a Path object. So our function can't be injective!
To be surjective, every possible byte vector would have to correspond to at least one file path. That of course depends utterly on the current file system, but in principle, we could enumerate all possible byte vectors and assign them a path, for example by concatenating all the bytes, and use this as a file name. So our function could be surjective.
But there is a problem! What does our function do when it encounters a path to a file that does not exist? To what value should our function map this path? It could map it to an empty vector, as no bytes could be loaded for a file that does not exist, but this would make it impossible to distinguish between an empty file and a file that does not exist. Also, what about files that do exist, but are read-protected?
Let's look at this from a users perspective: If a user tries to open a file in some software, for example a text editor, and they specify an invalid path, what should happen? If we map invalid and inaccessible paths to an empty byte vector, the text editor might show an empty document. This might confuse the user, especially if they chose an existing file: Why is this existing file empty all of a sudden? It would be much better if the text editor notified the user that the file could not be opened. Even better would be if the user gets notified about the reason why the file could not be opened.
Is our function &Path -> Vec<u8> able to convey this information? Clearly not, because the codomain (Vec<u8>) has no way of encoding error information! Sure, we could take an error message and put its bytes into the Vec<u8>, but then how would we know that the returned vector contains an error message and that the bytes are not just the bytes that were loaded from the file?
To fix this mess, we do the same thing that we did in chapter 4.1 when we learned about the Option<T> type: We extend the set of return values! One possible way to do this would be to just use error codes and return a tuple like (Vec<u8>, ErrorCode) from the function. On ErrorCode::Success the Vec<u8> would contain the file data, otherwise the reason for the error would be encoded in the ErrorCode. But recall from our discussion on Option<T> that tuples are product types: Our function now returns a vector and an error code. But we never really need both: Either the function succeeds, in which case we just care about the Vec<u8>, or the function fails, in which case we don't care about the Vec<u8> and only need the ErrorCode to figure out what went wrong. On top of that, we might just use the Vec<u8> and forget to check the ErrorCode, resulting in a bug in our code!
So instead of using a product type, let's use a sum type:
#![allow(unused)] fn main() { enum SuccessOrError<T> { Success(T), Error(ErrorCode), } }
Now our function looks like this: fn foo(file_path: &Path) -> SuccessOrError<Vec<u8>> { todo!() }. It now returns either a successful result (the byte vector) or an ErrorCode. As an added benefit, Rust forces us to handle both cases separately (just like with Option<T>):
fn main() { match foo("/bar") { SuccessOrError::Success(bytes) => (), SuccessOrError::Error(error_code) => eprintln!("Error reading file: {}", error_code), } }
Maybe we don't want to return an ErrorCode but something else, like a message or some piece of contextual information. So it would be better if our SuccessOrError type were generic over what kind of error as well. This is exactly what the Rust built-in type Result<T, E> is:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
We can use this type like so:
#![allow(unused)] fn main() { fn foo(file_path: &Path) -> Result<Vec<u8>, String> { match std::fs::read(file_path) { Ok(bytes) => Ok(bytes), Err(why) => Err(format!("Could not read file ({})", why)), } } }
Here we used the standard library function std::fs::read, which reads the contents of a file into a Vec<u8> (just what our foo function was intended to do), which itself returns a Result<T, E>. The functions in the std::fs module return a special error type std::io::Error if they fail. Since we want to return a String instead, we match on the result of std::fs::read and convert the error into a message. Since foo also returns a Result<T, E>, we wrap both the contents of the happy path (bytes) and the error path (our message) in the appropriate literals of the Result<T, E> type. Since Result<T, E> is such a common type, it is automatically imported into every Rust file, so we can simply write Ok(...) and Err(...) instead of Result::Ok(...) and Result::Err(...).
With Result<T, E>, we have a mechanism to include failure as a first-class citizen in our code, by adding error types to the codomain (i.e. return type) of our functions. With Result<T, E>, we can explicitly state that a function might fail, similar to what we did with error codes, but a lot more explicit and flexible, since Result<T, E> can store anything as the error type.
Working with Result<T, E>
The Result<T, E> type has similar methods as the Option<T> type: Besides matching, we can check if a Result<T, E> contains an Ok value with is_ok() or an Err value with is_err(). If we only care about either of those values, we can convert from a Result<T, E> to an Option<T> with ok(), or to an Option<E> with err(). Both the ok() and the err() function consume the Result<T, E> value, which can be seen from the function signature:
#![allow(unused)] fn main() { pub fn ok(self) -> Option<T> }
It takes self by value, thus consuming the value it is called on. We already saw this pattern with some of the itereator algorithms in chapter 4.3.
One of the most useful functions on Option<T> was map(), and it exists on Result<T, E> as well. Since Result<T, E> has two possible types that could be mapped, there are multiple methods:
map()has the signature(Result<T, E>, (T -> U)) -> Result<U, E>and converts theOkvalue from typeTto typeUusing the given mapping function. If the givenResult<T, E>instead contains anErrvalue, the function is not applied and theErrvalue is just passed on.map_err()has the signature(Result<T, E>, (E -> F)) -> Result<T, F>and converts theErrvalue from typeEto typeFusing the given mapping function. If the givenResult<T, E>instead contains anOkvalue, the function is not applied and theOkvalue is just passed on.map_or_else()has the signature(Result<T, E>, T -> U, E -> F) -> Result<U, F>and is a combination ofmap()andmap_err()that takes two mapping functions to map both theOkvalue and theErrvalue to a new type.
With map_err() we can rewrite our foo function:
#![allow(unused)] fn main() { fn foo(file_path: &Path) -> Result<Vec<u8>, String> { std::fs::read(file_path). map_err(|e| format!("Could not read file ({})", e)) } }
Similar to Option<T>, we can chain multiple function calls that return a Result<T, E> value using and_then():
#![allow(unused)] fn main() { fn reverse_file(src: &Path, dst: &Path) -> Result<(), String> { std::fs::read(src) .and_then(|mut bytes| { bytes.reverse(); std::fs::write(dst, bytes) }) .map_err(|e| format!("Could not read file ({})", e)) } }
Notice how both Result<T, E> and Option<T> behave a little like a range of values, where you either have exactly one value (Some(T) or Ok(T)) or no values (None and disregarding the value of Err(E)). This is similar to an iterator, and indeed both Option<T> and Result<T, E> can be converted to an iterator using the iter() and iter_mut() functions.
The ? operator
Once we start using Result<T, E> in our code, we will often encounter situations where we use multiple functions that return a Result within a single function. A simple example would be to read a text-file, parse all lines as numbers, and compute the sum of these numbers:
#![allow(unused)] fn main() { fn sum_numbers_in_file(file_path: &Path) -> Result<i64, String> { let lines = match read_lines(file_path) { Ok(lines) => lines, Err(why) => return Err(why.to_string()), }; let numbers = match lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>() { Ok(numbers) => numbers, Err(why) => return Err(why.to_string()), }; Ok(numbers.into_iter().sum()) } }
We are using a helper function read_lines here, which is not part of the Rust standard library. All it does is reading a file line-by-line into a Vec<String>. Since this operation can fail, it returns std::io::Result<Vec<String>>. Also note that String::parse<T> returns a Result as well. If we were to collect the result of the map call into Vec<_>, we would get a Vec<Result<i64, ParseIntError>>. This would mean that we have to unpack every result and check if it is Ok or not. There is a shorter way, which is shown here: Collecting into a Result<Vec<i64>, ParseIntError>. This way, either all parse operations succeed, in which case an Ok value is returned, or the whole collect function early-exits with the first error that happened.
What we see in this code is a repeated pattern of matching on a Result<T, E>, continuing with the Ok value or early-exiting from the function with the Err value. This quickly becomes difficult to read. Since this is such a common pattern when working with Result<T, E>, the Rust language has a bit of syntactic sugar to perform this operation: The ? operator.
The ? operator is shorthand for writing this code:
#![allow(unused)] fn main() { // res is Result<T, E> let something = match res { Ok(inner) => inner, Err(e) => return Err(e), }; }
It only works in functions that return a Result<T, E> for Result<T, F> types, where F is convertible into E. With the ? operator, we can make our code much more readable:
#![allow(unused)] fn main() { fn sum_numbers_in_file_cleaner(file_path: &Path) -> Result<i64, String> { let lines = read_lines(file_path).map_err(|e| e.to_string())?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>() .map_err(|e| e.to_string())?; Ok(numbers.into_iter().sum()) } }
Unfortunately, since our function returns Result<i64, String>, we have to convert other error types into String by using map_err(). Let's try to fix that!
It is not uncommon that different functions that return Result values will have different error types. read_lines returned Result<_, std::io::Error>, while String::parse::<i64> returned Result<_, ParseIntError>. There is a common trait for all error types called Error. This is what Error looks like:
#![allow(unused)] fn main() { pub trait Error: Debug + Display { fn source(&self) -> Option<&(dyn Error + 'static)> { ... } fn backtrace(&self) -> Option<&Backtrace> { ... } // These two functions are deprecated: fn description(&self) -> &str { ... } fn cause(&self) -> Option<&dyn Error> { ... } } }
All types implementing Error have to implement the Debug and Display traits, so that the error can be converted into a human-readable representation. The Error trait also allows chaining errors together: source() returns the Error that caused the current error, if it is available. This is nice if you have a larger system with different subsystems where errors can propagate through many functions. Lastly there is a function to obtain a stack trace (backtrace()), but it is experimental at the moment of writing.
With the Error trait, we can try to write a function that returns an arbitary error, as long as it implements Error:
#![allow(unused)] fn main() { fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> { let lines = read_lines(file_path)?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>()?; Ok(numbers.into_iter().sum()) } }
This does not compile unfortunately. We try to use a trait like we would use a regular type and get both an error and a warning from the compiler:
warning: trait objects without an explicit `dyn` are deprecated
--> src/bin/chap5_result.rs:38:71
|
38 | fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> {
| ^^^^^^^^^^^^^^^^^ help: use `dyn`: `dyn std::error::Error`
|
= note: `#[warn(bare_trait_objects)]` on by default
= warning: this is accepted in the current edition (Rust 2018) but is a hard error in Rust 2021!
= note: for more information, see issue #80165 <https://github.com/rust-lang/rust/issues/80165>
error[E0277]: the size for values of type `(dyn std::error::Error + 'static)` cannot be known at compilation time
--> src/bin/chap5_result.rs:38:59
|
38 | fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
::: /Users/pbormann/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/src/rust/library/core/src/result.rs:503:20
|
503 | pub enum Result<T, E> {
| - required by this bound in `Result`
|
= help: the trait `Sized` is not implemented for `(dyn std::error::Error + 'static)`
The warning states that we have to use the dyn keyword when we refer to trait objects. Trait objects are Rusts way of dealing with types that implement some trait but whose type cannot be known at compile time. Think of trait objects like abstract base classes or interfaces in other languages. The compilation error actually relates to this: Objects whose type is not known at compile-time don't have a size known to the compiler. This is why the Rust compiler is complaining that our trait object (dyn std::error::Error) does not implement the Sized trait. Sized is a marker trait that is automatically implemented for all types that have a fixed size known at compile-time. Types that don't implement Sized are called dynamically sized types or DST for short. If you recall what we learned about how the compiler translates types into assembly code, one of the important properties was that the compiler has to figure out the size of types so that it can generate the appropriate instructions for memory access and so on. It is for this reason that Rust disallows storing DSTs in structs, enums, tuples, or to pass them by value to functions. The only option we have if we want to store an instance of a DST in some type is to store it on the heap, similar to how we used pointers and heap-allocations in C++ to store objects by their base class/interface. So let's use Box<T> to fix this problem:
#![allow(unused)] fn main() { fn sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, Box<dyn std::error::Error>> { let lines = read_lines(file_path)?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>()?; Ok(numbers.into_iter().sum()) } }
This now happily compiles and we also got rid of the map_err() calls! This is called 'boxing errors' and is the standard way in Rust to deal with arbitrary errors returned from functions. Since it is so common, there is actually a crate for working with arbitrary errors, called anyhow!
The anyhow crate
The anyhow crate is a good default crate to include in your Rust projects because it makes dealing with arbitrary errors easy. It defines a new error type anyhow::Error and a default Result type Result<T, anyhow::Error>, which is abbreviated as anyhow::Result<T>, or simply Result<T> if you add a use statement: use anyhow::Result;. When using anyhow, anyhow::Result<T> can be used as the default return type for all functions that might fail:
#![allow(unused)] fn main() { use anyhow::Result; fn foo() -> Result<String> { Ok("using anyhow!".into()) } }
anhyow provides several convenience functions for working with errors. The context() function can be used by importing the Context trait (use anyhow::Context;) and allows you to add some contextual information to an error to make it more readable. It also comes in a lazy variant with_context, which takes a function that generates the context information only when an error actually occurs:
#![allow(unused)] fn main() { let file_data = std::fs::read(path).context(format!("Could not read file {}", path))?; let file_data = std::fs::read(path).with_context(|| format!("Could not read file {}", path))?; }
If you want to early-exit from a function with an error, you can use the bail! macro:
#![allow(unused)] fn main() { fn foo(parameter: &str) -> Result<()> { if !parameter.starts_with("p") { bail!("Parameter must start with a 'p'"); } } }
panic!
Sometimes, you encounter conditions in your code that are so bad that your program can't possibly recover from them. In such a situation, it is often best to simply terminate the program, ideally printing an error message to the standard output. To do this, Rust provides the panic! macro. panic! immediately terminates the current programActually it terminates the thread that it is called from, but since we won't talk about threads until chapter 7, it's easier to understand this way for now. and prints an error message to the standard output (technically to stderr), along with information about where in the code the panic! happened. We can use it like so:
pub fn main() { panic!("Panic from main"); }
Which gives the following output:
thread 'main' panicked at 'Panic from main', /app/example.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
panic! has an intimate relationship with the Result<T, E> and Option<T> types. Both types provide a method called unwrap(), which accesses the Ok(T) or Some(T) value directly without any pattern matching. In case that the Result<T, E> contains an Err(E) instead, or the Option<T> contains None, unwrap() will panic! and terminate the program. It is tempting to use unwrap() because it often produces shorter code and skips all the nasty error handling business, but terminating a program is pretty extreme. You will see unwrap() being used mostly in example/prototype code, or in rare situations where you as a programmer know that an Option<T> will never contain None or a Result<T, E> will never contain Err(E). Apart from that, prefer pattern matching or functions such as map() or is_some()/is_ok() over unwrap().
By using the environment variable RUST_BACKTRACE, we can also see where in the code the panic occurred.