Applied concurrent programming in Rust using the rayon and crossbeam crates
Time to take our newly acquired knowledge of concurrent programming in Rust to the next level! In this chapter, we will learn about two useful crates called crossbeam and rayon, which will help us to write better concurrent code. Let's dive right in!
Scoped threads
Recall from the previous chapter that the threads from the Rust standard library required all borrows to have 'static lifetime? This forced us to use the thread-safe multi-ownership smart pointer type Arc<T>, so that each thread could take ownership of shared data. But we already suspected that this requirement is overly strict! Look at the following code:
fn main() { let text = format!("Current time: {:?}", std::time::SystemTime::now()); let text_borrow = text.as_str(); let join_handle = std::thread::spawn(move || { println!("Thread: {}", text_borrow); }); join_handle.join().unwrap(); println!("Main thread: {}", text); }
This code fails to compile with the error 'text' does not live long enough [...] requires that 'text' is borrowed for 'static. But both the thread and the text variable have the same lifetime, because we join with the thread from within main! This is a nuisance: We as developers know that our code is correct, but the Rust standard library is preventing us from writing this code. This is made even worse by the fact that the 'intended' solution (using Arc<Mutex<String>>) has worse performance than our 'borrow-only' solution!
What we would like is a thread that obeys the scope that it is launched from, so that the thread function only has to be valid for the lifetime of that scope. This is exactly what the crossbeam crate offers!
crossbeam contains a bunch of utilities for writing concurrent Rust code, for our purposes we will need the crossbeam::scope method. With scope, we get access to a special Scope type that lets us spawn threads that live only as long as the Scope. The Scope type has a function spawn which looks similar to std::thread::spawn, but with different lifetime requirements:
#![allow(unused)] fn main() { pub fn spawn<F, T>(&'scope self, f: F) -> ScopedJoinHandle<'scope, T> where T: Send + 'env, F: FnOnce(&Scope<'env>) -> T + Send + 'env }
All we care about for now is the 'env lifetime, which is the lifetime of the Scope type that we get from calling the crossbeam::scope function. Putting the two functions together, we can rewrite our initial code like this:
fn main() { let text = format!("Current time: {:?}", std::time::SystemTime::now()); let text_borrow = text.as_str(); crossbeam::scope(|scope| { scope.spawn(|_| { println!("Thread: {}", text_borrow); }) .join() .unwrap(); }) .unwrap(); println!("Main thread: {}", text); }
Notice that the crossbeam::scope function accepts another function and passes the Scope instance to this function. Only from within this function is the Scope valid, so we have to put all our code that launches threads inside this function. This is a bit of Rust gymnastics to make sure that all lifetimes are obeyed. In particular, since the Scope is created from within the crossbeam::scope function, which itself is called from main, the lifetime of the Scope will never exceed that of the main function, which allows us to use borrows from the stack frame of main inside the threads spawned from the Scope. Neat!
Let's take the DNA editing example from the previous chapter and rewrite it using crossbeam:
#![allow(unused)] fn main() { fn dna_editing_crossbeam( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], parallelism: usize, ) { if old_sequence.len() != new_sequence.len() { panic!("old_sequence and new_sequence must have the same length"); } crossbeam::scope(|scope| { let chunk_size = (source.len() + parallelism - 1) / parallelism; let chunks = source.chunks_mut(chunk_size).collect::<Vec<_>>(); for chunk in chunks { scope.spawn(move |_| dna_editing_sequential(chunk, old_sequence, new_sequence)); } }) .unwrap(); } }
Not only is this code a lot simpler than the code we had previously, it also runs much faster! We have zero copying of our source data, and because we can now use borrows together with chunks_mut, each thread only has access to its own unique slice of source. Using 12 threads, this code runs about 10 times faster than the sequential code on the tested system. Another useful side-effect of using the crossbeam::scope function is that we don't have to explicitly join with our spawned threads, crossbeam does this automatically for us once the scope gets destroyed!
Channels
Up until now, we only worked with the fork-join concurrent programming model. This model works well if we have all data that is to be processed available, so that we can split the data up into chunks and process them in parallel. We don't always have a problem where we have all data available upfront. In addition, spinning up a thread everytime we fork our data might introduce unnecessary overhead, especially if the amount of data processed per thread is small. To grow our concurrent programming toolkit, we have to learn about a new concurrent programming model, called the message passing model.
Message passing is one of the most successful models for concurrent programming. In fact, we already used message passing in the chapter on network programming: Every client/server system works through exchanging messages, and client/server applications are inherently concurrent! Where we used a network connection to exchange messages between processes in the networking chapter, we can also exchange messages between threads running in the same process by using thread-safe queues. In Rust, they are called channels, and both the Rust standard library as well as crossbeam provide implementations for channels.
Good candidates for applying the message passing paradigm are producer/consumer problems. These are scenarios in which one or more producers of a certain piece of work exist, and one or more consumers that can process these work items. A real-world example would be a restaurant, where you have a bunch of customers that produce work for the kitchen (by ordering food), and one or more chefs in the kitchen which work on the ordered food and thus consume the food requests. It also works in the other way of course, with the kitchen being the producer and all customers being consumers.
For a more computer-friendly application, we will look at a program which checks numbers whether they are prime or not. The user can input numbers from the command line and a dedicated thread processes each number to figure out whether it is a prime number or not. Using a separate thread to do the heavy computations means that the main thread is always free to handle user input and text output. This is a good thing, because the user will never see the program hang on a long-running computation! In this scenario, the user is the producer and the thread is the consumer. Let's implement this:
fn main() { let (sender, receiver) = std::sync::mpsc::channel(); let consumer_handle = consumer(receiver); producer(sender); consumer_handle.join(); }
The main function is simple and illustrates the producer/consumer nature of our application. To handle the communication between producer and consumer, we are using the aforementioned channel, in this case the one provided by the Rust standard library. Every channel has two ends: A sending end and a receiving end, represented by the two variables sender (of type Sender<T>) and receiver (of type Receiver<T>) in the code. The channel itself handles all synchronization so that one thread can send arbitrary data to another thread without any data races. Let's see how we can produce values:
#![allow(unused)] fn main() { fn producer(sender: Sender<u64>) { loop { let mut command = String::new(); println!("Enter number:"); std::io::stdin().read_line(&mut command).unwrap(); let trimmed = command.trim(); match trimmed { "quit" => break, _ => match trimmed.parse::<u64>() { Ok(number) => { sender.send(number).unwrap(); } Err(why) => eprintln!("Invalid command ({})", why), }, } } } }
Although this function looks a bit messy, all that it does is read in a line from the command line and interpret it either as a number, or as the quit command, which will exit the program. The important line is right here: sender.send(number).unwrap(). Here, we send the number to be checked through the channel to the consumer. Since a channel has two ends, we can't be sure that the other end of the channel is still alive (the corresponding thread might have exited for example). For this reason, send returns a Result, which we handle quite ungracefully here.
The consumer is more interesting:
#![allow(unused)] fn main() { fn consumer(receiver: Receiver<u64>) -> JoinHandle<()> { std::thread::spawn(move || { while let Ok(number) = receiver.recv() { let number_is_prime = is_prime(number); let prime_text = if number_is_prime { "is" } else { "is not" }; println!("{} {} prime", number, prime_text); } }) } }
We launch a new thread and move the receiving end of the channel onto this thread. There, we call the recv function on the channel, which will return the next value in the channel if it exists, or block until a value is put into the channel by the producer. Just as the sender, the receiver also has no way of knowing whether the other end of the channel is still alive, so recv also returns a Result. And just like that, we have established a message-passing system between the main thread and our consumer thread! If we run this program and put in a large prime number, we will see that our program does not hang, but it takes some time until the answer comes in. We can even have multiple potential prime numbers in flight at the same time:
Enter number:
2147483647
Enter number:
1334
Enter number:
2147483647 is prime
1334 is not prime
You might have noticed the weird module name that we pulled the channel from: mpsc. mpsc is shorthand for 'multi-producer, single-consumer', which describes the scenario that this type of channel can be used for. We can have multiple producers, but only one consumer. Consequently, the Sender<T> type that channel() returns implements Clone so that we can have multiple threads send data to the same channel. The Receiver<T> type however is not clonable, because we can have at most one receiver (consumer). What if we want this though? In our prime-checker example, it might make sense to have multiple consumer threads to make good usage of the CPU cores in our machine. Here, the crossbeam crate has the right type for us: crossbeam::channel::unbounded creates a multi-producer, multi-consumer channel with unlimited capacity. With this, we can have as many consumers as we want, because the corresponding Receiver<T> type also implements Clone. The channel itself will store an unlimited amount of data that is sent but not yet received, if we don't want this and instead want senders to block at a certain point, we can use crossbeam::channel::bounded instead.
Message-passing is a good alternative to explicitly synchronizing data between threads, and Rust gives us several easy-to-use tools to implement message-passing. This pattern is so popular for concurrent programming that another systems programming language called Go has channels as a built-in language feature. In Go, one very popular piece of advice goes like this: Do not communicate by sharing memory; instead, share memory by communicating{{#cite effectiveGo}}.
Parallel iterators using rayon
The last practical application of concurrency in Rust that we will look at are parallel iterators. Sometimes, it is useful to take an existing iterator and process it concurrently, for example on multiple threads at once. This is closely related to the fork/join pattern that we used in the previous chapter, but instead of having an array that we split up into chunks to process on threads, why not use the more general iterator abstraction and process each element of the iterator on a different thread? The advantage of this would be that we can take sequential code that uses iterators and parallelize it easily by switching to a 'thread-based iterator'. This is exactly what the rayon crate offers!
Let's take our string search algorithm from the previous chapter and implement it in parallel using rayon! To get access to all the cool features that rayon provides, we typically start with a use rayon::prelude::*; statement, which imports all necessary types for parallel iterators. Then, the actual implementation of a parallel string search algorithm is very simple:
#![allow(unused)] fn main() { fn search_parallel_rayon(text: &str, keyword: &str, parallelism: usize) -> usize { let chunks = chunk_string_at_whitespace(text, parallelism); chunks .par_iter() .map(|chunk| search_sequential(chunk, keyword)) .sum() } }
The only difference to a sequential implementation is that we are using the par_iter() function that rayon provides, which returns a parallel iterator instead of a sequential iterator. Internally, rayon uses a bunch of threads that process the elements of parallel iterators, but we don't have to spawn those threads ourselves. rayon provides a lot of the iterator algorithms that we saw in chapter 4.3, but they execute in parallel! This is very helpful, because figuring out how to correctly and efficiently parallelize these algorithms can be tough.
Let's try to understand rayon a bit better. Somehow, rayon is creating an appropriate number of threads in the background to handle the parallel iterators on. How does rayon know how many threads to create? If the iterator comes from a container that has a known size, i.e. the iterator implements ExactSizeIterator, then we know upfront how many items there are, but in all other cases the length of the iterator is unknown. And does it even make sense to create more threads than there are CPU cores in the current machine? If there are 8 cores and 8 threads that run instructions at full speed, then adding more threads doesn't magically give us more CPU power.
Looking back at our application of the fork/join pattern, what did we actually do if we had more items to be processed than CPU cores? Instead of creating more threads, we grouped the items into a number of equally-sized chunks, equal to the number of CPU cores. Then, we moved each chunk onto a thread and processed it there. Now suppose that we don't know how many items we have and thus can't create an appropriate number of chunks, because we don't know the chunk size. What if we could move items onto threads one at a time? Then it doesn't matter how many items we have, we can move each item onto a thread one-by-one, moving through the threads in a round-robin fashion:
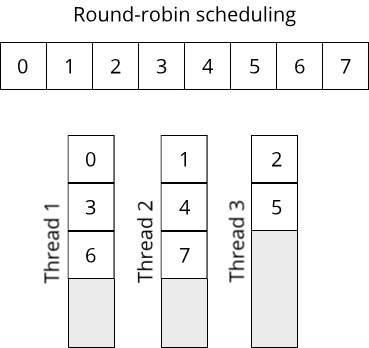
This requires that our threads have the ability to wait for new items, but we already saw that this is achieved easily by using channels. Whenever we have a bunch of active threads that are waiting for data to be processed, we call this a thread pool (or task pool). This is exactly what rayon is using under the hood to do all parallel processing. Since rayon is a library aimed at data parallelism (the fork/join pattern is an example of data parallelism), it focuses on data-intensive parallel computations. If we map such computations onto threads, we typically assume that one thread is able to saturate one CPU core, which means that it executes instructions at or near its maximum speed. The internal thread pool that rayon uses thus has one thread per CPU core running and waiting for work. If we look into the documentation of rayon, we see that it also offers some configuration options to create a thread pool ourselves using a ThreadPoolBuilder type.
Conclusion
In this chapter we looked at some useful crates and patterns that make concurrent programming easier in Rust. We can overcome the lifetime problems by using the scoped threads that the crossbeam crate offers. If we can't use fork/join, we can use message passing for which both the Rust standard library and crossbeam provide channels that can send data between threads. Lastly, we saw that we can use the rayon crate to turn code using regular iterators into parallel code through parallel iterators.