3.1. Types of memory in a typical computer
The memory hierarchy
Your average computer has many different types of memory available for programs to use. They differ in their storage capacity and access speed, as well as their location (internal or external storage). The term memory in the context of software is often used as a synonym for main memory, also know as RAM (Random Access Memory). Other types of memory include disk storage, found in your computers hard drive, as well as registers and CPU caches found on your processor. Beyond that, external storage media, such as network attached storage (NAS), cloud storage or tape libraries can also be available for your computer.
Together, the different types of memory form what is known as the memory hierarchy:
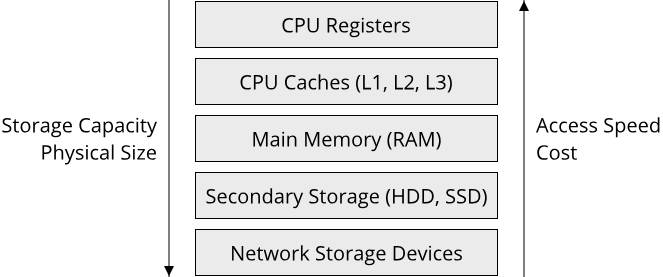
At the top of the memory hierarchy sit your CPU registers. These are small memory cells right on your processor, located very close to the circuits which do calculations (such as the ALU (Arithmetic-Logic Unit)). Registers typically only stores a couple of bytes worth of data. Next come a series of caches in increasing sizes, sitting also right on your CPU, although a bit further out since they are larger than the registers, in the order of Kilobytes to a few Megabytes. We will examine these caches closer in just a moment. After the CPU caches comes the main memory, which is typically several Gigabytes in size for a modern computer, though some clusters and supercomputers can have Terabytes of main memory available to them. Following the main memory is the secondary storage, in the form of hard-disk drives (HDDs) and solid-state drives (SSDs), which range in the low Terabytes. Lastly in the memory hierarchy are the network storage devices, which can be external harddrives, cloud storage or even tape libraries. They can range from several Terabytes up into the Exabyte domain.
Caches
Before continuing out study of the memory hierarchy, it is worth examining the concept of caches a bit closer. A cache is a piece of memory that serves as a storage buffer for frequently used data. Modern CPUs use caches to speed up computations by providing faster access to memory. There are caches for data and instructions, and different levels with different sizes. Here is a picture illustrating the cache hierachy in a modern processor:
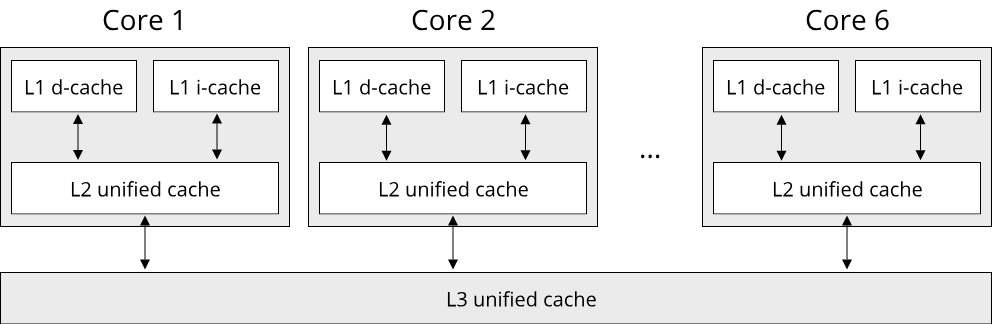
It depicts the caches for a processor with six logical cores, such as the Intel Core-i7 CPU in a 2019 MacBook Pro. At the lowest level, called L1, there are two small caches, one for storing executable instructions (L1 I-Cache) and one for storing data (L1 D-Cache). The typically are in the order of a few kilobytes large, 32 KiB for the given CPU model. Next up is the L2 cache, which is larger but does not differentiate between instructions and data. It is typically a few hundred kilobytes large, 256 KiB for the Core-i7 CPU. On top of that, modern CPUs have a third level of cache, which is shared by all cores, called the L3 cache. It is typically a few megabytes large, 12 MiB for the Core-i7 CPU.
The purpose of the memory hierarchy
At this point it is reasonable to ask: Why does this memory hierarchy exist? Why don't we all use the same type of memory? The memory hierarchy is built on the fact that fast memory is physically small and expensive, while large storage capacity has slow access times. The simplest explanation for this fact comes from the physical properties of electric circuits: To get information from one point to another, computers use electricity, which travels at roughly the speed of light through a conductor. While the speed of light is very fast, computers are also very fast, and these numbers cancel out quite neatly for modern computers. For a 3 GHz CPU, that is three billion cycles per second, every cycle lasts just a third of a nanosecond. How far does light travel in a third of a nanosecond? We can do the calculation: The speed of light is about 3*108 meters per second, a single cycle in a 3 GHz CPU takes 3.33*10-10 seconds. Divide one by the other and you get 1*10-1 meters, which is 10 centimeters. Not a lot. Assuming that we want to load a value from memory into register, do a calculation, and write it back to memory, it is physically impossible to do so in a single clock cycle if the memory is further than 5cm away from our CPU register, assuming that they are connected in a straight line. Since memory is made of up some circuitry itself, which takes up space, it becomes clear that we can't just have an arbitary large amount of memory with arbitrary fast access times.
There is a very famous chart available in the internet called 'Latency Numbers Every Programmer Should Know' which illustrates the differences in access times for the various types of memory in the memory hierarchy. For systems programming, we care about these numbers deeply, as they can have a significant impact on how fast or slow our code is running. Here are some of the most important numbers:
| Memory Type | Typical Size | Typical access time |
|---|---|---|
| Register | A few bytes | One CPU cycle (less than a nanosecond) |
| L1 Cache | Dozens of KiBs | A few CPU cycles (about a nanosecond) |
| L2 Cache | Hundreds of KiBs | ~10ns |
| L3 Cache | A few MiBs | 20-40ns |
| Main Memory | GiBs | 100-300ns |
| SSD | TiBs | A few hundred microseconds |
| HDD | Dozens of TiBs | A few milliseconds |
| Network Storage | Up to Exabytes | Hundreds of milliseconds to seconds |
A fundamental principle which makes the memory hierarchy work is that of locality. If a program exhibits good locality, it uses the same limited amount of data frequently and repeatedly. Locality can be observed in many processes outside of computer science as well. Think of a kitchen with dedicated drawers and cabinets for spices or cutlery. If you use one spice, the chances are high that you will use another spice shortly after, and if you use a fork, you might need a knive soon after. The same principle holds for computers: A memory cell that was read from or written too might be followed by reads and writes to adjacent memory cells shortly after. In more colloquial terms, locality means: 'Keep stuff you need frequently close to you'.
From the table of memory access speeds, we can see that it makes a huge difference if a value that our code needs is in L1 cache or in main memory. If a single main memory access takes about 100 nanoseconds, on a 3 GHz processor that means that we can do about 300 computationsThat is assuming that every computation takes just one CPU cycle to complete. This is not true for every instruction and also depends on the CPU instruction set, but for simple instructions such as additions, this is a resonable assumption. in the time it takes to load just one byte from main memory. Without caches, this would mean that an increase in CPU speed would be useless, since most time would be spent waiting on main memory. On top of that, increasing the speed of memory turns out to be much harder than increasing the speed of a CPU. In the end, adding several sophisticated cache levels was the only remedy for this situation.
Communicating between different memory devices
Since your computer uses different types of memory, there has to be a mechanism through which these memory devices can communicate with each other. Most modern computers follow the Von-Neumann architecture, which is a fundamental architecture for how components in a computer are connected. In this architecture, connecting the different parts of your computer to each other is a system called the bus. We can think of the bus as a wire that physically connects these parts, so that information can move from one device to another. In reality, there will be multiple buses in a computer that connect different parts to each other to increase efficiency and decrease coupling of the components.
Traditionally, there is a tight coupling between the processor and main memory, allowing the processor to read from and write to main memory directly. The processor can also be connected to other input/output (I/O) devices, such as an SSD, graphics card or network adapter. Since these devices will typically run at different speeds, which are often much slower than the clock speed of the processor, if the processor were to read data from such a device, it would have to wait and sit idle while the data transfer is being completed. In practice, a mechanism called direct memory access (DMA) is used, which allows I/O devices to access main memory directly. With DMA, the CPU only triggers a read or write operation to an I/O device and then does other work, while the I/O device asynchronously writes or reads data from/to main memory.
From a systems programming perspective, I/O devices thus are not typically accessed directly by the CPU in the same way main memory is. Instead, communication works through the operating system and the driver for the I/O device. In practice, this means that we do not care that variables that we declare in code refer to memory locations in main memory, because the compiler will figure this out for us. The same is not true for accessing data on your SSD (in the form of files) or on your GPU. Here, we have to call routines provided by the operating system to get access to these data.
Systems programming is a wide field, and depending on what types of systems you write, the information of this section might not apply to you. On an embedded system, for example, you might interface directly with I/O devices through writing to special memory addresses. The GameBoy handheld console, for example, required software to write the pixels that should be drawn directly to a special memory region which was then read by the display circuits. The study of such embedded systems with close interplay between hardware and software is interesting, however it is out of the scope for this courseThere is a course on embedded systems programming being taught at the same university that this course is taught, hence embedded systems are not covered in detail here., where we will focus on systems software for Unix-like systems. If you are interested in the nitty-gritty details of such a computer system, GBDEV is a good starting point.
Exercises
Matrix multiplication
A classical example where performance is dependend on cache access is matrix multiplication. Write a small Rust program that multiplies two N-by-N matrices of f64 values with each other and measure the performance of this operation. Store the matrix data in a one-dimensional array, like so:
#![allow(unused)] fn main() { struct Matrix4x4 { data: [f64; 16], } }
There are two ways of mapping the two-dimensional matrix to the one-dimensional array: Row-major and column-major order. Given a row and column index (row, col), look up how to calculate the corresponding index in the 1D-array for row-major and column-major memory layout. Then implement the matrix multiplication routine like so:
#![allow(unused)] fn main() { fn matrix_mul(l: &Matrix4x4, r: &Matrix4x4) -> Matrix4x4 { let mut vals = [0.0; 16]; for col in 0..4 { for row in 0..4 { for idx in 0..4 { // TODO Calculate l_idx, r_idx, and dst_idx. Do this once for row-major, and once for column-major // layout (in two separate matrix_mul functions) vals[dst_idx] += l.vals[l_idx] * r.vals[r_idx]; } } } Matrix4x4{ data: vals, } } }
To measure the runtime, you can use Instant::now(). In order to get some reasonable values, create a Vec with a few thousand matrices and multiply every two adjacent matrices (i.e. index 0 and 1, index 1 and 2, and so on). Do this for row-major and column-major order. Start with a small matrix of 4*4 elements, as shown here, and move up to 8*8, 16*16 and 32*32 elements. Comparing the row-major and column-major functions, which perform the same number of instructions and memory accesses, what do you observe?