Copying values
Let us think back to what we initially set out to do in this chapter: We saw that there is some need to use dynamic memory allocation in a program, and we saw that it can be difficult to get right. So we (ab)used some language mechanics to create safe(r) wrapper types that do the dynamic memory management for us. Which led us down a rabbit hole of lifetimes and ownerships. We now know that we can use references/borrows to get around some of these ownership problems, but it hasn't really helped us in writing a better vector implementation. While the Rust language forces us to use borrows or accept that objects move, the C++ language does not do the same. So while the right way to do things is to pass our CustomVector object by reference to a function, we (or someone else using our code) can still ignore this knowledge and use call-by-value.
There are two ways out of this: One is to simply prevent our CustomVector type from ever being copied in the first place, effectively preventing call-by-value. This is easily done in C++11 and onwards, by removing the copy constructor and copy assignment operator:
CustomVector(const CustomVector&) = delete;
CustomVector& operator=(const CustomVector&) = delete;
Trying to pass CustomVector by value then gives the following error message:
<source>:61:18: error: use of deleted function 'CustomVector<T>::CustomVector(const CustomVector<T>&) [with T = int]'
61 | print_vec(vec);
| ~~~~~~~~~~^~~~~
Which is not too bad for a C++ error message ;)
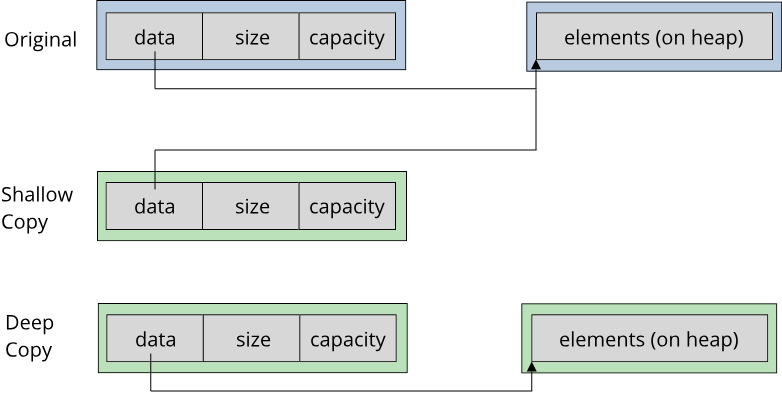
The other option is to think hard on what it actually means to copy a vector. Our CustomVector is actually a wrapper around some other type, in our case a dynamically allocated array. The important property of CustomVector is that the type that it wraps is not part of the memory of the CustomVector type itself! In memory, it looks like this:

For any such type that refers to memory that is not part of itself, we have two options when we copy the type. We can copy only the memory of the type itself, or we can also copy the external memory. The first approach is called a shallow copy, the second is called a deep copy. A shallow copy always creates additional owners to the same data, which was what the default-implementation of the copy constructor for CustomVector was doing. A deep copy creates a completely new object with a new owner and thus does not have the problem of ownership duplication. This comes at a cost however: Creating a deep copy of CustomVector means allocating another memory block on the heap and copying all elements from the original memory block to the new memory block.
Beyond the concept of shallow and deep copies, there is also another aspect to copying data, this time from a systems programming perspective. We can ask ourselves how copying a value translates to machine code. This is one last piece of the puzzle that we need to implement a decent copyable vector.
Copying versus cloning
To understand what is going on our your processor when we copy a value or an object, we can look at an example:
struct Composite {
long a, b, c, d;
};
int main() {
Composite a;
a.a = 42;
a.b = 43;
a.c = 44;
a.d = 45;
Composite b;
b = a;
return 0;
}
Here we have a composite type, made up of a bunch of long values. We create an instance a of this composite type and assign some values to its members. Then we create a second instance b and assign a to it, effectively creating a copy of a in b. Let's look at the corresponding assembly code of this example:
; skipped some stuff here ...
mov rbp, rsp
mov QWORD PTR [rbp-32], 42
mov QWORD PTR [rbp-24], 43
mov QWORD PTR [rbp-16], 44
mov QWORD PTR [rbp-8], 45
mov rax, QWORD PTR [rbp-32]
mov rdx, QWORD PTR [rbp-24]
mov QWORD PTR [rbp-64], rax
mov QWORD PTR [rbp-56], rdx
mov rax, QWORD PTR [rbp-16]
mov rdx, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-48], rax
mov QWORD PTR [rbp-40], rdx
; ... and here
A bunch of mov instructions. mov is used to move values to and from registers or memory. Of course in assembly code, there is no notion of objects anymore, just memory. Our two instances a and b live on the stack, and the current stack pointer always lives in the register called rsp. So the first line moves the value of rsp into another register for working with this value. Then we have four instructions that load immediate values (42 to 45) into specific memory addresses. This is what the mov QWORD PTR [X] Y syntax does: It moves the value Y into the memory address X. So the four assignments to the member variables a to d turn into four mov instructions which write these values onto the stack.
sizeof(Composite) will tell us that an instance of the Composite type takes 32 bytes in memory (at least on a 64-bit Linux system), so the first 32 bytes of the stack frame of the main function correspond to the memory of the a object. The next 32 bytes then correspond to the b object. The copy assignment can be seen in the eight mov instructions following the initialization of a: The values of a.a, a.b etc. are loaded into registers from their respective addresses on the stack, and then these register values are written to the stack again, at the address of b.a, b.b and so on. This has to be done in two steps, because the mov instruction in the x64 instruction set can only move data from a register to memory or vice versa, but never from memory to memory directly. The compiler chose to use two registers (rax and rdx), but all the copying could also be done with only the rax register, which would look like this:
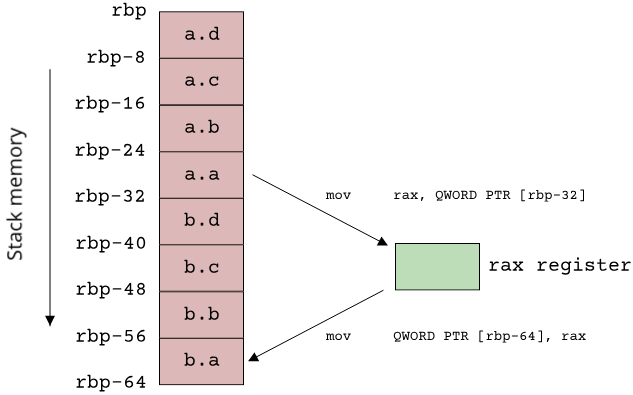
So there we have it: Copying the Composite type is equivalent to copying some numbers from one memory location to another. The C++ standard calls any type with this property trivially copyable. In Rust, there is a special trait for types that can be copied by simply copying their memory, aptly named Copy. In C++, being trivially copyable is an inherent property on a type, in Rust we have to explicitly state that we want our type to be trivially copyable:
#[derive(Copy, Clone)] struct Composite { a: i64, b: i64, c: i64, d: i64, } pub fn main() { let a = Composite { a: 42, b: 43, c: 44, d: 45, }; let b = a; println!("{}", a.a); }
We do so using the derive macro, which is a little bit of Rust magic that automatically implements certain traits for us, whenever possible. The generated assembly code of the Rust example will be quite similar to that of the C++ example. As an additional benefit, our assignment let b = a; does not move out of the value a anymore. Instead, since the value is trivially copyable, b becomes a copy of a and we can still use a after the assignment.
For all other types that can be copied, but not through a simple memory copy, Rust provides the Clone trait, which is a weaker version of Copy. In fact, any type that implements Copy has to implement Clone. Clone does what the copy constructor in C++ does: It provides a dedicated method that performs the copy process. To create a deep copy of our CustomVec class, we could use the Clone trait:
#![allow(unused)] fn main() { impl<T: Copy> Clone for CustomVec<T> { fn clone(&self) -> Self { let mut copy = Self::new(); for idx in 0..self.size() { copy.push(self.get_at(idx)); } copy } } }
This is not an efficient implementation, but it illustrates the process: Create a new CustomVec and push copies of all elements of the current CustomVec into the copy.
The distinction between a type being Copy or being Clone (or none of the two) is very useful for systems programming, because we can check on this property. If we know that a type implements Copy, we can assume that such copies are cheap and write algorithms differently than if the type only implemented Clone.