The Stack
The first region that is worth a closer look is the stack. It gets its name from the fact that it behaves exactly like the stack datastructure: Growing the stack pushes elements on top of it, shrinking the stack removes elements from the top. In case of the stack memory region, the elements that are pushed and removed are just memory regions. Since the stack starts at a fixed address, a process only has to keep track of the current top of the stack, which it does through a single value called the stack pointer. If we are programming in assembly language, we can manipulate the stack pointer directly through the push and pop instructions, like so:
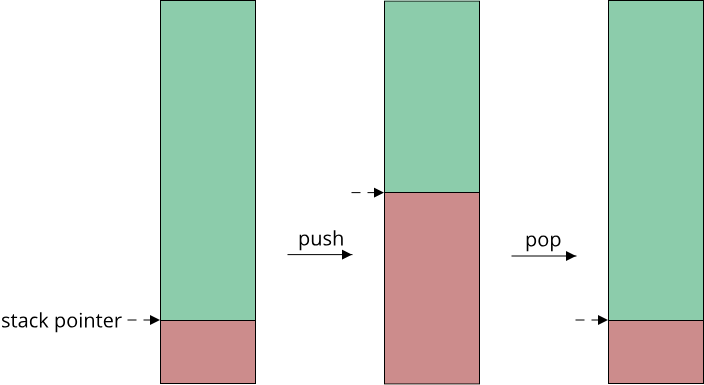
These instructions can only push and pop values that are in a register. So push rax pushes the value of the rax register onto the stack. On a 64-bit system, rax is a 64-bit register and thus holds an 8-byte value, so push rax first decrementsRemember that the stack grows downwards towards lower memory addresses! the stack pointer by 8 bytes, and then writes the value of rax to the old stack pointer address. pop rax goes the other way and removes the top value from the stack, storing it in the rax register. Again, rax is 8-byte wide, so an 8-byte value from the current stack pointer minus 8 is read and stored in rax, then the current stack pointer is incremented by 8 bytes.
In a higher level programming language than assembly language, instead of manipulating the stack directly, the compiler generates the necessary instructions for us. The question is: From which constructs in the higher-level programming language does the compiler generate these stack manipulation instructions?
In a language such as C, C++, or Rust, there are two constructs for which the stack is used: local variables and functions. Local variables are all variables that live inside the scope of a function. The scope of a variable refers to the region within the code were the variable is valid, i.e. it is recognized by the compiler or interpreter as a valid name. In C, C++, or Rust, a function scope can be thought of as the region between the opening and closing curly brackets of the function:
#![allow(unused)] fn main() { fn foo() { //<-- scope of 'foo' starts here let num = 42; //'num' is a local variable of 'foo' because it is valid only within the scope of 'foo' } //<-- scope of 'foo' ends here *num = 42; //<-- Accessing the variable 'num' outside of its scope is invalid under the rules of Rust! }
All local variables are stored on the stack, and the compiler generates the necessary code to allocate memory on the stack and store the values on the stack. Here we can see that having a language with static typing, where the type (and hence the size) of all variables is known to the compiler helps to generate efficient code.
The other situation where the stack is used for is to enable functions to call other functions. Let's look at an example:
#![allow(unused)] fn main() { fn f3(arg1: i32, arg2: i32) { let var_f3 = 42; println!("f3: {} {} {}", arg1, arg2, var_f3); } fn f2(arg: i32) { let var_f2 = 53; f3(arg, var_f2); println!("f2: {}", var_f2 + arg); } fn f1() { let var_f1 = 64; f2(var_f1); println!("f1: {}", var_f1); } }
Here we have three functions which all define local variables. Starting at f1, a variable is declared, then f2 is called with this variable as the function argument. Once f2 exits, the variable is used again in a print statement. f2 does a similar thing, declaring a variable, then calling f3 with both this variable and the variable that was passed in. f3 then declares one last variable and prints it, together with the arguments of f3. If we look at the scopes of all the variables, we could draw a diagram like this:
{ "scope of f1"
var_f1
{ "scope of f2"
var_f2
{ "scope of f3"
var_f3
}
}
}
By using the stack, we can make sure that all scopes of all variables are obeyed: Upon entering a function, memory is allocated on the stack for all local variables of the function, and upon exiting the function this memory is released again. The memory region within the stack corresponding to a specific function is called this function's stack frame. Passing arguments to functions can also be realized through the stack, by memorizing the address of the variable on the stack. In practice however, small arguments are passed not as addresses on the stack, but are loaded into registers prior to the function call. Only if the arguments are too large to fit into registers, or there are too many arguments, is the stack used to pass arguments.
We can examine how the stack grows by writing a simple program that prints out addresses of multiple local variables:
#include <iostream>
int main() {
int first = 42;
std::cout << &first << std::endl;
int second = 43;
std::cout << &second << std::endl;
return 0;
}
❓ Question
Without running the example code above, which of the two addresses &first and &second do you think is larger?
💡 Click to show the answer
Since the stack grows downward, the address of first should be larger than of second. All major OSes implement this convention. However the C standard does not define what the order of local variables on the stack is, so compilers are allowed to reorder variables on the stack, as long as they live in the same scope.
Run this example for yourself to verify the expected behavior.
Here is a key observation from our study of the stack: The stack automatically manages the lifetime of our variables! Think about it: Memory is a resource, and we learned that any computer resource must be managed somehow. It has to be acquired, and it has to be released properly, otherwise we will run out of the resource eventually. Here we have a mechanism that manages memory as a resource automatically for us, simply due to the way our programming language is structured! In addition, this mechanism for managing memory is as efficient as what we could have written by hand, even in raw assembly language. This is a powerful abstraction, and we will be looking for similar abstractions throughout this course.
While the stack works very well, it also has a lot of limitations. First and foremost, stack size is very limited! On Unix-systems, we can use the shell command ulimit -s to print the maximum stack size for our programs, which will often be only a few Megabytes. On top of that, the stack memory is directly tied to scopes. If we have data that is generated in one function, but should live longer than the function, we are out of luck, as stack memory is automatically cleaned up. For this reason, operating systems provide another memory region called the heap, which we can use much more freely.