4.2. Iterators
In the previous chapter, we talked about an abstraction (Option<T>) that lets us deal with two situations: We either have one value of a certain type, or we have zero values. While this something/nothing dichotomy is important - computers work with only two states (zero and one) after all - as programmers we almost always want to work with more than one value of a type. In this chapter we will learn about the concept of iterators, which is an abstraction over multiple values of a type. The iterator abstraction is one of the key pieces that made the C++ standard template library (STL) so successful, because it maps very well onto hardware. Besides learning what iterators are, we will see how C++ and Rust differ in their approach to this abstraction.
What is iteration?
Iteration is one of the first concepts that is taught to new programmers. The notion of doing the same thing multiple times is one of the cornerstones of computer science and the reason why computers are so successful, since they exceed at repetition. Many of the most fundamental operations in computer science rely on iteration: Counting, searching, sorting, to name just a few. The name 'iteration' comes from the latin word 'iterare', which translates as 'to repeat'.
If you learned a language such as C, C++, or Java, the basic language primitive for iteration is the for-loop, which can be described as 'doing something as long as a condition holds'. A simple implementation for calculating the sum of the first N natural numbers in C++ can be realized with a for-loop:
int sum(int n) {
int summand = 0;
for(int i = 1; i <= n; ++i) {
summand += i;
}
return summand;
}
We can translate this loop into a series of instructions in the english language:
- Initialize the variable
iwith the value1 - As long as
iis less than or equal ton:- Add
ionto the variablesummand - Add
1toi
- Add
Remember back to chapter 2, when we talked about programming paradigms? This is the imperative programming paradigm: A simple series of step-by-step instructions. There is nothing wrong with this way of programming, it maps very well onto computer hardware, but less well onto the way most people think, especially before they learn programming.
A different way of thinking about this problem is to restate it. What is the sum of the first N natural numbers? It is a special combination of the set of natural numbers \(\{1, 2, ..., N\}\), namely the addition of all its elements. The algorithm to compute this sum could be states as:
Starting with a sum of zero, for each element in the set \(\{1, 2, ..., N\}\), add this element to the sum.
Now instead of an imperative program, we have a declarative program, where we state what we want to do, not how it is done. Notice that we now deal with a collection of elements (the set of natural numbers up to and including N), and this algorithm involes iterating over all elements of this set! This is different from the for-loop that we had before. The for-loop stood for 'do something while a condition holds', now we have 'do something with each element in a collection'. Let's try to express this with C++ code:
int sum(const std::vector<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
The code is pretty similar to what we had before, but now we iterate over the elements in a collection (std::vector in this case). Naturally, the next step would be to make this code more generic. The algorithm that we described above does not really care what memory layout we use to store the numbers, so it should work with arbitrary collections. Let's try a linked-list:
int sum(const std::list<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
Unfortunately, this example does not compile! The problem here is that our implementation did make an assumption regarding the memory layout of the collection: We used operator[] to access elements by their index within the collection. But this requires that our collection provides random access in constant time. std::vector has random access, because it is just a linear array of values internally, but the whole point of a linked-list is that its elements are linked dynamically, so there is no way to index an element in constant time. Other collections don't even have the notion of an index. A set for example is - by definition - unordered, it only matters whether an element is part of the set or not, its position in the set is irrelevant.
But we can still iterate over the elements in a linked-list in C++:
int sum(const std::list<int>& numbers) {
int summand = 0;
for(auto number : numbers) {
summand += number;
}
return summand;
}
Here we are using the range-based for loop syntax that was introduced with C++11. In other languages, this is sometimes called a for-each loop, which describes pretty well what it does: It does some action for each element in a collection. But to realize this loop, the compiler has to know the memory layout and other details of the actual collection. Random-access collections such as std::vector can access elements using simple pointer arithmetic, a linked-list however requires chasing the link pointers. So what we really want is an abstraction for the concept of iteration. Enter iterators.
Iterators in C++
The C++ STL defines the concept of an iterator, which is any type that satisfies a set of operations that can be performed with the type. While there are many different variations of the iterator concept in C++, all iterators share the following three capabilities:
- They are comparable: Given two iterators
aandb, it is possible to determine whether they refer to the same element in a collection or not - They can be dereferenced: Given an iterator
a, it is possible to obtain the element thatacurrently refers to - They can be incremented: Given an iterator
a, it is possible to advanceato the next element
With these three capabilities, the concept of iteration is pretty well defined. Let's assume for a moment that we have some type Iterator<T> that we can obtain from a collection such as std::vector<T>. How would we write code with this type? Let's try something:
// Does not compile, just an example
int sum(const std::list<int>& numbers) {
int summand = 0;
for(
Iterator<T> iter = get_iterator(numbers);
???;
iter.advance()
) {
int number = iter.current();
summand += number;
}
return summand;
}
We can implement most things that are needed, in particular advancing it to the next element and obtaining the current element. But how do we know that we have reached the end of our iterator? There are several ways to do this, which will result in slightly different iterator abstractions:
- We can give our iterator a method
bool is_at_end()that we can call to determine whether we are at the end or not - We can compare out iterator against a special iterator that points to the end of the collection
Before reading on, what advantages and disadvantages do these two approaches have? Would you prefer one over the other?
C++ went with the second approach, while Rust went with the first. We will first examine the C++ approach and then move on to the Rust approach.
Since our C++ iterator has the ability to be compared to another iterator, if we can get an iterator that represents the end of our collection, we can rewrite our code like so:
// Does not compile, just an example
int sum(const std::list<int>& numbers) {
int summand = 0;
for(
Iterator<T> start = get_start(numbers), Iterator<T> end = get_end(numbers);
start != end;
start.advance()
) {
int number = start.current();
summand += number;
}
return summand;
}
This is exactly what the range-based for loop syntax in C++ does internally! The methods for getting the start and end iterators are called begin and end in C++ and are available on all collections in the STL. So every collection that provides begin and end methods can be used with the for(auto x : collection) syntax, thanks to the iterator abstraction. The return type of the begin and end expressions will depend on the type of collection, so there is no single Iterator<T> type in C++, only a bunch of specialized types that all satisfy the three conditions (comparable, dereferencable, incrementable) that we defined earlier.
To understand how exactly begin and end behave, we can look at a picture of an array:
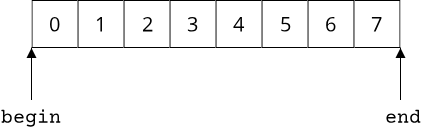
The position of the begin iterator is trivial: It points to the first element of the array, so that it can immediately be dereferenced to yield the first element. The end iterator is a bit more challenging. It must not point to the last element, because then the check begin != end in our for-loop would be wrong, causing the loop to terminate before the last element instead of after the last element. So end has to point to the element after the last element. This is not a valid element, so we must never dereference the end iterator, but using it in a comparison is perfectly valid.
Together, the begin and end iterator define what is known as a range in the C++ world, which is the jargon for any sequence of elements that can be iterated over. The following image illustrates how iterators can be used to iterate over an array with 3 values:
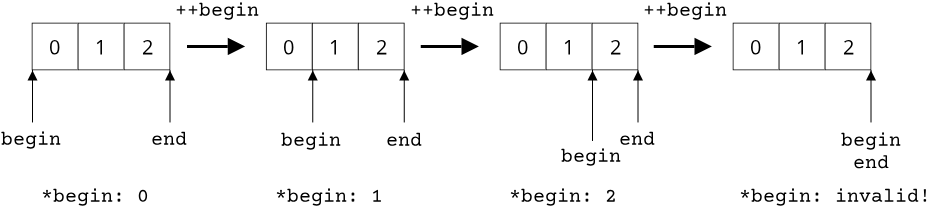
Examples of iterators in C++
So what types are iterators? The simplest type of iterator is a pointer. Iterating over the elements in an array can be achieved with a pointer, because the pointer supports all necessary operations:
int main() {
int values[] = {1, 2, 3, 4, 5};
int* begin = values;
int* end = values + 5;
for(; begin != end; ++begin) {
std::cout << *begin << std::endl;
}
return 0;
}
We can increment a pointer, which in C++ advances the pointer by however many bytes its type takes up in memory. For an array of type T, the elements are all sizeof(T) large and thus start at an offset that is N*sizeof(T) from the start of the array. So simply calling operator++ on a T* moves us to the right offsets, given that we started at the beginning of the array. Comparing pointers is easy as well, as pointers are just numbers. Lastly, dereferencing a pointer is what we are doing all the time to get access to the value at its memory location. So pointers are iterators.
What collections can we iterate over with a pointer? Arrays work, since they are densely packed, and in theory std::vector would also work (but in practice std::vector defines its own iterator type). In general, pointers are valid iterators for any collection whose elements are densely packed in memory. We call such a collection a contiguous collection. Built-in arrays, std::vector, std::array, std::basic_string (the actual type of std::string) as well as std::basic_string_view are all examples of contiguous collections.
We already saw std::list, a doubly-linked list, as an example for a non-contiguous collection. We can access the elements of std::list using a pointer during iteration, however we can't use operator++ on this pointer, as the elements of std::list are not guaranteed to be adjacent in memory:
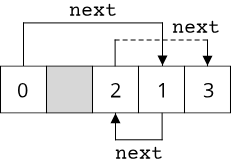
Incrementing the iterator for a std::list means chasing a pointer to the next link. So for iteration over std::list, we have to define a custom iterator type that encapsulates this behaviour:
template<typename T>
struct list {
struct node {
T val;
node* next;
node* prev;
};
//...
};
template<typename T>
struct list_iterator {
list_iterator& operator++() {
_current = _current->next;
return *this;
}
T& operator*() {
return *_current;
}
bool operator!=(const list_iterator& other) const {
return _current != other._current;
}
private:
typename list<T>::node* _current;
};
In C++, such an iterator is called a forward iterator, because we can use it to traverse a collection in forward-direction from front to back. Naturally, there should also be an iterator to traverse a collection in the opposite direction (back to front). As moving in the forward direction is achieved through operator++, moving backwards is achieved through operator--. An iterator that supports moving backwards using operator-- is called a bidirectional iterator. We could adapt our list iterator to also support iterating backwards:
template<typename T>
struct list_iterator {
list_iterator& operator++() {
_current = _current->next;
return *this;
}
list_iterator& operator--() {
_current = _current->prev;
return *this;
}
T& operator*() {
return *_current;
}
bool operator!=(const list_iterator& other) const {
return _current != other._current;
}
private:
typename list<T>::node* _current;
};
Corresponding to the begin and end functions, which returned an iterator to the first and one-after-last element respectively, when we want to iterate over a collection in reverse order, we can use the rbegin and rend functions. rbegin will point to the last element in the collection, rend to the element before the first element:
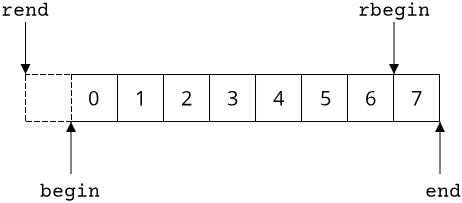
Iterators without collections
All the iterators that we have seen thus far always pointed to memory within a collection. There are situations where this is not desireable or simply not needed. Remember back to our initial method for calculating the sum of the first N natural numbers:
int sum(int n) {
int summand = 0;
for(int i = 1; i <= n; ++i) {
summand += i;
}
return summand;
}
This code is quite memory-efficient: At no point during the computation do we have to store all N numbers in memory. Switching to iterators introduced this requirement:
int sum(const std::vector<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
Here we have to pass in a std::vector which has to store in memory all the numbers that we want to sum. It would be nice if we could define iterators that don't point to memory inside a collection, but simply generate their elements on the fly, just as the naive for-loop does it. Such iterators are called input iterators and output iterators in C++. An input iterator only supports reading values, whereas an output iterator only supports writing values. Both iterator types are single-pass iterators, which means that we can only use them once, as opposed to the iterators pointing to collections, which can be re-used as often as we want.
Since input iterators are able to generate values on the fly, dereferencing will generally return a raw value (T) instead of a reference (T&). Let's try to write an input iterator for iterating over a sequence of adjacent numbers (an arcane procedure sometimes known as counting):
struct CountingIterator {
explicit CountingIterator(int start) : _current(start) {}
CountingIterator& operator++() {
++_current;
return *this;
}
bool operator!=(const CountingIterator& other) const {
return _current != other._current;
}
int operator*() {
return _current;
}
private:
int _current;
};
To make this usable, we need some type that provides begin and end functions which return our CountingIterator type, so let's write one:
struct NumberRange {
NumberRange(int start, int end) : _start(start), _end(end) {}
CountingIterator begin() const {
return CountingIterator{_start};
}
CountingIterator end() const {
return CountingIterator{_end + 1};
}
private:
int _start, _end;
};
We can use these two types to rewrite our initial code to work with iterators that don't belong to any collection:
int main() {
int sum = 0;
for(auto num : NumberRange(1, 100)) {
sum += num;
}
std::cout << sum << std::endl;
return 0;
}
If you ever wrote code in Python, this syntax might look familiar, since Python does not have an index-based for-loop:
for number in range(100):
print(number)
Iterators in Rust
Now let's take a look at how Rust handles iterators. We already saw that C++ uses a stateless approach to iterators, where the iterator instance itself does not know whether it is at the end of its underlying range or not. Rust goes a different route: Iterators in Rust do know once they have reached the end of the underlying range. Instead of defining the iterator capabilities in terms of its supported operators, Rust defines a trait called Iterator. The definition of Iterator is very simple:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; } }
Here we first encounter the concept of associated types, which are useful to let implementors of a trait communicate extra type information to users of the trait. In the case of Iterator, implementors of Iterator have to declare what type of items the iterator yields.
Rust then collapses all requirements for an iterator into a single method called next(). It returns an Option<Self::Item>, so either the next item of the underlying range, or a None value to indicate that the end of the range has been reached. Since next() takes a &mut self parameter, calling next() will mutate the iterator. Since Rust iterators communicate whether or not they have reached the end through the next() method, Rust iterators are stateful. This also means that iterator instances are not reusable in Rust!
Depending on who you ask, people might say that the way Rust handles iteration is closer to what the word 'Iterator' actually means, and that the C++ approach is more like a 'Cursor' since it contains no real state about the underlying range. We will refer to both C++ and Rust iterators simply by the term 'Iterator', as this is what is used in the respective documentation for both languages. Both abstractions are also known as external iteration, since the process of iterating over the range is controlled by an external object, not the range (or collection) itself.
C++ had the begin and end methods to obtain iterators for a collection or range. Since Rust iterators hold all necessary state in a single object, in Rust we don't need iterator pairs to represent ranges, and consequently don't need two methods to obtain iterators for a collection. Instead, Rust collections typically provide an iter() method that returns a new iterator instance. Just as C++, Rust provides built-in support for iterating over an iterator using a for loop:
pub fn main() { let numbers = vec![1, 2, 3, 4]; for number in numbers.iter() { println!("{}", number); } }
This could be the end of the story and we could move on to the next chapter, looking at the cool things we can do with iterators. Alas, Rust has strict lifetime rules, and they can become complicated when it comes to iterators. So we will take some time to understand how iterators and lifetimes play together before we can move on!
Rust iterators and lifetimes
To understand the problems with iterators and lifetimes in Rust, we will try to implement our own iterator for the Vec<T> type.
Vec<T> implements all of this already, but doing it ourselves is quite enlightening.
We start with a custom iterator type:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<T> { vec: &Vec<T>, } }
Since Rust iterators need to know when they have reached the end of their underlying range, we borrow the Vec<T> type inside the iterator. You already learned that borrows in structs require explicit lifetime annotations, so let's do that:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<'a, T> { vec: &'a Vec<T>, } }
Now we can implement the Iterator trait on our new type:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIter<'a, T> { type Item = &'a T; fn next(&mut self) -> Option<Self::Item> { todo!() } } }
The first thing we have to decide is what type our iterator yields. We could simply yield T by value, but then we would have to constrain T to be Copy, otherwise iterating over the collection would move the elements out of the vector. So instead we can return a borrow of the current element: &T. Surely this borrow can't outlive the vector, so its full type is &'a T.
How can we implement next()? For this, we have to keep track inside our MyAwesomeVecIter type where in the Vec we currently are. Since we know that our Vec type has contiguous memory, we can simply use an index for this:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<'a, T> { vec: &'a Vec<T>, position: usize, } impl <'a, T> MyAwesomeVecIter<'a, T> { fn new(vec: &'a Vec<T>) -> Self { Self { vec, position: 0, } } } }
Implementing next() is easy now:
#![allow(unused)] fn main() { fn next(&mut self) -> Option<Self::Item> { if self.position == self.vec.len() { None } else { let current_element = &self.vec[self.position]; self.position += 1; Some(current_element) } } }
This iterator is useable now:
pub fn main() { let numbers = vec![1,2,3,4]; for number in MyAwesomeVecIter::new(&numbers) { println!("{}", number); } }
That was fairly easy to implement. Let's try something more interesting: Mutating values through an iterator! Since in Rust, iterators are tied to the type of item that they yield, we need a new type to iterate over mutable borrows:
#![allow(unused)] fn main() { struct MyAwesomeVecIterMut<'a, T> { vec: &'a mut Vec<T>, position: usize, } impl <'a, T> MyAwesomeVecIterMut<'a, T> { fn new(vec: &'a mut Vec<T>) -> Self { Self { vec, position: 0, } } } }
It's basically the same type as before, but since we want to mutate the values, we have to borrow the underlying Vec<T> as mut. Now to implement Iterator on this type:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> { type Item = &'a mut T; fn next(&mut self) -> Option<Self::Item> { if self.position == self.vec.len() { None } else { let current_element = &mut self.vec[self.position]; self.position += 1; Some(current_element) } } } }
Nothing much changed besides a few mut keywords that we had to add. Unfortunately, this code does not compile, and what an error message we get:
error[E0495]: cannot infer an appropriate lifetime for lifetime parameter in function call due to conflicting requirements
--> src/chap4_iter.rs:52:40
|
52 | let current_element = &mut self.vec[self.position];
| ^^^^^^^^^^^^^^^^^^^^^^^
|
note: first, the lifetime cannot outlive the anonymous lifetime defined on the method body at 48:13...
--> src/chap4_iter.rs:48:13
|
48 | fn next(&mut self) -> Option<Self::Item> {
| ^^^^^^^^^
note: ...so that reference does not outlive borrowed content
--> src/chap4_iter.rs:52:40
|
52 | let current_element = &mut self.vec[self.position];
| ^^^^^^^^
note: but, the lifetime must be valid for the lifetime `'a` as defined on the impl at 45:7...
--> src/chap4_iter.rs:45:7
|
45 | impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> {
| ^^
note: ...so that the types are compatible
--> src/chap4_iter.rs:48:46
|
48 | fn next(&mut self) -> Option<Self::Item> {
| ______________________________________________^
49 | | if self.position == self.vec.len() {
50 | | None
51 | | } else {
... |
55 | | }
56 | | }
| |_____^
= note: expected `Iterator`
found `Iterator`
The problem is that we take a mutable borrow inside the next() method to something that belongs to self. next() itself takes a mutable borrow to self, which defines an anonymous lifetime. If we were to give this lifetime a name, it would look like this: fn next<'b>(&'b mut self). But next must return a borrow that is valid for the lifetime 'a. The Rust compiler has no way of figuring out whether 'a and 'b are related, so it complains that these two lifetimes are incompatible.
Ok, simple enough, let's just constraint the &mut self borrow with our 'a lifetime:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> { type Item = &'a mut T; fn next(&'a mut self) -> Option<Self::Item> { //... } } }
But this also does not compile:
error[E0308]: method not compatible with trait
--> src/chap4_iter.rs:48:5
|
48 | fn next(&'a mut self) -> Option<Self::Item> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ lifetime mismatch
|
= note: expected fn pointer `fn(&mut MyAwesomeVecIterMut<'a, T>) -> Option<_>`
found fn pointer `fn(&'a mut MyAwesomeVecIterMut<'a, T>) -> Option<_>`
note: the anonymous lifetime #1 defined on the method body at 48:5...
--> src/chap4_iter.rs:48:5
|
48 | fn next(&'a mut self) -> Option<Self::Item> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
note: ...does not necessarily outlive the lifetime `'a` as defined on the impl at 45:7
--> src/chap4_iter.rs:45:7
|
45 | impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> {
| ^^
Because the signature of the next() method is given by the Iterator trait, and it expects an anonymous lifetime parameter. Unfortunately, this is the end of our effort to implement a mutable iterator on Vec<T>: The lifetime rules of Rust, together with the definition of the Iterator trait make it impossible to implement a mutable iterator using only safe Rust. If we take a look at the mutable iterator for Vec<T>Which is actually an iterator over a mutable slice &mut [T], we will see that it uses raw pointers internally to circumvent the lifetime requirements:
#![allow(unused)] fn main() { pub struct IterMut<'a, T: 'a> { ptr: NonNull<T>, end: *mut T, _marker: PhantomData<&'a mut T>, } }
Instead of arguing whether this is a good idea or not, we will instead conclude this chapter by understanding why Rust's lifetime guarantees actually require Rust iterators to be stateful.
Why Rust iterators are stateful
C++ iterators are neat because they are so light-weight, both in terms of the data that an iterator instance stores as well as the information that it carries with it about the source container. We saw that pointers are valid iterators in C++, and pointers are very simple data types. This simplicity however comes with a cost: There is more information that we as programmers have to be aware about that is not encoded in the iterator type. Take a look at the following code:
#include <iostream>
#include <vector>
template<typename T>
void print_range(T begin, T end) {
for(; begin != end; ++begin) {
std::cout << *begin << std::endl;
}
}
int main() {
std::vector<int> numbers{1,2,3,4};
auto begin = std::begin(numbers);
auto end = std::end(numbers);
//Ah forgot to add something to 'numbers'!
numbers.push_back(42);
print_range(begin, end);
return 0;
}
In this code, we have a collection of numbers, obtain the necessary begin and end iterators from it and want to print the numbers using the iterators. Before we call the print_range function however, we add another number into the collection. A possible output of this code looks like this:
0
0
22638608
0
(But successful program termination!)
What went wrong here? Simple: We violated one of the invariants for the iterators of the std::vector type! We manipulated the std::vector while holding iterators to it. If we look at the documentation for std::vector::push_back, here is what it tells us:
If the new size() is greater than capacity() then all iterators and references (including the past-the-end iterator) are invalidated. Otherwise only the past-the-end iterator is invalidated.
One of the fundamental principles of std::vector is that adding new elements can cause a reallocation of the internal memory block, to accomodate the new elements. Since the begin and end iterators for std::vector are basically pointers to the start and end of the underlying memory block, calling push_back potentially causes our iterators to point to a freed memory block. Accessing freed memory results in undefined behaviour, hence the strange program output. Since iterators in C++ have so little state attached to them, we as programmers have to track their validity - the time in which they are valid - manually.
What does this mean for the Rust programming language? The closest thing to a raw pointer in safe Rust code is a borrow (&T), but borrows have much stricter semantics than pointers. Of the three operations that C++ iterators require (comparing, dereferencing, and incrementing), Rust borrows only support one: Dereferencing. So right of the bat we are stuck since Rust does not offer a suitable primitive type that we could use for a stateless iterator. If we could somehow use borrows to elements directly, the Rust borrow checker would prevent us from modifying the collection while we hold an iterator to it:
pub fn main() { let mut numbers = vec![1,2,3,4]; let begin = &numbers[0]; let end_inclusive = &numbers[3]; numbers.push(42); println!("{}", *begin); }
The push method takes a &mut self parameter, but we can't borrow numbers as mutable since we also borrowed it as immutable in begin and end_inclusive. So even if borrows don't have the right semantics, at least they would prevent the sort of mistakes that we can make with C++ iterators.
There is another reason why stateless iterators are difficult to realize in Rust. Note that with stateless iterators, we always require two iterators to define a range of elements. For working with an immutable range, the Rust borrow rules would suffice, but what if we wanted to manipulate the values in the range? This would require at least one mutable borrow (for the begin iterator) as well as an immutable borrow (for the end iterator, which is never dereferenced), but we can't have both due to the Rust borrow rules. We could do some stuff with unsafe code, but that would defeat the purpose of these rules. So stateful iterators are the better alternative. In the next chapter, when we look at applications of iterators, we will see that stateful iterators are often simpler to work with because they are easier to manipulate.
Rust iterators and conversions
In C++, if you have a type that you want to use with e.g. a range-based for-loop, you provide the begin and end functions for this type (either as member-functions or a specialization of the free functions with the same name). It is helpful to understand how to achieve the same behaviour in Rust, which is possible through the trait IntoIterator:
#![allow(unused)] fn main() { pub trait IntoIterator { type Item; type IntoIter: Iterator; fn into_iter(self) -> Self::IntoIter; } }
It provides two associated types Item and IntoIter, as well as a single function into_iter that returns the iterator. Item is simply the type of item that the iterator will yield, so for a Vec<i32>, we would implement IntoIterator with type Item = i32Of course, Vec<T> already implements IntoIterator in the Rust standard library.. The IntoIter type is the type of iterator that your type will yield when calling into_iter. It has to implement the Iterator trait, but otherwise you are free to use whatever type you want. Here is the implementation of IntoIterator for the Vec<T> type in the Rust standard library:
#![allow(unused)] fn main() { impl<T, A: Allocator> IntoIterator for Vec<T, A> { type Item = T; type IntoIter = IntoIter<T, A>; fn into_iter(self) -> IntoIter<T, A> { // Details... } } }
So for a Vec<T>, its iterator iterates over values of type T, which makes sense. The iterator type returned is some special type IntoIter<T, A> which is implemented elsewhere. We don't really care about the implementation of this type here. into_iter then simply returns a value of this IntoIter<T, A> type.
Let's look more closely at the into_iter method: Notice that it takes the self parameter by value. This is common for conversions in Rust: The value that is converted is consumed in the conversion. This has some interesting implications when implementing IntoIterator on your own types: If you call into_iter on your type, the value of your type is consumed. This is exactly what happens when calling into_iter on Vec<T>:
pub fn main() { let vec = vec![1,2,3,4]; for val in vec.into_iter() { //simply writing 'in vec' has the same behaviour println!("{}", val); } println!("Vec has {} elements", vec.len()); }
Since into_iter consumes its self argument, we can't use the vec variable after the for loop! This is a bit unfortunate, because there are many situations were we want to obtain a read-only iterator for our type and continue to use our type afterwards. Rust allows this behaviour, but it is somewhat pedantic on how we have to express this. Since Rust is move-by-default, obtaining an iterator from a collection by value means that we also iterate over the collections elements by value. Since this moves the values out of the collection, we can't use the collection after we have obtained the iterator, since the iterator requires ownership of the collection to perform these moves. If we want to iterate not over a collection by value, but instead by reference, we have to tell Rust that we want this to be possible. We do so by implementing the IntoIterator trait for borrows of the collection:
#![allow(unused)] fn main() { impl<'a, T, A: Allocator> IntoIterator for &'a Vec<T, A> { type Item = &'a T; type IntoIter = slice::Iter<'a, T>; fn into_iter(self) -> slice::Iter<'a, T> { // Details } } }
It might seem unusual, but traits can be implemented not only on a type T, but also on borrows of T (&T), or mutable borrows (&mut T). This works because &T is a different type than T, kind of like how in C++ T and T& are different types. Since Rust uses ad-hoc polymorphism, if we have a value of type U and call into_iter on it, the compiler simply checks if there is an implementation of into_iter on the type U in the current scope. If U is &T and we have an impl IntoIterator for &T, then the into_iter call can be resolved by the compiler.
The difference between IntoIterator on Vec<T> and &Vec<T> is that we now have type Item = &'a T, which means that if we obtain an iterator over a borrow of a Vec<T>, we will iterate over borrows of the vector's values. We also have a lifetime parameter 'a here all of a sudden. This is necessary because every borrow needs an associated lifetime, and in a declaration like type Item = &T, the compiler can't figure out an appropriate lifetime, so we have to use a named lifetime 'a here. This lifetime has to be equal to the lifetime of the borrow of the Vec<T> for obvious reasons: The borrows of the elements of the Vec<T> must not outlive the Vec<T> itself. In this special case, the iterator type is slice::Iter<'a, T>, which is a type that internally stores a borrow to the vector that it iterates over, so it carries the lifetime of the Vec<T> over to its signature.
Now take a look at into_iter again: It still takes self by value, but because we now impl IntoIterator on &Vec<T>, self is a borrow as well! Borrows always implement Copy, so taking a borrow by value does not make our value unusable. This way, we can iterate over a Vec<T> by reference and still use it afterwards:
pub fn main() { let vec = vec![1,2,3,4]; for val in &vec.into_iter() { //Notice the added '&' println!("{}", val); } println!("Vec has {} elements", vec.len()); }
Naturally, the next step would be to provide an impl IntoIterator for &mut Vec<T> as well, so that we can iterate over mutable borrows to the elements of a Vec<T>. This impl exists on Vec<T> as well and looks basically identical to the impl for &Vec<T>, so we won't show it here.
This covers the conversion from a type to an iterator. Of course, sometimes we also want to go in the opposite direction: We have an iterator and want to convert it to a type. The best example for this is the collect method on the Iterator trait in Rust. We use it all the time to collect the elements of an iterator into a collection. This can be a Vec<T>, but it is also possible to collect an iterator into other collections, such as HashMap<K, V> or HashSet<T>. The signature of Iterator::collect tells us how this is possible:
#![allow(unused)] fn main() { fn collect<B>(self) -> B where B: FromIterator<Self::Item>; }
There is a special trait FromIterator that types can implement to signal that they can be constructed from an iterator. Here is the signature of the FromIterator trait:
#![allow(unused)] fn main() { pub trait FromIterator<A> { fn from_iter<T>(iter: T) -> Self where T: IntoIterator<Item = A>; } }
It provides only a single method from_iter, but this method has an interesting signature. It takes a single value of a type T, where T has to implement IntoIterator<Item = A>. A itself is a generic parameter on the FromIterator trait, and it refers to the type of item that we are collecting. So if we had a type Foo that can be constructed from values of type Bar, we would write impl FromIterator<Bar> for Foo. So why does from_iter take a generic type T and not simply a specific iterator type? The problem is that there are lots of specific iterator types. Recall the three impl statements for IntoIterator on Vec<T>, which used three different iterator types (IntoIter<T>, slice::Iter<'a, T> and slice::IterMut<'a, T>). Do we really want to tie FromIterator to any of these specific types, thus preventing all other iterator types from being used with FromIterator? This is not really an option, so instead from_iter takes a generic argument with the only constraint that this argument is convertible into an iterator over items of type A. This is a very powerful and very generic trait, which means we can write funny code like this:
#![allow(unused)] fn main() { let v1 = vec![1,2,3,4]; let v2 = Vec::<i32>::from_iter(v1); }
Which is (almost) identical to writing:
#![allow(unused)] fn main() { let v1 = vec![1,2,3,4]; let v2 = v1; }
Can you figure out what the difference between these two examples is?
To conclude, the two traits IntoIterator and FromIterator are quite useful to enable conversions between collections and iterators. If you want to make a custom type iteratable, consider implementing IntoIterator. If you want to create an instance of a custom type from an iterator, consider implementing FromIterator.
Summary
In this chapter, we learned about the concept of iterators, the abstraction for dealing with ranges of things in many programming languages. We learned how iterators work in C++ through a set of simple operations: compare, dereference, increment. We saw that iterators can be both for collections of values in memory, as well as for ranges that are calculated on the fly. We then saw how Rust handles iterators differently to C++: C++ iterators come in pairs and are mostly stateless, Rust iterators are single objects that are stateful.