Understanding performance through benchmarking and profiling
In this chapter, we will look at how we can measure performance in systems software (though many of these techniques are not exclusive to systems software) by using a series of tools often provided by the operating system. When it comes to measuring performance, there are three terms that you might stumble upon: Benchmarking, profiling, and tracing. While they might be used interchangeably, the do mean different things and it is useful to know when to use which. Once we understand these terms, we will look at the tools available in modern operating systems (and the Rust programming language!) to understand the performance characteristics of our software.
Benchmarking vs. profiling vs. tracing
Benchmarking is perhaps the simplest to understand: When we employ benchmarking, we are looking for a single number that tells us something about the performance of our program. Executing this program takes 12 seconds on this machine, this function executes in 200 microseconds, the latency of this network application is about 200 milliseconds, or I get 60 frames per second in 'God of War' on my PC are all examples of benchmarking results (though the last is very high-level). The important thing is that the result of a benchmark is a single number.
Since modern computers are complex machines, performance is not always constant: The current system load, other programs running on your machine, thermal throttling, caching, all can have an effect on performance. This makes it hard to measure precise values when running a benchmark. Sticking with the previous examples, running program X might take 12 seconds when you run it the first time, but then only 10 seconds the second time, and then 13 seconds the third time, and so on. To deal with these uncertainties, benchmarking requires making use of statistics to quantify the uncertainty in a measurement. The amount of uncertainty that is to be expected depends on the system that you are benchmarking on: A microcontroller such as an Arduino might have very predictable performance, whereas running a program on a virtual machine in a Cloud environment where hardware is shared with thousands or millions of other programs and users can lead to much larger fluctuations in performance. The simplest way to get reliable results when benchmarking is thus to run the benchmark multiple times and performing statistical analysis on the results to calculate mean values and standard deviations.
The next performance measuring process is profiling. With profiling we try to understand how a system behaves. The result of profiling is - as the name suggest - a profile that describes various performance aspects of a system. An example is called 'time profiling', where the result is a table containing the runtime of each function in a program. If benchmarking tells you the number of seconds that your program takes to execute, profiling tells you how this number came to be. Profiling is immensely useful when developing modern systems software, as it helps us to make sense of the complexity of hardware and software. Where benchmarking answers the 'What?'-questions ('What is the runtime of this piece of code?'), profiling answers the 'Why?'-questions ('Why is the runtime of this piece of code X seconds? Because 80% of it is spent in this function and 20% in that function!'). Profiling can be overwhelming at first due to the increased amount of information compared to benchmarking, but it is an indispensable tool for systems programmers.
The last term is tracing, which is similar to profiling but not limited to performance measurements. It instead aims at understanding system behaviour as a whole and is often used whenever the system at hand is large and complex (such as operating systems or distributed systemsThe challenge with distributed systems is not that they are distributed, but instead that communication is asynchronous, which makes it difficult to understand cause/effect relationships. Incidentally, this is one of the reaons why distributed systems are considered 'hard' to develop for.). Tracing mainly helps to understand causal relationships in complex systems and as such the result of tracing (the trace) is most often a list of events with some relationship between them. Tracing can be used to understand system performance, but typically is used to understand causal relationships instead, for example to identify root failure causes in distributed systems.
An interesting property of benchmarking in contrast to profiling and tracing is that benchmarking in general is non-invasive, whereas profiling and tracing is invasive: Measuring a single number, such as program runtime, typically doesn't require an interference with the program itself, but understanding whole program behaviour requires some sort of introspection into the inner workings of the program and thus is invasive. As a result, benchmarking can almost always be done without affecting the behavior of the program, but gathering the necessary information for profiling and tracing might have some performance overhead itself. Simply put: The more detailed the information is that you want to gather about your system, the more resources you have to allocate to the information gathering, compared to actually running the program.
A first simple benchmark
Now that we know the difference between benchmarking, profiling, and tracing, how do we actually perform these actions? We saw that benchmarking is conceptually simple, so this is where we will start. In the previous chapter, we saw some performance metrics such as wall clock time or memory footprint. Let's try to write a benchmark that measures wall clock time, i.e. the amount of time that a piece of code takes to execute.
The first thing we need is some code that we want to write a benchmark for. Since we want to measure wall clock time, it should be a piece of code that takes a certain amount of time to run so that we get some nice values. For this first example, we will compute the value of the Ackermann function, which can be done in a few lines of Rust:
#![allow(unused)] fn main() { fn ackermann(m: usize, n: usize) -> usize { match (m, n) { (0, n) => n + 1, (m, 0) => ackermann(m - 1, 1), (m, n) => ackermann(m - 1, ackermann(m, n - 1)), } } }
We can write a very simple command line application that takes two integer values as arguments and calls ackermann to compute the value of the Ackermann function using the clap crate:
use clap::Parser; #[derive(Parser, Debug)] struct Args { #[clap(value_parser)] m: usize, #[clap(value_parser)] n: usize, } fn ackermann(m: usize, n: usize) -> usize { ... } fn main() { let args = Args::parse(); println!("A({},{}) = {}", args.m, args.n, ackermann(args.m, args.n)); }
The Ackermann function is an extremely fast-growing function. The Wikipedia article has a table showing values of the Ackermann function where we can see that even for very small numbers for m and n we quickly move beyond the realm of what our computers can handle. Try playing around with values for m and n and see how the program behaves! In particular notice the difference between ackermann(4,0) and ackermann(4,1) in terms of runtimeYou might have to run your program in release configuration to make ackermann(4,1) work!!
To measure the runtime of ackermann, we have a multiple options. We can measure the runtime of the whole program with a command-line tool such as time. A first try to do this might look like this: time cargo run --release -- 4 1. Notice that we run our code in release configuration! Always run the release build of your code when doing any kind of performance measurements! As we learned, building with release configuration allows the compiler to perform aggresive optimizations, causing code in release configuration to be significantly faster than code in debug configuration!
The output of time cargo run --release -- 4 1 might look like this:
Finished release [optimized] target(s) in 0.14s
Running `target/release/ackermann 4 1`
A(4,1) = 65533
cargo run --release --bin ackermann -- 4 1 3.00s user 0.07s system 95% cpu 3.195 total
Unfortunately, cargo run first builds the executable, so we get the runtime of both the build process and running the ackermann executable. It is thus better to run the executable manually when checking its runtime with time: time ./target/release/ackermann 4 1 might yield the following output:
A(4,1) = 65533
./target/release/ackermann 4 1 2.83s user 0.00s system 99% cpu 2.832 total
It tells us that the ackermann program took 2.832 seconds to execute.
time is an easy way to benchmark wall clock time for executables, but it is very restrictive as it only works for whole executables. If we want to know how long a specific function takes to execute within our program, we can't use time. Instead, we can add time measurement code within our program! If we had a very precise timer in our computer, we could ask it for the current time before we call our function, and the current time after the function returns, calculate the difference between the two timestamps and thus get the runtime of the function. Luckily, modern CPUs do have means to track elapsed time, and systems programming languages such as Rust or C++ typically come with routines to access these CPU functionalitiesIf you want to understand how the CPU keeps track of time, the documentation for the Linux clock_gettime system call is a good starting point.. In the case of Rust, we can use the std::time::Instant type from the standard library. As the name suggests, it represents an instant in time for some arbitrary clock, with the specific purpose of being comparable to other instants in time. Comparing two Instant types yields a std::time::Duration type, which can be converted to known time measurement units such as seconds, milliseconds etc. To use Instant for wall clock time measurement, we use the following pattern: At the start of the block of code that we want to measure, create an Instant using Instant::now(). Then at the end of the block, call elapsed on this Instant to receive a Duration, which we can convert to time values using various functions such as as_secs or as_millis. In code, it will look like this:
#![allow(unused)] fn main() { let timer = Instant::now(); println!("A({},{}) = {}", args.m, args.n, ackermann(args.m, args.n)); println!("Took {} ms", timer.elapsed().as_secs_f32() * 1000.0); }
Note that if you want to show the fractional part of the time value as we do here, instead of using as_millis we have to use as_secs_f32 (or as_micros) and manually convert to milliseconds, since as_millis returns an integer value and thus has no fractional part.
With this simple pattern, we can measure the wall clock time for any piece of code in our Rust programs!
Limitations of using std::time::Instant for wall clock time benchmarking
There are limitations when using the Instant type (or any related type in other programming languages) for wall clock time measurements:
- It requires changing the code and thus manual effort. It also will clutter the code, especially once you start to use it for more than one block of code at a time.
- The precision depends on the underlying timer that the standard library uses. In Rust, a high-precision timer is used, which typically has nanosecond resolution, but this might be different in other languages.
- On its own, benchmarking with
Instantdoes not perform any statistical analysis of the runtimes. It just measures runtime for one piece of code, which - as we saw - might vary from invocation to invocation.
Measuring time with Instant is very similar to debugging using print-statements: It is simple, works in many situations, but is also very limited. We generally have better tools at our disposal: Debuggers instead of print-statements and profilers instead of manual time measurements. We will see profilers in action shortly, but first we will see how we can write more sophisticated benchmarks!
Benchmarking in Rust with statistical analysis
We saw that benchmarking has its uses: Sometimes we really do want to know just how long a single function takes so that we can focus all our optimization efforts on this function. It would be great if we could easily take existing functions and write benchmarks for them which deal with all the statistical stuff. A good benchmark would run the piece of code that we want to measure multiple times, record all runtimes and then print a nice statistical analysis of the findings. Even more, due to the various caches in modern computers, running code for the first time or couple of times might be slower than running it for the fifth or tenth or hundreth time, so a 'warmup period' would also be nice. Oh and we have to make sure that we take enough samples to get a statistically significant result!
With your knowledge of systems programming and a bit of looking up the math in a statistics textbook you should be able to write code that does exactly this yourself. Or you could use the existing capabilities of Rust, namely cargo bench. Yes, cargo also includes functionalities for running benchmarks!
Benchmarks, similar to tests, are standalone functions that get run by a harness, which is a framework that orchestrates benchmark execution and gathering of information. With unit tests in Rust, you mark them with a #[test] attribute and when you type cargo test some magical framework finds all these tests, runs them and deals with any failures. This is a test harness, and the same thing exists for benchmarks. Since you typically want statistical analysis, warmups and whatnot, in practice you might use a sophisticated benchmark harness such as criterion.
Let's take a look at how a typical benchmark with criterion looks like. In rust benchmarks are stored in a folder called benches right in the root directory of your project:
benches/
benchmark_1.rs
...
src/
lib.rs
...
Cargo.toml
...
Here is an example of a typical benchmark function with criterion:
#![allow(unused)] fn main() { pub fn ackermann_bench(c: &mut Criterion) { c.bench_function("Ackermann(4,0)", |bencher| { bencher.iter(|| ackermann(4,0)); }); c.bench_function("Ackermann(4,1)", |bencher| { bencher.iter(|| ackermann(4,1)); }); } }
Two things are worth noting here: First we have a Criterion object which we can use to bench multiple functions at the same time. Second benching functions works through the bencher object which provides an iter which does exactly what we want, namely to run the function to benchmark multiple times. To run this benchmark we have to do a bit more: We have to add some boilerplate code that generates a main function and registers our benchmark function with criterion. We can do so like this:
#![allow(unused)] fn main() { // Add these imports up top: use criterion::{criterion_group, criterion_main, Criterion}; // Tell criterion the name for our benchmark and register the benchmark function as a group criterion_group!(bench, ackermann_bench); criterion_main!(bench); }
The other thing we have to do is to tell cargo that we want to use criterion as a benchmark harness. We have to do this in the Cargo.toml file like so:
[[bench]]
name = "ackermann_bench" # name of the benchmark file minus the file extension
harness = false
We can now execute our benchmarks by running cargo bench. Part of the output will look like this:
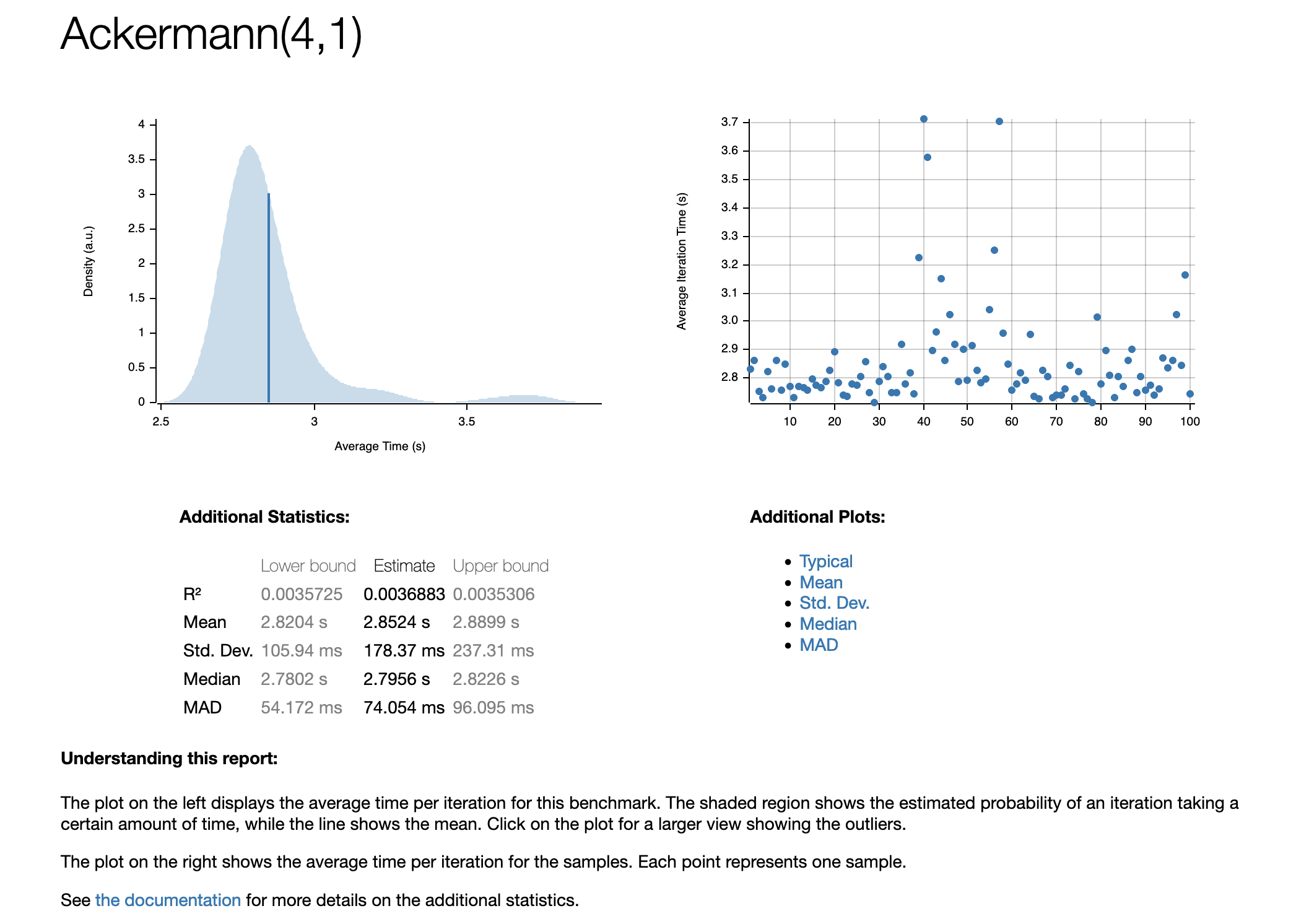
Ackermann(4,1) time: [2.8204 s 2.8524 s 2.8899 s]
Found 10 outliers among 100 measurements (10.00%)
5 (5.00%) high mild
5 (5.00%) high severe
We see that criterion ran the Ackermann(4,1) benchmark 100 times and computed statistical values for the resulting runtime. The values printed after time are what criterion calculated as the most likely candidates for the average runtime (specifically the lower bound, estimate, and upper bound, in that order). It also reported that there were some outliers whose runtime differed from the average runtime by some predefined percentage. Even better, criterion generates a visual analysis of the results and exports them to an HTML file that we can view. These files can be found in the target/criterion directory. For the Ackermann(4,1) test for example, there exists a file target/criterion/Ackermann(4,1)/report/index.html which looks like this:
Another userful feature of criterion is that it memorizes the benchmark results and compares the current results to the previous results. Suppose we decide to optimize the function by explicitly stating one more case in the match statement:
#![allow(unused)] fn main() { (1, n) => ackermann(0, ackermann(1, n - 1)), }
We think this might speed up the function, but there is no need for guesswork. We can simply run cargo bench again and take a look at the output of criterion:
Ackermann(4,1) time: [1.0168 s 1.0213 s 1.0263 s]
change: [-64.689% -64.196% -63.756%] (p = 0.00 < 0.05)
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
2 (2.00%) high mild
3 (3.00%) high severe
This was indeed a good change, criterion figured out that the performance has improved by about 64% and it even tells us the probability that this change in performance is just a random fluctuation. p = 0.00 < 0.05 in this case tells us that the probability is basically zero (or at least below 1%) that this is a random-chance event.
If you want to familiarize yourself further with criterion, the criterion user documentation is a good read that goes into detail on a lot of the configuration options and the statistical analysis that criterion performs.
Profiling
After you have written a benchmark for a function, you might still not know precisely why that function is as fast or slow as it is. This is where profilers come in handy, as they create an in-depth profile of the behavior of a program which lets us examine all sorts of detail that we might need to understand where the performance characteristics of the program originate from. Profiling is a complex topic and we can only skim the surface here, but there are lots of resources out there for the various profiling tools that exist.
First, we will need a program that we want to profile. Our Ackermann function calculator is a bit too simple, so instead we will use a slightly more useful program that can find occurrences of strings in files. Something like grep, but with much less features so that it fits in this book. A crude version of grep, if you will. Introducing crap, the silly grep variant!
crap - grep with less features
The whole code is still a bit too large to easily fit here, you can look it up online here. In essence, crap does what grep does: It searches for occurrences of some pattern in one or more files. We can launch it like so: crap PATH PATTERN, where PATH points to a file or directory, and PATTERN is the pattern to search for. To search for all occurrences of the word Rust in the source code of this book, you would call crap /path/to/book/src Rust, which would print something like this:
Matches in file /Users/pbormann/data/lehre/advanced_systems_programming/skript/src/chap4/4_1.md:
61 - 284: ...f the Rust progr...
76 - 141: .... The Rust-type ...
76 - 251: ..., the Rust type ...
78 - 94: ...2` in Rust? What...
80 - 78: ...>` in Rust? We c...
...and so on
The heart of crap is the search_file function, which looks for matches in a single file. If you pass a directory to crap, it recursively searches all files within that directory! search_file looks like this:
#![allow(unused)] fn main() { fn search_file(path: &Path, pattern: &str) -> Result<Vec<Match>> { let file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; Ok(file .lines() .enumerate() .filter_map(|(line_number, line)| -> Option<Vec<Match>> { let line = line.ok()?; let matches = regex .find_iter(line.as_str()) .map(|m| { // Get matches as Vec<Match> from line }) .collect(); Some(matches) }) .flatten() .collect()) } }
It reads the file line-by-line and searches each line for occurrences of pattern (the pattern we passed as command-line argument!) using the regex crate. When a match is found, it is converted into a Match object like so:
#![allow(unused)] fn main() { let context_start = m.start().saturating_sub(NUM_CONTEXT_CHARS); let context_end = (m.end() + NUM_CONTEXT_CHARS).min(line.len()); // If the match is somewhere inbetween, print some ellipses around the context to make it more pretty :) let ellipse_before = if context_start < m.start() { "..." } else { "" }; let ellipse_after = if context_end < line.len() { "..." } else { "" }; // Make sure the context respects multi-byte unicode characters let context_start = line.floor_char_boundary(context_start); let context_end = line.ceil_char_boundary(context_end); Match { context: format!( "{}{}{}", ellipse_before, &line[context_start..context_end], ellipse_after ), line_number, position_in_line: m.start(), } }
This code extracts the match itself and some of its surrounding characters from the line (called context here), which is why crap always prints a bit more than just the pattern on each line. It also memorizes the line number and the position within the line, which are the two numbers that you see before the context:
61 - 284: ...f the Rust progr...
// Match in line 61, starting at character 284
Understanding the performance characteristics of crap
Now that we have our program, let's start to analyze the performance. We already saw that we can get a very rough estimate of the wall clock time by using time, so let's do that with crap. We also need some test data that is interesting enough and large enough so that we get usable performance data. We will use enwik8, which is a dump of the English Wikipedia containing the first 100MB of data. Let's see how crap fares to find all occurrences of the term Wikipedia. First, let's see how many matches we get. You can either run crap with logging enabled by setting the environment variable RUST_LOG to info, or use the command line tool wc, if you are on a Unix system:
crap enwik8 Wikipedia | wc -l
|> 2290
So 2290 matches. Technically, 2289 because crap also prints the file name of each file it searches. How long does it take?
time crap enwik8 Wikipedia
|> 0.25s user 0.03s system 86% cpu 0.316 total
0.3 seconds to search through 100MB of text, which gives us a throughput of about 330MB/s. Not bad. But can we do better? Let's compare it to some existing tools. First, grep:
time grep -o Wikipedia enwik8
|> 0.82s user 0.07s system 79% cpu 1.119 total
We use -o to print only the matching words, as otherwise grep prints a lot more (and nicer) context than crap. But hey, crap is about 3 times faster than grep! This is probably not a fair comparison though, as grep is much more powerful than crap. Let's try ripgrep, a faster grep alternative written in Rust!
time rg -o Wikipedia enwik8
|> 0.02s user 0.05s system 35% cpu 0.182 total
ripgrep is about twice as fast as crap, and it is also more powerful! Oh crap!!
Now it is time to whip out the big tools! We have to profile crap to understand where we can optimize! Profilers are system-specific tools, so we will only look at one profiler here - Instruments for MacOSWhy a profiler for MacOS and not Linux? The go-to profiler for Linux is perf, which is very powerful but runs only on the command line. Instruments for MacOS has a nice GUI and is similar to other GUI-based profilers such as the one shipped with Visual Studio on Windows. - but the workings are usually similar when using other profiling tools.
Instruments - A profiler
We saw that there are many metrics that we can gather for a program. If you launch a profiler such as Instruments, you typically will be greeted by a screen to select what type of profiling you want to do. Here is how it looks like for Instruments:
There are some MacOS-specific features here, but also some more general ones. We will look at the CPU Profiler and the Time Profiler in detail, but here is a list of what the most common profiling types are that you will find in profiling applications:
- Cycle- or time-based profilers that show how long each function in your code took to execute
- CPU counters, which show things like cache miss rates, branch mispredictions and other low-level counters that your CPU supports
- System tracing, showing a more general overview of the inner workings of the operating system while your application is running. This might show things like how thread are scheduled across CPU cores, or virtual memory page misses
- Network tracing, which shows network packages and network traffic generated by your application
- Memory tracing, which shows how memory is allocated and from which part of your code. This might also include detecting memory leaks
- GPU profiling, which shows what code is executed on your GPU, how long it takes, and might also include GPU counters similar to the CPU counters. If you are doing graphics programming, there might be dedicated graphics profilers that show things like draw calls, shader, buffer, and texture usage in more detail
We will choose the CPU Profiler option for now. If we do that, we have to select the executable that we want to profile, so make sure that you have a compiled binary available. Two things are important: We want a release build, because it is optimized and we typically want to measure performance of the optimized version of our program. And we want debug symbols, so that we can understand the names of the functions that were called. In Rust, you can add the following two lines to your Cargo.toml file to generate debug symbols even in a release build:
[profile.release]
debug = true
In Instruments, selecting the executable looks like this:
We can specify command line arguments with which to run this executable, and some other parameters such as environment variables. Once we have our executable selected, we will be greeted with the main screen for CPU profiling in Instruments. At the top left, there is a record button that we can press to run our program while the profiler is gathering its data. If we do that with our crap tool, this is what we might get:
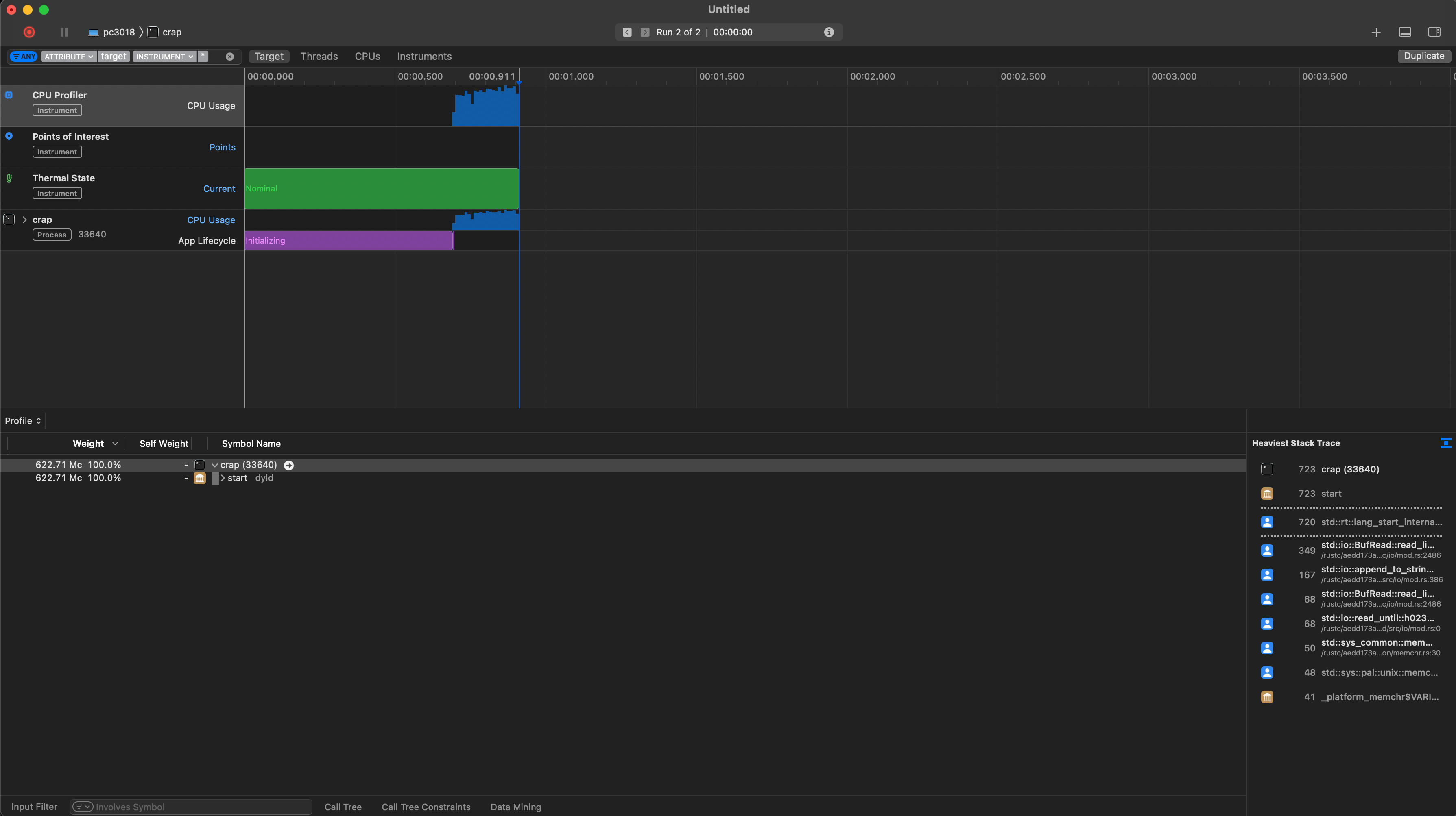
There are three main areas of interest in this screen:
- A timeline at the top, with some graphs that show things like CPU usage over time. Here, you can filter for a specific region in time, which is helpful for narrowing in on critical sections of your program
- A call-hierarchy view at the bottom left. This shows the number of CPU cycles spent in each function over the whole runtime of your program, and this is where we will get most of the information the we care about from. It works like a stack-trace and allows us to 'dig in' to specific functions in our program
- A stack-trace view on the right, which gives a more condensed overview of the 'heaviest' functions, which is to say the functions that your program spent most of the time in
Let's start exploring the data we have available! Unsurprisingly, most of the CPU cycles of our program are spent in main, which doesn't tell us much. But we can start to drill down, until we end up in a function that calls multiple functions with significant numbers of CPU cycles spent. At this point, it is important to understand how to read these numbers. Instruments gives us two columns called 'Weight' and 'Self Weight'. 'Weight' is the total number of CPU cycles spent in this function and all functions called by this function, whereas 'Self Weight' refers only to the number of CPU cycles spent within this function alone. Let's look at a simple example:
Suppose we have two functions a() and b(), where a() calls b(). a() has a Weight of 100, b() a Weight of 80. Since 80 cycles of the full 100 cycles spent in a() come from the call to b(), we know that the remaining 20 must come from stuff that a() does that does not blong to any function call. So the Self Weight of a() would be 20.
So we can start to drill down until we find a function that either has a significant Self Weight, or calls multiple functions where at least one of them has a significant Weight. In our case, we will end up with a function called try_fold, which took about 600 million CPU cycles. This function calls two functions that both take about 300 million CPU cycles: BufRead::read_line and enumerate. Both functions take a little less than 50% of the CPU cycles of try_fold, so we know that try_fold itself is not interesting, but instead the two functions it calls are! BufRead::read_line makes sense, this is the function that is called to get the next line in the text-file that crap is searching in. So already we have gained a valuable piece of information: About half of the 622 million CPU cycles of our program are spent in reading a file line-by-line. This is also what the percentage number in the 'Weight' column tells us: 47.0% of the CPU cycles of the program are spent in the BufRead::read_line function. Another 46.9% are spent in this enumerate function.
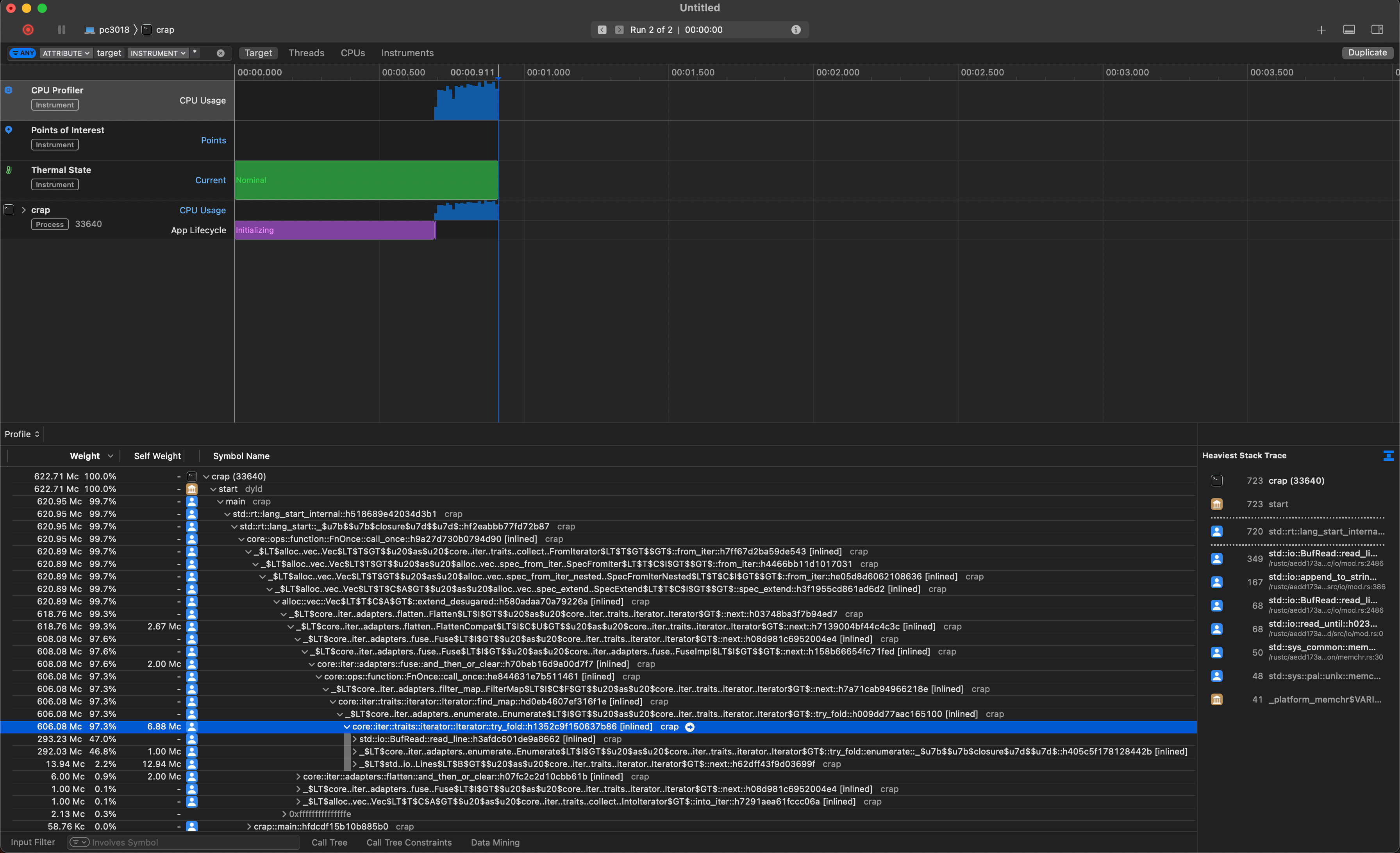
We now have a choice: Both BufRead::read_line and enumerate are responsible for about half of the program execution time each. Let's drill deeper into enumerate to understand this function. We might end up with a call tree like this:
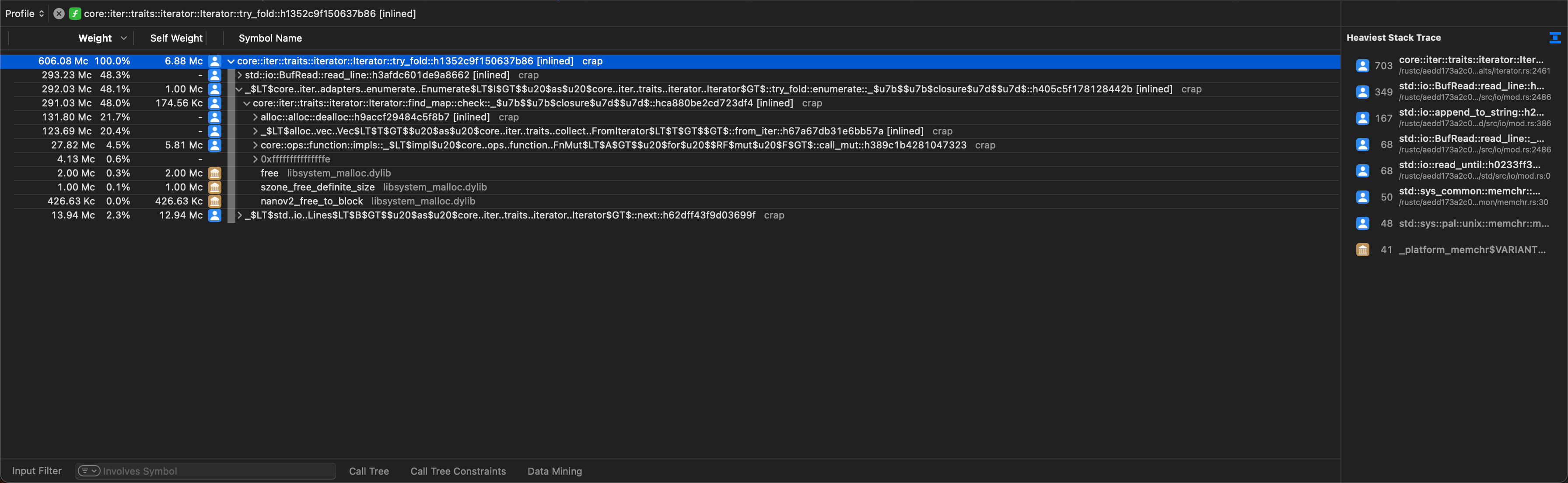
Here we find two functions that are interesting: alloc::alloc::dealloc and the hard to read _$LT$alloc..vec..Vec$LT$T$GT$$u20$as$u20$core..iter..traits..collect..FromIterator$LT$T$GT$$GT$::from_iter, which we might parse as a call to collect::<Vec<_>>. The first function is interesting, as it again takes about half of the time of its parent function. 50% of enumerate goes to the deallocation of some memory? Understanding what exactly gets deallocated can be tricky, because we never see any stack traces pointing into our own code. Notice all the [inlined] labels at the end of each entry in the call tree? The compiler performed quite a lot of inlining, which improves performance but makes it harder to track the source of our function calls, since they are not actually function calls anymore. It helps to look at our code and trying to understand which variables contain dynamic memory allocations. A deallocation will typically happen when one of these variables goes out of scope. All the relevant code happens inside the function we pass to filter_map:
filter_map(|(line_number: usize, line: Result<String, std::io::Error>)| -> Option<Vec<Match>> { let line: String = line.ok()?; let matches: Vec<Match> = regex .find_iter(line.as_str()) .map(|m| { // Extract information about match Match { ... } }) .collect(); Some(matches) })
Adding some type annotations makes it clearer to see what goes on here. Within the closure, we have three types that manage dynamic memory allocations:
lineis aStringmatchesis aVec- Each entry in
matchesis aMatchobject, which has a fieldcontext: String
Since we return the Vec<Match> from this function, neither the vector nor the Match objects will be cleaned up at the end of the function. Which leaves only the line variable, which indeed goes out of scope, causing the String to be deallocated. So a quarter of the runtime of our program is spent for deallocating strings. Quite surprising, isn't it?
Reasoning based on profiler results
Now it is time to take a step back and process the information that we obtained by profiling our crap executable with Instruments. We saw that we could drill down quite easily through the call stack in our code and figure out which function takes how many CPU cycles. We ended up at the realization that a lot of time seems to be spent on deallocating String instances. From here, we are on our own, the work of the profiler is done (for now) and we have to understand how these numbers relate to our program.
During the development of crap, it is unlikely that we ever thought 'And with this piece of code, I want to deallocate a lot of Strings!' As it is more often the case, especially when using a programming language that has lots of abstractions, this is a byproduct of how we designed our code. Let's look at a (simplified) version of the search_file function again:
let file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; Ok(file .lines() .enumerate() .filter_map(|(line_number, line : Result<String, std::io::Error>)| -> Option<Vec<Match>> { let line = line.ok()?; let matches = regex .find_iter(line.as_str()) .map(|m| { // Omitted code that gets the context of the match, i.e. some characters around the matching word... Match { context: format!( "{}{}{}", ellipse_before, &line[context_start..context_end], ellipse_after ), line_number, position_in_line: m.start(), } }) .collect(); Some(matches) }) .flatten() .collect())
There are two locations where we are dealing with instances of the String type: The lines() function returns an iterator over Result<String, std::io::Error>, and we explicitly create a String for each match using format!, within the inner map() call. We already had a good reason to suspect that it is the line variable that gets cleaned up, and not the context field of the Match object that we create. To increase our certainty, we can do a bit of reasoning based on our data:
We know that the function passed to filter_map will be called one time for each line in the file, because we chain it to the file.lines() iterator. Within this function, we create one Match instance (with one context String) for each match of the pattern that we are searching for. What is the ratio of matches to lines? Two shell commands can help us here:
crap enwik8 Wikipedia | wc -l
cat enwik8 | wc -l
The first command counts the number of lines that crap outputs. Since crap prints each match in a separate line, this gives us the number of matches. The second command counts the number of lines in the enwik8 file. Here are the results:
crap enwik8 Wikipedia | wc -l
|> 2290
cat enwik8 | wc -l
|> 1128023
1.13 million lines versus 2290 matches. So unless each String in a match would be about 1000 times more expensive to deallocate than a String containing a line of the file, this is very strong evidence that the line strings are the culprit!
What we do with this information is up to us. We might start to think about whether we actually need each line as a full owning String, or if we couldn't use &str somewhere to reduce the overhead of allocating and deallocating all these String instances. From there we might figure out that a typical line in a text file is often not very long, a few hundred characters at the most, but in our example we have a very large number of lines, meaning lots of Strings get created and destroyed. So that might be an area for optimization. Most importantly, however, is the fact that using a profiler gave us the necessary information to figure out that we spend a lot of time in our program with the (de)allocation of String values. That is the power of a profiler: It gathers a lot of information and gives us the right tools to dig deep into our code, until we find the pieces of code that take the most CPU cycles or the longest time.
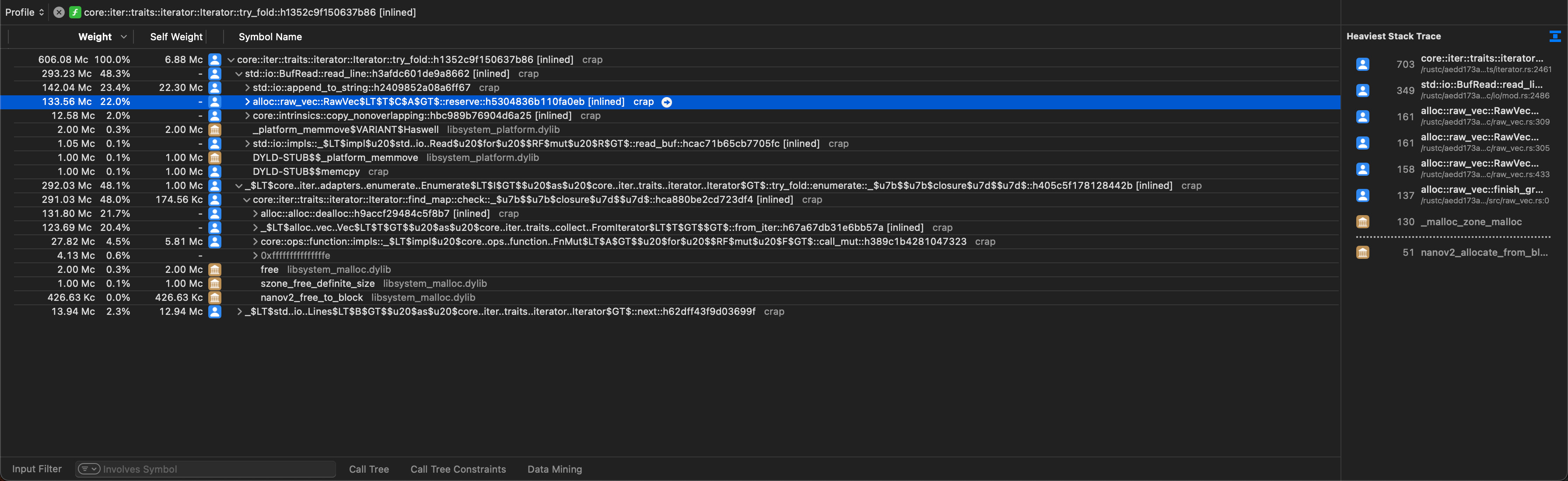
One closing remark regarding our investigation: We never checked the BufRead::read_line function, but we can now strongly suspect that there will be a lot of time spent on allocations as well, maybe even as much time as is spent on deallocating the line strings. Indeed this is what we will find:
An example optimization for crap
We will look at one potential optimization for crap based on the data we gathered, so you will get a feel for how profiler-guided optimization works.
Based on the data, our main goal is to get rid of the large number of allocations. Instead of allocating a new String for each line, we can pre-allocate one String that acts as a line buffer and read each line into this buffer. This means replacing the call to file.lines() with an explicit loop and manual calls to file.read_line:
fn search_file_optimized(path: &Path, pattern: &str) -> Result<Vec<Match>> { let mut file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; let mut line = String::with_capacity(1024); let mut matches = vec![]; let mut line_number = 0; while let Ok(count) = file.read_line(&mut line) { if count == 0 { break; } line_number += 1; // Get matches in line for match_within_line in regex.find_iter(line.as_str()) { // Extract data for match. Code is identical to before matches.push(Match { ... }); } // Clear line for next iteration line.clear(); } Ok(matches) }
We pre-allocate some memory for our line buffer. How much memory is up to us, if we allocate too little the read_line function will grow our string as needed. We go with 1KiB here, but you can experiment with this value and see if it makes a difference. Then we read the file line by line through file.read_line(&mut line), at which point the data for the current line is stored in line. Match extraction works like before, nothing fancy going on there. At the end of our loop body, we have to make sure that we clear the contents of the line buffer, otherwise the next line would be appended to the end of the buffer.
To make sure that this is a good optimization, we have to measure again! First, let's measure the runtime:
time crap enwik8 Wikipedia
|> 0.10s user 0.03s system 74% cpu 0.170 total
From 316ms down to 170ms, even lower than ripgrep! Of course we have to measure multiple times to get statistically relevant results. But we can also profile again and see where most of the runtime is spent now!
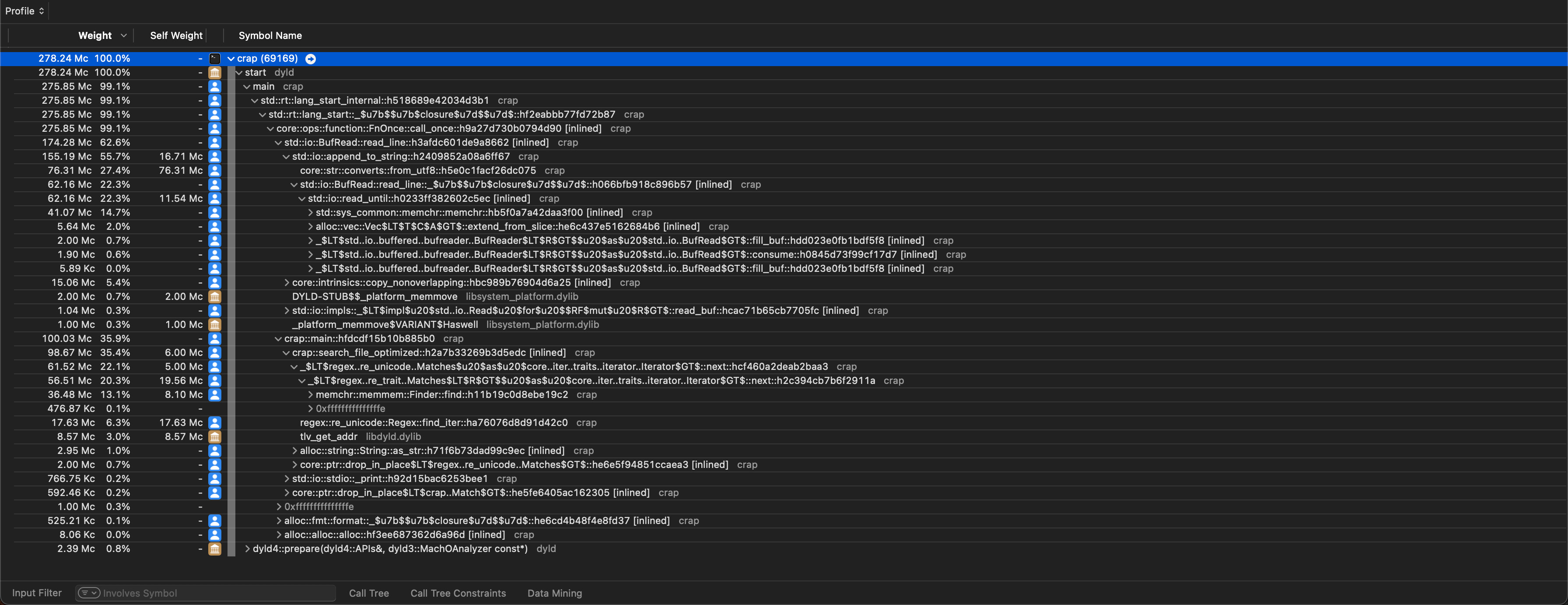
Here is a list of things that you might notice based on the new data, which can serve as a starting point for further optimizations:
- About 63% of the runtime is spent in
BufReader::read_line, which is a larger relative proportion than before, but lower absolute cycles (174M now vs. 293M before)- Almost all time is spent in
append_to_string, so appending the line data to our line buffer string- About 50% of that time is spent validating that the string is valid UTF-8 (
core::str::from_utf8) - 40% of that time is spent reading the actual data until the end of the line. Finding the end of the line is done using the
memchrcrate and takes about 25% of the total time ofappend_to_string
- About 50% of that time is spent validating that the string is valid UTF-8 (
- Almost all time is spent in
- The remaining runtime is spent in the
regexcrate, which finds the actual matches
hyperfine - A better alternative to time
We will conclude this section on benchmarking and profiling by introducing one last tool: hyperfine. hyperfine provides statistical benchmarking for command line applications and is thus similar to criterion which provided statistical benchmarking of Rust functions. The reasons for using a statistical benchmarking tool on the command line are the same as for benchmarking individual functions: It catches fluctuations in systems performance and provides a more reliable way of analyzing performance.
Of the many features that hyperfine provides, we will look at three: The default mode, warmup runs, and preparation commands.
The default invocation of hyperfine to benchmark our (optimized) crap executable looks like this:
hyperfine 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 131.3 ms ± 8.3 ms [User: 92.1 ms, System: 25.9 ms]
|> Range (min … max): 99.1 ms … 134.9 ms 21 runs
|>
|> Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
hyperfine executes the given command multiple times and performs a statistical analysis on the program runtime. We see the mean runtime and its standard deviation (131.3 ms ± 8.3 ms), a breakdown between time spent in user space and kernel space ([User: 92.1 ms, System: 25.9 ms]), the minimum and maximum recorded runtime (99.1 ms … 134.9 ms), and how many runs hyperfine performed (21).
hyperfine also prints a warning message that it found statistical outliers. In this case this happened because the disk cache was cleared prior to the call to hyperfine. crap is a very I/O heavy tool and benefits a lot from data being cached in the disk cache. If it is not, the first run might be a lot slower than successive runs (for which data will now be in the cache). hyperfine suggests two remedies for this: Warmup runs, or prepare commands.
Warmup runs introduce a small number of program executions for 'warming up' caches. After these runs have been executed, the actual benchmarking runs start. If your program accesses the same data (which in the case of our crap invocation it does), this will guarantee that this data is probably in the cache and subsequent runs all operate on cached data. This should keep fluctuations in the runtime due to caching effects to a minimum.
Prepare commands on the other hand execute a specific command or set of commands prior to every run of the benchmarked program. This allows manual preparation of the necessary environment for the program. Where warmup runs are helpful to ensure warm caches, prepare commands can be used to manually clear caches before every program run.
Running with warmup runs is as simple as this:
hyperfine --warmup 3 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 126.8 ms ± 0.3 ms [User: 93.3 ms, System: 25.5 ms]
|> Range (min … max): 126.4 ms … 127.4 ms 20 runs
Compared to our initial invocation of hyperfine, warmup runs drastically reduced the runtime fluctuations from 8.3ms (~6%) down to 0.3ms (~0.2%).
If we want to benchmark how crap behaves on a cold cache, we can use a prepare command that empties the disk cache prior to every run. This depends on the OS that we run on, for Linux it is typically sync; echo 3 | sudo tee /proc/sys/vm/drop_caches, on macOS you will use sync && purge:
hyperfine -p 'sync && purge' 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 505.7 ms ± 183.3 ms [User: 92.5 ms, System: 56.4 ms]
|> Range (min … max): 328.4 ms … 968.7 ms 10 runs
Here we notice much higher runtimes and runtime fluctuations, which are to be expected when interacting with I/O devices like the disk.
This leaves us with an interesting question: Should we benchmark with a cold cache or hot cache? Which scenario more closely represents the actual runtime characteristics of our program? The answer to this question depends on the way the program is typically used. For a pattern searcher such as crap, it is reasonable to assume that the same files will be searched repeatedly, in which case the hot cache performance would more closely resemble the actual user experience. Other tools might operate on rarely used files, in which case cold cache performance will be more relevant.
Summary
In this section we learned about ways for measuring performance through benchmarking and profiling. The former is good for isolated functions and small pieces of code, is easy to set up, but does not give very detailed information. If we want to understand how larger programs function and want to understand which parts of the program affect performance in which way, profilers are the way to go.