6.1. The file abstraction
In this chapter, we will know about one of the most fundamental abstractions of modern computers: Files. Most people who have worked with a computer will have some rough intutition about what a file is. It's this thing that stores data, right? Except, we also store data in working memory, and in CPU registers, and on our GPU, and so on. But we don't call our CPU a file. So what makes a file special?
The basics of files
In technical terms, a file is defines as a sequence of bytes, nothing more and nothing less. Files can be stored persistently on a hard drive, but they can also come from non-persistent devices such as networks or a terminal. Here is an image of a file in memory:
The file abstraction became very popular with the Unix-family of operating systems. Unix is built on the idea that all I/O operations can be modeled using files. So very input/output operation is based on a couple of 'atomic' operations on sequences of bytes called files:
- Open a file
- Read a range of bytes from a file
- Write a range of bytes to a file
- Changing the current position within a file
- Close a file
With these operations, we can read from the disk the same way as we would read from the network or any other I/O device. This is a powerful abstraction, because it reduces the complexity of various I/O operations (think about how using a network might be different from using a disk) to a simple set of operations. For us developers, this is very convenient.
Managing files and handling access to files is usually done by a part of the operating system called the file system. There are many different file system implementations in use today, such as ext4, ntfs, fat32 or zfs. You will even find file systems in other domains, such as distributed object storing services such as Amazon's AWS S3 service, which has its own file system. The study of file systems itself is not part of this course though.
One file system that is particularily interesting is the procfs file system on Linux. With procfs, we can get access to information about running processes using a bunch of files that we can read from (or write to to pass information to the process). This is very convenient because we can use standard command line tools such as cat or grep to work with processes.
A fundamental part of file systems is the management of file access. Programs have to be able to unqiuely identify each file through some sort of identifier. We call such an identifier a file path. Since users often interact with files, it makes sense to use text as the data type for file identifiers, so file paths are usually human-readable strings. Depending on the file system, file paths might contain additional information which is useful for grouping files together. On both Unix-systems and Windows, the file system can group multiple files together into directories, and this fact is represented in the file path. With directories, a hierarchical file structure can be formed, and this structure is represented through a path separator. Let's look at an example:
/home/asp/hello.txt
This path uniquely identifies a single file in a file system (ext4 in this case, though paths in most other file systems look similar). The path itself is simply a string, but we can break it up into several components using the path separator /:
/home: A directory namedhomewithin the root directory/of the file system. If all we had was the path/home, this could also point to a regular file, but since our path continues, we know thathomeis a directory./asp: A directory namedaspwithin thehomedirectory./hello.txt: A file namedhello.txtwithin theaspdirectory. The.txtpart is what is known as a file extension, which is a little piece of information that software can use to filter for files of a specific type (.txtis a common extension for text files, for example).
Seeing a path split up like this, the name path makes a lot of sense: It describes the path to a specific item within a tree-like structure (the file system)! The information whether an item within this tree is a file or a directory is stored within the file system itself. A simplified view of things is that the file system really is this tree-structure, where the entries are files and directories. In the ext4 file system (and several others), files and directories are different, but there are also file systems which do not have the concept of a directory, for example Amazon AWS S3.
The path separator itself is based on convention. Back in the early days of computing, Unix chose the / character for this, but Windows (more specifically its precursor MS DOS) chose \ (the backslash character) as the path separator. Modern Windows versions also support /, but the difference in path separators caused a lot of confusion in the past and is something to keep in mind.
The meaning of files
Since files are simply a sequence of bytes, what we use them for is up to us as developers. The meaning of these bytes comes solely from the interpretation of these bytes. A text file is a text file only because we define a special encoding that maps the positions and values of the bytes to text. For writing programs that work with files, this means that our programs have to know what kinds of files to expect. Working with text is often a good idea because text is such a fundamental data representation that many programming languages already provide mechanisms to interpret data as text when working with files. Sadly, text is not always an efficient representation, so many programs use different encodings to store their data in a more efficient format.
Here is an example to illustrate this: Suppose you have an image, which is made up of pixels. A common way to store image data is with red, green, and blue intensities for each pixel, so each pixel in the image is represented by 3 numbers. A sensible default for these numbers are 8-bit unsigned integers, giving 256 shades for each red-, green-, and blue-channel, or a total of \( 256^{3}=16777216 \) unique colors. If we represent each pixel in a binary format, using 8-bit unsigned integers, a single pixel takes exactly 3 bytes of memory. Since we know that each pixel has the same size, we can store the pixels tightly packed in memory, like this: rgbrgbrgb.... If we instead were to use a textual representation for the numbers, a single number can be between 1 and 3 characters long (e.g. 6, 95, 255). So either we add some separating character, or we pad with zeroes so that every number has the same amount of characters. If we assume that each character takes one byte of memory, we see that a textual representation takes three times the amount of memory than a binary representation.
Luckily, there are many standardized file formats available for various types of data. For compatibility reasons, it often makes sense to use a well-established file format instead of inventing a new format. The main factors are often efficiency and usability. Binary formats by their nature are more efficient to read and write, because no text-encoding/decoding has to be performed, but they are not human-readable. If files have to be inspected by humans, text-based formats are often preferred.
Common misconceptions about files
Since files are such a fundamental abstraction, there are a lot of misconceptions about files. First and foremost, we have to distinguish between the Unix file abstraction, which is an abstraction over an I/O device as we have seen, and files on a disk. We can have files in Unix systems that represent network connections, for example, and thus don't exist anywhere on the disk.
There is another common misconception that files on Windows systems are different than files on Unix systems. In general, this is not true, with two exceptions: Windows uses a different path separator, and Windows treats text files differently. A fundamental part of every text file is the concept of lines. Since text files really are just binary files with a special interpretation, some bytes within a text file have to represent the concept of a new line. There are two special characters that are often used for this, called the line feed (LF) and the carriage return (CR)These terms are old printer terminology. A line feed was equal to moving the printer head one row down, whereas a carriage return moved the printer head to the beginning (left) of the current line.. Unix systems use just a line feed to represent a new line, whereas Windows uses both a carriage return and a line feed.
The last misconception is about the meaning of file extensions, so things such as .txt or .pdf. Since the meaning of the bytes in a file depends on the interpretation of these bytes (called the file format), software has to know how to interpret a file to work with it. From just a raw sequence of bytes, how would anyone know what the correct file format of this file is? As a hint for applications, the file extension was established, which can help an application to filter for files that match an expected file format. The file extension however is purely encoded within the file path, it has no effect on the contents of the file! So you could rename a file foo.txt into foo.pdf, and this would leave the contents of the file unaltered. A PDF reader application might now think that this is a valid PDF file, but it probably won't be, because it was a text file initially (assuming that the initial file extension correctly represented the file in the first place).
Working with files on Linux
Access to files is managed through the operating system. On Linux, we have the POSIX API for this, with the following basic functions for handling files:
int open(char *filename, int flags, mode_t mode);int close(int fd);ssize_t read(int fd, void *buf, size_t n);ssize_t write(int fd, const void *buf, size_t n);
Linux also exposes some functions to access the file system directly, to get information about files and directories:
int stat(const char *filename, struct stat *buf);andint fstat(int fd, struct stat *buf);
On top of that, there are convenience functions in the C standard library for handling files:
fopen,fclose,fread,fwrite- Also for strings
fgetsandfputs - And for formatted I/O
scanfandprintf - Where the raw POSIX functions returned a file descriptor (an integer number identifying an open file for the operating system), the C standard library functions return a pointer to the opaque
FILEtype:FILE*
The advantage of the C standard library functions is that they are operating-system agnostic, which is a fancy term of saying: 'These functions work on any operating system (that supports a C library)'. If you were to use the raw POSIX functions, you would have to write different code when compiling your program for Windows. So what is called open on Linux is called CreateFileA on Windows.
Rust as a systems programming language should also work on multiple platforms, so we expect that Rust provides some abstractions for working with files as well, similar to the C standard library. The remainder of this chapter will deal with how files are represented in Rust.
Files in Rust
The Rust standard library has a lot of functionality in the standard library for working with files. Let's look at the first module for handling files: std::fs
If we look into std::fs, we will find a lot of functions and types for managing files and directories, such as create_dir or the Metadata type, but not a lot on how to read/write specific files. There is the File type and two functions to read an entire file into a String or vector as well as one function to write a slice as a whole file, but most other functions don't have anything to do with reading/writing files:
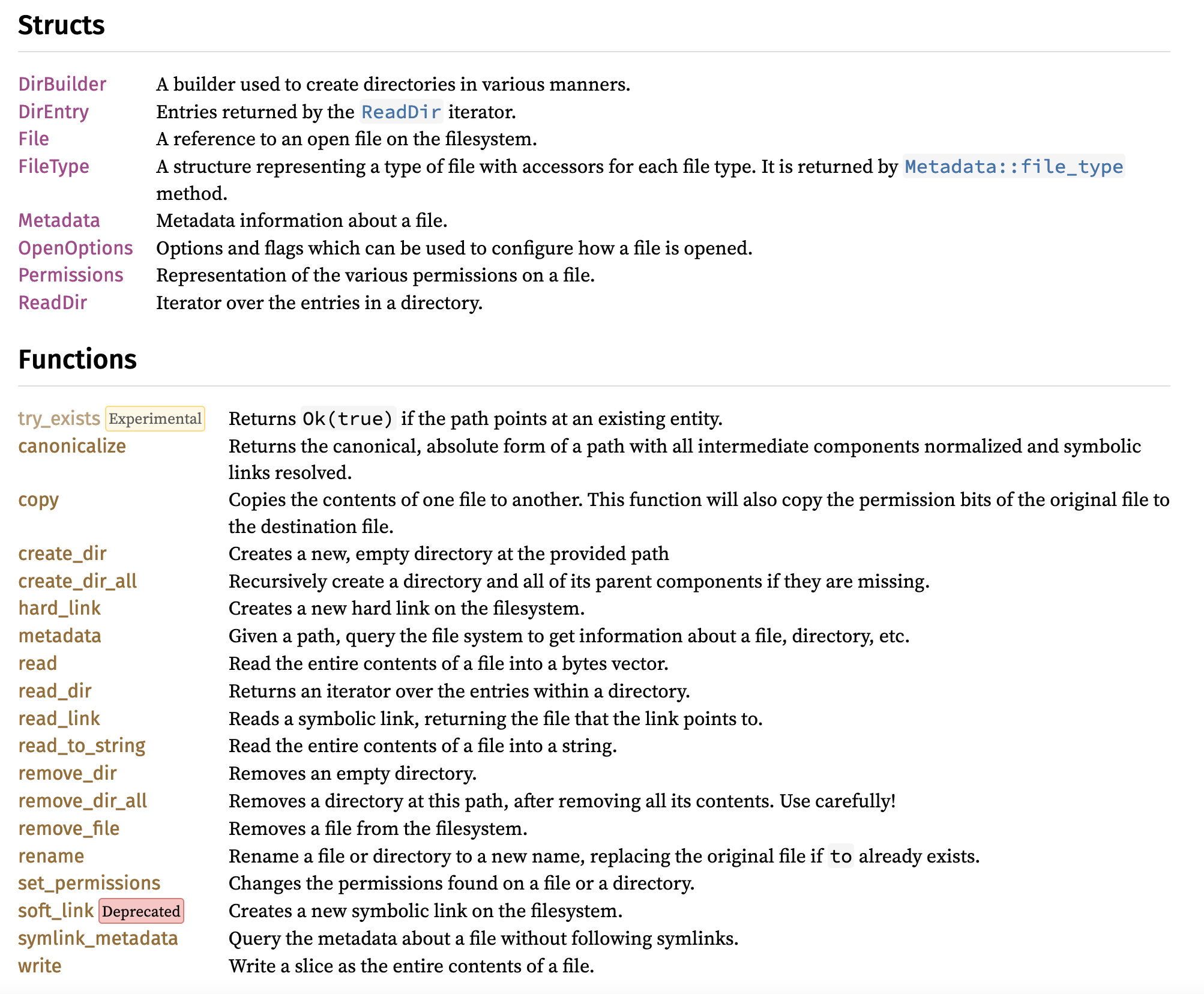
Remember when we said that the file abstraction is not the same thing as files in a file system? Rust makes this distinction as well, and the types for working with the file abstraction are located inside the std::io module instead! So let's look at std::io first!
The std:io module
std::io defines two core traits for doing I/O operations: Read and Write. It's not hard to guess what these two traits do: They provide means for reading and writing data. Since these are traits, they don't make any assumption on the source/target of these read and write operations. It could be a file, and indeed std::fs::File implements both Read and Write, but it could also be a network connection or even some in-memory buffer. In addition to these two traits, there is also the Seek trait, which provides useful functions for random access within a stream of bytes.
Here is what the Read trait looks like:
#![allow(unused)] fn main() { pub trait Read { fn read(&mut self, buf: &mut [u8]) -> Result<usize>; } }
It has one mandatory method that implementors have to define: read. When calling read, data from the type will be written into the provided buffer buf in the form of raw bytes (u8). Since read is an I/O operation, and I/O operations can frequently fail, the method returns the success status as a Result<usize> value, which will contain the number of bytes that were read in the Ok case, or the reason for failure in the Err case. The documentation of read has a lot more information on how this method is meant to behave, for now this is all we care about.
Here is what the Write trait looks like:
#![allow(unused)] fn main() { pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; } }
It is similar to Read, but requires two methods: write and flush. write is analogous to read, in that it takes a buffer of raw bytes and returns a Result<usize>. Where read took a mutable buffer, because this is where data is read into, write takes an immutable buffer for the data to be written. The return value of write indicates how many bytes were written in the Ok case, or the reason for failure in the Err case. Since writing is often buffered, there is also the flush method, which guarantees that all buffered data gets written to whatever destination the Write instance uses internally.
A quick look at Seek completes the picture for Rust's I/O abstractions:
#![allow(unused)] fn main() { pub trait Seek { fn seek(&mut self, pos: SeekFrom) -> Result<u64>; } pub enum SeekFrom { Start(u64), End(i64), Current(i64), } }
Seek also requires just one method to be implemented: seek. With seek, the current position to read from / write to within a Read/Write type can be manipulated. Since it is useful to either seek to an offset from the start, end, or current position of an I/O type, Seek uses the SeekFrom enum with the three variants Start(u64), End(i64), and Current(i64).
Exercise 6.1: Why does SeekFrom::Start wrap an unsigned integer, but SeekFrom::End and SeekFrom::Current wrap signed integers?
The std::fs and std::path modules
Now let's look at how to access files in a file system. As we already saw, the std::fs module contains functions and types to interact with the file system. The simplest way to access a file is by using the File type, like this:
use std::fs::File; use std::io::prelude::*; pub fn main() -> std::io::Result<()> { let mut file = File::create("test.txt")?; file.write_all(b"Test")?; Ok(()) }
Since files are typically either read or written, there are two convenience functions File::open and File::create for opening a file in read-only (open) or write-only (create) mode. For more control, the Rust standard library also provides the OpenOptions type. Since a file might not exist or might be inaccessible, these operations can fail and thus return Result<File>, so we use the ? operator here to simplify the code and get access to the File value in the success case. Since File implements both Read and Write, we can use all methods on these traits (if they are in scope, which is why we use std::io::prelude::*, which contains the two traits). write_all is a convenience method on Write that ensures that the whole buffer is written. b"Test" is some fancy syntax to create a byte array that corresponds to the text Test, since the methods on Write accept u8 slices and not str. We will see later how we can write string data more conveniently.
If you are curious, you might miss a call to flush in this code. In our case, File is not buffered internally, so there is no need to call flush. If a type requires a flush operation, one option is to implement Drop for the type and either call flush when the value of the type is dropped, or raise an error that the user forgot to call flush.
We accessed our file through a file path which we specified as a string literal: "test.txt". If we look at the definition of the File::create function, this is what we will see:
#![allow(unused)] fn main() { pub fn create<P: AsRef<Path>>(path: P) -> io::Result<File> { ... } }
It accepts a generic type P with the interesting constraint AsRef<Path>. AsRef is a trait for cheaply converting between borrows. It is similar to From, but is meant for situations where it is possible to cheaply obtain a borrow to a new type U from a borrow to a type T. As an example, the type &String implements AsRef<str>, indicating that there is a cheap way to go from a &String to a &str. Since &str is a borrowed string slice, and &String is a borrowed string, the conversion makes sense (&str will just point to the memory behind the String value). So here we have a constraint for AsRef<Path>, which means that any type is valid that can be converted to a borrow of a Path type (&Path). &str implements AsRef<Path>, so our code works.
Now, what is Path? It is a special type that represents a slice of a file path. It contains special methods for working with paths, like splitting a path into its components or concatenating paths. Since Path is only a slice, it is an unsized type and can only be used behind pointer types. There is an owned equivalent called PathBuf. Path and PathBuf are like str and String, but for file paths.
Working with paths in Rust takes some getting used to, because file paths are very close to the operating system but also include a lot of string handling, which is a complicated area in itself. Here are the most common ways of creating paths illustrated:
use std::path::*; fn main() { // Create a path from a string slice let p1 = Path::new("foo.txt"); // Create an owned PathBuf from a string slice let p2: PathBuf = "foo.txt".into(); //or PathBuf::from("foo.txt") // ...or from a Path let p3 = p1.to_owned(); //or p1.to_path_buf() // Getting a Path from a PathBuf let p4 = p3.as_path(); // Getting the string slice back from a path let str_slice = p1.to_str(); //Might fail if the Path contains invalid Unicode characters, which is valid for some operating systems // Building paths from separate components let p5 = Path::new("/usr").join("bin").join("foo.txt"); assert_eq!(p5.as_path(), Path::new("/usr/bin/foo.txt")); // Building paths from separate components using PathBuf let mut p6 = PathBuf::from("/usr"); p6.push("bin"); p6.push("foo.txt"); assert_eq!(p6, p5); // But beware: PathBuf::push behaves a bit weird if you add a path separator p6.push("/bin"); assert_eq!(p6.as_path(), Path::new("/bin")); //NOT /usr/bin/foo.txt/bin !! }
Path also has convenient methods to access the different components of a path (i.e. all the directories, potential file extension(s) etc.). To get every single component as an iterator, we can use components. To get a path to the parent directory of the current path, we can use parent, and to get only the file name of a path, file_name is used. Since paths are just strings with separators, all these methods don't have to allocate new memory and can instead return path slices (&Path) as well.
A Path also provides information about the file or directory it points to:
is_fileandis_dircan be used to determine if aPathpoints to a file or directory.metadatacan be used to get access to metadata about the file/directory (if possible). This includes the length of the file in bytes, last access time, or the access permissions.- For getting access to all files/directories within a directory, the useful
read_dirfunction can be used, which returns an iterator over all entries within the directory (if thePathrefers to a valid, accessible directory)
Writing strings to a Write type
In a previous section we saw that writing string data to a Write type can be a bit tricky, since the write method accepts a byte slice (&[u8]). The String type has a handy method bytes which returns a byte slice for the string, so we could simply use this. This works if we already have a String and just want to write it, but often we also have to create an appropriate String first. This is where the write! macro comes in! It combines the functionality of format! and writing data to a Write type:
use std::fs::File; use std::io::Write; fn main() -> std::io::Result<()> { let mut file = File::create("foo.txt")?; let the_answer: i32 = 42; write!(&mut file, "The answer is: {}", the_answer)?; Ok(()) }
Running this example will create a new file foo.txt with the contents: The answer is: 42. Notice the ? at the end of the write! macro call: Just as how calls to the raw write function on Writer could fail, calling the write! macro can fail as well, so write! returns a Result (in this case a Result<()>).
Buffered reading and writing
Under the hood, the read and write methods on File will use the file API of the current operating system. This results in system calls that have some overhead in addition to the raw time it takes to read from or write to the target I/O device. When frequently calling read or write, this overhead can slow down the I/O operations unnecessarily. For that reason, buffered I/O is often used. With buffered I/O, data is first written into an intermediate in-memory buffer, and only if this buffer is full (or flush is explicitly called) are the whole contents of the buffer written to the file using a single call to write. The process is similar for reading: First, as many bytes as possible are read into the buffer with a single read call, and then data is read from the buffer until the buffer has been exhausted, in which case the next chunk of data is read from the file.
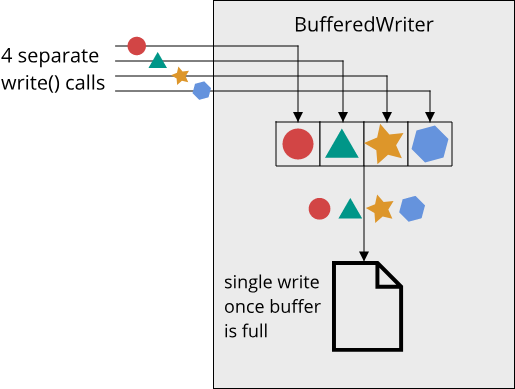
Since this is such a common operation, Rust provides wrapper types for buffered reading and writing: BufReader and BufWriter. We can use these types like so:
use std::fs::File; use std::io::BufWriter; use std::io::Write; fn main() -> std::io::Result<()> { let mut file = BufWriter::new(File::create("foo.txt")?); let the_answer: i32 = 42; write!(&mut file, "The answer is: {}", the_answer)?; file.flush()?; Ok(()) }
Since BufWriter implements Write, our code is almost identical, the only difference to before is that we wrap our File instance in a BufWriter and that we explicitly call flush at the end. This last part is important: While BufWriter does call flush when it is dropped (by implementing Drop), dropping happens automatically, but flush can fail. To make this work, BufWriter ignores all potential errors of the flush call while being dropped, so we have no way of knowing whether our writes really succeeded or not.
When using BufReader and BufWriter, we usually pass the inner type (for example a File instance) by value to the new function of BufReader or BufWriter:
#![allow(unused)] fn main() { impl<W: Write> BufWriter<W> { pub fn new(inner: W) -> BufWriter<W> {...} } }
Since Rust is move-by-default, this consumes our inner type, which makes sense, because we only want to use it through the buffered I/O type now! But sometimes, it is useful to get the inner type back from a BufReader or BufWriter. For this, we can use the into_inner method:
#![allow(unused)] fn main() { pub fn into_inner(self) -> Result<W, IntoInnerError<BufWriter<W>>> }
into_inner consumes self, so after calling it, the BufReader or BufWriter instance is not usable anymore. This is neat, because it guarantees that there is always exactly one owner of the underlying I/O type. We can start out with a File, then pass it to BufWriter::new, at which point we can only do I/O through the BufWriter, because the File has been moved. At the end, we call into_inner, effectively destroying the BufWriter and giving us back the File. As a caveat, into_inner has to perform a flush operation before returning the inner type, otherwise some buffered data might be lost. Since this can fail, into_inner returns a Result whose Err variant returns the BufWriter type itself. If you don't want to flush, consider using into_parts instead!
More I/O convenience functions
Sometimes, all you really want is to read the whole contents of a file into either a String (if it is a text file) or a vector of bytes (Vec<u8>). Rust has you covered:
fn main() -> std::io::Result<()> { let file_as_string: String = std::fs::read_to_string("foo.txt")?; let file_as_bytes: Vec<u8> = std::fs::read("bar.bin")?; Ok(()) }
These convenience functions take the size of the file into account, if it is known, and thus are generally very efficient.
Exercise 6.2: Compare different ways of reading the contents of a file into a Vec<u8>. Try: 1) std::fs::read, 2) a single call to File::read using a preallocated Vec<u8>, 3) a single call to BufReader::read with a preallocated Vec<u8>, and 4) the bytes function on Read together with collect::<Result<Vec<_>, _>>?. Try to measure the performance using Instant::now. What do you observe?
Recap
In this chapter, we learned about the file abstraction. Files are simply sequences of bytes, and they are a useful abstraction for input/output (I/O) operations. We learned about how Unix systems treat files and then looked at what abstractions Rust provides for I/O and files. We saw that Rust strictly separates between I/O (using the Read and Write traits) and the file system (using the std::fs module). Lastly we saw how to use the necessary types and functions in practice, with things like buffered I/O and string writing.