Preface
This book serves as the script for the lecture 'Advanced Systems Programming' taught at the University of Applied Sciences in Darmstadt. 'Advanced Systems Programming' is part of the curriculum of the computer science bachelor degree course. It is aimed at undergrad students in their last couple of semesters and is an optional course. Prerequisites are the basic 'Introduction to Programming' courses (PAD1&2) as well as the introductory course on operating systems (Betriebssysteme).
What is Advanced Systems Programming about?
The main focus of the Advanced Systems Programming course and this book is to teach you how to develop systems software using a modern programming language (Rust). Within this course, you will learn the basics of what systems programming is with many hands-on examples and exercises to get them familiar with the modern systems programming language Rust. You are expected to have basic knowledge of C++, so one of the cornerstones of this course is the continuous comparison of common aspects of systems software in the C++-World and the Rust-World. These aspects include:
- Data (memory and files, ownership)
- Runtime performance (zero-overhead abstractions, what makes C++ & Rust fast or slow?)
- Error Handling
- Communication between processes and applications
- Concurrency as a basic building block of systems software
- The development ecosystem, specifically Rust's
cargoand how it unifies compilation, deployment, configuration, testing, benchmarking etc.
For students taking the ASP course, hands-on experience with these topics is gained in the extended lab part, where they will implement the learned aspects within real systems software. In the first part of the lab, this is done through a series of exercises, which include translating concepts from C++ code to the Rust world and extending small programs with new features. The second part of the lab will be a larger project in which students will implement a system of their choice (for example a web-server, game-engine, or a compiler for a scripting language) using the concepts that they have learned in this course. All lab sessions will also include a small analysis of an existing piece of (open-source) software. This way, students will familiarize themselves with reading foreign code and will get experience from real-world code.
What is Advanced Systems Programming not about?
Systems programming is a very large discipline that covers areas from all over the computer science field. As such, many of the concepts that you will learn and use in this course might warrant a course on their own (and sometimes already have a course on their own). As such, Advanced Systems Programming is not a course that goes into the cutting edge research of how to write blazing fast code on a supercomputer or writing an operating system from scratch. While this course does cover many details that are relevant to systems programming, it is much more focused on the big picture than a deep-dive into high-performance software.
Additionally, while this course uses Rust as its main programming language, it will not cover all features that Rust has to offer, nor will it teach all Rust concepts from the ground up in isolation. Rust is well known for its outstanding documentation and you are expected to use this documentation, in particular the Rust book, to extend your knowledge of Rust beyond what is covered in this course. This course also is not a tutorial on how to use Rust. You will learn systems programming using Rust, but Rust as a general-purpose language has many more areas of application than just systems programming. A lot of focus on the practical aspects of using the Rust language will be put in the lab part of this course, as it is the authors firm believe that one learns programming by doing, and not so much by reading.
How to use this book?
This book is meant to be used as the backing material for the lecture series. In principle, all information covered in the lectures can be found within this book (disregarding spontaneous disussions and questions that might arise during a lecture). Depending on your learning style, this book can serve as a reference for the things discussed in the lecture, or can be used for self-study. It does not replace participation in the lab part of the course. Gaining hands-on experience is at the core of this lecture series, so attendence of the lab is mandatory.
Besides a lot of text, throughout this book you will find several exercises, which range from conceptual questions to small programming tasks. These exercises are meant to recap the learned material and sometimes to do some further research on your own. With an exception to the open-ended questions, all exercises do provide solutions hidden behind a collapsible UI element, like so:
Additionally, this book contains many code examples, which look like this:
fn main() { println!("Hello Rust"); }
Whenever applicable, you can run the code example using the play button on the top-right of the code panel. Rust code is run using the Rust playground.
Supplementary material
This book comes with lots of code examples throughout the text. In addition, the following text-books are a good start for diving into the concepts taught in this course:
- Bryant, Randal E., O'Hallaron David Richard, and O'Hallaron David Richard. Computer systems: a programmer's perspective. Vol. 2. Upper Saddle River: Prentice Hall, 2003. {{#cite Bryant03}}
- Klabnik, Steve, and Carol Nichols. The Rust Programming Language (Covers Rust 2018). No Starch Press, 2019. {{#cite Klabnik19}}
- Also available online: https://doc.rust-lang.org/book/
- Stroustrup, Bjarne. "The C++ programming language." (2013). {{#cite Stroustrup00}}
An comprehensive list of references can be found at the end of this book.
1. Introduction to Systems Programming
In this chapter, we will understand what Systems Programming is all about. We will get an understanding of the main concepts that make a piece of software 'systems software' and which programming language features help in developing systems software. We will classify programming languages by their ability to be used in systems programming and will take a first look at a modern systems programming language called Rust.
1.1 What is systems programming?
The term systems programming is a somewhat losely defined term for which several definitions can be found. Here are some definitions from the literature:
- "writing code that directly uses hardware resources, has serious resource constraints, or closely interacts with code that does" ("The C++ programming language", Stroustrup)
- "“systems-level” work [...] deals with low-level details of memory management, data representation, and concurrency" ("The Rust Programming Language", Steve Klabnik and Carol Nichols)
- "a systems programming language is used to construct software systems that control underlying computer hardware and to provide software platforms that are used by higher level application programming languages used to build applications and services" (from a panel on systems programming at the Lang.NEXT 2014 conference)
- "Applications software comprises programs designed for an end user, such as word processors, database systems, and spreadsheet programs. Systems software includes compilers, loaders, linkers, and debuggers." (Vangie Beal, from a 1996 blog post)
From these definitions, we can see that a couple of aspects seem to be important in systems programming:
- Systems programming interacts closely with the hardware
- Systems programming is concerned with writing efficient software
- Systems software is software that is used by other software, as opposed to applications software, which is used by the end-user
These definitions are still a bit ambiguous, especially the third one. Take a database as an example: A user might interact with a database to store and retrieve their data manually. At the same time, a database might be accessed from other software, such as the backend of a web-application. Most databases are developed with efficiency and performance in mind, so that they can perform well even under high load and with billions of entries. Is a database an application or systems software then?
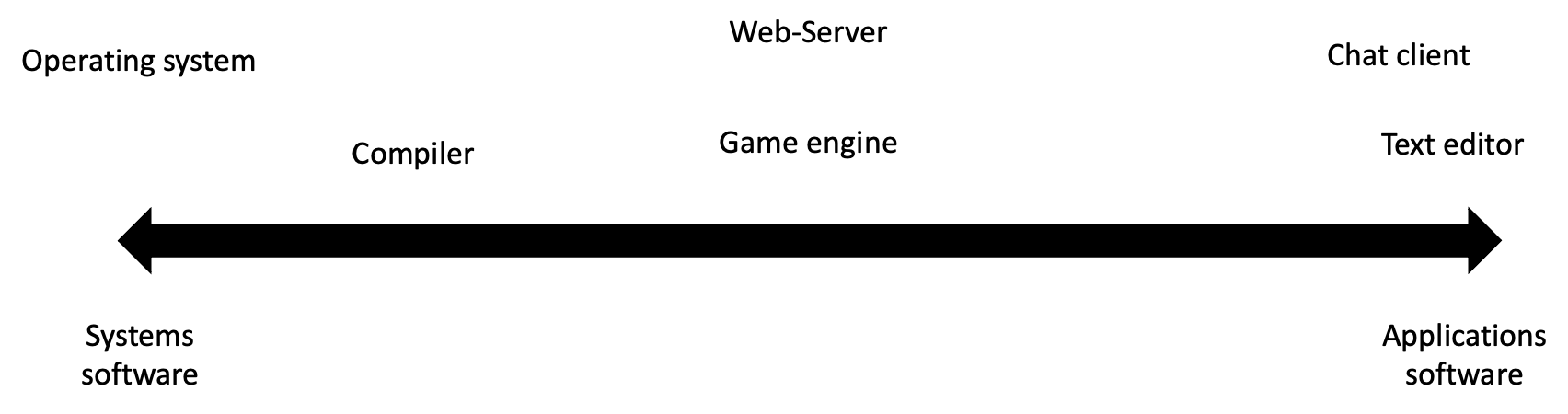
For this course, instead of seeing systems programming and application programming as two disjunct domains, we will instead think of them as two ends of a spectrum. We will see that most software falls somewhere on this spectrum, with aspects from systems programming and aspects from application programming. For the sake of completeness, here are some types of software that will be considered systems software in the context of this course:
- Operating systems (perhaps the prime example of systems software. It even has system in the name!)
- Web-Servers
- Compilers and Debuggers
- Game Engines
🔤 Exercise 1.1.1
Take a look at the software running on your computer. Pick 5 programs and put them onto the systems programming/application programming scale. Justify your decisions using the criteria for systems programming that you learned in this section.
💡 Need help? Click here
| Software | Systems Programming (0) vs. Applications Programming (5) | Reasons |
|---|---|---|
| Browser | 2 | High performance and security demands, needs to run JavaScript code (and potentially WASM, WebGL etc.) |
| Terminal | 3 | Seems low-level, but most of the heavy lifting is done by the OS, making the terminal more of a GUI for typing commands and displaying text |
| Mail Client | 5 | Not particularily resource-constrained, needs to make some network calls and maybe uses a database internally, but mostly this is a user-facing GUI application |
systemd (on Linux) | 0 | Its main purpose is to control other software, and it interacts closely with the OS |
| IDE (e.g. VS Code) | 4 | A fancy text editor that acts as a GUI for all the actual development components (compiler, linker etc.) |
1.2 How do we write systems software?
To write software, we use programming languages. From the multitude of programming languages in use today, you will find that not every programming language is equally well suited for writing the same types of software. A language such as JavaScript might be more suited for writing client-facing software and can thus be considered an application programming language. In contrast, a language like C, which provides access to the underlying hardware, will be more suited for writing systems software and thus can be considered a systems programming language. In practice, most modern languages can be used for a multitude of tasks, which is why you will often find the term general-purpose programming language being used.
An important aspect that makes some languages ill-suited for writing systems software under our definition is the ability to access the computers hardware resources directly. Examples of hardware resources are:
- Memory (working memory and disk memory)
- CPU cycles (both on a single logical core and on multiple logical cores)
- Network throughput
- GPU (Graphics Processing Unit) cycles
Based on these hardware resources, we can classify programming languages by their ability to directly manage access to these resources. This leads us to the often-used terms of low-level and high-level programming languages. Again, there is no clear definition of what constitutes a low-level or high-level programming language, and indeed the usage of these terms has changed over the last decades. Here are two ways of defining these terms:
- Definition 1) The level of a programming language describes the level of abstraction over a machines underlying hardware architecture
- Definition 2) A low-level programming language gives the programmer direct access to hardware resources, a high-level programming language hides these details from the programmer
Both definitions are strongly related and deal with hardware and abstractions. In the context of computer science, abstraction refers to the process of hiding information in order to simplify interaction with a system (Colburn, T., Shute, G. Abstraction in Computer Science. Minds & Machines 17, 169–184 (2007). https://doi.org/10.1007/s11023-007-9061-7). Modern computers are extremely sophisticated, complex machines. Working with the actual hardware in full detail would include a massive amount of information that the programmer needs to know about the underlying system, making even simple tasks very time-consuming. All modern languages, even the ones that can be considered fairly low-level, thus use some form of abstraction over the underlying hardware. As abstraction is information hiding, there is the possibility of a loss of control when using abstractions. This can happen if the abstraction hides information necessary to achieve a specific task. Let's look at an example:
The Java programming language can be considered fairly high-level. It provides a unified abstraction of the systems hardware architecture called the Java Virtual Machine (JVM). One part of the JVM is concerned with providing the programmer access to working memory. It uses a high degree of abstraction: Memory can be allocated in a general manner by the programmer, unused memory is automatically detected and cleaned up through a garbage collector. This makes the process of allocating and using working memory quite simple in Java, but takes the possibility of specifying exactly where, when and how memory is allocated and released away from the user. The C programming language does not employ a garbage collector and instead requires the programmer to manually release all allocated memory once it is no longer used. Under this set of features and our two definitions of a programming language's level, we can consider Java a more high-level programming language than C.
Here is one more example to illustrate that this concept applies to other hardware resources as well:
The JavaScript programming language is an event-driven programming language. One of its main points of application is the development of client-side behaviour of web pages. Here, the JavaScript code is executed by another program (your browser), which controls the execution flow of the JavaScript program through something called an event-loop. Without going into detail on how this event-loop works, it enforces a sequential execution model for JavaScript code. This means that in pure JavaScript, no two pieces of code can be executed at the same time. Now take a look at the Java programming language. It provides a simple abstraction for running multiple pieces of code in parallel called a Thread. Through threads, the programmer effectively gains access to multiple CPU cores as a resource. In practice, many of the details are still managed by the JVM and the operating system, but given our initial definitions, we can consider JavaScript a more high-level programming language than Java.
Similar to our classification of software on a scale from systems to applications, we can put programming languages on a scale from low-level to high-level:
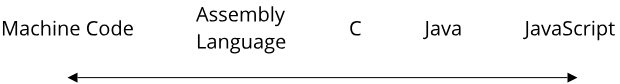
🔤 Exercise 1.2.1
Given the programming languages Python, C++, Haskell, Kotlin and Assembly language, sort them onto the scale from low-level to high-level programming languages. What can you say about the relationship between Kotlin and Java? How about the relationship between C and C++? Where would you put Haskell on this scale, and why?
💡 Need help? Click here
| Language | Low-level (0) vs. High-level (5) | Reasons |
|---|---|---|
| Python | 5 | Interpreted, dynamically typed, garbage collected (i.e. no manual memory management) |
| C++ | 2 (above C) | Compiled, statically typed, manual memory management. Syntactically more dense than C, but provides more abstractions, so a bit more high-level than C |
| Haskell | 5 (above Python) | Purely functional language with zero imperative programming constructs, making it very far removed from the actual hardware |
| Kotlin | 4 (above Java) | Runs on the JVM, so similar power to Java (i.e. limited manual memory management constructs), but incorporates more functional programming abstractions, making it more high-level than Java |
| Assembly Language | 1 | Almost as low-level as it gets, though there are undocumented CPU instructions not expressible in assembly language |
Now that we have learned about low-level and high-level programming languages, it becomes clear that more low-level programming languages will provide us with better means for writing good systems software that makes efficient use of hardware resources. At the same time, the most low-level programming languages will be missing some abstractions that we would like to have in order to make the process of writing systems software efficient. For the longest time, C and C++ thus were the two main programming languages used for writing systems software, which also shows in their popularity. These are powerful, very well established languages which, despite their considerable age (C being developed in the early 1970s, C++ in the mid 1980s), still continue to be relevant today. At the same time, over the last decade new systems programming languages have emerged, such as Rust and Go. These languages aim to improve some shortcomings of their predecessors, such as memory safety or simple concurrent programming, while at the same time maintaining a level of control over the hardware that makes them well-suited for systems programming.
This course takes the deliberate decision to focus on Rust as a modern systems programming language in contrast to a well-established language such as C++. While no one of the two languages is clearly superior to the other, Rust does adress some shortcomings in C++ in terms of memory safety and safe concurrent programming that can make writing good systems software easier. Rust also has gained a lot of popularity over the last couple of years, continuingly scoring as the most loved programming language in the StackOverflow programmers survey. In addition, Rust's excellent tooling makes it very well suited for a lecture series, as getting some Rust code up and running is very simple.
At the same time, this course assumes that the students are familiar with C++, as it will make continuous references to C++ features important in systems programming and compare them to Rust's approach on systems programming.
1.3 Systems programming features in a nutshell
In this course, we will learn the most important concepts when writing systems software and apply them to a series of real-world problems. The features covered in this book are:
- A general introduction to Rust and its concepts compared to C++ (Chapter 2)
- The fundamentals of memory management and memory safety (Chapter 3)
- Zero-overhead abstractions - Writing fast, readable and maintainable code (Chapter 4)
- Error handling - How to make systems software robust (Chapter 5)
- Systems level I/O - How to make systems talk to each other (Chapter 6)
- Fearless concurrency - Using compute resources effectively (Chapter 7)
- Performance - How to measure, evaluate and tweak systems performance (Chapter 8)
2. A general introduction to Rust and its concepts compared to C++
The Rust programming language is an ahead-of-time compiled, multi-paradigm programming language that is statically typed, uses borrow checking for enforcing memory safety and supports ad-hoc polymorphism through traits, among other features.
This definition is quite the mouthful of fancy words. In this chapter, we will try to understand the basics of what these features mean, why they are useful in systems programming, and how they relate to similar features present in C++. We will dive deeper into some of Rusts features in the later chapters, however we will always do so by keeping the systems programming aspect in mind. The Rust book does a fantastic job at teaching the Rust programming language in general, so refer to it whenever you want to know more about a specific Rust feature or are confused about a piece of syntax or a specific term.
Let's start unpacking the complicated statement above! There are several highlighted concepts in this sentence:
- ahead-of-time compiled
- multi-paradigm
- statically-typed
- borrow checking
- ad-hoc polymorphism
- traits
Over the next sections, we will look at each of these keywords together with code examples to understand what they mean and how they relate to systems programming.
2.1. Rust as an ahead-of-time compiled language
In this chapter, we will learn about compiled languages and why they are often used for systems programming. We will see that both Rust and C++ are what is known as ahead-of-time compiled languages. We will learn the benefits of ahead-of-time compilation, in particular in terms of program optimization, and also its drawbacks, specifically problems with cross-plattform development and the impact of long compilation times.
Programming languages were invented as a tool for developers to simplify the process of giving instructions to a computer. As such, a programming language can be seen as an abstraction over the actual machine that the code will be executed on. As we have seen in chapter 1.2, programming languages can be classified by their level of abstraction over the underlying hardware. Since ultimately, every program has to be executed on the actual hardware, and the hardware has a fixed set of instructions that it can execute, code written in a programming language has to be translated into hardware instructions at some point prior to execution. This process is known as compilation and the associated tools that perform this translation are called compilers. Any language whose code is executed directly on the underlying hardware is called a compiled languageThe exception to this are assembly languages, which are used to write raw machine instructions. Code in an assembly language is not compiled but rather assembled into an object file which your computer can execute..
At this point, one might wonder if it is possible to execute code on anything else but the underlying hardware of a computer system. To answer this question, it is worth doing a small detour into the domain of theoretical computer science, to gain a better understanding of what code actually is.
Detour - The birth of computer science and the nature of code
In the early 20th century, mathematicians were trying to understand the nature of computation. It had become quite clear that computation was some systematic process with a set of rules whose application enabled humans to solve certain kinds of problems. Basic arithmetic operations, such as addition, subtraction or multiplication, were known to be solvable through applying a set of operations by ancient Babylonian mathematicians. Over time, specific sets of operations for solving several popular problems became known, however it remained unclear whether any possible problem that can be stated mathematically could also be solved through applying a series of well-defined operations. In modern terms, this systematic application of a set of rules is known as an algorithm. The question that vexed early 20th century mathematicians could thus be simplified as:
"For every possible mathematical problem, does there exist an algorithm that solves this problem?"
Finding an answer to this question seems very rewarding. Just imagine for a moment that you were able to show that there exists a systematic set of rules that, when applied, gives you the answer to every possible (mathematical) problem. That does sound very intruiging, does it not?
The main challenge in answering this question was the formalization of what it means to 'solve a mathematical problem', which can be stated as the simple question:
"What is computation?"
In the 1930s, several independent results were published which tried to give an answer to this question. Perhaps the most famous one was given by Alan Turing in 1936 with what is now know as a Turing machine. Turing was able to formalize the process of computation by breaking it down to a series of very simple instructions operating on an abstract machine. A Turing machine can be pictured as an infinitely long tape with a writing head that can manipulate symbols on the tape. The symbols are stored in cells on the tape and the writing head always reads the symbol at the current cell. Based on the current symbol, the writing head writes a specific symbol to the current cell, then moves one step to the left or right. Turing was able to show that this outstandingly simple machine is able to perform any calculation that could be performed by a human on paper or any other arbitrarily complex machine. This statement is now known as the Church-Turing thesis.
So how is this relevant to todays computers, programming languages and systems programming? Turing introduced two important concepts: A set of instructions ("code") to be executed on an abstract machine ("computer"). This definition holds until today, where we refer to code as simply any set of instructions that can be executed on some abstract machine.
It pays off to think about what might constitute such an 'abstract computing machine'. Processors of course come to mind, as they are what we use to run our instructions on. However, humans can also be considered as 'abstract computing machines' in a sense. Whenever we are doing calculations by hand, we apply the same principal of systematic execution of instructions. Indeed, the term computer historically refered to people carrying out computations by hand.
Interpreted languages
Armed with our new knowledge about the history of computers and code, we can now answer our initial question: Is it possible to execute code on anything else but the underlying hardware of a computer system? We already gave the answer in the previous section where we saw that there are many different types of abstract machines that can carry out instructions. From a programmers point of view, there is one category of abstract machine that is worth closer investigation, which is that of emulation.
Consider a C++ program that simulates the rules of a Turing machine. It takes a string of input characters, maybe through the command line, and applies the rules of a Turing machine to this input. This program itself can now be seen as a new abstract machine executing instructions. Instead of executing the rules of a Turing machine on a real physical Turing machine, the rules are executed on the processors of your computer. Your computer thus emulates a Turing machine. Through emulation, computer programs can themselves become abstract machines that can execute instructions. There is a whole category of programming languages that utilize this principle, called interpreted programming languagesWhy interpreted and not emulated? Read on!.
In an interpreted programming language, code is fed to an interpreter, which is a program that parses the code and executes the relevant instructions on the fly. This has some advantages over compiled languages, in particular independence of the underlying hardware and the ability to immediately execute code without waiting on a possibly time-consuming compilation process. At the same time, interpreted languages are often significantly slower than compiled languages because of the overhead of the interpreter and less potential for optimizing the written code ahead of time.
As we have seen, many concepts in computer science are not as binary (pun intended) as they first appear. The concept of interpreted vs. compiled languages is no different: There are interpreted languages which still use a form of compilation to first convert the code into an optimized format for the interpreter, as well as languages which defer the compilation process to the runtime in a process called just-in-time compilation (JIT).
Why ahead-of-time compiled languages are great for systems programming
As one of the main goals of systems programming is to write software that makes efficient use of computer resources, most systems programming is typically done with ahead-of-time compiled languages. There are two reasons for this:
- First, ahead-of-time compiled languages get translated into machine code for specific hardware architectures. This removes any overhead of potential interpretation of code, as the code runs 'close to the metal', i.e. directly on the underlying hardware.
- Second, ahead-of-time compilation enables automatic program optimization through a compiler. Modern compilers are very sophisticated programs that know the innards of various hardware architectures and thus can perform a wide range of optimizations that can make the code substantially faster than what was written by the programmer.
- A third benefit that is related to ahead-of-time compilation is that we can perform correctness checks on the program, more on that in chapter 2.4
This second part - program optimization through the compiler - plays a big role in systems programming. Of course we want our code to be as efficient as possible, however depending on the way we write our code, we might prevent the compiler from applying optimizations that it otherwise could apply. Understanding what typical optimizations are will help us understand how we can write code that is more favorable for the compiler to optimize.
We will now look at how ahead-of-time compilation works in practice, using Rust as an example.
The Rust programming language is an ahead-of-time compiled language built on top of the LLVM compiler project.
The Rust toolchain includes a compiler, rustc, which converts Rust code into machine code, similar to how compilers such as gcc, clang or MSVC convert C and C++ code into machine code. While the study of the Rust compiler (and compilers in general) is beyond the scope of this course, it pays off to get a basic understanding of the process of compiling Rust code into an executable programWe will use the term executable code to refer to any code that can be run on an abstract machine without further preprocessing. The other usage of the term executable is for an executable file and to distinguish it from a library, which is a file that contains executable code, but can't be executed on its own..
When you install Rust, you will get access to cargo, the build system and package manager for Rust. Most of our interaction with the Rust toolchain will be through cargo, which acts as an overseer for many of the other tools in the Rust ecosystem. Most importantly for now, cargo controls the Rust compiler, rustc. You can of course invoke rustc yourself, generally though we will resort to calls such as cargo build for invoking the compiler. Suppose you have written some rust code in a file called hello.rs (.rs is the extension for files containing Rust code) and you run rustc on this file to convert it into an executable. The following image gives an overview of the process of compiling your source file hello.rs into an executable:
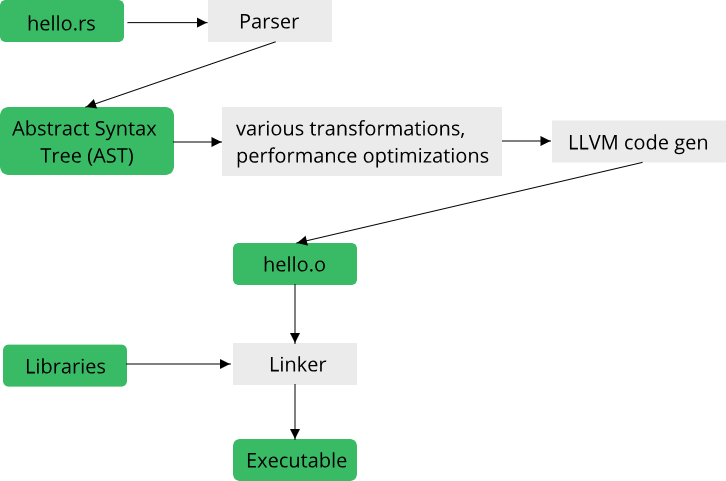
Your code in its textual representation is first parsed and converted into an abstract syntax tree (AST). This is essentially a data structure that the represents your program in a way that the compiler can easily work with. From there, a bunch of transformations and optimizations are applied to the code, which is then ultimately fed into the LLVM code generator, which is responsible for converting your code into something that your CPU understands. The output of this stage are called object files, as indicated by the .o file extension (or .obj on Windows). Your code might reference other code written by other people, in the form of libraries. Combining your code with the libraries into an executable is the job of the linker.
The Rust compiler (and most other compilers that you will find in the wild) has three main tasks:
-
- It enforces the rules of the programming language. This checks that your code adheres to the syntax and semantics of the programing language
-
- It converts the programming language constructs and syntax into a series of instructions that your CPU can execute (called machine code)
-
- It performs optimizations on the source code to make your program run faster
The only mandatory stage for any compiler is stage 2, the conversion of source code into executable instructions. Stage 1 tends to follow as a direct consequence of the task of stage 2: In order to know how to convert source code into executable instructions, every programming language has to define some syntax (things like if, for, while etc.) which dictates the rules of this conversion. In that regard, programming language syntax is nothing more than a list of rules that define which piece of source code maps to which type of runtime behaviour (loops, conditionals, call statements etc.). In applying these rules, compilers implicitly enforce the rules of the programming language, thus implementing stage 1.
The last stage - program optimization - is not necessary, however it has become clear that this is a stage which, if implemented, makes the compiler immensely more powerful. Recall what we have learned about abstractions in chapter 1: Abstraction is information-hiding. A programming language is an abstraction for computation, an abstraction which might be missing some crucial information that would improve performance. Because compilers can optimize our written code, we can thus gain back some information (albeit only indirectly) that was lost in the abstraction. In practice this means we can write code at a fairly high level of abstraction and can count on the compiler to fill in the missing information to make our code run efficiently on the target hardware. While this process is far from perfect, we will see that it can lead to substantial performance improvements in many situations.
Compiler Explorer: A handy tool to understand compiler optimizations
When studying systems programming, it can sometimes be helpful to understand just what exactly the compiler did to your source code. While it is possible to get your compiler to output annotated assembly code (which shows the machine-level instructions that your code was converted into), doing this by hand can become quite tedious, especially in a bigger project where you might only be interested in just a single function. Luckily, there exists a tremendously helpful tool called Compiler Explorer which we will use throughout this course. Compiler Explorer is a web-application that lets you input code in one of several programming languages (including C++ and Rust) and immediately shows you the corresponding compiler output for that code. It effectively automates the process of calling the compiler with the right arguments by hand and instead gives us a nice user interface to work with. Here is what Compiler Explorer looks like:
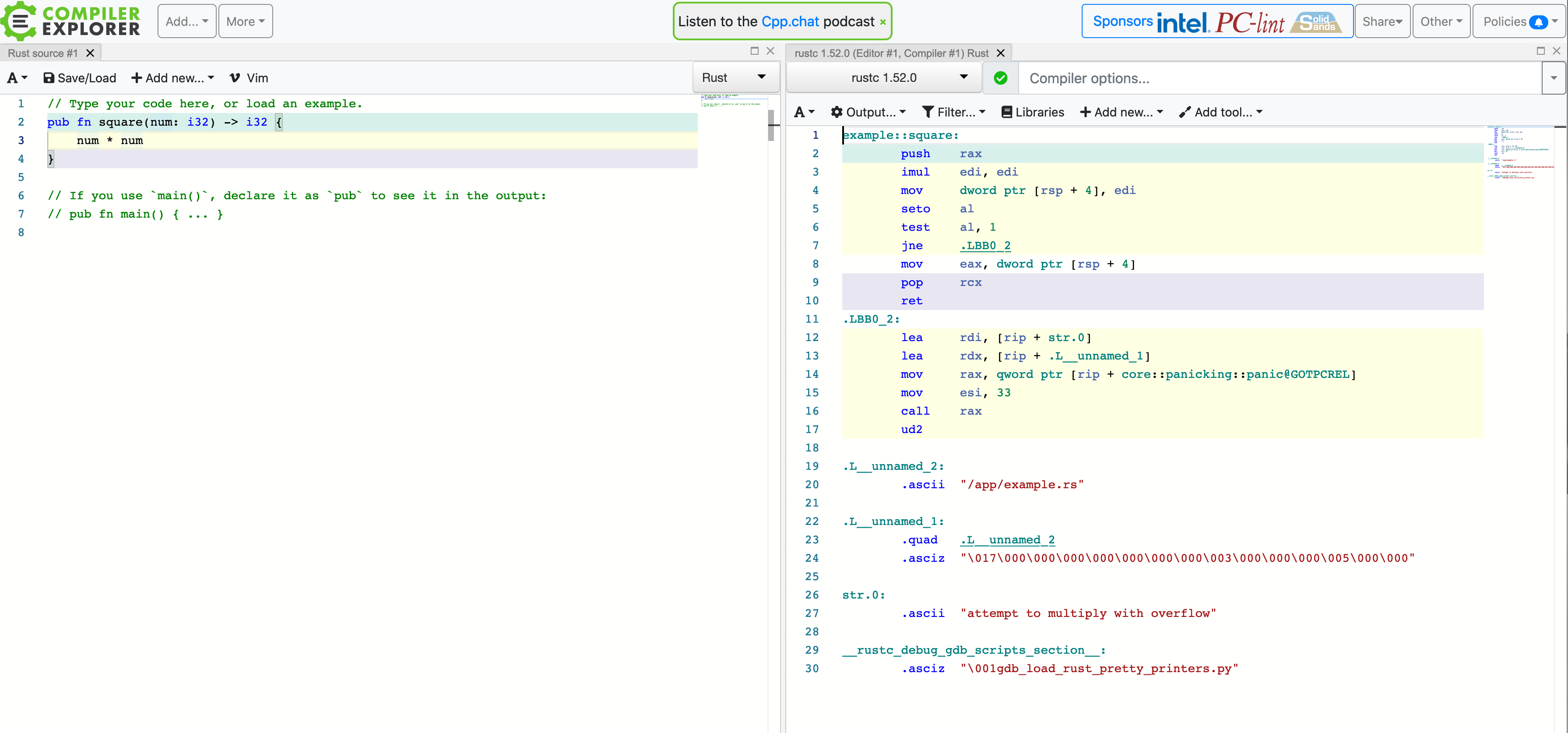
On the left you input your code, choose the appropriate programming language and on the right you will find the compiler output for that piece of code. You can select which compiler to use, and provide arguments to the compiler. Here is an example of the same piece of code, compiled with the compiler argument -O, which tells the compiler to optimize the code:

Notice how much less code there is once the compiler applied its optimizations! We will use Compiler Explorer whenever we want to understand how the compiler acts on our code.
The dark side of compilers
While compilers are these quasi-magical tools that take our code and convert it into an efficient machine-level representation, there are also downsides to using ahead-of-time compiled languages. Perhaps the largest downside is the time that it takes to compile code. All these transformations and optimizations that a compiler performs can be quite complex. A compiler is nothing more than a program itself, so it is bound by the same rules as any program, namely: Complex processes take time. For sophisticated programming languages, such as Rust or C++, compiling even moderately-sized projects can take minutes, with some of the largest projects taking hours to compile. Compared to interpreted languages such as Python or JavaScript, where code can be run almost instantaneuously, this difference in time for a single "write-code-then-run-it" iteration is what caused the notion of compiled languages being 'less productive' than interpreted languages.
Looking at Rust, fast compilation times are not one of its strong sides, unfortunately. You will find plenty of criticism for Rust due to its sometimes very poor compile times, as well as lots of tips on how to reduce compile times.
At the same time, most of the criticism deals with the speed of "clean builds", that is compiling all code from scratch. Most compilers support what is know as incremental builds, where only those files which have changed since the last compilation are recompiled. In practice, this makes working with ahead-of-time compiled languages quite fast. Nonetheless, it is worth keeping compilation times in mind and, when necessary, adapt your code once things get out of hand.
Recap
In this section, we learned about the difference between compiled languages and interpreted languages. Based on a historical example, the Turing machine, we learned about the concept of abstract machines which can execute code. We saw that for systems programming, it is benefitial to have an abstract machine that matches the underlying hardware closely, to get fine-grained control over the hardware and to achieve good performance. We learned about compilers, which are tools that translate source code from one language into executable code for an abstract machine, and looked at one specific compiler, rustc, for the Rust programming language. Lastly, we learned that the process of compiling code can quite slow due to the various transformations and optimizations that a compiler might apply to source code.
In the next chapter, we will look more closely at the Rust programming language and learn about its major features. Here, we will learn the concept of language paradigms.
2.2. Rust as a multi-paradigm language
In this chapter, we will look more closely at the Rust programming language and its high-level features. We will do some comparisons between Rust code and C++ code, for now purely from a theoretical perspective. In the process, we will learn about programming paradigms, which often define the way one writes code in a programming language.
Why different programming languages?
There are a myriad of different programming languages available today. As of 2021, Wikipedia lists almost 700 unique programming languages, stating that these are only the "notable programming languages". With such an abundance in programming languages that a programmer can choose from, it is only natural that questions such as "What is the best programming language?" arise. Such questions are of course highly subjective, and discussions whether programming language A is superior to programming language B are often fought with almost religious zeal. Perhaps the better question to ask instead is: "Why do so many different programming languages exist?"
🔤 Exercise 2.2.1
List the programming languages that you know of, as well as the ones that you have already written some code in. If you have written code in more than one language, which language did you prefer, and why? Can you come up with some metrics that can be used to assess the quality of a programming language?
💡 Need help? Click here
C++ is often seen as "hard" due to its many language features, few guardrails and a complex standard. At the same time, it is seen as very fast, meaning the programs written with C++ can be high-performance programs. For actual quality criteria that we can deduce from that, read on!
One possible approach to understand why there are so many different programming languages is to view a programming language like any other product that is available on the market. Take shoes as an analogy. There are lots of companies making shoes, and each company typically has many different product lines of shoes available. There are of course different types of shoes for different occasions, such as sneakers, slippers, winter boots or dress shoes. Even within each functional category, there are many different variations which will differ in price, style, material used etc. A way to classify shoes (or any product for that matter) is through quality criteria. Examples of quality criteria are:
- Performance
- Usability
- Reliability
- Look&Feel
- Cost
We can apply these quality criteria to programming languages as well and gain some insight into why there are so many programming languages. We will do so for the three interesting criteria Performance, Usability and Reliability.
Performance as a quality criterion for programming languages
Performance is one of the most interesting quality criteria when applying it to programming languages. There are two major ways to interpret the term performance here: One is the intuitive notion of "How fast are the programs that I can write with this programming language?". We talked a bit about this in section 1.2 when we learned about high-level and low-level programming languages. Another interpretation of performance is "What can I actually do with this programming language?" This question is interesting because there is a theoretical answer and a practical one, and both are equally valuable. The theoretical answers comes from the area of theoretical computer science (a bit obvious, isn't it?). Studying theoretical computer science is part of any decent undergraduate curriculum in computer science, as it deals with the more mathematical and formal aspects of computer science. Many of the underlying concepts that make modern programming languages so powerful are directly rooted in theoretical computer science, as we will see time and again in this course. To answer the question "What can I do with programming language X?", a theoretical computer scientist will ask you what abstract machine your programming language runs on. In the previous chapter, we learned about the Turing machine as an abstract machine, which incidentely is also the most powerful (conventional) abstract machine known to theoretical computer scientists (remember the Church-Turing-Thesis?).
If you can simulate a Turing machine in your programming language, you have shown that your programming language is as powerful (as capable) as any other computational model (disregarding some exotic, theoretical models). We call any such language a Turing-complete language. Most modern programming languages are Turing-complete, which is why you rarely encounter computational problems which you can solve with one popular programming language, but not with another. At least, this is the theoretical aspect of it. From a practical standpoint, there are many capabilities that one language might have that another language is lacking. The ability to directly access hardware resources is one example, as we saw in section 1.2. The whole reason why we chose Rust as a programming language in this course is that it has capabilities that for example the language Python does not have. In practice, many languages have mechanisms to interface with code written in other languages, to get access to certain capabilities that they themselves lack. This is called language interoperability or interop for shortThis might become part of a future chapter of this book. Stay tuned!. In this regard, if language A can interop with language B, they are in principle equivalent in terms of their capabilities (strictly speaking the capabilities of A form a superset of the capabilities of B). In practice, interop might introduce some performance overhead, makes code harder to debug and maintain and thus is not always the best solution. This leads us to the next quality criterion:
Usability of programming languages
Usability is an interesting criterion because it is highly subjective. While there are formal definitions for usability, even those definitions still involve a high degree of subjectiveness. The same is true for programming languages. The Python language has become one of the most popular programming languages over the last decade in part due to its great usability. It is easy to install, easy to learn and easy to write, which is why it is now seen as a great choice for the first programming language that one should learn when learning programming. We can define some aspects that make a language usable:
- Simplicity: How many concepts does the programmer have to memorize in order to effectively use the language?
- Conciseness: How much code does the programmer have to write for certain tasks?
- Familiarity: Does the language use standard terminology and syntax that is also used in other languages?
- Accessibility: How much effort is it to install the necessary tools and run your first program in the language?
You will see that not all of these aspects might have the same weight for everyone. If you start out learning programming, simplicity and accessibility might be the most important criteria for you. As an experienced programmer, you might look more for conciseness and familiarity instead.
🔤 Exercise 2.2.2
How would you rate the following programming languages in terms of simplicity, conciseness, familiarity and accessibility? Python, Java, C, C++, Rust, Haskell. If you don't know some of these languages, try to look up an introductory tutorial for them (you don't have to write any code) and make an educated guess.
💡 Need help? Click here
| Language | Simplicity | Conciseness | Familiarity | Accessibility |
|---|---|---|---|---|
| Python | High (easy to learn) | High (depending on the problem to solve, for algorithms less so than for data processing) | Medium-high (indentation for scoping is unusual, but has many wide-spread keywords) | High (installation is easy, often comes preinstalled on Linux systems, lots of resources for learning out there) |
| Java | Medium-high (object-oriented nature can feel cumbersome, but there is little arcane syntax) | Low (Java code is famous for being very verbose) | High (the syntax is similar enough to C/C++ in many aspects, almost identical to C#, and not too far removed from JavaScript, covering a wide range of popular languages) | High ("Java runs on over X billion devices" was a popular marketing slogan) |
| C | Medium (pointers can be hard to learn, but the language itself is small in terms of features) | Medium (not as much boilerplate as Java, but also not many features for expressing things in a more dense way) | Medium (perhaps the most used language historically, but if you come from Web development for example, C is very different) | Medium (the main selling point of C is that everything - as in every platform - supports C. The tooling is lacking however) |
| C++ | Low (C++ is famous for being overly complex and tripping even experts with arcane language details. Its growth over multiple decades has made the language bloated) | Low (the stronger type system compared to C means more typing for the same things) | Medium (the basic syntax is easy enough, templates complicate things) | Low (mainly due to the way C++ projects are structured, often requiring complex build systems that are hard to learn) |
| Rust | Low (hard learning curve due to the very strict type system) | Medium (arguably better than C++ due to more high-level abstractions and type inference, but still requires more typing to express certain things compared to e.g. Python) | Low (there are certain syntactic elements that are unusual for many programmers, such as match and lifetime annotations, but mostly the concepts of borrow checking and lifetimes themselves are unfamiliar to most programmers) | High (easy to install, some of the best tooling out there, outstanding documentation at least for the core parts of the language) |
| Haskell | Low (perhaps the most complicated language on the list, if only due to its close relation to mathematics) | Very high (a side-effect of being a functional language, often reading similar to mathematical statements) | Low (very unusual syntax for most programmers not used to functional programming) | Medium (simple enough to install and has decent tooling, but it is a niche programming language and as such resources are scarcer than for other languages) |
In the opinion of the author, Rust has an overall higher usability than most other systems programming languages due to its great tooling and documentation, which is the main reason why it was chosen for this course.
Reliability of programming languages
Reliability is a difficult criterion to assess in the context of programming languages. A programming language does not wear out with repeated use, as any physical product might. Instead, we might ask the question "How reliable are the programs that I write with this language?" This all boils down to "How easy is it to accidently introduce bugs to the code?", which is an exceedingly difficult question to answer. Bugs can take on a variety of forms and can have a myriad of origins. No programming language can reasonably expect to prevent all sorts of bugs, so we have to instead figure out what bugs can be prevented by using a specific programming language, and how the language deals with any errors that can't be prevented.
Generally, it makes sense to distinguish between logical errors caused by the programmer (directly or indirectly), and runtime errors, which can occur due to external circumstances. Examples of logical errors are:
- The usage of uninitialized variables
- Not enforcing assumptions (e.g. calling a function with a null-pointer without checking for the possibility of null-pointers)
- Accessing an array out-of-bounds (for example due to the famous off-by-one errors)
- Wrong calculations
Examples of runtime errors are:
- Trying to access a non-existing file (or insufficient privileges to access the file)
- A dropped network connection
- Insufficient working memory
- Wrong user input
We can now classify languages by the mechanisms they provide to deal with logical and runtime errors. For runtime errors, a reliable language will have robust mechanisms to deal with a large range of possible errors and will make it easy to deal with these errors. We will learn more about this in chapter 5 when we talk about error handling. Preventing logical errors is a lot harder, but there are also many different mechanisms which can help and make a language more reliable. In the next section for example, we will learn how the Rust type system makes certain kinds of logical errors impossible to write in Rust.
A last important concept, which plays a large role in systems programming, is that of determinism. One part of being reliable as a system is that the system gives expected behaviour repeatedly. Intuitively, one might think that every program should behave in this way, giving the same results when executed multiple times with the same parameters. While this is true in principle, in practice not all parameters of a program can be specified by the user. On a modern multi-processor system, the operating system for example determines at which point in time your program is executed on which logical core. Here, it might compete with other programs that are currently running on your system in a chaotic, unpredictable manner. Even disregarding the operating system, a programming language might contain unpredictable parts, such as a garbage collector which periodically (but unpredictably) interrupts the program to free up unused but reserved memory. Determinism is especially important in time-critical systems (so-called real-time systems), where code has to execute in a predictable timespan. This ranges from soft real-time systems, such as video games which have to hit a certain target framerate in order to provide good user experience, to hard real-time systems, such as the circuit that triggers the airbag in your car in case of an emergency.
It is worth pointing out that, in principle, all of the given examples still constitute deterministic behaviour, however the amount of information required to make a useful prediction in those systems is so large that any such prediction is in practice not feasible. Many programs thus constitute chaotic systems: Systems that are in principle deterministic, but are so sensitive to even a small change in input conditions that their behaviour cannot be accurately predicted. Luckily, most software still behaves deterministically on the macroscopic scale, even if it exhibits chaotic behaviour on the microscopic scale.
The concept of programming paradigms
In order to obtain good performance, usability or reliability, there are certain patterns in programming language design that can be used. Since programming languages are abstractions over computation, a natural question that arises is: "What are good abstractions for computation?" Here, over the last decades, several patterns have emerged that turned out to be immensely useful for writing fast, efficient, concise and powerful code. These patterns are called programming paradigms and can be used to classify the features of a programming language. Perhaps one of the most well-known paradigms is object-oriented programming. It refers to a way of structuring data and functions together in functional units called objects. While object-oriented programming is often marketed as a "natural" way of writing code, by modeling it as you would model relationships between entities in the real world, it is far from the only programming paradigm. In the next couple of sections, we will look at the most important programming paradigms in use today.
The most important programming paradigms
In the context of systems programming, there are several programming paradigms which are especially important. These are: Imperative programming, object-oriented programming, functional programming, generic programming, and concurrent programming. Of course, there are many other programming paradigms in use today, for a comprehensive survey the paper "Programming Paradigms for Dummies: What Every Programmer Should Know" by Peter Van Roy {{#cite Roy09}} is a good starting point.
Imperative
Imperative programming refers to a way of programming in which statements modify state and express control flow. Here is a small example written in Rust:
#![allow(unused)] fn main() { fn collatz(mut n: u32) { loop { if n % 2 == 0 { n /= 2; } else { n = 3 * n + 1; } } } }
This code computes the famous Collatz sequence and illustrates the key concepts of imperative programming. It defines some state (the variable n) that is modified using statements (conditionals, such as if and else, and assignments through =). The statements define the control flow of the program, which can be thought of as the sequence of instructions that are executed when your program runs. In this regard, imperative programming is a way of defining how a program should achieve its desired result.
Imperative programming might feel very natural to many programmers, especially when starting out to learn programming. It is the classic "Do this, then that" way of telling a computer how to behave. Indeed, most modern hardware architectures are imperative in nature, as the low-level machine instructions are run one after another, each acting on and potentially modifying some state. As this style of programming closely resembles the way that processors execute code, it has become a natural choice for writing systems software. Most systems programming languages that are in use today thus use the imperative programming paradigm to some extent.
The opposite of imperative programming is called declarative programming. If imperative programming focuses on how things are to be achieved, declarative programming focuses on what should be achieved. To illustrate the declarative programming style, it pays of to take a look at mathematical statements, which are inherently declarative in nature:
f(x)=x²
This simple statement expresses the idea that "There is some function f(x) whose value is x²". It describes what things are, not how they are achieved. The imperative equivalent of this statement might be something like this:
#![allow(unused)] fn main() { fn f_x(x: u32) -> u32 { x * x } }
Here, we describe how we achieve the desired result (f(x) is achieved by multiplying x by itself). While this difference might seem pedantic at first, it has large implications for the way we write our programs. One specific form of declarative programming is called functional programming, which we will introduce in just a bit.
Object-Oriented
The next important programming paradigm is the famous object-oriented programming (OOP). The basic idea of object-oriented programming is to combine state and functions into functional units called objects. OOP builds on the concept of information hiding, where the inner workings of an object are hidden to its users. Here is a short example of object-oriented code, this time written in C++:
#include <iostream>
#include <string>
class Cat {
std::string _name;
bool _is_angry;
public:
Cat(std::string name, bool is_angry) : _name(std::move(name)), _is_angry(is_angry) {}
void pet() const {
std::cout << "Petting the cat " << _name << std::endl;
if(_is_angry) {
std::cout << "*hiss* How dare you touch me?" << std::endl;
} else {
std::cout << "*purr* This is... acceptable." << std::endl;
}
}
};
int main() {
Cat cat1{"Milo", false};
Cat cat2{"Jack", true};
cat1.pet();
cat2.pet();
}
In OOP, we hide internal state in objects and only interact with them through a well-defined set of functions on the object. The technical term for this is encapsulation, which is an important idea to keep larger code bases from becoming confusing and hard to maintain. Besides encapsulation, OOP introduces two more concepts that are important: Inheritance, and Polymorphism.
Inheritance refers to a way of sharing functionality and state between multiple objects. By inheriting from an objectTechnically, classes inherit from other classes, but it does not really matter here., another object gains access to the state and functionality of the base object, without having to redefine these state and functionalities. Inheritance thus aims to reduce code duplication.
Polymorphism goes a step further and allows objects to serve as templates for specific behaviour. This is perhaps the most well-known example of object-oriented code, where common state or behaviour of a class of entities is lifted into a common base type. The base type defines what can be done with these objects, each specific type of object then defines how this action is done. We will learn more about different types of polymorphism in section 2.5, for now a single example will suffice:
#include <iostream>
#include <memory>
struct Shape {
virtual ~Shape() {};
virtual double area() const = 0;
};
class Circle : Shape {
double radius;
public:
explicit Circle(double radius) : radius(radius) {}
double area() const override {
return 3.14159 * radius * radius;
}
};
class Square : Shape {
double sidelength;
public:
explicit Square(double sidelength) : sidelength(sidelength) {}
double area() const override {
return sidelength * sidelength;
}
};
int main() {
auto shape1 = std::make_unique<Circle>(10.0);
auto shape2 = std::make_unique<Square>(5.0);
std::cout << "Area of shape1: " << shape1->area() << std::endl;
std::cout << "Area of shape2: " << shape2->area() << std::endl;
}
OOP became quite popular in the 1980s and 1990s and still to this day is one of the most widely adopted programming paradigms. It has arguably more importance in applications programming than in systems programming (many systems software is written in C, a non-object-oriented language), but its overall importance and impact to programming as a whole make it worth knowing. In particular, the core concepts of OOP (encapsulation, inheritance, polymorphism) can be found within other programming paradigms as well, albeit in different flavours. In particular, Rust is not considered to use the OOP paradigm, but it still supports encapsulation and polymorphism, as we will see in later chapters.
It is worth noting that the popularity of OOP is perhaps more due to its history than due to its practical usefulness today. OOP has been heavily criticised time and again, and modern programming languages increasingly tend to move away from it. This is in large part due to the downsides of OOP: The immense success of OOP after its introduction for a time led many programmers to use it as a one-size-fits-all solution, designing large class hierarchies that quickly become unmaintainable. Perhaps most importantly, OOP does not map well onto modern hardware architectures. Advances in computational power over the last decade were mostly due to increased support for concurrent computing, not so much due to an increase in sequential execution speed. To make good use of modern multi-core processors, programming languages require solid support for concurrent programming. OOP is notoriously bad at this, as the information-hiding principle employed by typical OOP code does not lend itself well to parallelization of computations. This is where concepts such as functional programming and specifically concurrent programming come into play.
Functional
We already briefly looked at declarative programming, which is the umbrella term for all programming paradigms that focus on what things are, instead of how things are done. Functional programming (FP) is one of the most important programming paradigms from the latter domain. With roots deep within mathematics and theoretical computer science, it has seen an increase in popularity over the last decade due to its elegance, efficiency and usefulness for writing concurrent code.
FP generally refers to programs which are written through the application and composition of functions. Functions are of course a common concept in most programming languages, what makes functional programming stand out is that it treats functions as "first-class citizens". This means that functions share the same characteristics as data, namely that they can be passed around as arguments, assigned to variables and stored in collections. A function that takes another function as an argument is called a higher-order function, a concept which is crucial to the success of the FP paradigm. Many of the most common operations in programming can be elegantly solved through the usage of higher-order functions. In particular, all algorithms that use some form of iteration over elements in a container are good candidates: Sorting a collection, searching for an element in a collection, filtering elements from a collection, transforming elements from one type into another type etc. The following example illustrates the application of functional programming in Rust:
#![allow(unused)] fn main() { struct Student { pub id: String, pub gpa: f64, pub courses: Vec<String>, } fn which_courses_are_easy(students: &[Student]) -> HashSet<String> { students .iter() .filter(|student| student.gpa >= 3.0) .flat_map(|student| student.courses.clone()) .collect() } }
Here, we have a collection of Students and want to figure out which courses might be easy. The naive way to do this is to look at the best students (all those with a GPA >= 3) and collect all the courses that these students took. In functional programming, these operations - finding elements in a collection, converting elements from one type to another etc. - are higher-order functions with specific names that make them read almost like an english sentence: "Iterate over all students, filter for those with a GPA >= 3 and map (convert) them to the list of courses. Then collect everything at the end." Notice that the filter and flat_map functions (which is a special variant of map that collapses collections of collections into a single level) take another function as their argument. In this way, these functions are composable and general-purpose. Changing the search criterion in the filter call is equal to passing a different function to filter:
#![allow(unused)] fn main() { filter(|student| student.id.starts_with("700")) }
All this can of course be achieved with the imperative way of programming as well: Create a counter that loops from zero to the number of elements in the collection minus one, access the element in the collection at the current index, check the first condition (GPA >= 3) with an if-statement, continue-ing if the condition is not met etc. While there are many arguments for functional programming, such as that it produces prettier code that is easier to understand and maintain, there is one argument that is especially important in the context of systems programming. Functional programming, by its nature, makes it easy to write concurrent code (i.e. code that can be run in parallel on multiple processor cores). In Rust, using a library called rayon, we can run the same code as before in parallel by adding just 4 characters:
#![allow(unused)] fn main() { fn which_courses_are_easy(students: &[Student]) -> HashSet<String> { students .par_iter() .filter(|student| student.gpa >= 3.0) .flat_map(|student| student.courses.clone()) .collect() } }
We will learn a lot more about writing concurrent code in Rust in chapter 7, for now it is sufficient to note that functional programming is one of the core programming paradigms which make writing concurrent code easy.
As a closing note to this section, there are also languages that are purely functional, such as Haskell. Functions in a purely functional programming language must not have side-effects, that is they must not modify any global state. Any function for which this condition holds is called a pure function (hence the name purely function language). Pure functions are an important concept that we will examine more closely when we will learn about concurrency in systems programming.
Generic
Another important programming paradigm is called generic programming. In generic programming, algorithms and datastructures can be implemented without knowing the specific types that they operate on. Generic programming thus is immensely helpful in preventing code duplication. Code can be written once in a generic way, which is then specialized (instantiated) using specific types. The following Rust-Code illustrates the concept of a generic container class:
use std::fmt::{Display, Formatter}; struct PrettyContainer<T: Display> { val: T, } impl<T: Display> PrettyContainer<T> { pub fn new(val: T) -> Self { Self { val } } } impl<T: Display> Display for PrettyContainer<T> { fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result { write!(f, "~~~{}~~~", self.val) } } fn main() { // Type annotations are here for clarity let container1 : PrettyContainer<i32> = PrettyContainer::new(42); let container2 : PrettyContainer<&str> = PrettyContainer::new("hello"); println!("{}", container1); println!("{}", container2); }
Here, we create a container called PrettyContainer which is generic over some arbitrary type T. The purpose of this container is to wrap arbitrary values and print them in a pretty way. To make this work, we constrain our generic type T, requiring it to have the necessary functionality for being displayed (e.g. written to the standard output).
Generic programming enables us to write the necessary code just once and then use our container with various different types, such as i32 and &str in this example. Generic programming is closely related to the concept of polymorphism that we learned about in the section on object-oriented programming. We will cover generics in the context of type systems more closely in the next two chapters.
Concurrent
The last important programming paradigm that we will look at is concurrent programming. We already saw an example for writing code that makes use of multiple processor cores in the section on functional programming. Concurrent programming goes a step further and includes various mechanisms for writing concurrent code. At this point, we first have to understand an important distinction between two terms: Concurrency and Parallelism. Concurrency refers to multiple processes running during the same time periods, whereas parallelism refers to multiple processes running at the same time. An example of concurrency in real-life is university. Over the course of a semester (the time period), one student will typical be enrolled in multiple courses, making progress on all of them (ideally finishing them by the end of the semester). At no point in time, however, did the student sit in two lectures at the same timeWith online courses during the pandemic, things might be different though. Time-turners might also be a way to go.. An example of parallelism is during studying. A student can study for an exam while, at the same time, listening to some music. These two processes (studying and music) run at the same time, thus they are parallel.
Concurrency thus can be seen as a weaker, more general form of parallelism. An interesting piece of history is that concurrency was employed in operating systems way before multi-core processors became commonplace. This allowed users to run multiple pieces of software seemingly at the same time, all one just one processor. The illusion of parallelism was achieved through a process called time slicing, where each program ran exclusively on the single processor core for only a few milliseconds before being replaced by the next program. This rapid switching between programs gave the illusion that multiple things were happening at the same time.
Concurrency is a very important programming paradigm nowadays because it is central for achieving good performance and interactivity in complex applications. At the same time, concurrency means that multiple operations can be in flight at the same time, resulting in asynchronous execution and often non-deterministic behaviour. This makes writing concurrent code generally more difficult than writing sequential code (for example with imperative programming). Especially when employing parallelism, where multiple things can happen at the same instant in time, a whole new class of programming errors becomes possible due to multiple operations interfering with each other. To reduce the mental load of progammers when writing concurrent or parallel code, and to prevent some of these programming errors, concurrent programming employs many powerful abstractions. We will learn more about these abstractions when we talk about fearless concurrency in chapter 7. For now, here is a short example form the Rust documentation that illustrates a simple form of concurrency using the thread abstraction:
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
Running this example multiple times illustrates the non-deterministic nature of concurrent code, with each run of the program potentially producing a different order of the print statements.
The programming paradigms used by Rust
Now that we know some of the most important programming paradigms and their importance for systems programming, we can take a quick look at the Rust programming language again. As you might have guessed while reading the previous sections, many programming languages use multiple programming paradigms at the same time. These languages are called multi-paradigm languages. This includes languages such as C++, Java, Python, and also Rust. Here is a list of the main programming paradigms that Rust uses:
- Imperative
- Functional
- Generic
- Concurrent
Additionally, Rust is not an object-oriented programming language. This makes it stand out somewhat from most of the other languages that are usually taught in undergraduate courses at universities, with the exception of C, which is also not object-oriented. Comparing C to Rust is an interesting comparison in the context of systems programming, because C is one of the most widely used systems programming languages, even though from a modern point of view, it is lacking many convenience features that one might be used to from other languages. There is plenty of discussion regarding the necessity of "fancy" programming features, and some people will argue that one can write perfectly fine systems code in C (as the Linux kernel demonstrates). While this is certainly true (people also used to write working programs in assembly language for a long time), a modern systems programming language such as Rust might be more appealing to a wider range of developers, from students just starting to learn programming, to experienced programmers who have been scared by unreadable C++-template-code in the past.
Feature comparison between Rust, C++, Java, Python etc.
We shall conclude this section with a small feature comparison of Rust and a bunch of other popular programming languages in use today:
| Language | Imperative | Object-oriented | Functional | Generic | Concurrent | Other notable features |
|---|---|---|---|---|---|---|
| Rust | Yes | No | Yes (impure) | Yes (type-classes) | Yes (threads, async) | Memory-safety through ownership semantics |
| C++ | Yes | Yes (class-based) | Yes (impure) | Yes (templates) | Yes (threads since C++11, coroutines since C++20) | Metaprogramming through templates |
| C | Yes | No | No | No | No (but possible through OS-dependent APIs, such as pthreads) | Metaprogramming through preprocessor |
| Java | Yes | Yes (class-based) | Yes (impure) | Yes (type-erasure) | Yes (threads) | Supports runtime reflection |
| Python | Yes | Yes (class-based) | Yes (impure) | No (dynamically typed) | Yes (threads, coroutines) | Dynamically typed scripting language |
| JavaScript | Yes | Yes (prototype-based) | Yes (impure) | No (dynamically typed) | Yes (async) | Uses event-driven programming |
| C# | Yes | Yes (class-based) | Yes (impure) | Yes (type substitution at runtime) | Yes (threads, coroutines) | One of the most paradigm-rich programming languages in use today |
| Haskell | No | No | Yes (pure) | Yes (type-classes) | Yes (various methods available) | A very powerful type system |
It is worth noting that most languages undergo a constant process of evolution and development themselves. C++ has seen significant change over the last decade, starting a three-year release cycle with C++11 in 2011, with the current C++ version depicted here. Rust has a much faster release cycle of just six weeks, new versions and their changelogs can be found here.
Recap
In this chapter, we learned about programming paradigms. We saw how certain patterns for designing a programming language can aid in writing faster, more robust, more maintainable code. We learned about five important programming paradigms: Imperative programming, object-oriented programming, functional programming, generic programming and concurrent programming. We saw some examples of Rust and C++ code for these paradigms and learned that Rust supports most of these paradigms, with the exception of object-oriented programming. We concluded with a feature comparison of several popular programming languages.
In the next chapter, we will dive deeper into Rust and take a look at the type system of Rust. Here, we will learn why strongly typed languages are often preferred in systems programming.
Questions and exercises
❓ Question
Why do all of the languages introduced in this chapter use multiple programming paradigms instead of a single one?
💡 Click to show the answer
Each programming paradigm has something unique to offer in terms of usability, performance, robustness etc. It is possible to support more than one paradigm within a single language, so we can make languages more expressive by doing so. Adding too many paradigms can also result in a language that is harder to understand, as there are too many different ways of doing the same thing.
❓ Question
Why do almost all modern programming languages use the concurrent programming paradigm?
💡 Click to show the answer
Since Moore's Law doesn't hold anymore, doing things concurrently has been one of the major ways for improving program performance over the last two decades. Without a way to access concurrency on our machines, a language will thus be very limited when it comes to writing fast code.
❓ Question
What is the main benefit of generic programming? If you ever wrote C code, how did you handle data structures working with multiple different types?
💡 Click to show the answer
Generic code prevents code duplication. Most generic programming approaches also maintain type-safety. This is less error-prone and generally simpler to reason about than methods for code reuse such as the C/C++ preprocessor, which operates purely textual.
🔤 Exercise 2.2.3
Write a small program that sorts a large number of integers (e.g. 1 million) in both C/C++ and Python. Measure the runtime of both programs. What do you observe?
💡 Need help? Click here
Hint: You can measure whole-program execution time on the command line using e.g. time on Unix-systems: time my_program. Many languages also provide ways of measuring time with high-precision from within the source code, e.g. through std::chrono::high_resolution_clock in C++ or time.perf_counter() in Python.
🔤 Exercise 2.2.4
Write a C++ program that implements the same algorithm in three different styles: Imperative, object-oriented, and functional. Calculating fibonacci numbers or finding even numbers in an array are good candidates. What do you observe?
💡 Need help? Click here
Hint: Imperative will use for-loops, functional will use iterators and the algorithms from the algorithms library, and object-oriented will try to encapsulate collections to iterate over as well as the operations to perform on these collections using interfaces.
2.3. Rust as a statically-typed language
In this chapter, we will look at an aspect of programming language design called the type system. Without becoming experts on compiler building, we will learn what types are, what makes some types "static" and others "dynamic", and why this distinction is useful for understanding which languages work well for systems programming. We will see a first example of why Rust is considered to have a particularly strong type system.
Why strongly typed languages for systems programming?
Since this course uses Rust as its main programming language, you will have to get used to some of the special features that Rust offers. One of the most powerful ones is the type system that Rust is built upon. Many of the examples in this course deal with finding, building, and understanding abstractions for the many different areas of systems programming that we as programmers have to deal with. A strong type system helps with these abstractions, as it provides a way to encode concepts into rules that the (Rust) compiler can check and enforce for us before we ever run our program. As we saw in chapter 2.1, strong checks are helpful for systems programming, but be aware that they come at a cost (slower iteration cycles for example, as we have to wait for the compiler to check our program).
Examples of encoding concepts into rules using types
Let's try to understand what "encoding concepts into rules" means. What types of concepts can we even encode? It turns out that this is very different depending on the programming language that we use, as we saw in chapter 2.2 when we learned about programming paradigms. Some concepts that you might already know are:
- Primitive data types: Is something an integer (e.g.
int) or a rational number (e.g.float), or maybe text (e.g.const char*)? - Control flow and conditions: Loops, recursion,
if/else,switchetc. - Objects and object hierarchies:
class,virtualetc. - Single entities vs. sequences: Arrays, pointers Notice that collections such as
std::vector<T>are not listed here. Those are not features of the language itself but are typically part of the standard library of the language, meaning they are things that are built using the language, not built into the language! Some languages have certain containers as parts of the language itself, but that is rare.
These concepts might seem like fundamental properties of what "programming" means to you, and they might not even look all that special. All of them are abstractions however, as none of them exist on the level of computer hardware: Your CPU knows nothing of objects, arrays, text, not even of loops! It knows a bit about data types, but less than you are used to in languages such as C++ or Python. You can realize object-like, array-like or loop-like behavior using assembly language, but you have to do that manually, which is error-prone and tediousIt can also be fun, if you are into puzzles :). Since we don't want to do things manually, we want abstractions for these concepts, which is what programming languages give us. So a simple piece of code such as the following one contains quite a lot of nifty abstractions:
int div(int a, int b) {
return a / b;
}
Here is what this piece of code states:
- There is a reusable procedure (typically called a function) with a specific name (
div) - The procedure has specific inputs and outputs (2 things in, one thing out)
- The inputs and outputs have specific properties: They are signed, whole numbers with a specific size (32 bits, depending on the compiler that we use)
- The procedure implements a specific operation (signed integer division), which is hidden in the
/operator
For your machine, the corresponding instructions in x86-64 assembly language might look like this:
div(int, int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
mov eax, DWORD PTR [rbp-4]
cdq
idiv DWORD PTR [rbp-8]
pop rbp
ret
Compared to the abstraction level that C++ supports, x86-64 assembly language is a lot less powerful:
- There is some notion of reusable procedures, namely a label (
div(int, int)) and theretinstruction. What we don't immediately find are the function arguments (aandb), these are handled implicitly by the calling convention. We might guess that the arguments are stored in the registersediandesi, which is the default for the "System V AMD64 ABI", the calling convention used for the system this code was compiled on (x86-64Linux). If we were to write the assembly code ourselves, we would have to memorize the calling convention and always pass arguments in the correct registers. It is not hard to imagine how we could make mistakes and write wrong code at this abstraction level! - There is no notion of
intanymore. Instead, we have a few keywords and numbers that tell us how many bytes of memory our values take, and how to treat them:DWORD PTR [x]means "read 4 bytes (32 bits) from memory addressx", theeinediandesiis the identifier for the 32-bit registers onx86-64. Theiinidivis a hint that we want to do signed integer division. Again, it is easy to get things wrong here! - The return value of the procedure is also treated implicitly due to the calling convention: It is stored in the
eaxregister, from which the caller can access it, given that they also stick to the calling convention.
Before diving into more complex types, take a moment to answer the following questions for yourself:
❓ Question
What are the things that are easiest to get wrong in the x86-64 assembly language snippet, if you would have to write it yourself?
💡 Click to show the answer
Subjective questions will yield subjective answers, but here are a few ideas:
- Register names are hard to read and easy to mistype:
ediis one keystroke away fromesi - As mentioned, forgetting the rules of the calling convention seems like a likely situation, especially as a beginner
- Forgetting to
pushandpopthe frame pointer register (rbp)
❓ Question
How many places / statements would you have to change if you wanted to do 64-bit unsigned integer division instead of 32-bit signed integer division, both in the C++ version of the code and in the assembly version?
💡 Click to show the answer
- All
movstatements have to change, both their register names and their addresses:- We have to use the 64-bit registers, which start with an
r:rdiinstead ofedi - We have to load 8 bytes instead of 4 bytes:
QWORD PTR [rbp-8]instead ofDWORD PTR [rbp-4]. Notice that the addresses also changed
- We have to use the 64-bit registers, which start with an
A higher level of abstraction
The same code as before might look like this in Python:
def div(a, b):
return a // b
Notice that the types are gone: No int anywhere to be found. Other than that, it looks quite similar: We have a return statement, use the division operator (which for integer division is written as // in Python instead of / in C++) and define two arguments. Since we state no types and every function in both Python and C++ has exactly one return value, the Python code doesn't need an extra piece of information that says "This function returns one value", like we needed in C++."What about functions that return nothing in C++?" you might ask. They still return a "value" (void), but the language designates this value to mean "nothing". Translated to assembly language this actually makes sense, as the calling convention states that the return value of a function is accessed through a register, but we can just ignore that register if we have no return value.
❓ Question
What would you have to do to convert this exact Python function into x86-64 assembly code? Does Python provide enough information to do that?
💡 Click to show the answer
Since we already have an example of a C++ function for signed integer division and its corresponing x86-64 assembly equivalent, we can take inspiration from that. However, since Python is a dynamically typed language, we do not know if we need 8-bit, 16-bit, 32-bit, 64-bit or some entirely different bit-width for the mov operations. We also do not know if the numbers are actually signed or unsigned.
You might have struggled to answer the previous question because it is unclear what a direct mapping of the Python function to assembly code would require. You could simply use the function we have seen before, which might be viable in some situations, but does it cover all the possible argument that the Python function can handle? How about this:
>>> div(2 ** 128, 2)
170141183460469231731687303715884105728
We divide a pretty big value (\(2^{128}\)) by 2, and Python does that effortlessly. But the C++ function uses the type int, of which we know that it can only represent numbers in the range \( [-2^{31}; 2^{31} - 1] \). If we try to execute similar code in C++, the result is different:
std::cout << div(2 << 128, 2);
We get both a compiler warning and the wrong result:
<source>: In function 'int main()':
<source>:10:29: warning: left shift count >= width of type [-Wshift-count-overflow]
10 | std::cout << asp::div(2 << 128, 2);
| ~~^~~~~~
Output: 0
Now you can start to debate who did something wrong here: Our computer or us? The compiler did issue a warning, but isn't it maybe the machines fault if it doesn't do what we want? If Python can do it, why can't C++?
Questions like these are interesting to debate, because the computer science perspective is different from the user perspective: The user might want a calculator-like behavior, but the computer scientist is the one who has to make a thinking piece of rock behave in the expected way.It turns out that implementing a calculator is really hard Python hides more of the underlying hardware than C++ does (which is precisely what makes Python more high-level than C++, as we saw in chapter 2.1). In C++, there is no such thing as "any integer", the compiler comes right back at us and asks "how many bits does your integer require?". The fact that we get a warning from the compiler for the statement 2 << 128 is arguably a good thing, even though it might be annoying if all you want is to simply calculate \(\frac{2^{128}}{2} \).
Interestingly enough, Python does have a corresponding abstraction for numbers (even though we never wrote any explicit types into our Python function), but it is more general than the one that C++ uses. Consulting the Python documentation, we see this statement: "There are three distinct numeric types: integers, floating-point numbers, and complex numbers. [...] Integers have unlimited precision" (emphasis ours). Unlimited precision integers are what make the Python code work, where the C++ code fails. They come at a cost however, as unlimited precision requires memory allocations and the usage of dynamically-sized arrays, which are more complex and costly to handle than the primitive types that fit within registers.
A limitation of our div function
One thing that we haven't talked about concerning our div function is what happens if the second argument is zero. What does happen? Here is how Python handles it:
>>> div(2, 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in div
ZeroDivisionError: division by zero
And in C++:
std::cout << div(2, 0);
Outout: Program terminated with signal: SIGFPE
SIGFPE signals an "Erroneous arithmetic operation", as can be seen in the Linux man page for signal. In both cases, our program crashed, which is undesirable. So let's go back to the roots and look at the underlying math of our function!
Mathematically, the operation of division is generally deemed to be undefined if the denominator is zero, which we can express like so:
\[ f : \mathbb{Z} \times (\mathbb{Z} \setminus {0}) \to \mathbb{Z}, \quad f(x, y) = \lfloor \frac{x}{y} \rfloor \]
There are a couple of noteworthy things:
- We define the domain and codomain of the function. This is the mathematical equivalent of the input arguments and function output. We can read the first part of the above expression as: "A function mapping from an ordered set of pairs of integersThe pair is a result from the cross product operation
x, where the second pair element must not be zero, to the set of integers" - The mathematical notation is closer to C++ than it is to Python, because we describe something like the type of each argument. Where in C++ we said
int, here we say \(\mathbb{Z}\), meaning "the set of all integers" - Just like in C++, the mathematical notation has both a function signature (the domain to codomain mapping) and a function body (the actual function definition)
🔤 Exercise 2.3.1
We never really stated how two numbers divide by each other, neither in the C++ and Python code nor in the mathematical definition. We saw that the C++ code compiles down to using an assembly instruction called idiv that does the heavy lifting. Find out how integer division is implemented in Python, and what the mathematical algorithm for integer division is.
💡 Need help? Click here
First we have to decide on a Python interpreter, as there are multiple ones. CPython is open source and the code can be found on GitHub. Then we have to figure out how CPython implements integers in the first place. The Python documentation on Integer Objects tells us that PyLongObject is the type that represents arbitrary-precision integers. With a bit of searching, we find a file called Objects/longobject.c. Depending on your preference, you might first want to look into the corresponding header file, but since we are looking for an implementation for an algorithm, the C file makes sense. The very first search result for "div" shows a forward declaration of the following function:
static PyLongObject *x_divrem(PyLongObject *, PyLongObject *, PyLongObject **);
The function body is found in line 3304 and contains an illuminating comment: "We follow Knuth [The Art of Computer Programming, Vol. 2 (3rd edn.), section 4.3.1, Algorithm D]". So they are using an integer division algorithm from the classic reference textbook "The Art of Computer Programming" by Donald Knuth.
If the fact that mathematical notation also has types of some sort made you curious, you are onto something, because the idea of types in programming languages comes from mathematics! As we will soon see, mathematical sets are a good way of conceptualizing types.
Back to the problem at hand: Our C++ and Python code allowed divisions by zero. The mathematical definition of our division function was more powerful than both the C++ and Python code, because in the former we were able to exclude the malformed value (0 for the denominator) from the domain of the function. Translating this to a programming language would mean that it should be impossible to call the function div with 0 as the second argument. "Impossible" here can mean different things. It can mean "literally impossible", as in "there is no way to express having 0 as the second argument to div", or it can mean "impossible to compile/run such a program". The former would require a kind of newspeak programming language that has no concept of zero-valued denominators, which is hard to conceptualizeWe could try by defining the number representation in this language in a way that we simply can't express the number 0. Maybe each number n is written as n repetitions of the 🍣 emoji. To make the picture complete, our language would need prefix notation for calling functions. Then, the div function with two integer arguments could be written as: div 🍣🍣🍣🍣 🍣🍣 to express \(\frac{4}{2}\). It would then be impossible to divide by zero, because the expression div 🍣🍣🍣🍣 is malformed, as div expects two arguments. Unfortunately, this would also mean that we can't have a zero-values nominator, something which is perfectly legal in math. And negative numbers also can't really be expressed... Maybe we would have to define negative numbers -n as n repetitions of 🍕... . Luckily, the latter definition is easier to achieve, as the act of checking the adherence to syntax is already part of both compilers and interpreters.
So what we are looking for is a way to encode the idea of a non-zero integer into the language as a type! How exactly this looks depends on the way type checking is implemented in each programming language. For example, C++ has somewhat lenient rules for conversions between types:
std::cout << div(3.0, 1.5);
Output: 3
Passing float values to a function that is declared to accept int values works in C++, because there is an implicit conversion between float and int. This can lead to subtle and confusing bugs: 3.0 divided by 1.5 should be 2.0, but in the conversion to the int type, numbers are always rounded down to the next lowest integer, so what we actually computed was div(3, 1), which of course is 3. The compiler could warn about such implicit conversions, but the language itself explicitly allows them.
🔤 Exercise 2.3.2
Try playing around with the code example to see which compiler issues a warning for the conversions and which one doesn't.
💡 Need help? Click here
Note that Python is a bit smarter:
>>> div(3.0, 1.5)
2.0
Rust on the other hand is very strict and does not allow implicit conversions even between primitive types:
fn div(a: i32, b: i32) -> i32 {
a / b
}
fn main() {
div(3.0, 1.5);
}
This program does not compile:
error[E0308]: arguments to this function are incorrect
--> <source>:16:5
|
16 | div(3.0, 1.5);
| ^^^ --- --- expected `i32`, found floating-point number
| |
| expected `i32`, found floating-point number
|
note: function defined here
--> <source>:10:8
|
10 | fn div(a: i32, b: i32) -> i32 {
| ^^^ ------ ------
Definition: We just saw our first example of the strictness of a type system: The number of implicit conversions it allows between different types. Rust is more strict than C++ or Python because it allows fewer conversions.
Fixing the gap in div using the Rust type system
Since Rust is so strict, we can use this strictness to our advantageBe prepared to be annoyed by the level of strictness of the Rust compiler. You will have to be very explicit about a lot of things, which can get frustrating while learning. This is a common criticism regarding the learning curve of Rust. At the same time, this strictness does prevent a lot of runtime bugs and was a concious design decision of Rust. Decide for yourself if it was worth it.. To prevent passing 0 as the second argument to div, the type of the second argument has to be something not convertible from e.g. the literal 0. A first place to look is the list of all primitive types in Rust. The Rust language documentation states that these are all the primitive types:
- Boolean — bool
- Numeric — integer and float
- Textual — char and str
- Never — ! — a type with no values
We need a numeric type, but none of the primitive numeric types naturally excludes zero. The unsigned types all start at 0, the signed types all include 0 as well. The two floating-point types f32 and f64 use IEEE-754 encoding, which also can represent 0 (technically it can represent -0.0 and +0.0). So the primitive types are out of the question. But we can write our own types in Rust (these are called user-defined types):
pub struct NonZeroI32(i32);
fn div(a: i32, b: NonZeroI32) -> i32 {
a / b.0
}
The NonZeroI32 type is a tuple struct, which is a convenient way of writing a Rust type that simply wraps another type. You will often encounter these tuple structs for various wrapper types. Since Rust has strict type checking rules, we can only pass a value of the type NonZeroI32 as the second argument to div, which prevents this code:
div(2, 0);
Unfortunately, it also prevents this code:
div(2, 1);
The correct way to invoke div is to first create an instance of NonZeroI32 and pass that as the second argument. We can do that in-place like so:
div(2, NonZeroI32(1));
Unfortunately we have gained nothing, because NonZeroI32 itself accepts any i32 value, even 0:
div(2, NonZeroI32(0)); // :(
The common way to deal with that is to restrict the means through which we can construct an instance of the type NonZeroI32. We can use the visibility and privacy rules of Rust to make the constructor of NonZeroI32 private:
mod safety {
// `pub` exports the struct definition from the module `safety`, so it can be accessed from the outside!
// The inner field `i32` is NOT declared `pub`, so outside code can't access it. If you would want that,
// write `pub struct NonZeroI32(pub i32)`. Also try out what happens if you write `struct NonZeroI32(pub i32)`
pub struct NonZeroI32(i32);
}
// Now we can't create an instance of NonZeroI32 from a raw number anymore:
div(2, safety::NonZeroI32(1)); // Does not compile!
This is like making the constructor private in C++. Now we have to re-introduce a way to create instances of our type. We do so by defining a constructor-like function within the module safety and declaring that function pub, so it gets exported from the module, making it accessible to outside code. Since the function itself sits within the safety module, it has full access to all the private fields of NonZeroI32:
mod safety {
pub struct NonZeroI32(i32);
pub fn make_non_zero(val: i32) -> NonZeroI32 {
NonZeroI32(val)
}
}
div(2, safety::make_non_zero(1));
div(2, safety::make_non_zero(0));
You might think that we still haven't gained anything, after all we can still write safety::make_non_zero(1). But now we have a function that creates the instances of NonZeroI32, and we can perform a check inside of that function to disallow zero as an argument:
pub fn make_non_zero(val: i32) -> NonZeroI32 {
if val == 0 {
panic!("Not allowed to create NonZeroI32 from 0");
}
NonZeroI32(val)
}
This is not perfect, because our check happens at runtime and we simply crash if the wrong value is passed to make_non_zero, but it is a start. In chapter 4 we will learn about more powerful ways that Rust gives us to get rid of the runtime panic!. For now, ignoring the construction of NonZeroI32, we have introduced a new concept: A type that is guaranteed to never be zero. If we have an instance of NonZeroI32 (outside of the safety module), we know that it will never be zero. There is just one last caveat however, which is that we lost a way to access the inner i32 value from NonZeroI32. Let's fix that with a getter function for now:
mod safety {
pub struct NonZeroI32(i32);
impl NonZeroI32 {
pub fn inner(&self) -> i32 {
self.0
}
}
}
fn div(a: i32, b: safety::NonZeroI32) -> i32 {
a / b.inner()
}
❓ Question
What other (mathematical) functions would the NonZeroI32 type be useful for?
💡 Click to show the answer
An example is the logarithm function (to any base), which is undefined for the value 0.
The types that Rust provides
Rust has a bunch of built-in types as well as many useful types in its standard library. We already saw primitive types and structs as well as functions, but there are many more. For a great visual overview that links to the Rust documentation of each type, check out this guide on rustcurious.com.
Recap
We learned about the role of the type system in that it checks certain properties of our code and upholds certain invariantsAn invariant is a property that must always be true. We saw that some language are more strict than others when it comes to checking these invariants. Rust is very strict, and we learned of a way to use that strictness to our advantage to express properties of function arguments that go beyond the common primitive types that we typically might use.
2.4. Rust and ad-hoc polymorphism using traits
In this chapter we will dive deeper into the Rust type system and look at how interface-like behavior is realized in Rust through traits. Once we know about traits, we can also write powerful generic code using type constraints. At the end of this chapter you will know how to write your own traits and use them in generic code, and how to use the different traits for creating and converting types that the Rust standard library offers.
A deeper look at type conversions
In the previous chapter we talked about type conversions and saw that Rust doesn't do any implicit (i.e. automatic) conversions between types for us. We used this fact to build an abstraction for non-zero integers to constrain the domain of functions on the integers. In this chapter, we will improve the ergonomicsA common term used by programmers that translates to "How much code do I have to write/repeat when using this thing?" of the NonZeroI32 type. Before reading on, first take a look at our current implementation of NonZeroI32 and a usage example, and answer the following question for yourself:
mod safety {
pub struct NonZeroI32(i32);
impl NonZeroI32 {
pub fn inner(&self) -> i32 {
self.0
}
}
// Other code omitted...
}
fn div(a: i32, b: safety::NonZeroI32) -> i32 {
a / b.inner()
}
❓ Question
From an ergonomics point of view, what do you like about NonZeroI32 and what do you think could be improved? For things that you dislike, try to phrase it in a way that is specific to the way the type is used. Here is a first example: We need a special function inner() to access the value that NonZeroI32 wraps, which requires more typing than the tuple-syntax value.0.
💡 Click to show the answer
Advantages of NonZeroI32:
- Solves the problem of defining functions that must not take
0as a parameter - Explicit notation makes programmer think about the usage of the function ("Wait, this function doesn't accept two numbers, why is that? Ooooh because I can't divide by zero, makes sense, so I better think about my surrounding code if zero might be a valid edge case that I haven't though about!")
Disadvantages of NonZeroI32:
- Code of
NonZeroI32must be within a separate module to make visibility trick work - We have to write trivial boilerplate code (the
inner()function) - The current constructor function
safety::make_non_zerois pretty verbose (and will fail only at runtime) - It only works for
i32values. What if we want non-zerou8values, or any other integer or even floating-point type?
Let's tackle some of these shortcomings, starting with the problem of accessing the inner i32 value. Currently we have the inner() function, which is a more verbose way of simply doing b.0 in the function body of div. We can think of inner() as another type conversion, from NonZeroI32 to i32Technically from &NonZeroI23 to i32, but we'll talk about references (&) later. To make our thinking a bit easier, it makes sense to use a different syntax when we talk about function definitions. Instead of describing our function in natural language ("A conversion from type A to type B") or in full Rust code (fn inner(&self) -> i32), we can take inspiration from the mathematical notation that we saw in the previous chapter. Recall this definition of the mathematical function for integer division:
\[ f : \mathbb{Z} \times (\mathbb{Z} \setminus {0}) \to \mathbb{Z}, \quad f(x, y) = \lfloor \frac{x}{y} \rfloor \]
The first part describes only the types that are involved, without giving them any names or anything. We can do the same thing in Rust and describe only the input and output types of a function:
fn(NonZeroI32) -> i32
// For brevity, we will omit the `fn()` part:
NonZeroI32 -> i32
Definition: This special syntax is called the function signature. Multiple functions with different names can have the same signature if they have the same set of input argument types and output type. This will become useful later on when we talk about passing around functions to other functions!
An interesting property of the function signature syntax is that every function signature describes a total function:
Definition: A function \(f\) from domain \(S \subseteq X\) to codomain \(Y\) is called total if \(S = X\). In natural language: "\(f\) is a total function if it is defined for every element of \(X\)"
Going from a NonZeroI32 value to the inner i32 value always works, because every possible NonZeroI32 has a valid inner i32. What about the opposite direction?
i32 -> NonZeroI32
This is obviously not a total function, as we do not want to allow to go from 0 to a NonZeroI32 value! Functions that are only defined on a subset of the input domain are called partial functions. Most programming languages do not have a way to express partial functions at the type level and instead fall back to runtime checks. This is exactly what we did when we used the panic! functionTechnically panic! is not a function but a macro: We deferred something that we could not express through types (i.e. at compile-time) to a runtime check. For a dynamically-typed language such as Python, almost all type checks are performed at runtime, which is why we see fast iteration cycles in Python, but typically a lot more runtime errors than e.g. in Rust.
Rust does provide a way to express partial functions, but you will have to wait a bit longer until we will cover that topic. If patience is not your strong suite, check out the section on Enums and Pattern Matching from the Rust book.
For now, let's stick with the conversion from NonZeroI32 to i32, for which we wrote a custom inner() function. It turns out that such one-to-one conversions (from type A to type B) are a very common pattern in Rust. The language still does not do conversions automatically, but the Rust standard library has defined a common interface for type conversions. You might recall from chapter 2.2 that Rust is not an object-oriented language, so talking about interfaces in Rust might confuse you. We use the term interface a bit more informally to mean "A way to define a common set of behavior". The technical term for interfaces in Rust is traits, and we will look at them now!
Traits - Defining common behavior in Rust
Before continuing with this section, you are encouraged to read the chapter on Traits in the Rust book. It talks about the idea behind traits and gives a bunch of examples on how to use them.
To not lose sight of the problem, we are looking for a way to either simplify or standardize the type conversion NonZeroI32 -> i32 and maybe also the reverse direction i32 -> NonZeroI32 (with the runtime panic! if we pass in 0). You might notice some symmetry while looking at these type signatures:
i32 -> NonZeroI32
NonZeroI32 -> i32
The first line is a conversion from the i32 type into the NonZeroI32 type, while the second line is a conversion from the NonZeroI32 type into the i32 type. We could just as well swap the "from" and "into" in the first statement: A conversion into the i32 type from the NonZeroI32 type. We might write it like this, by flipping the arrow:
i32 <- NonZeroI32
This is not a valid type signature, but it illustrates the symmetry of type conversions. This gives us two ways of implementing type conversions: One from the perspective of the source type, and one from the perspective of the target type. Our safety::make_non_zero function from the previous chapter was written from the perspective of the target type NonZeroI32. This is hard to see since we wrote it as a free-standing function, but we could also have implemented it as a function on the type NonZeroI32:
impl NonZeroI32 {
pub fn from_i32(val: i32) -> Self { // "Self" is the same type as "NonZeroI32", it's a shorthand notation when inside an `impl` block
// Implementation is the same as before
}
}
// Call it like so:
div(2, safety::NonZeroI32::from_i32(1));
We could also have written this conversion from the perspective of the source type i32, however we can't do so using an impl i32 block, as the Rust visibility rules prevent us from implementing new functions on what is called a foreign type, i.e. a type that we did not define within our own code. But let us assume for now that we couldWe actually can, using a small workaround that is considered idiomatic Rust. Stay tuned!, in which case the conversion would look like this:
impl i32 {
pub fn as_non_zero(&self) -> safety::NonZeroI32 {
safety::NonZeroI32::from_i32(self)
}
}
It might seem redundant to write the code in this way, as it simply defers to the code we wrote previously from the perspective of the target type. However if we could write the code in this way, it would allow us to call the non_zero_i32 function on the i32 type! You might not have seen such syntax from other programming languages, typically primitive types don't have methods that you can call on them, but in Rust this is allowed and looks like this:
div(2, 1.as_non_zero());
That is a significant improvement in ergonomics! Unfortunately we can't write the implementation of as_non_zero on the i32 type. What we learned however is that we can (in theory) improve ergonomics of type conversions by making use of the symmetry inherent to the type conversions. B::from(a) is the same thing as a.to_b()! This is a general pattern, and as programmers we love patterns, as they are ways to prevent us from repeating ourselves! So let's look for a way to exploit this pattern to make arbitrary type conversions easier to write!
First, we need a way to state that a type A converts to another type B. An interface for type conversions, if you will. We use the trait keyword to define an interface-like type in Rust. We will also take our learning from the previous example and instead of defining a ToB trait, use the inverse FromA notation. We will see in a second why this is a good idea:
trait FromA {
fn from(value: A) -> Self; // Self refers to the type that we will implement this trait ON
}
We could then implement this trait on any type B that we want to convert from an A:
impl FromA for NonZeroI32 {
fn from(value: A) -> NonZeroI32 { // Could have written "-> Self", but "-> NonZeroI32" makes it clearer what the `from` function returns!
// TODO Figure out how `A` converts to `NonZeroI32`...
}
}
// Call like this:
let a: A = ...; // Get an `A` from somewhere
let v = NonZeroI32::from(a);
We used a placeholder name A, but that doesn't make much sense, after all what exactly is A? What we really mean is "any type", for which the corresponding language feature is called generics, as we already saw in chapter 2.2. This is the same feature that makes it possible to write a std::vector<T> class in C++ that works for any type T: std::vector<int>, std::vector<std::string>, std::vector<std::vector<int>> etc. So let's adjust our trait to take any type AYou might be used to the letter T when seeing generic code. There is nothing special about T, it doesn't even have to be a single letter. std::vector<AnyType> would have been possible as well. T is a shorthand for "type", it is simple to write, so it became a default. In our case, we talked about abstract types A and B, so we stick with A now.:
trait From<A> {
fn from(value: A) -> Self;
}
Now, we can implement this trait for any type we want:
impl From<i32> for NonZeroI32 {
fn from(value: i32) -> NonZeroI32 {
if value == 0 {
panic!("Can't create NonZeroI32 from 0");
}
NonZeroI32(value)
}
}
It is also possible to implement the same trait on the same type with a different generic argument:
impl From<i16> for NonZeroI32 {
fn from(value: i16) -> NonZeroI32 {
Self::from(value as i32)
}
}
Here we used the language-feature of explicit type casts between primitive types using the as keyword to delegate to the From<i32> implementation! Now we can convert from i32 and i16 values to NonZeroI32!
We are now ready to implement a bit of magic, by looking at the opposite direction of the type conversion. We have B::from(a) but what we really want is a.into() to make a B. The signature of into() is A -> B, just as the signature of from() is A -> B, but the difference is that from() is a function on the type B, whereas we want into() to be a function on a value of A. Functions on values are often called member functions and they are all the functions that take a first argument named self in RustOr any of the variants: &self, &mut self. self is very similar to this in other languages.
Comparison: Functions on types in Rust are the same thing as static member functions in C++. Functions on values (called instances) of a type in Rust are the same thing as non-static member functions in C++. Only if you have an instance of a type do you get access to this/self, which points to that exact instance.
Let's define another trait:
trait Into<B> {
fn into(self) -> B;
}
Now traits can be implemented on foreign types, even on primitive types, so we are allowed to do this:
impl Into<NonZeroI32> for i32 {
fn into(self) -> NonZeroI32 {
NonZeroI32::from(self)
}
}
impl Into<NonZeroI32> for i16 {
fn into(self) -> NonZeroI32 {
NonZeroI32::from(self)
}
}
But notice the code duplication: We had to implement Into<NonZeroI32> on both the i32 and the i16 types separately, even though the function body looks the same in both cases. We know that we can implement Into<NonZeroI32> on all types T if NonZeroI32 implements From<T>. Rust lets us implement traits on generic types as well, which is a very powerful feature:
impl<T> Into<NonZeroI32> for T {
fn into(self) -> NonZeroI32 {
NonZeroI32::from(self)
}
}
This does not yet compile, as the compiler can't guarantee that there is actually a function NonZeroI32::from(T) that returns a NonZeroI32! There are obvious examples where such a function does not (yet) exist, for example the f32 type, for which we haven't implemented From<f32> on NonZeroI32. So we have to add a type constraint that says "Only those types where NonZeroI32 implements From<T>". This is how it looks like:
impl<T> Into<NonZeroI32> for T where NonZeroI32: From<T> {
fn into(self) -> NonZeroI32 {
NonZeroI32::from(self)
}
}
Now we get the ergonomics we want:
div(2, 0.into());
If you try to compile this code, you might notice that it doesn't work because the Rust compiler complains about multiple defined names. As it turns out, the From/Into traits are so useful that the Rust standard library provides these exact traits and Rust auto-imports them into every Rust file you write! To learn more about From and Into, you can look at the corresponding section in "Rust By Example". One thing that is worth looking at is the way Into is implemented for any type that itself implements FromThis is called a blanket implementation, as it covers all types like a blanket:
impl<T, U> Into<U> for T // For all ordered pairs of types (`T`, `U`) implement the `Into<U>` trait
where // But only those pairs where type `U` implements the `From<T>` trait
U: From<T>,
{
fn into(self) -> U { // Implementation of the `into` function that creates a `U` value from a `T` value (`self` has type `T`)
U::from(self) // Defer to the `from` function of the `From<T>` trait!
}
}
What this blanket implementation does is it allows us to implement a conversion just once (using impl From<OtherType> for OurType) and gives us the .into() function on OtherType for free!
❓ Question
From<T> and Into<U> represent binary relations. As types are like sets, instances of a type can be thought of as elements of the set of the type, i.e. 'An instance of the type U' is similar to the math notation \(x \in U\). Suppose T and U are the same type. Are From<T> and Into<T> reflexive, symmetric, and/or transitive relations? Implement the necessary Rust functions to realize these properties.
💡 Click to show the answer
Reflexivity
Going from an instance of type T to an instance of type T is a no-op and works for all possible instances of T, so From<T> and Into<T> are reflexive
Symmetry
From<T> and Into<U> are also symmetric. The only possible conversion is from each value to itself (i.e. x.into() == x for all \(x \in T\)), but that conversion does also work in the opposite direction.
Transitivity
By similar reasoning, From<T> and Into<T> are also transitive (i.e. x.into().into() == x for all \(x \in T\))
The only function we have to implement to realize this is the following:
impl<T> From<T> for T {
fn from(t: T) -> T {
t
}
}
The reflexivity of Into<T> then follows from the previous blanket implementation.
Standard traits for creating and converting types
These conversion traits can be found in the std::convert module of the Rust standard library. If you skim the documentation, you will see a bunch of explanations that we have not yet covered:
- Both
FromandIntoonly handle value-to-value conversions. To understand what that means we have to learn what a value in Rust is and how it differs from references. Then we can understand the two additional traitsAsRefandAsMut, which deal with reference conversions. References are covered in chapter 3.3 - Conversions might fail, so Rust provides
TryFromandTryIntoas fallible versions ofFromandInto. We will learn about how to represent computations that can fail in chapter 5
For now, let's look at one other trait that is easier to understand with our current level of knowledge: Default. While we previously talked about conversions, this trait is all about creating values. It serves a similar purpose to the default constructor in C++, in that it lets us create a value of a type from "thin air". Just as in C++ we can have only one default constructor for a type, we can only have one implementation of Default for a type. In fact, any specific trait can only be implemented at most once for any typeYou might have noticed in the previous section that we implemented From twice on the NonZeroI32 type. This is different though, since one implementation was of From<i32> and the other of From<i16>. The way the Rust type system works, these are two distinct traits, which makes it legal to implement both on the NonZeroI32 type.. If we choose to implement Default, this is the Rust way of stating "This is how to default-construct a value of this type".
❓ Question
Can you guess how the Default trait is defined?
💡 Click to show the answer
trait Default {
fn default() -> Self;
}
The Default trait provides one single method default with the following signature: () -> Self. Unpacking this signature is insightful:
- This function takes zero arguments, as it creates a default instance out of thin air. In C++ we would have written "zero arguments" as
void, the corresponding Rust type is called the unit type and is written as(). Perhaps a bit confusingly,()is a type name and also the only valid value of that type. So creating an instance of()is written as() - The
Selfkeyword denotes a specific kind of type that is only meaningful within animplblock. In the signature within theDefaulttrait it can be read as "Whatever the type of the current implementor of this trait is"
To illustrate the second statement, let's implement Default for a new type:
struct NewStruct(i32);
impl Default for NewStruct {
fn default() -> Self {
// "Self" and "NewStruct" are the same type within this impl block!
NewStruct(42)
}
}
Default has two functions: First, it gives a common way of writing and calling a default constructor on a type. In our previous example, we could then call NewStruct::default() to obtain a default instance of NewStructNote that even though this gives us a default instance, it doesn't guarantee that every value returned from calling default() is actually the same. Take a UUID as an example: We do want every new UUID to be different, so UUID::default() returning a different value every time it is called actually makes sense.. The second feature is that it can be a useful generic type constraint, if we are in a generic function (or generic type) that requires creating instances of the generic type. A simple but contrived example would be to define a global function that creates a default instance of any type:
fn construct<T: Default>() -> T { // "<T: Default>" is equivalent to writing "where T: Default" after the return type.
T::default()
}
// Equivalent syntax:
fn construct<T>() -> T
where T: Default {
T::default()
}
Just as in the blanket implementation of Into, this function defers to the Default trait and its default() function. This works because the type constraint T: Default tells the compiler that the Default trait must be implemented for whatever type we call construct with. If this is guaranteed the compiler will then know how to find the implementation of Default and the corresponding default() function.
Traits vs. interfaces in other languages
Traits are a special way of providing interface-like functionality in a programming language. Since interfaces are about standardizing shared behavior on types, you might be used to object-oriented concepts such as inheritance and virtual functions to realize interfaces. C++ certainly handles them like that, though it doesn't have a dedicated interface keyword (compared to Java for example). A limitation of virtual functions is that they only let you write shared functionality for member functions. There are no virtual static functions in C++Though we can achieve similar behaviour through function pointers! In Rust, we are allowed to define non-member functions on traits: Default does that, as does the From trait. If you are interested in programming language history, the inspiration behind traits in Rust are type classes in Haskell. On the technical side, both interfaces using virtual functions as well as traits are forms of polymorphismA term borrowed from biology, based on the greek term polymorphos, meaning "of many forms".
Definition: Polymorphism in programming languages refers to strategies for using the same symbol to represent multiple different types.
There are three main approaches to polymorphism in use by programming languages today:
- Ad-hoc polymorphism
- Parametric polymorphism
- Subtyping
For an in-depth explanation of these approaches, the paper "On understanding types, data abstraction, and polymorphism." by Cardelli and Wegner {{#cite cardelli1985understanding}} is a worthwhile read. We will stick to a concise overview focused at explaining the difference between Rust traits and interfaces in other programming languages.
Ad-hoc polymorphism is best understood through operator overloading:
std::cout << 42 << "," << 42.0;
In this C++ example, operator<< is (ab-)usedIt is debatable whether using the symbol << for stream insertion was a good choice, as it does clash with its usage as the bit-shift operator: 2 << 8 to pipe data into stdout. The same symbol (<<) has different meaning and executes different code, depending on the type argument(s) that it is called with. This is made possible through operator overloading in C++ and is a form of polymorphism. It is ad-hoc because all different overloads must be known statically (i.e. at compile-time). If the corresponding header files containing the implementation of operator<< for int and const char* are not included, this code will not compile.
Rust traits work in the same way as operator overloading (they are a form of ad-hoc polymorphism): If we write code like let val: NonNegativeI32 = 2.into():, the call to into() is semantically equivalent to Into::<NonNegativeI32>::into(0). Since we can call into() on many different types, the into() function is effectively overloaded based on the type we call it on. Just as with operator overloading, calling trait functions on a type only works if the compiler can see the impl block of the trait for that type. Therefore, the set of all existing implementations of the trait is always known at compile-time, which is why ad-hoc polymorphism is sometimes called closed polymorphism.
🔎 Aside - Type inference
The following statement poses an interesting questions as to how the Rust compiler knows what Into<T> implementation it should call the into() function on:
#![allow(unused)] fn main() { let val: NonNegativeI32 = 2.into(); }
With out the type annotation (: NonNegativeI32), this code does not compile. The interesting part is that the annotation is on the variable we assign to, not on the into() function call itself! Contrast this with C++ and a function such as std::make_unique<T>, for which you have to specify the template parameter when you call it:
std::string val = std::make_unique<std::string>();
// Compilation of the next line fails with "couldn't deduce template parameter '_Tp'"
// std::string val = std::make_unique();
The Rust language has a feature called type inference which makes it possible to either omit type declarations altogether, or have the type of a function or trait be inferred from the context, as in the previous Rust example. Compared to C++, this makes Rust less verbose when it comes to type declarations, even though Rust has the stricter type system. The following code illustrates full type inference with into():
#![allow(unused)] fn main() { fn foo(v: NonNegativeI32) {} foo(2.into()); // Compiles and `into()` is deduced as `Into::<NonNegativeI32>::into()` }
It is also worth noting that we could not have written 2.into<NonNegativeI32>() in Rust, for two reasons:
- Specifying generic arguments in expressions requires special syntax called the turbofish syntax:
::<Type>instead of<Type>. This is necessary to make parsing of Rust code unambiguous into()is not itself a generic function, but a function on a generic trait. To correctly resolve that trait, we can use this syntax:Into::<NonNegativeI32>::into(2). This also explains what the method call operator.is, namely syntactic sugar for calling a function through its type and passing theselfvalue as the first argument
Subtyping works quite differently and usually defers the resolution of which function to call on a type to some runtime data structure. The canonical Java example listed on the Wikipedia page for Polymorphism explains it very succinctly:
abstract class Pet {
abstract String speak();
}
class Cat extends Pet {
String speak() {
return "Meow!";
}
}
class Dog extends Pet {
String speak() {
return "Woof!";
}
}
static void letsHear(final Pet pet) {
println(pet.speak());
}
static void main(String[] args) {
letsHear(new Cat());
letsHear(new Dog());
}
A function letsHear take instances of type Pet or any subtype of that type. Whereas in ad-hoc polymorphism, different functions were executed through the same symbol, implementation of letsHear is the same for Cat and Dog. What is different is the implementation of speak for these types, which is only resolved at runtime through a virtual table (vtable for short): A data structure containing a function pointer for each virtual function in the base type. This process of looking up the correct function based on the type at runtime is called late binding.
Compared to ad-hoc polymorphism, late binding is what enables subtyping to work with unknown types at compile-time. New subtypes of Pet can be written by anyone even after the code for letsHear was compiled. This is impossible with ad-hoc polymorphism. The downside of late binding is that is happens at runtime and thus has a runtime cost, compared to ad-hoc polymorphism which is resolved entirely at compile-time.
But what if we still want to use Rust traits and let other code add new types that implement the trait? This is where parametric polymorphism comes into play. Instead of writing code with concrete types, we make the type of a function argument or member variable a parameter. The corresponding language feature is often called generic code. We already saw generic code in Rust in the definition of the From and Into traits:
trait From<A> {
fn from(value: A) -> Self;
}
The function from takes a single argument of a parametric type, which can be read as "This function takes any type". Since traits themselves are also a form of polymorphism, it can get confusing to distinguish the two, so let's look at a generic function that is not associated with a trait instead:
fn equals<T>(l: T, r: T) -> bool {
l == r
}
This function takes two arguments of the same type T, but what T is exactly is undefined. It is not any specific type but instead a placeholder where a specific type will be filled in at some point. Just like with subtyping, this function has the same implementation for every possible type. It does however defer to another function (the == operator), which will be implemented differently depending on the specific type that will be filled in for T. We'll get to that in a moment. First, let's look at what happens if this code is called:
equals(2, 3);
When the compiler encounters this expression, it has to find the correct function equals to call with the given arguments. Integer literals have the default type i32 in Rust, so the compiler will look for a function called equals that takes two arguments of type i32The return type is ignored for now, and never plays a role in function resolution as Rust functions are uniquely determined by their name and argument types, not by the return type. Rust also does not support function overloading, so each fully qualified name of a function (with module paths) must be unique. Two functions with the same name but different arguments are not allowed.. It does find the generic function fn equals<T>(l: T, r: T) -> bool, which is a potential candidate. This function is polymorphic, which gives two possible ways of generating the actual machine code for this call: Either keep equals as a polymorphic function and perform late binding, or turn it into a non-polymorphic function that can be resolved at compile-time. Rust chooses the latter path and will turn the polymorphic equals<T> function into a specific equals<i32> function in a process called monomorphization: Going from a many-shaped function to a function with a single shape. At this point the compiler will generate a so-called instantiation of the equals function by replacing the parametric type T with i32. In doing so, it has to check if the resulting code is valid, which requires checking if the expression l == r is valid if l and r are of type i32.
At least this is what C++ would do if you were using templates. Rust generics work a bit different: Even though the equals function is parametric over an arbitrary type T, every usage of that type implies some capabilities. The Rust language requires that these capabilities are stated explicitly as generic bounds on the type parameter(s). In our case, we have one capability: The existence of an overload of the == operator for type T. Luckily, operators are only syntactic sugar in Rust, every operator is provided by a specific trait. The == operator is provided by the PartialEq trait. We already saw how to add constraints to generic types, stating "This type must implement this specific trait", so we can fix our equals code:
fn equals<T: PartialEq>(l: T, r: T) -> bool {
l == r
}
Monomorphization turns this generic function into the following function:
fn equals(l: i32, r: i32) -> bool {
l == r
}
Since there is an impl PartialEq for i32 block somewhere in the Rust standard library, the type constraint i32: PartialEq is met and i32 is a valid type for usage with the generic equals function. Notice that after monomorphization, ad-hoc polymorphism kicks in to find the correct overload of the == operator (i.e. the correct implementation of the PartialEq trait) for the type i32.
Observation: While Rust does allow unconstrained type parameters, as soon as we try to use such a type, we have to introduce type constraints so that the compiler can guarantee that the usage pattern is valid. The only way to constrain a type in Rust is by specifying which traits the type must implement. Therefore, parametric polymorphism and ad-hoc polymorphism always go hand in hand in Rust.
It is worth to compare the previous code example with an equivalent example written in a C++ version prior to C++20 (which introduced concepts, a similar feature to Rust traits):
template<typename T>
bool equals(T l, T r) {
return l == r;
}
C++ templates work through something called duck typing, which means the compiler will look for functions that look like the usage pattern we need. In this case, an operator== that takes two parameters of the same type and returns something that is convertible to bool. This has several downsides:
- The usage patterns are not obvious. Since C++ allows implicit conversions, this might find an
operator==that takes arguments of some other typeU, given that there is a non-explicitconversion fromTtoUimplemented somewhere. In more complex examples, there might also be hidden usage patterns in the code that are not desired, such as the existence of specific constructors or conversion operators. - Since the type requirements are never explicitly stated, this can lead to confusing compilation errors if a template function is called with invalid arguments. Whereas in the Rust example, a compilation error would state "the trait
PartialEqis not implemented forType" if called with aTypethat doesn't implementPartialEq, a C++ compiler will instead complain about a missing overload ofoperator==. With such a small example, the difference in error messages might not seem big, but experienced C++ programmers know that this can quickly get out of hand for heavily templated code.
To defend C++, with C++20 concepts were introduced as a language feature, which allow generic type constraints in a very similar way to traits in Rust:
#include <concepts>
template<typename T>
requires std::equality_comparable<T>
bool equals(T l, T r) {
return l == r;
}
Recap
In this chapter we learned what traits are in Rust, and how they can be used to defined shared behavior of types as well as to make generic code possible. We saw the idiomatic ways of converting between types and creating default instances of types. We also learned about the concept of polymorphism and three different ways that it is typically realized in a programmnig language.
Closing exercises
🔤 Exercise 2.4.1
The Rust standard library provides the Ord trait for types that form a total order. Informally, this is the trait that gives you the comparison operators <, <=, >= and >. Write a generic function that returns the largest element of exactly three arguments.
💡 Need help? Click here
fn max_element<T: Ord>(a: T, b: T, c: T) -> T {
if a >= b && a >= c {
a
} else if b >= a && b >= c {
b
} else {
c
}
// Or as a one-liner using the provided `max` method from the `Ord` trait:
// a.max(b.max(c))
}
🔤 Exercise 2.4.2
As we learned, Rust uses monomorphization to turn generic types into specific types at compile-time. This means that potentially multiple copies of the same function for different specific types have to be compiled and included in the binary you compile. Take the following small Rust program and compile it in debug mode (the default behavior of running cargo build):
use std::fmt::Display; fn foo_generic<T: Display>(val: T) { println!("The value is: {val}"); } fn main() { foo_generic(42); foo_generic("42"); foo_generic(false); }
Use your platform-dependent tool of choice for examining the symbols within the resulting executable (e.g. nm -C $EXECUTABLE on Linux) and try to find the symbol(s) for the monomorphized function foo_generic. What do you observe?
2.5. Rust and the borrow checker
In this chapter, we will learn about a unique feature of Rust called the borrow checker and how it relates to the concept of ownership. Compared to the previous chapters, this chapter will be quite brief because the concept of ownership and the Rust borrow checker are covered much more in-depth in chapter 3. Still it is worth giving a preview of this topic, as it is immensely important to systems programming.
The concept of resource ownership
In chapter 1, we learned that one of the key aspects that make systems software special is its usage of hardware resources. A systems programming language has to give the programmer the tools to manage these hardware resources. This management of resources is done through the resource lifecycle, which consists of three steps:
- Acquiring a resource
- Using the resource (technically optional, but if you acquire a resource you might as well use it)
- Releasing the resource back to the source it was acquired from
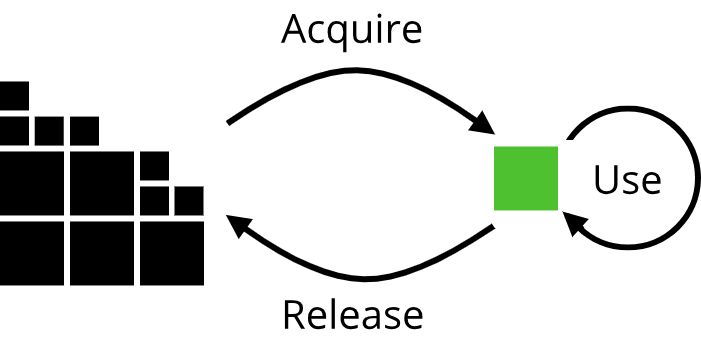
The operating system usually manages hardware resources, but in systems without one (such as embedded systems) programmers access the hardware directly. We will look closer at the different ways to access resources in later chapters. For now, we will focus on the consequences of this resource lifecycle. A direct consequence of the process of acquiring and releasing a resource is the concept of a resource owner. Simply put, the owner of a resource is responsible for releasing the resource once it is no longer needed. Without a well-defined owner, a resource might never get released back to its source, meaning that the resource has leaked. If resources keep being acquired but never released, ultimately the source of the resource (i.e. the computer) will run out of the resource, which can lead to unexpected program termination. As systems software often constitutes critical systems, this is not something that should happen. You don't want your airplane to shut down simply because some logging agent kept hoarding all the planes memory resources.
Different languages have different ways of dealing with ownership, from C's "You better clean up after yourself!"-mentality to the fully automatic "Room service cleans up for you, but you don't get do decide when"-approach of garbage-collected languages such as Java or C#. Rust has a very special approach to resource ownership called the borrow checker.
Borrow checking in a nutshell
The main problem with the resource lifecycle and ownership is that keeping track of who owns what can get quite complicated for the programmer. Languages that manage resource lifecycles automatically, for example through garbage collection, do so with a runtime cost that might not be acceptable in systems software. Here is where Rust and its borrow checker come in: Instead of figuring out which resources should be released at which point, Rust has a clever system that can resolve resource ownership at compile-time. It does so by annotating all resources at compile-time with so-called lifetime specifiers which tell us how long a resource is expected to live. There are certain rules for these lifetimes that are then enforced by the compiler, preventing many common problems that arise in manual resource management, such as trying to use a resource that has already been released, or forgetting to release a resource that is not used anymore. These rules are what makes Rust both memory-safe and thread-safe, without any additional runtime cost.
Unfortunately, we will see in chapter 3 that it is not possible to determine all resource lifecycles completely at compile-time, so there are cases where the borrow checker will not be able to aid the programmer. Additionally, the borrow checker has a very strict set of rules that can be confusing at first, so we will spend some time to understand how it operates. Is is worth noting that, while the borrow checker is somewhat unique to the Rust programming language, similar concepts have been employed in other languages through external tools called static analyzers, which scan through the code and try to uncover common errors related to resource usage (among other things).
Recap
In this section, we learned the basic of resource ownership and the resource lifecycle. We saw why systems programming languages might give the programmer the tools to explicitly manage hardware resources and what the downsides to this are (mental load, higher probability of bugs). We then saw that there are ways to mitigate these downsides by analyzing resource lifetimes in the code, for example using the borrow checker in Rust.
In the next chapter, we will look at the last major feature of Rust, namely its approach to polymorphism and why Rust is not considered an object-oriented language.
Closing exercises
🔤 Exercise 2.5.1
Using the programming language of your choice, write a program that demonstrates resource exhaustion for each of the following resources:
- Memory
- Files / file descriptors
- Network connections / sockets
Answer these questions first before writing your program, as they will help you conceptualize what your program has to do:
- How can I allocate the specific resource using your my chosen programming language?
- How many "elements" of each resource do I expect I should be able to allocate from a single program?
- For files: Is there a difference between opening the same file multiple times, or opening multiple different files? If I expect that I would need to open multiple different files simultaneously, how would I get access to a large number of different files on my file system?
- For network connections: Do I need multiple programs to establish a network connection (e.g. client and server) or can I do it within a single program?
Then run each of your programs to verify that you can exhaust the given resource. How does your programming language and operating system handle the resource exhaustion?
2.6. Recap on chapter 2
This concludes chapter 2, which was rather long and introduced a lot of important concepts for systems programming. While going into more detail on these topics will be postponed to the upcoming chapters, this chapter is very important from a conceptual point of view. Systems programming is a special discipline which draws on a lot of different ideas, both from an applied programming standpoint as well as from a more theoretical point of view. As a recap, try to answer the following questions using what you have learned in this chapter:
- What are ahead-of-time compiled languages? Why do we prefer them for systems programming over interpreted languages?
- What is a programming paradigm? What common programming paradigms do popular programming languages use? Which ones are relevant to systems programming, and why? How do C++ and Rust differ in terms of their programming paradigms?
- What is the difference between statically typed languages and dynamically typed languages? How does static typing play together with ahead-of-time compilation? Why do we consider static typing a good thing for systems programming?
- What does resource ownership mean? Why is it important for systems programming?
- What does polymorphism mean? Why is it important for systems programming (or programming in general)? How does the C++ approach for polymorphism differ from the Rust approach for polymorphism?
Chapter 3 - The fundamentals of memory management and memory safety
In this chapter, we will start to dive deep into systems programming and will study the hardware resource memory. We will learn how memory is managed, both at the level of the operating system as well as on the level of a systems programming language. In this process, we will learn what tools the Rust programming language provides developers to make best use of memory in their code. Here is the roadmap for this chapter:
- 3.1. Types of memory in a typical computer
- 3.2. How the operating system manages memory
- 3.3. Memory management in Rust - The basics of lifetimes and ownership
- 3.4. Smart pointers and reference counting
- 3.5. A first look at
unsafeRust
3.1. Types of memory in a typical computer
The memory hierarchy
Your average computer has many different types of memory available for programs to use. They differ in their storage capacity and access speed, as well as their location (internal or external storage). The term memory in the context of software is often used as a synonym for main memory, also know as RAM (Random Access Memory). Other types of memory include disk storage, found in your computers hard drive, as well as registers and CPU caches found on your processor. Beyond that, external storage media, such as network attached storage (NAS), cloud storage or tape libraries can also be available for your computer.
Together, the different types of memory form what is known as the memory hierarchy:
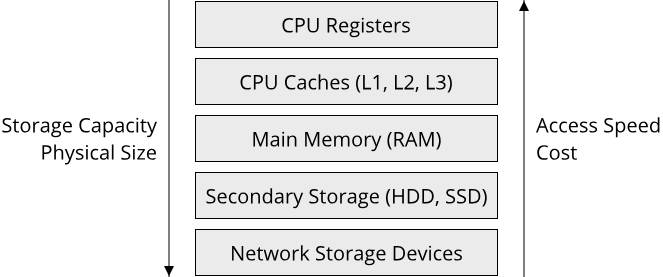
At the top of the memory hierarchy sit your CPU registers. These are small memory cells right on your processor, located very close to the circuits which do calculations (such as the ALU (Arithmetic-Logic Unit)). Registers typically only stores a couple of bytes worth of data. Next come a series of caches in increasing sizes, sitting also right on your CPU, although a bit further out since they are larger than the registers, in the order of Kilobytes to a few Megabytes. We will examine these caches closer in just a moment. After the CPU caches comes the main memory, which is typically several Gigabytes in size for a modern computer, though some clusters and supercomputers can have Terabytes of main memory available to them. Following the main memory is the secondary storage, in the form of hard-disk drives (HDDs) and solid-state drives (SSDs), which range in the low Terabytes. Lastly in the memory hierarchy are the network storage devices, which can be external harddrives, cloud storage or even tape libraries. They can range from several Terabytes up into the Exabyte domain.
Caches
Before continuing out study of the memory hierarchy, it is worth examining the concept of caches a bit closer. A cache is a piece of memory that serves as a storage buffer for frequently used data. Modern CPUs use caches to speed up computations by providing faster access to memory. There are caches for data and instructions, and different levels with different sizes. Here is a picture illustrating the cache hierachy in a modern processor:
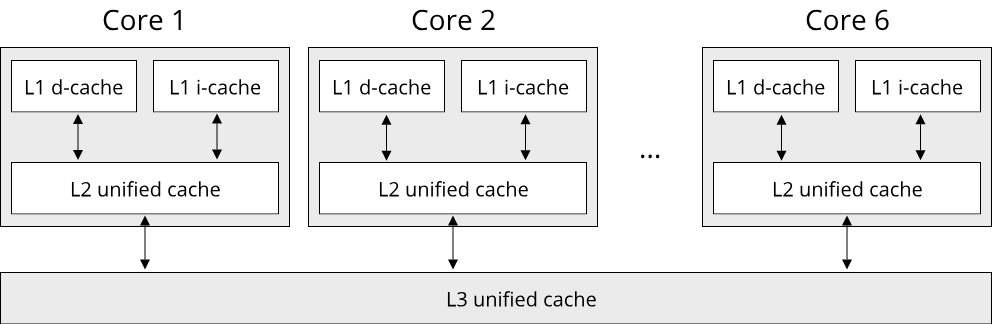
It depicts the caches for a processor with six logical cores, such as the Intel Core-i7 CPU in a 2019 MacBook Pro. At the lowest level, called L1, there are two small caches, one for storing executable instructions (L1 I-Cache) and one for storing data (L1 D-Cache). The typically are in the order of a few kilobytes large, 32 KiB for the given CPU model. Next up is the L2 cache, which is larger but does not differentiate between instructions and data. It is typically a few hundred kilobytes large, 256 KiB for the Core-i7 CPU. On top of that, modern CPUs have a third level of cache, which is shared by all cores, called the L3 cache. It is typically a few megabytes large, 12 MiB for the Core-i7 CPU.
The purpose of the memory hierarchy
At this point it is reasonable to ask: Why does this memory hierarchy exist? Why don't we all use the same type of memory? The memory hierarchy is built on the fact that fast memory is physically small and expensive, while large storage capacity has slow access times. The simplest explanation for this fact comes from the physical properties of electric circuits: To get information from one point to another, computers use electricity, which travels at roughly the speed of light through a conductor. While the speed of light is very fast, computers are also very fast, and these numbers cancel out quite neatly for modern computers. For a 3 GHz CPU, that is three billion cycles per second, every cycle lasts just a third of a nanosecond. How far does light travel in a third of a nanosecond? We can do the calculation: The speed of light is about 3*108 meters per second, a single cycle in a 3 GHz CPU takes 3.33*10-10 seconds. Divide one by the other and you get 1*10-1 meters, which is 10 centimeters. Not a lot. Assuming that we want to load a value from memory into register, do a calculation, and write it back to memory, it is physically impossible to do so in a single clock cycle if the memory is further than 5cm away from our CPU register, assuming that they are connected in a straight line. Since memory is made of up some circuitry itself, which takes up space, it becomes clear that we can't just have an arbitary large amount of memory with arbitrary fast access times.
There is a very famous chart available in the internet called 'Latency Numbers Every Programmer Should Know' which illustrates the differences in access times for the various types of memory in the memory hierarchy. For systems programming, we care about these numbers deeply, as they can have a significant impact on how fast or slow our code is running. Here are some of the most important numbers:
| Memory Type | Typical Size | Typical access time |
|---|---|---|
| Register | A few bytes | One CPU cycle (less than a nanosecond) |
| L1 Cache | Dozens of KiBs | A few CPU cycles (about a nanosecond) |
| L2 Cache | Hundreds of KiBs | ~10ns |
| L3 Cache | A few MiBs | 20-40ns |
| Main Memory | GiBs | 100-300ns |
| SSD | TiBs | A few hundred microseconds |
| HDD | Dozens of TiBs | A few milliseconds |
| Network Storage | Up to Exabytes | Hundreds of milliseconds to seconds |
A fundamental principle which makes the memory hierarchy work is that of locality. If a program exhibits good locality, it uses the same limited amount of data frequently and repeatedly. Locality can be observed in many processes outside of computer science as well. Think of a kitchen with dedicated drawers and cabinets for spices or cutlery. If you use one spice, the chances are high that you will use another spice shortly after, and if you use a fork, you might need a knive soon after. The same principle holds for computers: A memory cell that was read from or written too might be followed by reads and writes to adjacent memory cells shortly after. In more colloquial terms, locality means: 'Keep stuff you need frequently close to you'.
From the table of memory access speeds, we can see that it makes a huge difference if a value that our code needs is in L1 cache or in main memory. If a single main memory access takes about 100 nanoseconds, on a 3 GHz processor that means that we can do about 300 computationsThat is assuming that every computation takes just one CPU cycle to complete. This is not true for every instruction and also depends on the CPU instruction set, but for simple instructions such as additions, this is a resonable assumption. in the time it takes to load just one byte from main memory. Without caches, this would mean that an increase in CPU speed would be useless, since most time would be spent waiting on main memory. On top of that, increasing the speed of memory turns out to be much harder than increasing the speed of a CPU. In the end, adding several sophisticated cache levels was the only remedy for this situation.
Communicating between different memory devices
Since your computer uses different types of memory, there has to be a mechanism through which these memory devices can communicate with each other. Most modern computers follow the Von-Neumann architecture, which is a fundamental architecture for how components in a computer are connected. In this architecture, connecting the different parts of your computer to each other is a system called the bus. We can think of the bus as a wire that physically connects these parts, so that information can move from one device to another. In reality, there will be multiple buses in a computer that connect different parts to each other to increase efficiency and decrease coupling of the components.
Traditionally, there is a tight coupling between the processor and main memory, allowing the processor to read from and write to main memory directly. The processor can also be connected to other input/output (I/O) devices, such as an SSD, graphics card or network adapter. Since these devices will typically run at different speeds, which are often much slower than the clock speed of the processor, if the processor were to read data from such a device, it would have to wait and sit idle while the data transfer is being completed. In practice, a mechanism called direct memory access (DMA) is used, which allows I/O devices to access main memory directly. With DMA, the CPU only triggers a read or write operation to an I/O device and then does other work, while the I/O device asynchronously writes or reads data from/to main memory.
From a systems programming perspective, I/O devices thus are not typically accessed directly by the CPU in the same way main memory is. Instead, communication works through the operating system and the driver for the I/O device. In practice, this means that we do not care that variables that we declare in code refer to memory locations in main memory, because the compiler will figure this out for us. The same is not true for accessing data on your SSD (in the form of files) or on your GPU. Here, we have to call routines provided by the operating system to get access to these data.
Systems programming is a wide field, and depending on what types of systems you write, the information of this section might not apply to you. On an embedded system, for example, you might interface directly with I/O devices through writing to special memory addresses. The GameBoy handheld console, for example, required software to write the pixels that should be drawn directly to a special memory region which was then read by the display circuits. The study of such embedded systems with close interplay between hardware and software is interesting, however it is out of the scope for this courseThere is a course on embedded systems programming being taught at the same university that this course is taught, hence embedded systems are not covered in detail here., where we will focus on systems software for Unix-like systems. If you are interested in the nitty-gritty details of such a computer system, GBDEV is a good starting point.
Exercises
Matrix multiplication
A classical example where performance is dependend on cache access is matrix multiplication. Write a small Rust program that multiplies two N-by-N matrices of f64 values with each other and measure the performance of this operation. Store the matrix data in a one-dimensional array, like so:
#![allow(unused)] fn main() { struct Matrix4x4 { data: [f64; 16], } }
There are two ways of mapping the two-dimensional matrix to the one-dimensional array: Row-major and column-major order. Given a row and column index (row, col), look up how to calculate the corresponding index in the 1D-array for row-major and column-major memory layout. Then implement the matrix multiplication routine like so:
#![allow(unused)] fn main() { fn matrix_mul(l: &Matrix4x4, r: &Matrix4x4) -> Matrix4x4 { let mut vals = [0.0; 16]; for col in 0..4 { for row in 0..4 { for idx in 0..4 { // TODO Calculate l_idx, r_idx, and dst_idx. Do this once for row-major, and once for column-major // layout (in two separate matrix_mul functions) vals[dst_idx] += l.vals[l_idx] * r.vals[r_idx]; } } } Matrix4x4{ data: vals, } } }
To measure the runtime, you can use Instant::now(). In order to get some reasonable values, create a Vec with a few thousand matrices and multiply every two adjacent matrices (i.e. index 0 and 1, index 1 and 2, and so on). Do this for row-major and column-major order. Start with a small matrix of 4*4 elements, as shown here, and move up to 8*8, 16*16 and 32*32 elements. Comparing the row-major and column-major functions, which perform the same number of instructions and memory accesses, what do you observe?
3.2. How the operating system manages memory
Now that we know the different types of memory available to your computer, it is time to look at how we as programmers can work with memory. In this section, we will learn about the role that the operating system plays in managing the hardware memory resources, and the routines that it provides to other programs for accessing this memory.
Physical and virtual addressing
When we talk about memory in a computer, what we mean is a collection of identical memory cells that can store data in the form of bits. It has been shown to be convenient to talk not about individual bits, but group them together into one or more bytes at a time. If we then think of our memory as a collection of cells that can hold one byte worth of data each, we need a way to uniquely identify each of these memory cells. We do this by assigning each memory cell a number called its memory address. We then refer to the process of mapping between a memory address and its corresponding memory cell as addressing.
The simplest form of addressing is called physical addressing: Here, we just use the number of each memory cell as the address for our instructions. A corresponding instruction for loading the value of memory cell 3 into a register might look like this:
mov eax, BYTE PTR 3 ; move the byte at address 3 into the eax register
While this is the simplest and certainly the most conventient way of addressing memory, it is not the only way. In fact, physical addressing is seldom used in general purpose computers, for a variety of reasons:
- We can never address more memory than is physically present on the target machine
- If we have multiple processes, it becomes hard to assign memory regions to these processes. We would like separate processes to have separate address ranges, so that they don't interfer with each other. We also would like to be able to grow and shrink the amount of memory that each process can access dynamically
- How do we make sure that programs written by the user don't accidentally (or maliciously) overwrite memory that the operating system is using?
All these problems can be solved by introducing a layer of abstraction between the physical memory cells and the memory addresses. Instead of using physical addressing, we can use virtual addressing. With virtual addressing, we introduce a mechanism that maps a memory address from a virtual address space to a memory address from the physical address space. An address space in this context is a contiguous range of numbers from 0 to some maximum number N. If we have k bytes of physical memory, then the physical address space of this system is the range of numbers [0;k). We can then use a virtual address space of an arbitrary size, often one that is much larger than the physical address space, to generate virtual addresses from. Let's say we use a virtual address space of size 2k, so virtual addresses are in the range [0;2k). We now need a mechanism that maps from a virtual address to a physical address. Since we might have more virtual addresses than physical addresses, we need a way to perform this mapping without running out of physical space. A good way to achieve this is to a secondary storage medium as a cache for our memory cells. In practice, disk space is used, because most systems have more disk space available than working memory. Since the idea of a cache is to give faster access to data, in this concept the working memory actually serves as the cache for an address space stored on disk, and not vice versa. This might appear weird at first: With this concept, we are refering to memory addresses on disk instead of those in working memory, and we only hope that the data is in working memory as a cache. However note that in principle, there would be no need for a computer to have working memory at all. The only reason it has is that working memory is faster than disk memory, but from a purely functional point of view (remember the Turing machine?) any type of memory cells would be sufficient.
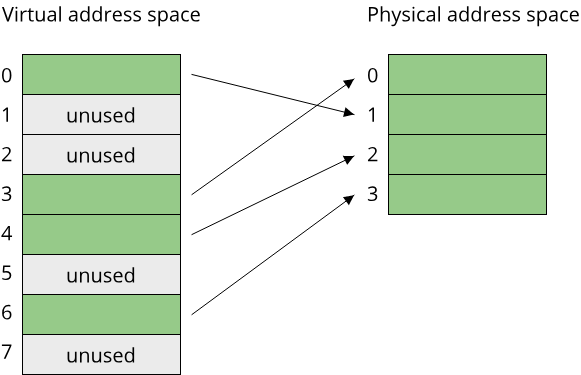
Virtual memory
The concept which is described here is called virtual memory and is one of the cornerstones of modern operating systems. It works like this: Suppose your program wants to store a variable that is 8 bytes large. It can then talk to the operating system and request access to a contiguous memory region that is 8 bytes large. The operating system allocates an 8 byte region from a virtual address space, and hands this memory region back to the program. A memory region in this context is nothing more than a contiguous interval in the virtual address space. In C/C++, it would be represented by a pointer, or a pair of pointersThe fact that memory is represented by a single pointer in C/C++ is one of the reasons why memory management can be tricky in these languages. A pointer itself is just a number, containing no information about the size of the memory region that it refers to! . If your program now reads from this memory region, the virtual address range has to be translated into a physical address range. This is just a mapping from one number to another number, where the resulting number is the physical address of a memory cell on disk. Now comes the clever part: During this address translation process, the operating system checks that the physical address is cached in working memory. If it is not, it is automatically loaded from disk into working memory. This way, even with virtual addressing, data is always physically accessed in working memory.
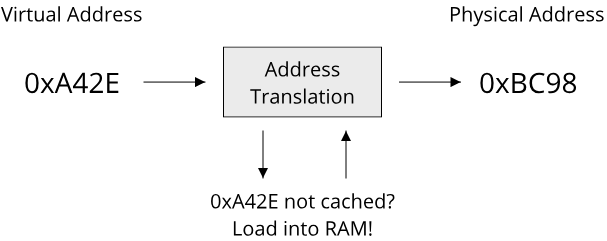
To perform this mapping between addresses, a data structure has to be kept somewhere that stores which virtual address maps to which physical address. Keeping such a mapping for every single byte in the address spaces would result in an unreasonably large data structure. Instead, the mapping is done based on contiguous memory regions called pages (sometimes also called virtual pages). These pages are in the order of a few KiB to a few MiB in size on an average computer today. Using pages makes the caching process easier and reduces the number of address mappings to keep in the internal data structure. A pretty standard page size on Unix-systems is 4KiB, which requires only 1/4096th the number of mapping entries than the naive approach of mapping every byte. Fittingly, the data structure that stores these mappings is called a page table.
Let's examine the usage of pages more closely. We saw that the operating system manages these pages and their mapping to memory regions in the physical address space. Whenever a data read or write is issued to a page that is not cached in working memory, this page has to be loaded from disk into working memory. This situation is called a page fault. This is a two-step process: First, a suitable address region in the physical address space has to be determined where the page is to be loaded into. Then, the actual copy process from disk into working memory is performed. This copy process takes time, the more so the larger the page size is, which results in a conflicting requirement for an 'ideal' page size. Small page sizes are good for caching, but result in very large page tables, large page sizes give managable page tables but make the caching process slower due to the overhead of copying lots of data from disk to working memory. Now, in order to perform the process of loading a page from disk into working memory, we need a way of determining where into working memory the page should be loaded. Working memory usually provides constant-time random access to any memory cell, so any region in working memory is as good as any other region for our mapping. We thus only have to identify a contiguous memory region as large as the page size that is not currently in use. How to identify such a memory region will be left as an exercise for the lab. For now, assume we found a suitable region. We can then record the mapping between the virtual page and this memory region inside the page table. We call these regions of working memory that contain data for a page the physical page or page frame.
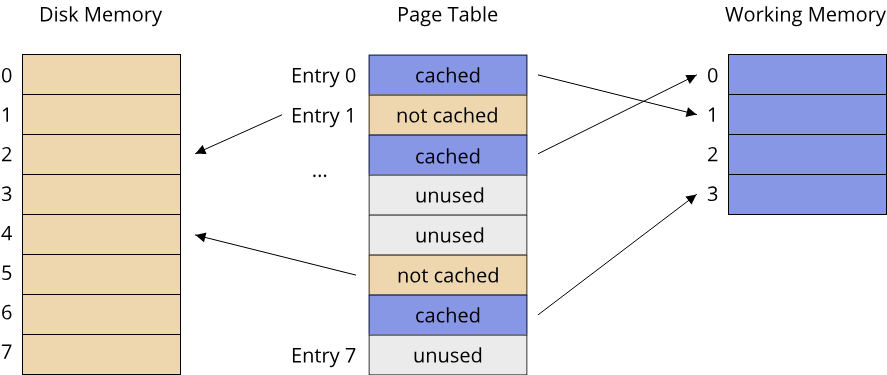
Remember how we said that our virtual address space can be larger than the physical address space? This is quite common in practice. Older hardware architectures, such as the i386 architecture by Intel (the predecessor of the x86-64 architecture that we saw in chapter 2.3), used a virtual address space that was 4GiB large, using the full 32-bit word size of these processors to address virtual memory. For a long time, most systems had significantly less working memory than these 4GiB, but as technology has advanced, systems with this much or more working memory became commonplace. In order to address more memory, modern architectures (such as x86-64) use significantly larger virtual address spaces. On x86-64 systems, where processors have a word size of 64 bits, the virtual address space is typically 48 bits largeWhy 48 bits and not the full 64 bits? Hardware limitations, mostly. 48 bit virtual addresses give you 256TiB of addressable memory, which was and still is considered to be sufficiently large for computers of the forseeable future. Keep in mind that 64-bit architectures were conceived in the late 1990s, so almost 25 years ago as of writing. Even as of today, there is basically no consumer hardware that has even 1TiB of working memory., yielding a virtual address space that is 256TiB in size. It is highly unlikely that the average system will have this much physical memory available, especially not as working memory. This leaves us in an unfortunate situation: Since the virtual address space is singificantly larger than the physical address space, when we encounter a page fault there is a real chance that all of our working memory is already occupied by other pages and no space is left to load in the data for the requested page. In this scenario, we have to select a page that is cached in working memory and have to evict it, which is to say we store its contents on disk and make room for a new page to be cached in working memory.
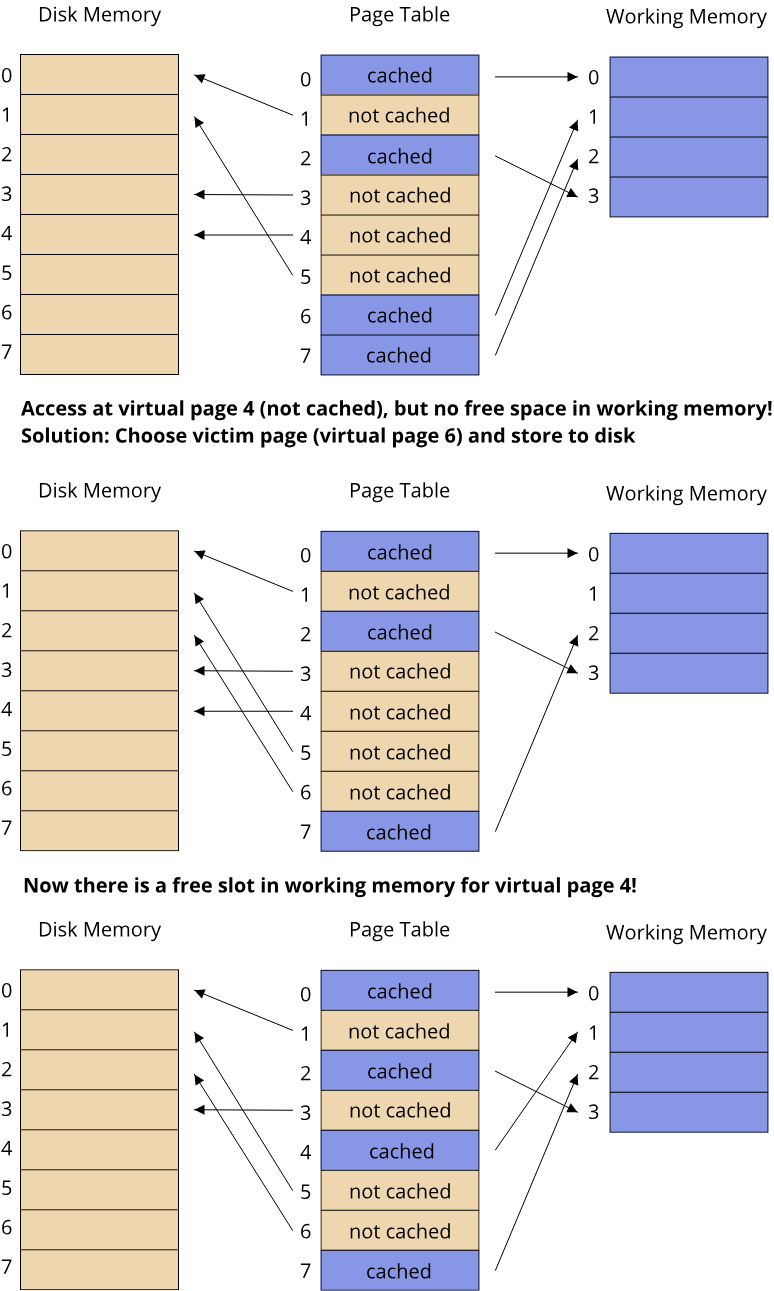
The process of evicting records from a cache to make room for other records is a fundamental property of any cache. There are many strategies for selecting the appropriate record to evict, all with their own unique advantages and disadvantages. Instead of discussing them here, researching popular caching strategies and implementing a simple virtual memory system based on an appropriate strategy will be a lab assignment.
Virtual memory hands-on
Up until now, we discussed the idea virtual memory in a fairly abstract sense. In this section, we will look at the whole process of virtual memory mapping and page faults using some real numbers to get a good feel for it.
Assume a system with a virtual address space (VAS) of 64KiB size, a physical address space (PAS) of 16KiB size, and a page size of 4KiB. We can represent all virtual addresses using 16-bit numbers. Since each page is 4KiB in size, there are 64KiB / 4KiB = 16 virtual pages in the virtual address space, and 16KiB / 4 KiB = 4 physical pages in the physical address space. If we look at a single virtual memory address, we can thus use the 4 most significant bits for the page number, and the lower 12 bits for the byte offset within a single page:
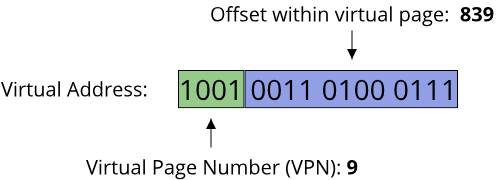
Since the page size is equal for both the virtual and physical address space, the lower 12 bits will tell us both the offset within the virtual page (VPO) as well as the offset within the physical page (PPO). What is different is just the page number. To perform our mapping between virtual page number (VPN) and the physical page number (PPN), we use the page table data structure. This page table is effectively a map between VPO and PPO or and invalid record, indicating that the given virtual page is not currently cached in physical memory. Recall that pages that are not cached in working memory are instead stored on disk, so our invalid record has to identify the location of disk where the given page is stored instead. This can be a binary offset within a file on disk, for example. A common strategy to keep the size of the page table entries (PTE) low is to encode this information in a single number, with a single bit indicating whether the physical page is cached in working memory or resides on disk, and as much bits as are needed to represent the maximum PPO. In our example, there are just 4 physical pages, so we would need only 3 bits in total for a PTE, but we will store them as 8-bit numbers instead:
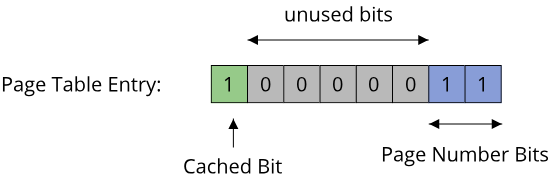
Initially, the page table starts out with 16 empty records, because none of the virtual pages from the virtual address space have been used yet. We need a special value to indicate that a virtual page is unused, we can use the value 0 for this and switch to 1-based indexing of the physical pages. Using 0 has the advantage that the highest bit is already set to zero, indicating that the page is not cached in working memory. As a downside, we need one more bit for addressing, however we have plenty to spare:
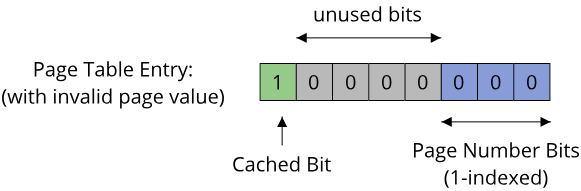
Converting a virtual address to a physical address then works like this:
- Split the virtual address into VPN (the upper 4 bits) and VPO (the lower 12 bits)
- Use the VPN as an index into the page table
- If the PTE indicates that the page is not cached in working memory (highest bit is zero), load it into working memory and adjsut the PTE accordingly
- Get the PPN from the PTE
- Concatenate the PPN and the VPO to get the physical address
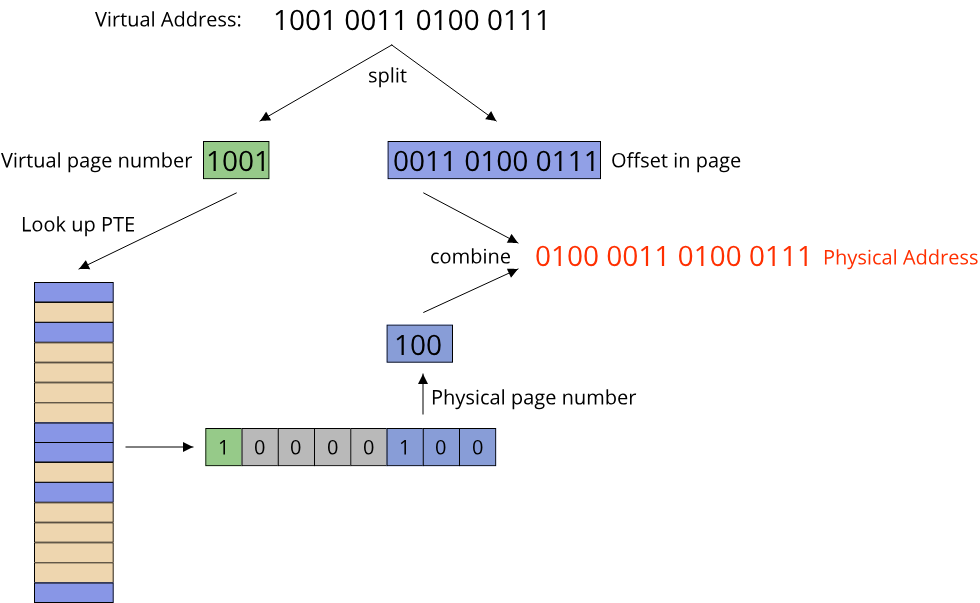
Virtual memory in practice
Virtual memory is an old concept that has seen many improvements over the years. As most things in computer science (or life, for that matter), reality tends to be more complex than the examples that we use to learn concepts. In this section, we will briefly look at some of the aspects that make virtual memory work in real operating systems.
While we talked about the process of address translation, we haven't talked about where exactly it happens. Take a look again at a machine code instruction that performs a memory load:
mov eax, BYTE PTR 3 ; move the byte at address 3 into the eax register
If this instruction is executed by the CPU, and the address 3 is a virtual address, then who does the translation into a physical address? The answer is: A specialized piece of hardware right on the CPU, called the memory management unit (MMU). Having the address translation being implemented in hardware is much faster than in software. In order to do the address translation, the MMU needs access to the page table, which has to reside somewhere in memory itself. As we saw, loading data from main memory can take up to a few hundred CPU cycles, which is a cost that we definitely do not want to pay every time we want to translate a virtual address into a physical address. As so often, caches are the answer here: A modern CPU will have a small cache for page table entries that provides very fast access to the most recently used page table entries. This cache is called a translation lookaside buffer (TLB).
The management of the page table itself is done by the operating system. To keep processes separated, each process has its own unique page table, giving each process a unique virtual address space. If two processes both want access to the same physical page, the operating system can map two virtual pages from the two processes onto the same virtual page for an easy way to share data between processes. Additionally, the page table entries will also store more flags than the ones we have seen: A page can be read- or write-protected, allowing only read or write access, and pages can be reserved for processes that are running in kernel mode, preventing user mode processes from manipulating them.
Lastly, a page table must be able to map every virtual page to a physical page, so it must be capable of holding enough entries for every possible virtual page from the virtual address space. With 4KiB pages on an x86-64 system, which uses 48-bit addressing, there are 2^36 unique virtual pages. Assuming 8 byte per page table entry, a full page table would require 512GiB of memory. Clearly this is not practical, so instead a hierarchy of page tables is used in practice. The lowest level of page table refers to individual pages, the next higher level refers to ranges of page table entries, and so on. The Intel Core i7 processor family for example uses 4 levels of page tables.
Summary
In this chapter, we learned about the concept of virtual memory. We learned how virtual addressing works, how to translate virtual addresses to physical addresses, and what the benefits of this approach are. We saw how the operating system manages virtual memory using page tables, learned about page faults and how working memory is used as a cache for the physical address space. Lastly, we saw that additional hardware and more complex page tables are used in practice to make virtual memory viable.
3.3. Memory management in Rust - The basics of lifetimes and ownership
Now that we know how the operating system treats memory, it is time to look at how we as programmers can deal with memory. Since memory management is one of the major areas of systems programming, it pays off to have a programming language that gives us good tools for managing memory. In this section, we will learn what tools the Rust programming language gives programmers for memory management, and how they differ from the common tools that the C/C++ programming language family provides. We will learn about memory allocation, delve deeper into the concept of lifetimes with a special focus on Rust's take on it, and will examine the concepts of copy- and move-semantics.
The address space of a process
Whenever we run a program on a modern operating system, the operating system creates a process that encapsulates this running program. Processes are abstractions over the whole hardware of a computer system, with the operating system overseeing processor and memory usage for the process. In this chapter, we will focus on the memory aspect, the processor aspect will be covered in chapter 7.
Through the concept of virtual memory that we learned about in the previous chapter, the operating system can assign each process a unique range of memory. This is the address space of the process, and in it lives all the data that the code in your process can access. For each process, there are several types of data and corresponding regions within the address space that are defined by the operating system. The following image illustrates the common regions of a process in the Linux operating system: (TODO cite from OS book)
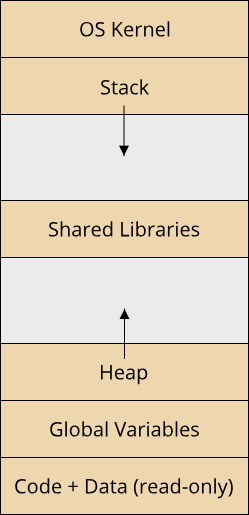
The actual instructions of the process live at the lowest range in the address space, followed by a block containing global variables. After that is a variable-length region called the heap, which grows upwards towards larger addresses. The heap is where we as programmers can obtain memory from to use in our program through a process called dynamic memory allocation. We will see how exactly this works in the next sections. Somewhere in the middle of the address space is a region where code from shared libraries lives. This is code written by other programmers that your program can access, for example the standard library in C. Beyond this section lies a memory region called the stack, which grows from a fixed address down. The stack is important to enable function calls, as it is where local variables reside. Beyond the stack comes the last memory region, which contains the address space of the operating system kernel. Since this region contains critical data and code, user programs are not allowed to read from it or write to it.
The Stack
The first region that is worth a closer look is the stack. It gets its name from the fact that it behaves exactly like the stack datastructure: Growing the stack pushes elements on top of it, shrinking the stack removes elements from the top. In case of the stack memory region, the elements that are pushed and removed are just memory regions. Since the stack starts at a fixed address, a process only has to keep track of the current top of the stack, which it does through a single value called the stack pointer. If we are programming in assembly language, we can manipulate the stack pointer directly through the push and pop instructions, like so:
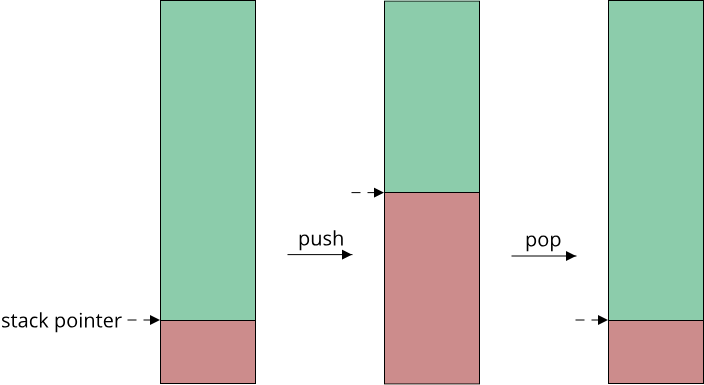
These instructions can only push and pop values that are in a register. So push rax pushes the value of the rax register onto the stack. On a 64-bit system, rax is a 64-bit register and thus holds an 8-byte value, so push rax first decrementsRemember that the stack grows downwards towards lower memory addresses! the stack pointer by 8 bytes, and then writes the value of rax to the old stack pointer address. pop rax goes the other way and removes the top value from the stack, storing it in the rax register. Again, rax is 8-byte wide, so an 8-byte value from the current stack pointer minus 8 is read and stored in rax, then the current stack pointer is incremented by 8 bytes.
In a higher level programming language than assembly language, instead of manipulating the stack directly, the compiler generates the necessary instructions for us. The question is: From which constructs in the higher-level programming language does the compiler generate these stack manipulation instructions?
In a language such as C, C++, or Rust, there are two constructs for which the stack is used: local variables and functions. Local variables are all variables that live inside the scope of a function. The scope of a variable refers to the region within the code were the variable is valid, i.e. it is recognized by the compiler or interpreter as a valid name. In C, C++, or Rust, a function scope can be thought of as the region between the opening and closing curly brackets of the function:
#![allow(unused)] fn main() { fn foo() { //<-- scope of 'foo' starts here let num = 42; //'num' is a local variable of 'foo' because it is valid only within the scope of 'foo' } //<-- scope of 'foo' ends here *num = 42; //<-- Accessing the variable 'num' outside of its scope is invalid under the rules of Rust! }
All local variables are stored on the stack, and the compiler generates the necessary code to allocate memory on the stack and store the values on the stack. Here we can see that having a language with static typing, where the type (and hence the size) of all variables is known to the compiler helps to generate efficient code.
The other situation where the stack is used for is to enable functions to call other functions. Let's look at an example:
#![allow(unused)] fn main() { fn f3(arg1: i32, arg2: i32) { let var_f3 = 42; println!("f3: {} {} {}", arg1, arg2, var_f3); } fn f2(arg: i32) { let var_f2 = 53; f3(arg, var_f2); println!("f2: {}", var_f2 + arg); } fn f1() { let var_f1 = 64; f2(var_f1); println!("f1: {}", var_f1); } }
Here we have three functions which all define local variables. Starting at f1, a variable is declared, then f2 is called with this variable as the function argument. Once f2 exits, the variable is used again in a print statement. f2 does a similar thing, declaring a variable, then calling f3 with both this variable and the variable that was passed in. f3 then declares one last variable and prints it, together with the arguments of f3. If we look at the scopes of all the variables, we could draw a diagram like this:
{ "scope of f1"
var_f1
{ "scope of f2"
var_f2
{ "scope of f3"
var_f3
}
}
}
By using the stack, we can make sure that all scopes of all variables are obeyed: Upon entering a function, memory is allocated on the stack for all local variables of the function, and upon exiting the function this memory is released again. The memory region within the stack corresponding to a specific function is called this function's stack frame. Passing arguments to functions can also be realized through the stack, by memorizing the address of the variable on the stack. In practice however, small arguments are passed not as addresses on the stack, but are loaded into registers prior to the function call. Only if the arguments are too large to fit into registers, or there are too many arguments, is the stack used to pass arguments.
We can examine how the stack grows by writing a simple program that prints out addresses of multiple local variables:
#include <iostream>
int main() {
int first = 42;
std::cout << &first << std::endl;
int second = 43;
std::cout << &second << std::endl;
return 0;
}
❓ Question
Without running the example code above, which of the two addresses &first and &second do you think is larger?
💡 Click to show the answer
Since the stack grows downward, the address of first should be larger than of second. All major OSes implement this convention. However the C standard does not define what the order of local variables on the stack is, so compilers are allowed to reorder variables on the stack, as long as they live in the same scope.
Run this example for yourself to verify the expected behavior.
Here is a key observation from our study of the stack: The stack automatically manages the lifetime of our variables! Think about it: Memory is a resource, and we learned that any computer resource must be managed somehow. It has to be acquired, and it has to be released properly, otherwise we will run out of the resource eventually. Here we have a mechanism that manages memory as a resource automatically for us, simply due to the way our programming language is structured! In addition, this mechanism for managing memory is as efficient as what we could have written by hand, even in raw assembly language. This is a powerful abstraction, and we will be looking for similar abstractions throughout this course.
While the stack works very well, it also has a lot of limitations. First and foremost, stack size is very limited! On Unix-systems, we can use the shell command ulimit -s to print the maximum stack size for our programs, which will often be only a few Megabytes. On top of that, the stack memory is directly tied to scopes. If we have data that is generated in one function, but should live longer than the function, we are out of luck, as stack memory is automatically cleaned up. For this reason, operating systems provide another memory region called the heap, which we can use much more freely.
The Heap
The heap refers to a memory region from which programs can obtain variable-sized memory regions dynamically. We call this process dynamic memory allocation or dynamic allocation for short. Dynamic in this context refers to two things: First, the lifetime of the acquired memory region is dynamic in that it does not depend on any programing-language construct (such as scopes), but instead depends purely on the programmer. Second, the size of the memory region can be specified fully at runtime and thus is also dynamic.
Before we look at how to use the heap, here is an example that illustrates why working with only the stack can get very difficult.
Heap motivation: Dynamically-sized memory
Suppose you were to write a program in C++ or Rust that prompts the user to input any number of integers and, once the user has finished, outputs all the strings in lasecnding order. One option would be to first ask the user how many integers they want to input, then prompt for input this many times, storing them in an array on the stack and sorting this array. Here is how we would write such a program in C++:
#include <iostream>
#include <algorithm>
int main() {
std::cout << "How many integers do you want to input?\n";
int count;
std::cin >> count;
std::cout << "Please enter " << count << " strings:\n";
int numbers[count];
for(int idx = 0; idx < count; ++idx) {
std::cin >> numbers[idx];
}
std::sort(numbers, numbers + count);
for(auto num : numbers) {
std::cout << num << std::endl;
}
return 0;
}
The interesting part is this line right here:
int numbers[count];
With this line, we allocate a dynamic amount of memory on the stack, which has the size count * sizeof(int). Depending on your compiler, this example might or might not compile. The problem here is that we are trying to create an array on the stack with a size that is not a constant expression, which effectively means the size is not known at compile-time. The GCC compiler provides an extension that makes it possible to use some non-constant value for the array size, the MSVC compiler does not support this. The Rust programming language also does not allow non-constant expressions for the array size.
What could we do in this case? Do we have to resort to writing assembly code to manipulate the stack ourselves? After all, if we examine the assembly code that GCC generates for our example, we will find an instruction that manipulates the stack pointer manually:
sub rsp, rax ; rax contains the dynamic size of our array
On a Linux system, there is a corresponding function, called alloca for allocating a dynamic amount of memory on the stack:
int* numbers = static_cast<int*>(alloca(count * sizeof(int)));
This memory is automatically freed once we exit the function that called alloca, so that sounds like a good candidate?! The problem with alloca (besides being an OS-specific function which might not be available on non-Linux systems) is that it is very unsafe. The stack is very limited in its size, and calling alloca with more requested memory than there is available on the stack is undefined behaviour, which is to say: Anything can happen in your program, good or bad. For this reason, programmers are discouraged from relying on alloca too much. Even disregarding the safety aspect, alloca has the same lifetime problem that local variables have, namely that they get freed automatically once a certain scope is exited. If we want to move the piece of code that allocates memory for our numbers into a separate function, we can't use alloca anymore.
What we really want is a way to safely obtain a region of memory with an arbitrary size, and fully decide on when and where we release this memory again. This is why the heap exists!
Using the heap
So how do we as programmers make use of the heap? From an operating system perspective, the heap is just one large memory region associated with a process. On Linux, the heap starts at a specific address based on the size of code and the amount of global variables of the current process, and extends upwards to a specific address called the program break. All memory between these two addresses is freely accessible by the process, and the operating system does not care how the process uses it. If the process needs more memory, the program break can be moved to a higher address using the brk and sbrk functions. brk moves the program break to the given address, sbrk increments the program break by the given number of bytes. With this, we get truly dynamic memory allocation:
int* numbers = static_cast<int*>(sbrk(count * sizeof(int)));
Technically, we never have to free this memory manually, because when the process terminates, the address space of the process is destroyed, effectively releasing all memory.
Now, is this the end of the story? sbrk and be done with it? Clearly it is not, depending on your background, you might never have heard of the sbrk function before. Maybe you are used to the new and delete keywords in C++, or the malloc and free functions in C. What's up with those?
To understand this situation, we have to move beyond our simple example with just one dynamic memory allocation, and onto a more realistic example: Dynamically sized arrays!
Using the heap - For real!
What is a dynamically sized array? You might know it as std::vector from C++. It is a contiguous sequence of elements which can grow dynamically. Possibly one of the first datastructures you learned of when starting out programming is the array, a sequence of elements with a fixed size. int arr[42]; Easy. The obivous next question then is: 'What if I want to store more than 42 elements?'. Sure, you can do int arr[43]; and so on, but as we have seen in our previous number-example, there are situations where you do not know upfront how many elements you need. This is where std::vector and its likes in other programming languages (Vec in Rust, ArrayList in Java, list in Python) come in. In Programming 101 you might accept these datastructures as some magical built-in features of the language, but let's try to peek under the hood and see if we can implement something like std::vector ourselves!
The central question of a growable array is: How do we grow the memory region that holds our elements? If we only ever had one single instance of our growable array, we could use sbrk, which does the growing for us. As soon as we have multiple growable arrays with different elements, we can't do this anymore, because growing one array might overwrite the memory of another array:
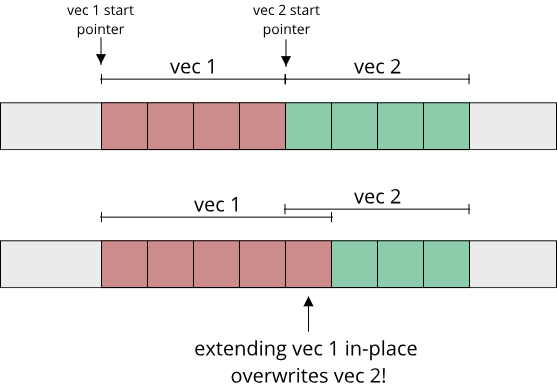
A fundamental property of an array is that all its elements are stored in a contiguous memory region, meaning right next to each other. So we can't say: 'The first N elements are stored at this memory location, the next M elements at this other memory location etc.' Well, we can do that, but this datastructure is not an array anymore but a linked list. So what is left? Try to think on this question for a moment:
Question: How can we grow contiguous memory in a linear address space?
The only viable solution is to allocate a second, larger contiguous memory block and copying all elements from the old memory block to the new memory block. This is exactly what std::vector does. You might think that this is slow, copying all these elements around, and it can be, which is why a good std::vector implementation will grow its memory not by one element at a time (requiring this copy process whenever an element is added), but by multiple elements at a time. You start out with an empty vector that has no memory and when the first element gets added to the vector, instead of allocating just enough memory for one element, you allocate enough for a bunch of elements, for example 4. Then once the fifth element gets added, you don't allocate a new memory block for 5 elements, but for twice as many elements as before, 8 in this case. You can keep doubling the amount of allocated memory in this way, which turns out to be a pretty good strategy to prevent the copying process as much as possible.
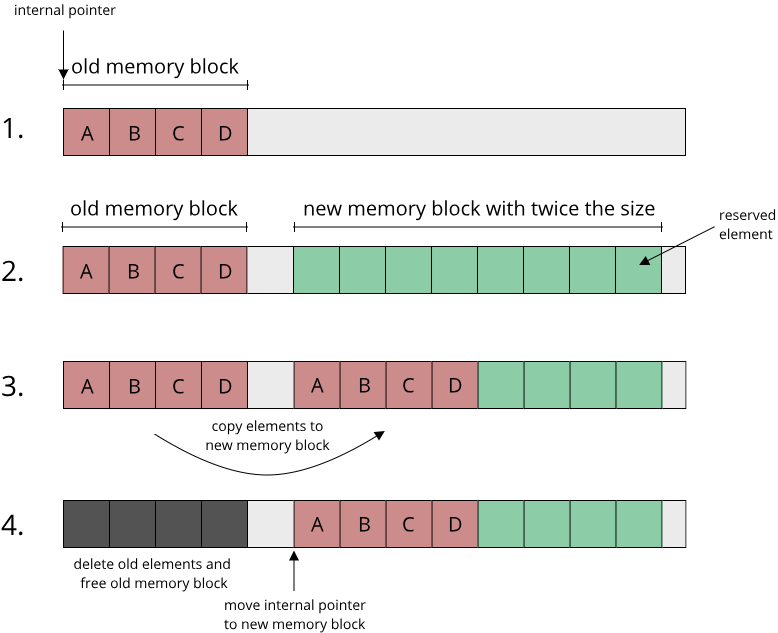
Now we spoke all this time of 'allocating a new memory block'. How exactly does that work though? If there are multiple instances of our growable array in memory, we need some way to keep track of which regions in memory are occupied, and which regions are still free to use.
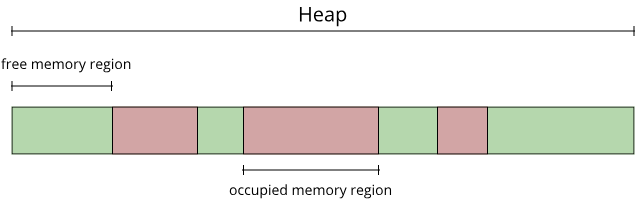
The operating system does not help us here, as we saw it only cares about how large the whole heap section is. This is where malloc and free come in, or in C++ new and delete. malloc and free are functions of the C standard library, and they deal with exactly this problem: Figuring out which regions of the heap are currently in use by our program, and which regions are free. How they do this does not really matter at this point (though we will look at ways for managing this allocated/free section in chapter 3.5), for now all we care about is that by calling malloc, we will get a pointer to a memory region somewhere in the heap that we can use in our program for as long as we like. If we are done using it, we call free to notify the C standard library that this memory region is free to use again. It can then be returned from another call to malloc in the future.
Before looking at this in action, make sure you understand why exactly we have to keep track of allocated and free memory regions! After all, on the stack we didn't really have to do this, our memory just grew and shrank in a linear fashion. The reason heap management is more complicated is that in reality, memory allocation is not always linear. It is not, because not all memory regions have the same lifetime. On the stack, all variables and functions have a hierarchical lifetime, which is to say that for two functions a() and b(), if a() calls b(), the lifetime of b() (and all its associated local variables) is strictly less than the lifetime of a(). This means that memory for all variables in b() is allocated after memory for the variables of a(), and it is released again before the memory for the variables of a() is released! The lifetime of a variable therefore is the time for which the memory of that variable is currently allocated.
In reality, you often have data in your code that gets created within one function, but is used well after the function has been exited, leading to lifetimes that are not hierarchical anymore. This happens as soon as we start to structure our code, moving different functionalities into different functions, namespaces, classes etc. Putting a bit of structure into our number-example already shows this:
#include <iostream>
#include <algorithm>
int* get_user_numbers(int count) {
// The lifetime of 'numbers' is LONGER than the lifetime implied by 'get_user_numbers'!
int* numbers = static_cast<int*>(malloc(count * sizeof(int)));
for(int idx = 0; idx < count; ++idx) {
std::cin >> numbers[idx];
}
return numbers;
}
void sort_and_print(int* numbers, int count) {
std::sort(numbers, numbers + count);
for(int idx = 0; idx < count; ++idx) {
std::cout << numbers[idx] << std::endl;
}
}
int main() {
std::cout << "How many integers do you want to input?\n";
int count;
std::cin >> count;
std::cout << "Please enter " << count << " strings:\n";
int* numbers = get_user_numbers(count);
sort_and_print(numbers, count);
free(numbers);
return 0;
}
This example already shows the usage of malloc and free to manage dynamic memory.
This fine-grained control over the lifetime of memory is one of the main things that sets a systems programming language apart from other more high-level languages!
In the remainder of this chapter, we will look at ways of getting rid of using malloc and free while still maintaining the capability of using dynamic memory allocation.
Recap
Try to answer the following questions for yourself:
- Where do the stack and the heap live within the address space of a process?
- Why do we have both the stack and the heap?
- Could we exclusively use the heap and have no stack at all?
Memory management basics
The way dynamic memory allocations work in C, through manually calling malloc and free, is one of the main points of frustration for programmers coming from higher-level programming languages such as Java or Python, which manage dynamic memory automatically. It is also one of the major points where bugs can manifest in a program. Calling malloc but forgetting to call free, or accidentally calling free twice, are popular errors that even experienced programmers tend to make, especially in large code bases. A large part of systems programming language design over the last decade and more has been focused on preventing these bugs through clever language features, while at the same time retaining the full control over memory allocations to the developers. We will explore which strategies are in use today in both C++ and Rust and build a solid understanding of how these strategies came to be and how they work under the hood. Building this understanding requires three things:
- Understanding composite datatypes (i.e. the
classandstructkeywords) and how they relate to memory - Understanding memory allocation
- Understanding value semantics
Composite datatypes
Let's start with composite datatypes. In C++, these are the types you create when writing class or struct. As a reminder, the only difference between class and struct in C++ is the default visibility of members (public for struct, private for class). A composite type is a type that combines primitive types (int, float, pointers etc.) and other composite types into more complex types. For a precise overview of all the different types in C++, check out the Types page on cppreference.
When we create a variable of such a composite type, the compiler has to figure out how much memory is required for this variable. For this, the language defines a bunch of rules that determine the memory layout of the composite type. While the actual rules can be a bit complicated, it is sufficient to understand the basic principle, for which we will look at the following composite datatype:
struct Composite {
int i1;
double d1;
void* ptr1;
}
The memory layout consists of two pieces of information: The size of the type and its alignment. The size determines how many bytes a single instance of the type requires. Alignment is a bit more special and refers to the numbers of bytes between two successive addresses at which an object of this type can be allocated. The alignment is always a non-negative power of two. Size and alignment are related to each other, as we will see shortly, and this relationship makes things complicated when figuring out how many bytes an instance of a type requires. A simple (but incorrect) formula for the size of a composite type is the sum of the size of each of its members. For our Composite type, this would mean the size of int plus the size of double plus the size of void*. These are all primitive types, so we can look up their size in the C++ standard. The standard only defines lower bounds for the size, but in practice there are a handful of accepted values for all major platforms. Disregarding the old Win16 API, the three major conventions are called ILP32 (4/4/4), LLP64 (4/8/8), and LP64 (4/8/8). The numbers refer to the size of an int, long, and pointer respectively. ILP32 is the default target for all 32-bit Unix systems (Linux, macOS) as well as the Win32 API. LLP64 is the Win32 API on 64-bit systems, and LP64 is 64-bit Unix. Let's stick with LP64 for now, which gives us the following
- Size of
int: 4 bytes - Size of
double: 8 bytes (typically refers to the 64-bit type in IEEE-754 floating point standard) - Size of
void*: 8 bytes (since it is a pointer)
Our naive algorithm would thus give Composite a size of 20 bytes. The memory layout of this type would therefore consist of 4 bytes for the i1 member, followed by 8 bytes for the d1 member and another 8 bytes for the ptr1 member:

In comes the alignment. Alignment is important because certain CPU instructions require that the data that they operate on is aligned to a specific power of two, which is to say the memory address on which the instruction operates is divisible by that power of two. The x86-64 instruction set is a bit more lenient and allows non-aligned accesses (with a performance penalty), others, such as the ARM instruction set, require correct alignment and will otherwise raise a CPU error! 64-bit floating point operations typically require 64-bit (8-byte) alignment, so our double value has to be 64-bit aligned! Suppose our variable of type Composite starts at byte 0 (which is correctly aligned, as 0 is divisible by 8). The offset of the d1 member within Composite is 4 bytes, so d1 would have the address 4, which is not divisible by 8. This would violate alignment!
To guarantee correct alignment for all members of a composite type, the compiler is allowed to introduce padding bytes, which are unused bytes within the type that do not belong to any member. In the case of the Composite type, the compiler might insert four padding bytes after the i1 member, but before the d1 member. This will guarantee that both d1 and ptr1 will always be correctly aligned, so long as the instance of the type starts at a correctly aligned address. The corrected memory layout thus will look like this:

There are some ways to control the amount of padding in C++, typically through compiler intrinsics. For example to prevent any padding bytes from being inserted, on GCC one would use __attribute__ ((packed)) or the equivalent #pragma pack(1) on MSVC.
Rust has its own set of rules for type memory layout, which are explained in the documentation. By default, the Rust compiler will respect the alignment of all type members, though the default memory layout (called the Rust representation) is implementation-defined. There are options to use a memory layout compatible with C, or to specify alignment directly.
The difference between memory allocation and memory initialization
Before looking at ways to make our life easier as programmers, we quickly have to go over the difference between malloc/free in C and new/delete in C++. Simply put: malloc allocates memory, but it does not initialize it, which is why in C you will often see code that first calls malloc to obtain a pointer, and then writes some values to the memory pointed to by this pointer. In C++, classes exist, from which objects can be created. If you create an object, you would like it to be in a usable state immediately after creation, which is what the constructor is for in C++. If you create a new object on the stack, you call the constructor and the compiler figures out where in memory to put your object:
struct Obj {
int v1;
float v2;
};
int main() {
Obj obj = Obj(); //This is the constructor call right here: Obj()
return 0;
}
The variable declaration (Obj obj) is what allocates memory on the stack, the constructor call (Obj()) is what writes values to that memory.
new is nothing more than the way to express within C++ that you want that exact same object, but allocated in a dynamic memory region on the heap instead of on the stack:
struct Obj {
int v1;
float v2;
};
int main() {
auto obj = new Obj(); //Almost the same syntax, the constructor call is still there!
return 0;
}
It is worth pointing out that in this second example, there are actually 2 memory allocations: One on the heap through new, and one on the stack, because new returns a pointer to the allocated memory block on the heap, and we store this pointer in a variable on the stack! We could do new Obj(); instead of auto obj = new Obj(); and would only get the heap allocation, but then we would never be able to free the memory allocated with new because we never memorized the address of the allocation.
Objects that manage memory
Besides constructors, C++ also has destructors, which manage how to destroy an object. Here is the neat thing: The C++ language ensures that the destructor of an object is automatically called when the object goes out of scope. So just as stack memory is automatically cleaned up when we exit a function scope, destructors are called for all objects that live within that function scope:
#include <iostream>
struct Obj {
int v1;
float v2;
Obj() {
std::cout << "Constructor called\n";
}
~Obj() {
std::cout << "Destructor called\n";
}
};
int main() {
auto obj = Obj(); //<-- Object lifetime starts here with constructor call
return 0;
} //<-- Object lifetime ends here with *automatic* destructor call
This fundamental property of the C++ language has a name: Resource acquisition is initialization, or RAII for short. The name is unintuitive, but the concept behind it is immensely powerful and one of the key features that set C++ apart from other programming languages. Rust also supports RAII and makes heavy use of it.
With RAII, we can exploit the fact that we get an automated clean-up mechanism to make dynamic memory management easier. Think about our growable array that we wanted to write. If we use dynamic memory allocation to make it work, we better make sure that whoever is using this growable array does not have to worry about the internal memory management that is going on. We can do this by writing our growable object as a class which frees its allocated memory in its destructor:
This vector implementation is far from perfect, but what it does is it encapsulates the dynamic memory allocation and makes sure that whoever uses this vector never has to use one of the dynamic memory allocation routines themselves. All allocations happen automatically, and once the vec variable goes out of scope at the end of main, all allocated memory is released again. And even better: The dynamic memory management is done in a way that is just as efficient as if we had written everything by hand! As systems programmers, we love these kinds of abstractions: Fast code, but much nicer to read and write, and very safe as well!
A key takeaway from this section is that the RAII mechanism is so powerful because it is automatic. We never really have memory management problems when only using stack-based memory management (i.e. local variables), so we try to wrap dynamic memory allocations in types that can be used using stack-based memory management. This is what the rest of this chapter is all about!
Recap
Try answering the following questions for yourself:
- What exactly is alignment in the context of memory? Why is it necessary?
- What is the difference between
mallocandnewin C++? Why do we need both?
A first glimpse of memory ownership and lifetimes
Let's assume for a moment that we use RAII to wrap all dynamic memory allocations inside some well-named classesSpoiler: We will do just that in a moment. There are a lot of these classes available in both C++ and Rust (though in Rust they are not called classes), and they are really useful!, just as we did with our CustomVector class. Does this solve all our problems with dynamic memory management?
The main problem that we were trying to solve with the RAII approach was that different pieces of heap memory will have different lifetimes. Some will live only a short time, others will live longer or even as long as the whole program runs. Through RAII, we are able to tie the lifetime of dynamic memory to the automated scope-system that C++ and Rust provide. But that really only shifted our problem from one place to another. Where before we had to memorize where to release our memory (e.g. by calling free), we now have to make sure that we attach our RAII-objects (like CustomVector) to the right scope. Remember back to the resource lifecycle that we learned about in chapter 2.4 and the associated concept of a resource owner. Through RAII, classes that manage dynamic memory, such as CustomVector, become owners of this dynamic memory. By the transitive property, the scope that an object of such a class lives in becomes the de-facto owner of the dynamic memory.
Why is this distinction important? After all, scope management is an inherent property of the C++ and Rust programming languages, and the compiler enforces its rules for us. It would not be important, were it not for two facts: First, just as we used dynamic memory allocation to break the hierarchical lifetime structure of the stack, we now also need a way to make our RAII-classes life longer than a single scope. Otherwise, how can we ever write a function that creates an object that lives longer than this function? Second, up until now we silently assumed that every resource can only have exactly one owner, however in reality, this is not always the case. There are certain scenarios where it is benefitial for the simplicity of the code or even required for correctness to have multiple simultaneous owners of a single resource. How would we express this ownership model with our CustomVector class?
How to leave a scope without dying
Let's start with the first situation: How do we write a function that creates a CustomVector and hands it to its calling function? The intuitive way of course is to simply return the CustomVector from the function. After all, this is what 'returning a value from a function' means, right? But think for a moment on how you might realize this notion of 'returning a value from a function', with all that we know about scope rules. After all, we said that at the end of a scope, every variable/object within that scope is automatically destroyed! Take a look at this next example and try to figure out what exactly is happening with the dummy variable inside the foo function, once foo is exited. For convencience, we even print out whenever a constructor and destructor is called:
#include <iostream>
#include <string>
// A custom type that wraps a non-trivial type (std::string) and prints
// constructor & destructor calls
struct StringWrapper {
std::string inner;
StringWrapper(std::string inner) : inner(inner) {
std::cout << "StringWrapper is created" << std::endl;
}
~StringWrapper() {
std::cout << "StringWrapper is destroyed" << std::endl;
}
};
StringWrapper foo() {
StringWrapper wrapper("hello");
return wrapper;
}
int main() {
StringWrapper wrapper = foo();
std::cout << wrapper.inner << std::endl;
return 0;
}
Interestingly enough, there is only one destructor called, at the end of the main method. But inside foo, wrapper is a local variable. Why did it not get destroyed? Sure, we wrote return wrapper;, but that does not explain a lot. A perfectly resonable way that this example could be translated to would be this:
int main() {
StringWrapper outer_wrapper;
// We copy-pasted the function body of 'foo()' into main:
{ // <-- The scope of 'foo()'
StringWrapper wrapper("hello");
outer_wrapper = wrapper;
} // <-- 'wrapper' gets destroyed here
std::cout << outer_wrapper.inner << std::endl;
return 0;
}
Here we took the function body of the foo() function and just copied it into the main method. Our return statement is gone, instead we see an assignment from the local wrapper variable to the variable in the scope of main, now renamed to outer_wrapper. If we run this code, we see that two destructors are run, as we would expect, since first the wrapper variable gets destroyed at the end of the local scope, and then the outer_wrapper variable gets destroyed once we exit main.
To solve this puzzle, we have to introduce the concept of return value optimization (RVO). It turns out that our manual expanded code from the previous example is actually how returning values from functions used to work, at least as far as the C++ standard was concerned. Remember, the C++ standard and the implementations of the C++ compilers are two different things. Compilers sometimes do stuff that yields better performance in practice, even though it does not agree with the standard fully. Returning values from functions is one of these areas where we really would like to have the best possible performance. Without any optimizations, returning a value from a function goes like this:
- Create an anonymous variable in the scope of the calling function (
mainin our example) - Enter the function, do the stuff, and at the end of the function, copy the function return value into the anonymous variable in the outer scope
- Clean up everything from the function's scope
So data is actually copied here, because otherwise our local variable would be destroyed before we could attach it to the variable in the outer scope. We will learn shortly what a copy actually is from the eyes of a systems programmer, but for now suffice it to say that copies can be costly and we want to prevent them, especially for something as trivial as returning a value from a function. So what most compilers do is they automatically rearrange the code in such a way that no copy is necessary, because the local variable within the functions scope (wrapper in our case) gets promoted to the outer scope. This is an optimization for return values, hence the name RVO, and since C++17, it is mandated by the standardAs always, rules are complicated and RVO is only mandated in simple cases. In reality, compilers are quite good at enabling RVO, but there are some scenarios where it is not possible., which is why we see just one destructor call in our initial example.
Great! Nothing to worry about, we can safely write functions that create these RAII-objects and return them to other functions. Now, what about this other thing with multiple owners?
The Clone Wars
In the previous section, we learned how to move from an inner scope to a greater scope, using return. The opposite should also be possible: Taking an object from an outer scope and making it available to the scope of a function that we call. This is what function arguments are for, easy! Let's try this:
void print_wrapper(StringWrapper wrapper) {
std::cout << "Got a StringWrapper(" << wrapper.inner << ")" << std::endl;
}
int main() {
StringWrapper wrapper("hello");
print_wrapper(wrapper);
std::cout << wrapper.inner << std::endl;
return 0;
}
If we run this example, we will find not one but two destructor calls. Of course, if you have done a little C++ in the past, you know why this is the case: The print_wrapper function takes its argument by value, and passing arguments by value copies them in C++. For our StringWrapper class, this does not really matter, but see what happens when we run the same code with our CustomVector class:
void print_vec(CustomVector<int> arg) {
std::cout << "Our vector has " << arg.get_size() << " elements\n";
}
int main() {
CustomVector<int> vec;
vec.push(42);
vec.push(43);
print_vec(vec);
std::cout << vec.get_size() << std::endl;
return 0;
}
Oops, a crash. free(): double free detected in tcache 2. That doesn't look good... Of course we commited a cardinal sin! Our CustomVector class was written under the assumption that the underlying dynamic memory has just one owner. And now we called print_vec and created a copy of our CustomVector. The copy gets destroyed at the end of print_vec, freeing the dynamic memory, while there is still another object pointing to this memory! Once this object (vec) gets destroyed, we are calling free() with a memory region that has already been freed and get an error.
But wait: How actually was the copy of our CustomVector created? In C++, for creating copies of objects, the copy constructor is used. But we never wrote a copy constructor! In this case, the C++ rules kicked in. The compiler figured out that we want to copy our object at the call to print_vec, and it was nice enough to generate a copy constructor for us! How nice of it! The copy constructor it generated might look something like this:
CustomVector(const CustomVector& other) :
data(other.data),
size(other.size),
capacity(other.capacity) {}
This copy constructor simply calls the copy constructor for all the members of our CustomVector class. All our members are primitive types (a pointer and two integers), so they can be copied using a simple bit-wise copy. However given the semantics of our CustomVector class, this is wrong! CustomVector stores a pointer to a dynamic memory region, and this pointer owns the memory region. It is the responsibility of CustomVector to clean up this memory region once it is done with it. We can't just copy such an owning pointer, because then we move from a model with just one unique owner to a model with two shared owners. Clearly, if two people own something, one person can't destroy the owned object while the other person is still using it.
Now comes the grand reveal: Rust enters the picture!
Rust and move semantics
Let us try and write a similar example to our C++ CustomVector, but with Rust. Don't worry if you don't understand all of the code at this point, we will get there eventually, for now we focus on what is important for this chapter.
Disclaimer: For the sake of our sanity, the following example shows simplified code that is not extensible and contains a subtle bug! We will fix this in chapter 3.5!
Rust keeps data and functionality separated, so let's start with the data:
#![allow(unused)] fn main() { struct CustomVec<T: Copy> { // T: Copy means this Vec only works for types that don't need a destructor call! data: Box<[T]>, size: usize, capacity: usize, } }
A simple structure, storing values of some type T. We have a generic constraint on the type T, to make sure that we can copy the values. In C++, this constraint was implicit in the way we wrote our code (by using the assignment operator operator=), in Rust we have to explicitly state what our generic type has to be capable of. Just as in C++, we store the size and capacity using integer types. We also store the pointer to the dynamic memory region, using some special Rust type Box<[T]>. For now, let's say that this is the Rust equivalent for an owning pointer to a dynamically allocated array, similar to T* in C++ after a call to new[].
On to the implementation:
#![allow(unused)] fn main() { impl<T: Copy> CustomVec<T> { pub fn new() -> Self { Self { data: Box::new([]), size: 0, capacity: 0, } } pub fn push(&mut self, element: T) { if self.size == self.capacity { self.grow(); } self.data[self.size] = element; self.size += 1; } pub fn get_at(&self, index: usize) -> T { if index >= self.size { panic!("Index out of bounds!"); } self.data[index] } pub fn size(&self) -> usize { self.size } fn grow(&mut self) { // nasty details } } }
We define a new function, which is like the default constructor in C++We don't have to call this function new, there is no relation to the new operator in C++. It is just an ordinary function like any other Rust function, calling it new just makes sense and is an established convention that you will find on many types in Rust! Since this new function does not take any parameters, we could also implement the Default trait, which is the even more established way of default-constructing types in Rust. For the sake of simplicity, we didn't include an implementation of Default here.. We then define our push, get_at and size functions with very similar implementations to the C++ example. Lastly, there is a private function grow, whose inner details should not concern us at the moment. Doing what we were doing in the C++ grow implementation in Rust is quite complicated, and for a good reason. Just assume that we can get it to work somehow. We can then use our CustomVec:
fn main() { let mut vec: CustomVec<i32> = CustomVec::new(); vec.push(42); vec.push(43); for idx in 0..vec.size() { println!("{}", vec.get_at(idx)); } }
Now let's try to pass our CustomVec to a function, like we did in C++:
fn print_vec(arg: CustomVec<i32>) { println!("Got a CustomVec with {} elements", arg.size()); } fn main() { let mut vec: CustomVec<i32> = CustomVec::new(); vec.push(42); vec.push(43); print_vec(vec); for idx in 0..vec.size() { println!("{}", vec.get_at(idx)); } }
This example does not compile! Interesting! Did Rust just outsmart us and prevented us from doing something stupid during compile-time? It did, but not in the way we might think. If we look at the compiler error, we get some information as to what went wrong:
error[E0382]: borrow of moved value: `vec`
--> <source>:75:19
|
69 | let mut vec: CustomVec<i32> = CustomVec::new();
| ------- move occurs because `vec` has type `CustomVec<i32>`, which does not implement the `Copy` trait
...
73 | print_vec(vec);
| --- value moved here
74 |
75 | for idx in 0..vec.size() {
| ^^^ value borrowed here after move
First of all: Take a minute to appreciate how nice this error message looks like! Even if you don't understand half of the words in it, it contains a lot of useful information and shows us exactly where in the code the problem lies. Time to analyze this message!
borrow of moved value: 'vec' So this tells us that our variable vec has been moved, for some reason. We then try to borrow this moved value, and somehow this is not allowed. Makes sense, if we move something and then try to use it, it won't be there anymore. So what is this borrow thing? Borrows are the Rust equivalent to references in C++. They even share almost the same syntax: int& in C++ is a (non-const) reference to an int, which in Rust would be written as &i32, a borrow of an i32. References in C++ are often created automatically by declaring a type to be a reference: int val = 42; int& ref_to_val = val; In Rust, we have to explicitly create a reference using the ampersand-operator &: let val = 42; let borrow_of_val = &val;
On the surface, borrows and references are very similar. If we write a const member method in C++, this is equivalent to a Rust method taking a &self parameter, a borrow to self, where self refers to the value that the function is called for. This is what happen in line 75, when we call the size function of our CustomVec type. Look at how it is defined:
#![allow(unused)] fn main() { pub fn size(&self) -> usize { self.size } }
Calling vec.size() is fully equivalent to the following code:
#![allow(unused)] fn main() { CustomVec::<i32>::size(&vec) }
The method calling syntax using the dot-operator is just some syntactic sugar that Rust provides for us! Which explains why the Rust compiler says that we are borrowing our vec variable here, even if we never explicitly wrote &vec.
Now comes the most important part: Rust prevents us from obtaining a borrow to any variable whose lifetime has expired. In C++, scope rules do the same thing, however Rust is more powerful, because the lifetime of a variable can end even if the variable itself is still technically in scope. How is this possible? Due to move semantics.
Move semanticsSemantics is a fancy term for the meaning of language constructs. In this case, move semantics is equivalent to "The meaning of passing values around (into functions or to other variables) is equivalent to moving those values" are an inherent property of Rust (though C++ also supports something similar). To move a value means to take it from one place to another, leaving nothing behind at the old place. Move semantics are closely related to copy semantics, as illustrated by the following picture:
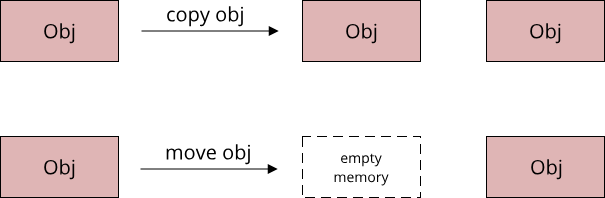
C++ employs copy semantics by default, which is to say that whenever we pass a value of something somewhere, a copy of the value is created, leaving the original value untouched. Move semantics on the other hand means that whenever we pass a value, the value is moved to the new location, and the old location is empty afterwards. This is why our print_vec method that takes a CustomVector by value works silently in C++:
void print_vec(CustomVector<int> arg) {
std::cout << "Our vector has " << arg.get_size() << " elements\n";
}
int main() {
CustomVector<int> vec;
//...
print_vec(vec /*<-- a COPY of 'vec' is created here! 'vec' is untouched!*/);
std::cout << vec.get_size() << std::endl;
return 0;
}
Whereas in Rust, our CustomVec is moved into the print_vec function:
fn print_vec(arg: CustomVec<i32>) { println!("Got a CustomVec with {} elements", arg.size()); } fn main() { let mut vec: CustomVec<i32> = CustomVec::new(); //... print_vec(vec /*<-- 'vec' is MOVED into the function. We cannot use something that has been moved, because it is gone!*/); for idx in 0..vec.size() { println!("{}", vec.get_at(idx)); } }
This point is quite important: C++ is copy-by-default, Rust is move-by-default!
Both the C++ and the Rust example are of course easily fixed, by realizing that we want to pass a reference/borrow to the print_vec function. Which takes us back to the concept of ownership: All variables (local, member, global) are owners of their respective values in C++ and Rust. If we do not want to own something, we make the variable hold a reference (C++) or borrow (Rust). They are like visitors to something that is owned by someone else.
Digression: On the difference between pointers and references
One question that often arises when learning C++ is: What is the difference between a pointer and a reference? Which is a good question to ask, because they both seem to do a similar thing: Point to something else so that we can use this something else without owning it. Under the hood, a C++ reference is equivalent to a pointer, pointing to the memory address of whatever value is referenced. References are more restrictive than pointers however:
- A reference must never be
null, that is to say a reference always points to a valid memory address - References are read-only. Once a reference has been created, its value (the address that it is pointing to) can never be changed. Of course, the value at that address can be changed through the reference, just not the address that the reference points to
- For that reason, references must be initialized when they are created. The following piece of code is thus invalid:
int val = 42; int& val_ref; val_ref = val;
Note that these rules are enforced purely by the compiler. There is zero runtime overhead when using references compared to using pointers. These rules often are very convenient and actually allow us to write faster code: A function taking a pointer has to check for potential null values, whereas a function taking a reference can omit this check.
Recap
Try to answer the following questions for yourself:
- What do we mean when we say "Rust has move-semantics and C++ has copy-semantics"?
- What problems can occur with silent copies and RAII wrappers such as our C++
CustomVector? - Why does a Rust function such as
fn size(&self)need to borrowself? (Hint: Think about how you might usethisin C++)
Copying values
Let us think back to what we initially set out to do in this chapter: We saw that there is some need to use dynamic memory allocation in a program, and we saw that it can be difficult to get right. So we (ab)used some language mechanics to create safe(r) wrapper types that do the dynamic memory management for us. Which led us down a rabbit hole of lifetimes and ownerships. We now know that we can use references/borrows to get around some of these ownership problems, but it hasn't really helped us in writing a better vector implementation. While the Rust language forces us to use borrows or accept that objects move, the C++ language does not do the same. So while the right way to do things is to pass our CustomVector object by reference to a function, we (or someone else using our code) can still ignore this knowledge and use call-by-value.
There are two ways out of this: One is to simply prevent our CustomVector type from ever being copied in the first place, effectively preventing call-by-value. This is easily done in C++11 and onwards, by removing the copy constructor and copy assignment operator:
CustomVector(const CustomVector&) = delete;
CustomVector& operator=(const CustomVector&) = delete;
Trying to pass CustomVector by value then gives the following error message:
<source>:61:18: error: use of deleted function 'CustomVector<T>::CustomVector(const CustomVector<T>&) [with T = int]'
61 | print_vec(vec);
| ~~~~~~~~~~^~~~~
Which is not too bad for a C++ error message ;)
The other option is to think hard on what it actually means to copy a vector. Our CustomVector is actually a wrapper around some other type, in our case a dynamically allocated array. The important property of CustomVector is that the type that it wraps is not part of the memory of the CustomVector type itself! In memory, it looks like this:

For any such type that refers to memory that is not part of itself, we have two options when we copy the type. We can copy only the memory of the type itself, or we can also copy the external memory. The first approach is called a shallow copy, the second is called a deep copy. A shallow copy always creates additional owners to the same data, which was what the default-implementation of the copy constructor for CustomVector was doing. A deep copy creates a completely new object with a new owner and thus does not have the problem of ownership duplication. This comes at a cost however: Creating a deep copy of CustomVector means allocating another memory block on the heap and copying all elements from the original memory block to the new memory block.
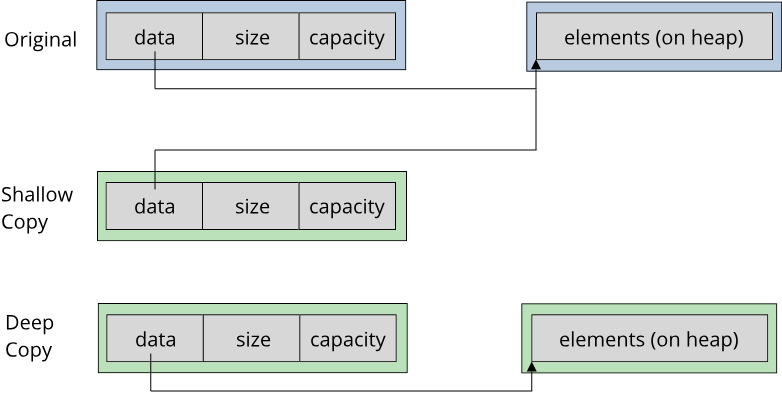
Beyond the concept of shallow and deep copies, there is also another aspect to copying data, this time from a systems programming perspective. We can ask ourselves how copying a value translates to machine code. This is one last piece of the puzzle that we need to implement a decent copyable vector.
Copying versus cloning
To understand what is going on our your processor when we copy a value or an object, we can look at an example:
struct Composite {
long a, b, c, d;
};
int main() {
Composite a;
a.a = 42;
a.b = 43;
a.c = 44;
a.d = 45;
Composite b;
b = a;
return 0;
}
Here we have a composite type, made up of a bunch of long values. We create an instance a of this composite type and assign some values to its members. Then we create a second instance b and assign a to it, effectively creating a copy of a in b. Let's look at the corresponding assembly code of this example:
; skipped some stuff here ...
mov rbp, rsp
mov QWORD PTR [rbp-32], 42
mov QWORD PTR [rbp-24], 43
mov QWORD PTR [rbp-16], 44
mov QWORD PTR [rbp-8], 45
mov rax, QWORD PTR [rbp-32]
mov rdx, QWORD PTR [rbp-24]
mov QWORD PTR [rbp-64], rax
mov QWORD PTR [rbp-56], rdx
mov rax, QWORD PTR [rbp-16]
mov rdx, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-48], rax
mov QWORD PTR [rbp-40], rdx
; ... and here
A bunch of mov instructions. mov is used to move values to and from registers or memory. Of course in assembly code, there is no notion of objects anymore, just memory. Our two instances a and b live on the stack, and the current stack pointer always lives in the register called rsp. So the first line moves the value of rsp into another register for working with this value. Then we have four instructions that load immediate values (42 to 45) into specific memory addresses. This is what the mov QWORD PTR [X] Y syntax does: It moves the value Y into the memory address X. So the four assignments to the member variables a to d turn into four mov instructions which write these values onto the stack.
sizeof(Composite) will tell us that an instance of the Composite type takes 32 bytes in memory (at least on a 64-bit Linux system), so the first 32 bytes of the stack frame of the main function correspond to the memory of the a object. The next 32 bytes then correspond to the b object. The copy assignment can be seen in the eight mov instructions following the initialization of a: The values of a.a, a.b etc. are loaded into registers from their respective addresses on the stack, and then these register values are written to the stack again, at the address of b.a, b.b and so on. This has to be done in two steps, because the mov instruction in the x64 instruction set can only move data from a register to memory or vice versa, but never from memory to memory directly. The compiler chose to use two registers (rax and rdx), but all the copying could also be done with only the rax register, which would look like this:
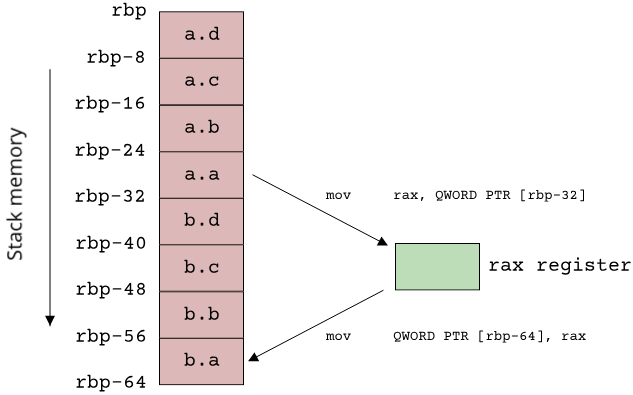
So there we have it: Copying the Composite type is equivalent to copying some numbers from one memory location to another. The C++ standard calls any type with this property trivially copyable. In Rust, there is a special trait for types that can be copied by simply copying their memory, aptly named Copy. In C++, being trivially copyable is an inherent property on a type, in Rust we have to explicitly state that we want our type to be trivially copyable:
#[derive(Copy, Clone)] struct Composite { a: i64, b: i64, c: i64, d: i64, } pub fn main() { let a = Composite { a: 42, b: 43, c: 44, d: 45, }; let b = a; println!("{}", a.a); }
We do so using the derive macro, which is a little bit of Rust magic that automatically implements certain traits for us, whenever possible. The generated assembly code of the Rust example will be quite similar to that of the C++ example. As an additional benefit, our assignment let b = a; does not move out of the value a anymore. Instead, since the value is trivially copyable, b becomes a copy of a and we can still use a after the assignment.
For all other types that can be copied, but not through a simple memory copy, Rust provides the Clone trait, which is a weaker version of Copy. In fact, any type that implements Copy has to implement Clone. Clone does what the copy constructor in C++ does: It provides a dedicated method that performs the copy process. To create a deep copy of our CustomVec class, we could use the Clone trait:
#![allow(unused)] fn main() { impl<T: Copy> Clone for CustomVec<T> { fn clone(&self) -> Self { let mut copy = Self::new(); for idx in 0..self.size() { copy.push(self.get_at(idx)); } copy } } }
This is not an efficient implementation, but it illustrates the process: Create a new CustomVec and push copies of all elements of the current CustomVec into the copy.
The distinction between a type being Copy or being Clone (or none of the two) is very useful for systems programming, because we can check on this property. If we know that a type implements Copy, we can assume that such copies are cheap and write algorithms differently than if the type only implemented Clone.
Borrows in Rust
Up until now, we haven't really talked a lot about some of the aspects in which Rust is fundamentally different to C++. If you heard a little bit about Rust, one of the first things that comes up is that Rust is a memory-safe language. What does that mean?
Do not overstay your welcome - The problem with borrowing values
To understand memory safety, we have to revisit the concept of references/borrows. All that follows is strictly valid for pointers as well, however pointers in C/C++ play a weird double-role, so it is easier to understand what is going on if we stick to references.
A reference is something like a visitor to a value. It does not own the value, but it can access the value and do things with it. Now what happens if this value gets destroyed while there are references to the value. What happens with the references? What happens if you try to access the value through the reference?
A simple but contrived example where this situation can happen is shown here:
int& evil() {
int local = 42;
return local;
}
int main() {
int& ref = evil();
return ref;
}
Here we have a function evil(), which returns a reference. In this case, it returns a reference to a local variable from within this function's scope! Once we exit evil(), the local variable gets cleaned up and we now have a reference to some memory on the stack that is already cleaned up. In C++, this is undefined behaviour, which means that absolutely anything can happen. Our program can run happily, crash now, crash later, give wrong results, who knows? This situation is what we mean when we call a language 'memory unsafe': The ability to manipulate memory that is not owned by your program anymore.
Of course in this situation, the error is trivial to spot and the compiler actually issues a warning for us:
<source>: In function 'int& evil()':
<source>:5:12: warning: reference to local variable 'local' returned [-Wreturn-local-addr]
5 | return local;
| ^~~~~
<source>:4:9: note: declared here
4 | int local = 42;
| ^~~~~
In other situations, similar errors might be harder to spot, yielding subtle bugs that can be difficult to track down! Memory unsafety actually includes a whole bunch of program errors related to memory:
- Reading from or writing to memory that has been freed
- Reading from or writing to memory that has never been allocated, for example out of bounds accesses on allocated memory blocks
- Writing to memory while concurrently reading from the memory
The third category of problems is related to the concept of parallel programming, which we will discuss in a later chapter and instead focus on the first two categories: Read/write after free, and read/write out of bounds. Here is a small exercise to familiarize yourself with these problems:
Exercise 3.3: Write two small C++ programs illustrating read/write after free and read/write out of bounds. Which real-world scenarios do you know where these memory problems can occur?
The reason why these memory problems can manifest in our programs lies in the way that programming languages such as C/C++ abstract memory. Both references and pointers are just numbers refering to a memory address, the validity and semantics of this memory address comes from the context of the program. Take the following example:
#include <iostream>
struct Composite {
long a, b, c, d;
};
int main() {
Composite a;
a.a = 42;
Composite* ptr_to_a = &a;
std::cout << ptr_to_a << std::endl;
std::cout << ptr_to_a->a << std::endl;
return 0;
}
Here we create a pointer to an instance of the Composite class. While we are used to thinking of the construct Composite* as 'A pointer to a Composite object', pointers really are just memory addresses. The type of the pointer just tells the compiler how to interpret this memory address, in this case as containing the memory for a Composite object. However that really is all there is to it, the pointer itself stores no information about its type! The type is just a guide for the compiler to generate the correct assembly code. Here is all the information that is not stored within a pointer:
- How large is the memory region that the pointer points to?
- Who owns this memory region?
On the surface, references seem to solve all these problems: A reference always points to a single value, or an array of constant size, and a reference never owns the memory it points to. Unfortunately, this is not enough. A reference can't be used to refer to a dynamically allocated memory block, because the reference can't store the size of the memory block and its address at the same time. Additionally, even if a reference never owns a memory region, it still can't tell us who does own the memory region. This was the main reason for our invalid program that returned a reference to a local variable: The reference pointed to memory which had no owner anymore!
This really is the main issue: The built-in C++ mechanisms are not strong enough to express all the information that we need to guarantee memory safety. This is exactly where Rust comes in! To guarantee memory safety, the Rust abstractions for pointers and references contain all this information. Even better, Rust does this in the majority of cases without any runtime overhead!
Enter the Rust borrow-checker
The central part that makes memory safety possible in Rust is a tool built into the compiler called the borrow checker. While the Rust book has many great examples that show you how the borrow checker works, we will try to understand it for ourselves based on the C++ examples that we saw in this chapter. So let's try to translate the evil C++ example to Rust:
fn evil() -> &i32 { let val: i32 = 42; &val } pub fn main() { let evil_borrow = evil(); println!("{}", *evil_borrow); }
Right off the bat, this does not compile. Again, we get a nice error message:
error[E0106]: missing lifetime specifier
--> <source>:1:14
|
1 | fn evil() -> &i32 {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
1 | fn evil() -> &'static i32 {
|
Interesting, now there is something about lifetimes here. As if this whole talk over the last chapter(s) about ownership and lifetime somehow made its way into the Rust programming language ;) So what is a lifetime in Rust? It is a little piece of information that is required for every borrow, telling the compiler how long the value that is borrowed lives! This almost tells us who owns the memory, this one crucial piece of information that C++ references were missing. It turns out that we don't actually have to know who exactly the owner of a piece of memory is (object a or b or what have you). Remember back to the RAII concept: We figure out that through RAII, we can tie the lifetime of resources to the scope of functions, and the the scope becomes the de-facto owner of the resource. This is what Rust lifetimes are: The name of the scope that the memory lives in!
To illustrate this, here is a quick example with some annotations:
pub fn main() { // <-- First scope, let's call it 'a let a : i32 = 42; let illegal_borrow; { // <-- Another scope, let's call it 'b // We borrow a, which lives in the scope 'a. This information gets encoded // within the TYPE of borrow_a. The full type is: // &'a i32 let borrow_a = &a; // Let's do the same thing again, but this time for a variable that lives // in the scope 'b! let b = 43; // The type of illegal_borrow is: // &'b i32 illegal_borrow = &b; } // Rust knows AT COMPILE TIME that using illegal_borrow from the scope 'a // is not allowed, because the lifetime 'b has expired! println!("{}", *illegal_borrow); }
Encoding lifetime information within the type of borrows is a powerful way of solving the lifetime problem. Since types are purely compile-time constructs, there is zero runtime overhead, and we still get all the benefits of checking for memory safety. Note that, while the previous example assigns some names to the scopes, these names are usually determined by the compiler automatically. In cases where we have to specify a lifetime name ourselves, we do so by prefixing the name with a single quote: 'name. Before we do this, however, one word on a special lifetime that you might have spotted in the error message of the first example in this section: 'static.
Up until now, we only talked about function scopes, with the 'largest' scope being the one of the main method. However there is a scope that is even larger: The global scope. This is where global variables reside in, which get initialized before we enter main, and get destroyed after we leave main. This scope has the fixed name 'static in Rust, with a lifetime equal to the lifetime of the program. Here are the two main things that have 'static lifetime:
- Global variables
- String literals (
"hello")
In a special sense, dynamically allocated memory also has 'static lifetime, because the heap lives as long as the program runs. However due to the way dynamically allocated memory is treated in Rust, you will rarely see this lifetime in this context.
Now, when do we have to specify a lifetime manually? This question is easy to answer: Whenever the compiler cannot figure out an appropriate lifetime for us. In this case it will complain, as it did for the initial example of this section, where we tried to return a borrow from a function. This is what the missing lifetime specifier error is trying to tell us!
Can we fix this error? The syntax for a lifetime specifier for a borrow goes like this: & 'lifetime TYPE, where TYPE is the type that we borrow, and 'lifetime is the name of our lifetime. So in our example of the evil() function, the lifetime of the borrow should be the name of the scope of the evil() function. However we don't know this name, as local scopes do not have a name that we can reference. Maybe we can try with this 'static lifetime first?
#![allow(unused)] fn main() { fn evil() -> & 'static i32 { let val: i32 = 42; &val } }
This gives us a new error: error[E0515]: cannot return reference to local variable 'val'. So the Rust compiler prevents returning a reference to a local variable, similar to the warning that we got in the C++ example. It is interesting that this is the error that we get, and not something akin to 'val' does not have a 'static lifetime, but for us this is a good thing, the error message that we get is easily understandable.
Let us try something else that is amazing when learning Rust. If you look at the full error message, you will see this line at the end:
For more information about this error, try 'rustc --explain E0515'. If we run the suggested line, we actually get a thorough explanation of what we are doing wrong, complete with code examples. The very first code example is actually exactly what we were trying to do :) Running rustc --explain ... is something you can try when you get stuck on an error that you don't understand in Rust.
Borrows inside types
Suppose we want to write a type that stores a reference to some other value. How would we express this in Rust using borrows? Here is a first try:
struct Ref { the_ref: &i32, } pub fn main() { let val : i32 = 42; let as_ref = Ref { the_ref: &val }; println!("{}", *as_ref.the_ref); }
With what we know already, this struct definition should make us suspicious: There is again a borrow without a lifetime specifier! Which is exactly the error that we get when trying to compile this code: error[E0106]: missing lifetime specifier. What would be a good lifetime specifier here? For writing types that use borrows, this is an interesting problem: A lifetime specifier refers to a specific lifetime, but this lifetime might not be known in the definition of our type. In our example, we create a Ref instance inside main, borrowing a value that lives in main, so the lifetime specifier would be equal to the scope of main. Disregarding the fact that we can't even name the scope of main, what if we specified our Ref type in another file, or even another library? There is no way to know about this specific main function and its scope in such a scenario.
It turns out that we don't have to know! Who said that our Ref type should only be valid for values borrowed within main? The specific as_ref instance is, but that doesn't mean that we could not create another instance at some other place in the code. What we need instead is a way for our Ref type to communicate on a per-instance base for which lifetime it is valid. This should ring a bell! We already know a concept that we can use to write a type that works with arbitrary types: Generics. Just as a type like Vec<T> can be used with arbitrary values for T (Vec<i32>, Vec<String> etc.), we can write a type that can work with arbitrary lifetimes:
#![allow(unused)] fn main() { struct Ref<'a> { the_ref: &'a i32, } }
We write this like any other generic type, but using the special Rust syntax for lifetime parameters with the quotation mark: <'a>. Now the lifetime of the borrowed value becomes part of the Ref type, which allows the Rust borrow checker to apply its lifetime checking rules to instances of Ref.
Compare this to C++, where we can easily store references inside types, but have no clue what these references point to:
#include <iostream>
struct Ref {
explicit Ref(int& the_ref) : the_ref(the_ref) {}
int& the_ref;
};
Ref evil() {
int val = 42;
Ref as_ref(val);
return as_ref;
}
int main() {
Ref as_ref = evil();
std::cout << as_ref.the_ref << std::endl;
return 0;
}
And just like that, we tricked the compiler, no warning message for returning the address of a temporary variable. Catching bugs like this during compile-time was one of the major design goals of Rust.
Almost done! One last thing remaining so that we can conclude this very long chapter!
Mutability and the rule of one
Now we are ready to learn about a central rule in Rust regarding borrows, which is called the rule of one.
The rule of one
You might have noticed that in Rust, variables and borrow are constant by default, which means you can't assign to them:
pub fn main() { let val : i32 = 42; let val_ref = &val; val = 47; // Not allowed, val is not mutable *val_ref = 49; // Not allowed, borrow to val is not mutable }
Any let binding (the fancy term for a variable in Rust) is immutable by default, so we can't assign to it twice. Any borrow is also immutable by default. To change this, we can use the mut keyword, making both let bindings and borrows mutable (i.e. writeable):
pub fn main() { let mut val : i32 = 42; val = 47; let val_ref = &mut val; *val_ref = 49; }
Notice a little difference between the two examples? The one with mut has the statements in a different order. What happens if we use the old order?
pub fn main() { let mut val : i32 = 42; let val_ref = &mut val; val = 47; *val_ref = 49; }
Now we get an error: error[E0506]: cannot assign to 'val' because it is borrowed. Here we have stumbled upon another rule that Rust imposes on borrowed values: You must not change a borrowed value through anything else but a mutable borrow! In our example, we try to mutate val while still holding a borrow to it, and this is not allowed. With just this simple example, it is a bit hard to understand why such a rule should exist in the first place, but there is a subtle C++ example which illustrates why this rule is useful:
#include <iostream>
#include <vector>
int main() {
std::vector<int> values = {1,2,3,4};
int& first_value = values[0];
std::cout << first_value << std::endl;
values.push_back(5);
std::cout << first_value << std::endl;
return 0;
}
Depending on your compiler, this example might be boring (because we got lucky), or it might be very confusing. We take a std::vector with four elements and get a reference to the first element with value 1. We then push a value to the end of the vector and examine our reference to the first element again. Compiling with gcc gives the following output:
1
0
Why did the first value change, if we added something to the end of the vector?? Try to find out for yourself what happens here first, before reading on.
Mutability is the root of all evil
So what exactly happened in the previous example? Remember how we implemented our CustomVector class? In order to keep growing our dynamic array, we sometimes had to allocate a new, larger array and copy values from the old array into the new array. If we do that, the addresses of all values in the vector change! Since a reference is nothing more than a fancy memory address, we end up with a reference that points into already freed memory. Which is undefined behavior, explaining why it is perfectly reasonable that we see a value of 0 pop up. If you have some experience with C++, you might know that it is dangerous to take references to elements inside a vector, however not even the documentation mentions this fact! Well, it does, just not for std::vector::operator[], where you might have looked first, instead you have to look at std::vector::push_back. Here it says: If the new size() is greater than capacity() then all iterators and references (including the past-the-end iterator) are invalidated.
We could have known, but it is a subtle bug. Why did it occur in the first place? And why do we find the relevant information only on the push_back method, not operator[] which we use to obtain our reference? The answer to these questions is simple: Mutability.
Mutability refers to things that can change in your program. We saw that in Rust, we have to use the mut keyword (which is a shorthand for mutable) to allow changing things, which is the opposite of C++, where everything is mutable and we can use const to prevent changing things. So here is another key difference between C++ and Rust: C++ is mutable-by-default, Rust is immutable-by-default! Why is mutability such a big deal? Hold on to your seats, because this answer might seem crazy:
Mutability is the source of ALL bugs in a program!
While throwing around absolutes is not something that we should do too often, this statement is so thought-provoking that we can make an exception. Did we really just stumble upon the holy grail of programming? The source of ALL bugs in any software? Time to quit university, you have gained the arcane knowledge to write transcendental code forevermore!

Of course there is a catch. Mutability is what makes our code do stuff. If there is no mutability, there is no input and output, no interaction nor reaction, nothing ever happens in our program. So we can't simply eliminate all mutability because we need it. What we can do however is to limit the usage of mutability! Clearly, not every line of code has to mutate some value. Sometimes we just want to read some data, look at some value but don't change it, and sometimes instead of changing a value, we can create a copy and apply our changes to this copy. This is the reason why Rust is immutable-by-default: Mutability is the exception, not the norm!
Now that we know that mutability can be dangerous, the Rust borrow rule that we cannot modify a value that is borrowed makes a lot more sense! A more precise definition of this rule in Rust goes like this:
There can either be exactly one mutable borrow or any number of immutable borrows to the same value at the same time.
With this rule (that takes some getting used to) Rust eliminates a whole class of bugs that can happen due to mutating a value that is still borrowed somewhere else.
Summary
Wow, what a chapter. We learned a lot about memory management from a systems programming perspective, coupled with the knowledge of how the C++ and Rust languages treat memory. We learned about the stack and heap, and how the stack works automatically because of the scope rules that both C++ and Rust provide. We saw why the stack alone is not sufficient for writing programs: It is limited in size and has very narrow lifetime rules. We learned about ways to use the heap, which has much broader lifetime rules, but also saw that it is difficult to use the heap correctly. We then combined automatic stack cleanup with using the heap to create types that manage memory for us. We learned about ownership and why we have to care about it whenever we pass values around and create copies. We learned about the difference between copy-semantics and move-semantics. Lastly, we learned about references and borrows and saw that Rust takes special care to imbue borrows with the necessary information to prevent memory issues.
This is perhaps the most dense chapter in this whole book, so clap yourselves on the shoulder that you got through it. In the next chapter, we will apply this knowledge to write really good abstractions that C++ and Rust programmers use in their day-to-day life!
3.4. Smart pointers and reference counting
In the previous section, we learned the tools to push memory management to the next level. We already saw how we can write types that manage memory efficiently for us while providing much more safety compared to full manual memory management. In this section we will learn that there is a whole zoo of types which handle memory management. These types are part of the C++ and Rust standard libraries, and understanding them will help us in writing better systems code. We will cover the following topics:
- Slices
- Pointers to single objects in C++
- A Rust smart pointer for single ownership:
Box<T> - Moving beyond single ownership
- A reference-counting smart pointer in Rust:
Rc<T> - Implementing
Rc<T>in Rust - The limits of reference counting
- Summary
Slices - Pointers to arrays
A fundamental problem with pointers that we stumbled upon in the previous section was that a pointer does not contain enough information to fully describe the memory location it points to. In particular, given a single pointer we have no way of knowing whether this pointer refers to just one instance of a type, or an array:
int main() {
int* ptr = get_ptr();
// If ptr is not null, this should at least be valid:
std::cout << *ptr << std::endl;
// But is this also valid?
std::cout << ptr[1] << std::endl;
return 0;
}
Just from looking at the pointer, no chance to figure it out. So we have to resort to the method documentation of get_ptr(). Which is fine, but not really what we as programmers would want. It would be better if we could write code that makes it obvious how to use it, without looking into the documentation.
We could establish a convention, something like 'Always use references for single instances, and pointers for arrays'. But any convention is fragile and prone to error, so that doesn't sound like a good idea. Instead, why not use a dedicated type for dynamic arrays? We can wrap our pointer inside a type that behaves like an array. What's the defining property of an array? It is a contiguous sequence of memory. To model this with a type, we can either use two pointers - one for the beginning of the array and one for the end - or we use a pointer and a size. The second approach might seem more intuitive, so let's go with that:
#include <iostream>
template<typename T>
struct DynamicArray {
T* start;
size_t size;
};
DynamicArray<int> get_ptr() {
int* arr = new int[42];
return {arr, 42};
}
int main() {
DynamicArray<int> arr = get_ptr();
for(size_t idx = 0; idx < arr.size; ++idx) {
std::cout << arr.start[idx] << std::endl;
}
return 0;
}
This DynamicArray type is missing a lot of syntactic sugar to make it really usable, but this is the main idea: A wrapper around a pointer and a size. In this toy example, it would have been better if we had used std::vector, because the get_ptr() method actually returns an owning pointer to the memory, but we can think of many scenarios where we don't want to own an array and instead only want a view on the array. This is like a reference, but for arrays.
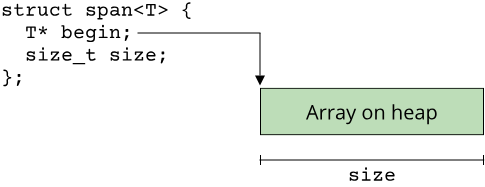
Of course, such types exist already in C++ and Rust. C++ took quite some time to standardize something like that, with C++20 the std::span type has been standardized, as an alternative gsl::span from the Guidelines Support Library can be used. Rust goes a step further and has built-in support for views through slices. Under the hood, slices are also just a pointer and a size, but they are integrated deeply into the Rust language:
fn main() { let numbers: [u32; 4] = [1, 2, 3, 4]; let numbers_slice: &[u32] = &numbers[..]; //[..] syntax takes a slice of the whole array //Slices behave like arrays: They have a len() method and support the [] operator: println!("{}", numbers_slice.len()); println!("{}", numbers_slice[0]); //We can even loop over slices (we will see in a later chapter how this works under the hood): for number in numbers_slice { println!("{}", number); } }
We haven't really talked about strings a lot, but strings are a special type of dynamic array storing charactersOr UTF-8 code points, in the case of Rust strings.. Since strings play a very important role in almost every program, strings typically get some extra types and functions that set them apart from plain arrays or vectors. C++ has a special variant of std::span for strings, called std::basic_string_view, which is already available in C++17. Rust has a special slice type for string slices, called str.
Pointers to single objects in C++
The next step after abstractions for owning and non-owning arrays in dynamic memory is to think about single instances of a type. We will first look at how this is typically done in C++, the Rust way of things is covered in the next section. This section covers the following topics:
- The motivation for putting single objects on the heap
- A first approach for handling instances on the heap
- Dealing with ownership
- A look at the move syntax in C++
Motivation: Why do we want single instances on the heap?
What reason is there to put a single instance onto the heap? For an array, our motivation was clear: We want a dynamic size that we only know at runtime. For a single instance, we know our size - the size of the type - so why use the heap here? Try to first come up with an answer for yourself before reading on:
❓ Question
What reasons are there to put a single instance of a type onto the heap?
💡 Click to show the answer
- The type is too big to fit onto the stack
- The type not copyable, not movable, and has a non-trivial lifetime
- The size of the type is not known
It is easy to come up with an example for the first situation: A type that is too large to fit onto the stack:
struct LargeType {
char ten_mb_of_text[10 * 1024 * 1024];
};
The second example is more tricky. Up until now, we only dealt mostly with types that could be copied and moved. Depending on the notion of 'moving', it is not even clear why a type should not be at least movable. We saw one previous example for a non-copyable type, during our CustomVector implementation before learning about deep copies. At this point, it is hard to come up with a good example of a non-movable type, but there are some in the C++ and Rust standard libraries, such as std::mutex and Pin<T>. Sometimes you also want to create self-referential types, so types that contain a reference to themselves. These types generally should not be movable, because moving them in memory will invalidate the reference.
The last example is interesting: A type whose size is not known at compile-time. Wasn't the whole point of having a strong type system to know the size of all types at compile-time? There are situations where this is not the case, even in a strong type system. This is the whole point of interfaces in many programming languages: To have a piece of code that works with instances whose type is only known at runtime. The concept of subtyping polymorphism works this way, for example when you have classes with virtual methods in C++. If you work with instances of a derived class through its base class, you end up with a type whose size is only known at runtime. Let's look at an example:
#include <iostream>
struct Base {
virtual ~Base() {}
virtual void foo() {
std::cout << "Base" << std::endl;
}
};
struct DerivedA : Base {
explicit DerivedA(int v) : val(v) {}
void foo() override {
std::cout << "DerivedA(" << val << ")" << std::endl;
}
int val;
};
struct DerivedB : Base {
explicit DerivedB(std::string v) : val(v) {}
void foo() override {
std::cout << "DerivedB(" << val << ")" << std::endl;
}
std::string val;
};
int main() {
Base a = DerivedA{42};
Base b = DerivedB{"hello"};
a.foo();
b.foo();
return 0;
}
In this example, we have a base class Base, and two derived classes which store different types and thus have different sizes. We then create an instance of both derived classes and call a virtual method on them...
Output of this example:
Base
Base
...and find out that none of our virtual methods in the subclasses have been called. Somehow, our code did not delegate to the appropriate virtual methods in the subclasses. This is reflected in the assembly code of this example:
; ...
call Base::foo()
; ...
So the C++ compiler saw that we were declaring a value of type Base and were calling a method named foo() on it. It didn't care that our function was declared virtual, because the way we invoked that function was on a value, which is just an ordinary function call. What we want is a virtual function call, and in C++ virtual function calls are only supported if a function is called through a pointer or reference. So let's try that:
int main() {
Base a = DerivedA{42};
Base b = DerivedB{"hello"};
Base& a_ref = a;
Base& b_ref = b;
a_ref.foo();
b_ref.foo();
return 0;
}
Output of this example:
Base
Base
Still the same result?! So what did we do wrong? Well, we commited a cardinal sin in C++: We assigned a value of a derived class to a value of a base class. Recall that all local variables are allocated on the stack. To do so, the compiler has to know the size of the variable to allocate enough memory on the stack. Our variables a and b are both of type Base, so the compiler generates the necessary instructions to allocate memory for two instances of Base. We can use the sizeof operator in C++ to figure out how big one Base instance is, which in this case yields 8 bytes. We then assign instances of DerivedA and DerivedB to these variables. How big are those?
sizeof(DerivedA): 16
sizeof(DerivedB): 40
How does that work, assigning a larger object to a smaller object? In C++, this is done through slicing, and it is not something you typically want. In the statement Base a = DerivedA{42};, we assign a 16-byte object into an 8-byte memory region. To make this fit, the compiler will slice off all the overlapping bytes of the larger object. So all the information that makes our DerivedA type special is gone.
Of course this is a toy example, no one would write code like this, right? Not like this maybe, but how about writing a function that returns an object derived from some base class. Let's say in our example that the function takes a bool parameter, and if this parameter is true, it returns a DerivedA instance, otherwise a DerivedB instance:
Base magic_factory(bool flavor) {
if(flavor) {
return DerivedA{42};
}
return DerivedB{"hello"};
}
int main() {
Base a = magic_factory(true);
Base b = magic_factory(false);
return 0;
}
This is the exact same situation! magic_factory returns an object of type Base, but constructs objects of the (larger) subtypes, so slicing will happen. In order to work correctly, magic_factory has to return a type whose size is unknown at compile-time! Which is why all polymorphic objects in C++ have to be allocated on the heap: Their size can be unknown at compile-time, so we have to use the only type available to use that can refer to a variable-size memory region - a pointer!
So there we have it, the last reason for allocating a single instance of a type on the heap. Just for completeness, here is the correct code for the previous example:
Base* magic_factory(bool flavor) {
if(flavor) {
return new DerivedA{42};
}
return new DerivedB{"hello"};
}
int main() {
Base* a = magic_factory(true);
Base* b = magic_factory(false);
a->foo();
b->foo();
delete a;
delete b;
return 0;
}
Managing single instances on the heap
We can now think about writing a good abstraction that represents a single instance allocated on the heap and manages the memory allocation for us. We already have an abstraction for multiple instances on the heap: Our CustomVector type (or the better std::vector type from the C++ standard library). Let's try to use it:
CustomVector<Base> magic_factory(bool flavor) {
CustomVector<Base> ret;
if(flavor) {
ret.push(DerivedA{42});
} else {
ret.push(DerivedB{"hello"});
}
return ret;
}
int main() {
CustomVector<Base> a = magic_factory(true);
CustomVector<Base> b = magic_factory(false);
a.at(0).foo();
b.at(0).foo();
return 0;
}
Ok, not super nice in terms of usability, with this a.at(0) syntax, but a start. Let's run this to confirm that it works:
Base
Base
Of course, our CustomVector<T> stores multiple instances of a single type known at compile-time. When we call the push() function, slicing happens again, because push() expects a value of type Base and we pass it a value of type DerivedA or DerivedB. So clearly, we need something better that can deal with derived classes.
What is it that we want from our new type? It should be able to hold a single instance of some type T, or any type U that derives from T! Just like CustomVector, we want all dynamic memory allocations to happen automatically, and memory should be cleaned up correctly once the instance of our new type is destroyed. So really what we want is a pointer that is just a bit smarter than a regular pointer:
template<typename T>
struct SmartPtr {
SmartPtr() : ptr(nullptr) {}
explicit SmartPtr(T* dumb_ptr) : ptr(dumb_ptr) {}
~SmartPtr() {
if(ptr) delete ptr;
}
T& get() { return *ptr; }
const T& get() const { return *ptr; }
private:
T* ptr;
};
This SmartPtr type wraps around a regular (dumb) pointer and makes sure that delete is called when the SmartPtr object goes out of scope. It also provides a get() method that returns a reference to the object (though calling it on a SmartPtr that holds nullptr is not a good idea). Note that this type is generic on the parameter T, but stores a pointer to T! The C++ rules allow a pointer of a derived type (U*) to be converted into a pointer of the base type (T*), so we can create a SmartPtr<Base> from a DerivedA* or DerivedB*, which is exactly what we want:
SmartPtr<Base> magic_factory(bool flavor) {
if(flavor) {
return SmartPtr<Base>{ new DerivedA{42} };
}
return SmartPtr<Base>{ new DerivedB{"hello"} };
}
int main() {
SmartPtr<Base> a = magic_factory(true);
SmartPtr<Base> b = magic_factory(false);
a.get().foo();
b.get().foo();
return 0;
}
The only unfortunate thing is that we have to call new DerivedA{...} ourselves in this example. To make this work, we would have to pass a value of some type U that is T or derives from T to the constructor, and then copy or move this value onto the heap. The other option would be to pass all the constructor arguments for the type U to the constructor of SmartPtr and then call new U{args} there. For the first option, we have to introduce a second template type U only for the constructor, and then make sure that this constructor can only get called when U derives from T. Prior to C++20, which introduced concepts for constraining generic types, this is how we would write such a constructor:
template<typename U,
typename = std::enable_if_t<std::is_base_of<T, U>::value>>
explicit SmartPtr(U val) {
ptr = new U{std::move(val)};
}
The std::enable_if_t construct effectively tells the compiler to only compile this templated function if the condition std::is_base_of<U, T> holds, that is if U is derived from T. Within the constructor, we then create a new instance of U on the heap and initialize it with the contents of val. std::move tells the compiler to try and move val into the constructor call of U. If U is not a movable type, it is copied instead.
With C++20 and concepts, we can write this code a bit nicer:
template<typename U>
explicit SmartPtr(U val) requires std::derived_from<U, T> {
ptr = new U{std::move(val)};
}
The downside of this approach is that we potentially create a copy of our val object. It would be nicer if we could construct the instance directly on the heap, without any copies! For this, we have to pass all constructor arguments to make an instance of U to the constructor of SmartPtr. However, there can be arbitrarily many constructor arguments, of arbitrary types. Luckily, C++ supports variadic templates since C++11, which can be used for situations where we have an arbitrary number of template arguments:
template<typename... Args>
explicit SmartPtr(Args... args) {
ptr = new ??? {args...};
}
Now we have the problem that we have to tell the SmartPtr constructor explicitly, for which type we want to call the constructor. Maybe we can add this type as another generic type?
template<typename U, typename... Args>
explicit SmartPtr(Args... args) {
ptr = new U {args...};
}
But now we run into a problem of how to call this code:
SmartPtr<Base> magic_factory(bool flavor) {
if(flavor) {
return SmartPtr<Base>{ 42 };
}
return SmartPtr<Base>{ "hello" };
}
This does not compile because the compiler can't figure out what type to use for the U template parameter. There is not good way to do this in C++, because explicitly specifying template arguments for a constructor is not supported by the language. It is for regular functions, just not for constructors. So we can use a regular function that behaves like a constructor: A factory function:
template<typename T, typename... Args>
SmartPtr<T> smart_new(Args... args) {
auto ptr = new T{args...};
return SmartPtr<T>{ ptr };
}
Which gets called like this:
SmartPtr<Base> magic_factory(bool flavor) {
if(flavor) {
return smart_new<DerivedA>(42);
}
return smart_new<DerivedB>("hello");
}
Which again does not compile :( This time, the compiler is complaining that we are returning an instance of the type SmartPtr<DerivedA> from a function that returns SmartPtr<Base>. These two types are different, and the compiler can't figure out how to convert from one into the other. What we want is the same property that pointers have, namely the ability to go from U* to T*, if U derives from T. This property is called covariance, and we can enable it for out SmartPtr type by adding yet another constructor:
template<typename U> friend struct SmartPtr;
template<typename U>
SmartPtr(SmartPtr<U> other) requires std::derived_from<U, T> {
ptr = other.ptr;
other.ptr = nullptr;
}
In this constructor, we steal the data from another SmartPtr object that is passed in, but this is only allowed if the other SmartPtr points to an instance of a derived type. Since SmartPtr<T> and SmartPtr<U> are different types, we also need a friend declaration so that we can access the private ptr member.
With that, we have a first working version of a type that manages single instances of types on the heap. We called it SmartPtr, because that it the name that such types go by: Smart pointers.
The problem with ownership - again
You know what is coming: Our SmartPtr type is incorrect. Look at this code:
int main() {
SmartPtr<Base> a = magic_factory(true);
{
SmartPtr<Base> b = a;
b.get().foo();
}
a.get().foo();
return 0;
}
Here we create a copy of our heap-allocated object. We never defined a copy constructor, so we get the one that the compiler generates for us, which - as in the example of CustomVector - creates a shallow copy. Now b goes out of scope, calls delete on the underlying pointer, but we still have another pointer to the same object living inside a. When we then dereference a, we access memory that has been freed, leading to undefined behavior.
Again we have two options: Create a deep copy, or disallow copying the SmartPtr type. Let's try the first approach by adding an appropriate copy constructor:
SmartPtr(const SmartPtr<T>& other) {
if(other.ptr) {
ptr = new T{other.get()};
} else {
ptr = nullptr;
}
}
If we run this, we are in for a surprise:
Base
DerivedA(42)
See this line right here: SmartPtr<Base> b = a;? It invokes the copy constructor for SmartPtr<Base>, which calls new Base{other.get()}. But we only store a pointer to Base, the actual type of the heap-allocated object is DerivedA! But the compiler can't know that, because the actual type is only known at runtime! So how would we ever know which copy constructor to call? What a mess...
We could spend some more time trying to find a workaround, but at this point it makes sense to look at the standard library and see what they do. What we have tried to implement with SmartPtr is available since C++11 as std::unique_ptr. For basically the same reasons that we just saw, std::unique_ptr is a non-copyable type! Which makes sense since - as the name implies - this type manages an instance of a type with unique ownership. While we can't copy a type that has unique ownership semantics, we can move it. We already did something like this, in our converting constructor from SmartPtr<U> to SmartPtr<T>: Here we stole the data from the original SmartPtr and moved it into the new SmartPtr. This way, ownership has been transferred and at no point in time were there two owners to the same piece of memory.
A primer on moving in C++
In Rust, moving was implictily done on assignment, in C++ we have to do some extra stuff to enable moving. First, we have to make a type movable by implementing a move constructor and/or move assignment operator:
SmartPtr(SmartPtr<T>&& other) : ptr(other.ptr) {
other.ptr = nullptr;
}
SmartPtr<T>& operator=(SmartPtr<T>&& other) {
std::swap(ptr, other.ptr);
return *this;
}
The move constructor looks has a similar signature to a copy constructor, but instead of taking a const reference (const SmartPtr<T>&), it takes something that looks like a double-reference: SmartPtr<T>&&. The double ampersand is a special piece of syntax introduced in C++11 and is called an rvalue reference. Without going into the nasty details of C++ value-categories, we can think of rvalues as everything that can appear on the right-hand side of an assignment. There are also lvalues, which are things on the left-hand side of an assignment:
int lvalue = 42;
// The variable 'lvalue' is an lvalue, the value '42' in this context is an rvalue
Another definition is that lvalues are things with a name and rvalues are things without a name. How exactly does this help us though? Looking at the concept of moving, remember that moving an instance of a type from location A to location B means effectively stealing the instance from location A. To steal it, we have to make sure that no one can use it anymore. Since the only things that we can use are things with a name, converting a value to an rvalue is what makes moving possible in C++Just to be clear: This is a massive oversimplification of the actual language rules of C++. Since C++ is a very complex language with lots of rules that even experts argue over, we will leave it at this simplification for the sake of this course.. Think of the value 42 in the statement above. It is a temporary value, we can't take an address to this value and thus we can't assign a name of this value. If we were to steal this value, no one would care, because no one can name this value to access it.
Since C++ defines a special type for rvalues, it is possible to write a function that only accepts rvalues, that is to say a function that only accepts values that are temporary and unnamed. This is how the move constructor is detected by the C++ compiler: If the argument is temporary and thus unnamed, it is an rvalue and thus a match for the function signature of the move constructor. If it is a named value, it is no rvalue and thus can't be passed to the move constructor. The following example illustrates this:
#include <iostream>
struct MoveCopy {
MoveCopy() {}
MoveCopy(const MoveCopy&) {
std::cout << "Copy constructor" << std::endl;
}
MoveCopy(MoveCopy&&) {
std::cout << "Move constructor" << std::endl;
}
MoveCopy& operator=(const MoveCopy&) {
std::cout << "Copy assignment" << std::endl;
return *this;
}
MoveCopy& operator=(MoveCopy&&) {
std::cout << "Move assignment" << std::endl;
return *this;
}
};
MoveCopy foo() {
return MoveCopy{};
}
int main() {
MoveCopy lvalue;
// Call the copy constructor, because 'lvalue' has a name and is an lvalue
MoveCopy copy(lvalue);
// Call the copy assignment operator, because 'lvalue' is an lvalue
copy = lvalue;
// Call the move assignment operator, because the expression 'MoveCopy{}' creates a temporary object, which is an rvalue
copy = MoveCopy{};
// Eplicitly calling the move constructor can be done with std::move:
MoveCopy moved{std::move(lvalue)};
return 0;
}
If we want to explicitly move an object that has a name, for example the local variable lvalue in the previous example, we have to convert it to an rvalue. For this conversion, we can use the std::move() function. std::move() is one of those weird C++ things that don't make sense at first. Look at the (simplified) implementation of std::move() in the C++ standard library:
template <class T>
inline typename remove_reference<T>::type&&
move(T&& t)
{
typedef typename remove_reference<T>::type U;
return static_cast<U&&>(t);
}
std::move() is just a type cast! There is zero runtime code being generated when we call std::move(), instead it just takes a type T and converts it into an rvalue reference (T&&). The remove_reference stuff exists so that we can call std::move() with regular references and still get an rvalue reference back.
At the end of the day, we have to accept that this is just how moving an object in C++ works. Perhaps the biggest issue with moving in C++ is that the language does not enforce what happens to the object that was moved. Look at this code:
#include <iostream>
#include <string>
int main() {
std::string str{"hello"};
std::cout << str << std::endl;
std::string other = std::move(str);
// WE STILL HAVE A VARIABLE ('str') TO THE MOVED OBJECT!!
std::cout << "String after moving: '" << str << "'" << std::endl;
return 0;
}
No one prevents us from still using the object that we just moved! What happend with the object that we moved from? The C++ standard is quite vague here, saying that moving 'leave[s] the argument in some valid but otherwise indeterminate state'. So it is something that we as programmers have to be aware of.
A smart pointer in Rust - Box<T>
Rust also has a smart pointer type with unique ownership called Box<T>. Putting a value on the heap can be done through Box<T> in a number of ways:
fn main() { let b1: Box<i32> = Box::new(42); let on_stack: i32 = 43; let b2: Box<i32> = on_stack.into(); let back_on_stack: i32 = *b2; let boxed_array: Box<[i32]> = Box::new([1, 2, 3]); let deep_copied: Box<i32> = b1.clone(); }
What is interesting is that Box<T> allows copying, whereas std::unique_ptr<T> did not allow copying. Rust actually does something smart here: Remember that Rust provides the Clone trait for values that have non-trivial copy operations? Well in Rust we can implement a trait on a type conditionally, like so:
#![allow(unused)] fn main() { impl<T: Clone, A: Allocator + Clone> Clone for Box<T, A> { fn clone(&self) -> Self { //... clone implementation } } }
Ignoring the A generic type for now, this statement implements the Clone trait for Box<T> only if T implements the Clone trait! This is a common pattern in Rust to propagate specific behaviour from a wrapped type (e.g. T) to its wrapper (e.g. Box<T>). Box<T> has a lot of these conditional trait implementations to make Box<T> behave like T in most situations. For example, we can test two instances of Box<T> for equality if T can be tested for equality (which is realized through the Eq trait):
pub fn main() { let b1: Box<i32> = Box::new(42); let b2: Box<i32> = Box::new(42); println!("{}", b1 == b2); }
b1 and b2 are located at different memory addresses, but their values are equal, so b1 == b2 resolves to true.
There is not much more to say about Box<T> at this point, besides that it is the main way of getting stuff on the heap in Rust. Let's move on to something more interesting then!
Moving beyond single-ownership
Up to this point, we have worked exclusively with a single-ownership memory model: Dynamic memory on the heap is owned by a single instance of a type (e.g. Vec<T> or Box<T>). Single ownership is often enough to solve many problems in a good way, and it is fairly easy to reason about. You might have heard of the single responsibility principle, which states that every module/class/function should have just one thing that it is responsible forWhich does not mean that it has to do just one thing. Sometimes to get some reasonable amount work done you have to do multiple things, but those things might still be part of the same overall functionality, so you might consider them a single responsibility. For most programming rules, trying to take them too literaly often defeats the purpose of the rule.. The single ownership memory models is somewhat related to that, as having just one owner of a piece of memory makes it clear whose responsibility this piece of memory is.
There are some exceptions to this rule though, where it is useful or even necessary to have multiple owners of the same piece of memory. At a higher level, shared memory would be such a concept, where two or more processes have access to the same virtual memory page(s), using this memory to communicate with each other. In this case of course we have the operating system to oversee the ownership of the memory, but we can find similar examples for dynamic memory allocations. It is however hard to isolate these examples from the broader context in which they operate, so the following examples might seem significantly more complex at first than the previous examples.
An example of multiple ownership
Consider an application that translates text. The user inputs some text in a text field and a translation process is started. Once the translation has finished, it is displayed in a second text field. To keep the application code clean, it is separated into the UI part and the translation part, maybe in two different classes or Rust modules UI and Translator. It is the job of the UI to react to user input and pass the text that should be translated to the Translator. A translation might take some time, so in order to keep the application responsive, the UI does not want to wait on the Translator. Instead, it frequently will check if the Translator has already finished the translation. As an added feature, the user can cancel a translation request, for example by deleting the text from the text field or overwriting it with some other text that shall be translated instead.
This is an example of an asynchronous communications channel: Two components communicate information with each other without either waiting on the other. In our example, text is communicated between UI and Translator, with the UI sending text in the source language and the Translator eventually sending text in the target language back (or never sending anything back if the request was cancelled).
A first try at implementing multiple ownership in Rust
Let's try to implement something like the UI/Translator system with our new-found Rust knowledge:
struct OngoingTranslation { source_text: String, translated_text: String, is_ready: bool, } impl OngoingTranslation { pub fn new(source_text: String) -> Self { Self {source_text, translated_text: Default::default(), is_ready: false} } } struct UI { outstanding_translations: Vec<Box<OngoingTranslation>>, } impl UI { pub fn new() -> Self { Self { outstanding_translations: vec![], } } pub fn update(&mut self, translator: &mut Translator) { todo!() } fn should_cancel_translation() -> bool { todo!() } } struct Translator {} impl Translator { pub fn update(&mut self) { todo!() } pub fn request_translation(&mut self, text: String) -> Box<OngoingTranslation> { todo!() } } fn main() { let mut translator = Translator{}; let mut ui = UI::new(); loop { ui.update(&mut translator); translator.update(); } }
Here we define our UI and Translator types, and the piece of work that represents an ongoing translation as OngoingTranslation. To simulate a responsive application, both the UI and the Translator specify update() methods which are called in a loop from main. The UI can request a new translation from the Translator, which returns a new OngoingTranslation instance that encapsulates the translation request. Since this request might live for a while, we put it onto the heap using Box<T>. Let's look closer at OngoingTranslation:
#![allow(unused)] fn main() { struct OngoingTranslation { source_text: String, translated_text: String, is_ready: bool, } }
It stores the source_text as a String, which is the text that has to be translated. translated_text is another String which will eventually contain the translated text. Lastly we have the aforementioned is_ready flag. An implementation of the UI update method might look like this:
#![allow(unused)] fn main() { pub fn update(&mut self, translator: &mut Translator) { // Process all translations that are done by printing them to the standard output for translation in &self.outstanding_translations { if translation.is_ready { println!("{} -> {}", translation.source_text, translation.translated_text); } } // Drop everything that has been translated or that should be cancelled. Don't bother with the syntax // for now, think of it as removing all elements in the vector for which 'is_ready' is true self.outstanding_translations = self.outstanding_translations.drain(..).filter(|translation| { !translation.is_ready && !Self::should_cancel_translation() }).collect(); // Create new translation requests self.outstanding_translations.push(translator.request_translation("text".into())); } }
Besides some alien syntax for handling removing elements from the vector, it is pretty straightforward. We use some magic should_cancel_translation() method to check if a translation should be cancelled, it doesn't matter how this method is implemented. Perhaps most interesting is the last line, where we use the Translator to create a new translation request. Let's try to write this method:
#![allow(unused)] fn main() { struct Translator { ongoing_translations: Vec<Box<OngoingTranslation>>, } impl Translator { pub fn request_translation(&mut self, text: String) -> Box<OngoingTranslation> { let translation_request = Box::new(OngoingTranslation { source_text: text, translated_text: "".into(), is_ready: false }); self.ongoing_translations.push(translation_request); translation_request } } }
First, we have to change the Translator type so that it actually stores the OngoingTranslations as well. We use Box<OngoingTranslation> here again, because we want these instances to live on the heap so that we can share them between the Translator and the UI. Then in request_translation(), we create a new OngoingTranslation instance, push it into self.ongoing_translations and return it from the method. Let's build this:
error[E0382]: use of moved value: `translation_request`
--> src/chap3_4.rs:69:9
|
63 | let translation_request = Box::new(OngoingTranslation {
| ------------------- move occurs because `translation_request` has type `Box<OngoingTranslation>`, which does not implement the `Copy` trait
...
68 | self.ongoing_translations.push(translation_request);
| ------------------- value moved here
69 | translation_request
| ^^^^^^^^^^^^^^^^^^^ value used here after move
Ah of course, the push() method takes something by value, so it is moved and then we can't use something after move. We could try to clone() the translation_request, however recall that in Rust, cloning a Box is equal to performing a deep copy. If we did that, than the translation_request instance in self.ongoing_translations and the one we return from the request_translation() method are two different instances! This way, we could never communicate to the UI that the request is done!
Shared mutable references to the rescue?
So maybe the Translator does not have to own the OngoingTranslations? Let's try storing a reference instead:
#![allow(unused)] fn main() { struct Translator<'a> { ongoing_translations: Vec<&'a mut OngoingTranslation>, } impl <'a> Translator<'a> { pub fn request_translation(&'a mut self, text: String) -> Box<OngoingTranslation> { let translation_request = Box::new(OngoingTranslation { source_text: text, translated_text: "".into(), is_ready: false }); self.ongoing_translations.push(translation_request.as_mut()); translation_request } } }
Since we now store references, we have to specify a lifetime for these references. In request_translation(), we tie this lifetime 'a to the lifetime of the &mut self reference, which effectively says: 'This lifetime is equal to the lifetime of the instance that request_translation() was called with.' Which seems fair, the OngoingTranslations probably don't live longer than the Translator itself.
You know the drill: Compile, aaaand...
error[E0623]: lifetime mismatch
--> src/chap3_4.rs:39:55
|
25 | pub fn update(&mut self, translator: &mut Translator) {
| ---------------
| |
| these two types are declared with different lifetimes...
...
39 | self.outstanding_translations.push(translator.request_translation("text".into()));
| ^^^^^^^^^^^^^^^^^^^ ...but data from `translator` flows into `translator` here
What is going on here? This error message is a lot harder to read than the previous error messages that we got. Clearly, some lifetimes are different to what the Rust borrow checker is expecting, but it is not clear where exactly. The error message says that this statement right here: &mut Translator has two types that have different lifetimes. One is the mutable borrow, which has an anonymous lifetime assigned to it, and the second type is the Translator type itself. Recall that we changed the signature from Translator to Translator<'a> at the type definition. Rust has some special rules for lifetime elision, which means that sometimes it is valid to not specify lifetimes explicitly, if the compiler can figure out reasonable default parameters. This is what happened here: We didn't specify the lifetime of the Translator type, and the compiler chose an appropriate lifetime for us. It just wasn't the right lifetime! Recall that we specified that the request_translation() method is valid for the lifetime called 'a of the instance that it is called on. This instance is the mutable borrow translator: &mut Translator in the function signature of update(). Without explicitly stating that this is the same lifetime as the one of the Translator type, the compiler is free to choose two different lifetimes, for example like this:
#![allow(unused)] fn main() { pub fn update<'a, 'b>(&mut self, translator: &'a mut Translator<'b>) { /*...*/ } }
Inside request_translation(), we then try to convert a mutable borrow that is valid for lifetime 'a to one that is valid for lifetime 'b, but 'a and 'b are unrelated, so the borrow checker complains. We can fix this by using the same lifetime in both places:
#![allow(unused)] fn main() { pub fn update<'a>(&mut self, translator: &'a mut Translator<'a>) { /*...*/ } }
Now we get a lot of new errors :( Let's look at just one error:
error[E0597]: `translation_request` does not live long enough
--> src/chap3_4.rs:69:40
|
52 | impl <'a> Translator<'a> {
| -- lifetime `'a` defined here
...
69 | self.ongoing_translations.push(translation_request.as_mut());
| -------------------------------^^^^^^^^^^^^^^^^^^^----------
| | |
| | borrowed value does not live long enough
| argument requires that `translation_request` is borrowed for `'a`
70 | translation_request
71 | }
| - `translation_request` dropped here while still borrowed
This happens inside the request_translation() method at the following line:
#![allow(unused)] fn main() { self.ongoing_translations.push(translation_request.as_mut()); }
Here, we get a mutable borrow of the new translation_request using the as_mut() method of the Box<T> type. We then try to push this mutable borrow into self.ongoing_translations, which expects &'a mut OngoingTranslation as type, so a mutable borrow that lives as long as the lifetime 'a. If we look at the signature of the as_mut() method, we see that it comes from a trait implementation like this:
#![allow(unused)] fn main() { pub trait AsMut<T: ?Sized> { fn as_mut(&mut self) -> &mut T; } }
At first this might look weird: A function returning a borrow without explicit lifetime specifiers. This is where the lifetime elision rules kick in again. In situations where you have a function that takes a borrow and returns a borrow, the Rust compiler assumes that the two borrows share a lifetime, so an alternate signature of this function would be:
#![allow(unused)] fn main() { fn as_mut<'a>(&'a mut self) -> &'a mut T; }
So in this line right here:
#![allow(unused)] fn main() { self.ongoing_translations.push(translation_request.as_mut()); }
We get a mutable borrow of the contents of translation_request that lives as long as the variable translation_request. Which is a local variable inside the request_translation() function, so of course it does not live long enough to match the lifetime of the Translator type.
What can we do here? At this point, instead of trying more and more convoluted things, we will directly go to the heart of the problem: We tried to use Box<T>, a single ownership container, to model a multiple ownership situation. Think about it: Both UI and Translator are full owners of an OngoingTranslation instance. Either the Translator finishes first, in which case it is the job of the UI to clean up the memory, or the UI aborts an ongoing request, which might still be in use by the Translator, requiring the Translator to clean up the memory. This situation is unresolvable at compile-time! So we need a type that effectively models this multiple ownership situation. Enter Rc<T>!
Rc<T> - A smart pointer supporting multiple ownership in Rust
Rust has a neat type called Rc<T>, which is similar to Box<T> but supports multiple owners at the same time. Compared to Box<T>, Rc<T> can be cloned without having to do a deep copy. All clones of an Rc<T> still point to the same object, which is exactly what we want. Even better, once the last Rc<T> goes out of scope, it automatically cleans up the heap allocation, just as Box<T> would. Since the final owner typically cannot be determined at compile-time, Rc<T> requires some form of runtime tracking of the number of owners. As a consequence, Rc<T> has a larger runtime overhead than Box<T>For most practical purposes, we can consider both Box<T> and std::unique_ptr<T> to have no runtime overhead compared to a hand-written version that does the same. There are some rare situations though where the generated code is not as optimal..
A first try at implementing a multiple ownership smart pointer (using C++)
How can we implement something that behaves like Rc<T>? We will try first in C++, because it has less strict rules, and then look at how we could do it in Rust.
struct RefCount {
size_t count;
};
template<typename T>
struct Rc {
Rc() : obj(nullptr), ref_count(nullptr) {}
~Rc() {
if(!ref_count) return;
ref_count->count--;
if(ref_count->count == 0) {
delete obj;
delete ref_count;
}
}
explicit Rc(T obj) {
this->obj = new T{std::move(obj)};
ref_count = new RefCount{};
ref_count->count = 1;
}
Rc(const Rc& other) {}
Rc(Rc&& other) {}
Rc& operator=(const Rc& other) {}
Rc& operator=(Rc&& other) {}
const T& get() const {
return *obj;
}
private:
T* obj;
RefCount* ref_count;
};
Our Rc type consists of two pieces of heap-allocated memory: The actual instance of type T and a reference count, which stores the number of references that exist to that instance. This already resolves the mystery of the name Rc, which is a shorthand for reference-counted. The constructor takes an instance of T and moves it onto the heap, creating a new RefCount on the heap and initializing its reference count with 1. In the destructor, the reference count is decremented by one and if it is zero then, we know that we just destroyed the last reference to the instance of T, so we delete both the instance and the RefCount. We also specify a default constructor which sets everything to nullptr.
Now to implement the copy and move constructors and assignment operators:
Rc(const Rc& other) : obj(other.obj), ref_count(other.ref_count) {
if(ref_count) {
ref_count->count++;
}
}
Rc(Rc&& other) : obj(other.obj), ref_count(other.ref_count) {
other.obj = nullptr;
other.ref_count = nullptr;
}
The copy constructor copies just the raw pointers of the instance and the reference count block, and if the reference count is not nullptr increments the reference count by one. This is a shallow copy because we just copied the pointers! The move constructor is even simpler: It moves the pointers from the old Rc to the new one. The reference count is not changed, because no new reference has been created.
Rc& operator=(const Rc& other) {
if(ref_count) {
ref_count->count--;
if(ref_count->count == 0) {
delete obj;
delete ref_count;
}
}
obj = other.obj;
ref_count = other.ref_count;
if(ref_count) {
ref_count->count++;
}
return *this;
}
Rc& operator=(Rc&& other) {
if(ref_count) {
ref_count->count--;
if(ref_count->count == 0) {
delete obj;
delete ref_count;
}
}
obj = other.obj;
ref_count = other.ref_count;
other.obj = nullptr;
other.ref_count = nullptr;
return *this;
}
The copy constructor is a bit more involved. It decrements the reference count of the current object and potentially deletes it if this was the last reference. Then, it copies the pointers of the other Rc and potentially increases the reference count, which now refers to the instance of the other Rc. The move constructor is similar, but instead of incrementing the new reference count, it just steals the pointers from the other Rc. The following example shows how to use this Rc type:
int main() {
Rc<int> rc1{42};
std::cout << rc1.get() << std::endl;
Rc<int> rc2 = rc1;
rc1 = {};
std::cout << rc2.get() << std::endl;
return 0;
}
The whole process that we implemented here is called reference counting, because that is exactly what it does: We count the number of active references to a piece of memory, and when this count goes to zero, we automatically release the memory. To do so requires two memory allocations, one for the object to track and one for the reference count. The reference count has to live on the heap as well, because it is also shared between all instances of the Rc type which point to the same instance of T. Since this reference count gets updated at runtime, reference counting has a larger performance overhead than using the single-ownership containers. It also means we lose a bit of determinism regarding when exactly the object gets destroyed. With Box<T>/std::unique_ptr<T>, we knew at compile-time where the object gets destroyed. With Rc, this depends on the runtime situation. If our type T does some non-trivial work in its destructor that takes some time, with Rc it is harder to figure out when exactly this work happens.
Reference counting details
One thing that is a little bothersome is that reference counting requires two memory allocations instead of one. The problem is that the type T and the type that stores the reference count (RefCount in our code) are two distinct types. We could make the type T should store its own reference count and then change our code to something like this:
template<typename T>
struct IntrusiveRc {
IntrusiveRc() : obj(nullptr) {}
~IntrusiveRc() {
if(!obj) return;
obj->dec_ref_count();
if(obj->get_ref_count() == 0) {
delete obj;
}
}
explicit IntrusiveRc(T obj) {
this->obj = new T{std::move(obj)};
this->obj->set_ref_count(1);
}
/* Other methods... */
private:
T* obj;
};
We call this process intrusive reference counting, because the information about the reference count intrudes the type T. As a consequence, our IntrusiveRc<T> type can only be used with specific types T which support the necessary operations (set_ref_count(), get_ref_count() etc.). The benefit is that we only require a single dynamic memory allocation, and the code can actually be faster, because the reference count will typically be stored inside the memory of the managed instance! This makes intrusive reference counting potentially faster than non-intrusive reference counting (which is what we used for our Rc<T> type).
There is a third option: We can store the reference count and the instance of T next to each other in memory, without one knowing about the other! Let's try this:
template<typename T>
struct RefCountAndT {
RefCountAndT(T obj) : ref_count(1), obj(std::move(obj)) {}
size_t ref_count;
T obj;
};
template<typename T>
struct PackedRc {
PackedRc() : ref_count_and_obj(nullptr) {}
~PackedRc() {
if(!ref_count_and_obj) return;
ref_count_and_obj->ref_count--;
if(ref_count_and_obj->ref_count == 0) {
delete ref_count_and_obj;
}
}
explicit PackedRc(T obj) {
ref_count_and_obj = new RefCountAndT{std::move(obj)};
}
/* Other methods... */
private:
RefCountAndT<T>* ref_count_and_obj;
};
Here we introduce a new type RefCountAndT, which packs the reference count and an instance of T into the same memory region. This way, we can allocate both the reference count and the instance of T next to each other in memory using a single allocation. This is a 'best-of-both-worlds' approach to reference counting, and it is basically what the standard library implementations of Rc<T> in Rust and its C++-equivalent std::shared_ptr<T> use internally. The following image visualizes the three types of reference counting:
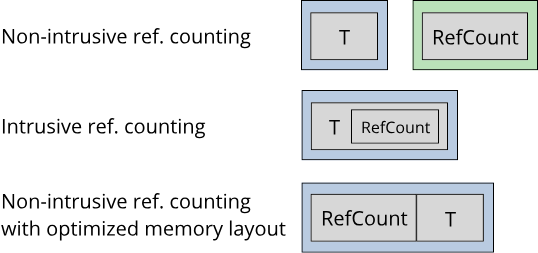
Implementing Rc<T> in Rust
We saw how to implement a reference counted smart pointer in C++, now we would like to do the same in Rust. Immediately, we stumble upon a problem: Which type do we use for the heap-allocated instance of T and the reference count? We can't use Box<T>, because the whole point of our new type is to have multiple owners of the same piece of memory. So we need something like an ownerless type that points to heap-allocated memory. Does Rust have something like this?
In C++, we use raw pointers for this, but the whole point of Rusts memory safety guarantees was to get rid of raw pointers. Still, Rust is a systems programming language, and any good systems programming language should be able to interface directly with code written in C. To do so, it has to support the same types that C does, specifically raw unchecked pointers. Enter unsafe Rust!
unsafe Rust
Instead of going into a whole lot of detail on what exactly unsafe Rust is, at this point it makes sense to simply look into the Rust documentation. It motivates the need for unsafe code and explains exactly how it works. Please take some time to read the section on unsafe Rust before continuing here!
An Rc<T> implementation in Rust using unsafe code
Part of unsafe Rust is the support for raw pointers. A raw pointer in Rust has no lifetime checking associated with it, which means it is a perfect candidate for the internal type of our Rc<T> implementation:
#![allow(unused)] fn main() { struct RefCountAndT<T> { ref_count: usize, obj: T, } struct Rc<T> { ref_count_and_t: *mut RefCountAndT<T>, } impl <T> Rc<T> { pub fn new(obj: T) -> Self { todo!() } pub fn get(&self) -> &T { todo!() } } }
In this rough outline of our Rc<T> type, we use a combined reference count and instance block RefCountAndT, just as in the last C++ example. We then store a raw pointer to this structure inside our Rc<T> type. Raw pointers in unsafe Rust come in two flavors: Immutable ones (*const T) and mutable ones (*mut T). Since we want to mutate the reference count eventually, we use a mutable pointer here! Our simple interface for Rc<T> currently only supports constructing a new Rc<T> from a value, and retrieving this value. Here is how we would implement the two functions:
#![allow(unused)] fn main() { pub fn new(obj: T) -> Self { //Move 'obj' onto the heap into a new RefCountAndT instance. We can use Box for this, just temporarily! let ref_count_and_t = Box::new(RefCountAndT { ref_count: 1, obj, }); //Now we *leak* the box to obtain the raw pointer! Box::leak returns a mutable *borrow*... let leaked : &mut RefCountAndT<T> = Box::leak(ref_count_and_t); //...but we want a *pointer*. Luckily, we can cast one into the other. This does NOT require unsafe code, //only *using* the pointer is unsafe (because it can be null)! let leaked_ptr : *mut RefCountAndT<T> = leaked; Self { ref_count_and_t: leaked_ptr, } } }
We make use of the Box<T> type to perform the heap allocation in a safe way. Box<T> provides a neat method called leak(), which gives us access to the underlying memory block without deallocating it. We can convert the result of leak() into a raw pointer and store this pointer inside the new Rc<T> instance.
Accessing the instance works like this:
#![allow(unused)] fn main() { pub fn get(&self) -> &T { unsafe { &self.ref_count_and_t.as_ref().unwrap().obj } } }
Dereferencing a raw pointer is unsafe, so we wrap the body of get() in an unsafe block. Raw pointers in Rust have a method as_ref() for obtaining a borrow to the underlying instance. The pointer might be null, so as_ref() can either return a valid borrow or nothing. We know that it will never return nothing, so we can bypass any checks using the unwrap() callas_ref() returns a special type called Option<T>, which is a fancy way of handling things that can either be something or nothing. It is null on steroids. We will learn more about Option<T> in chapter 4.. This gives us access to our RefCountAndT instance, from which we access obj and return a borrow to it.
At this point, our Rc<T> is still incomplete, because it never releases the allocated memory. We need something like a destructor for our type. In Rust, the equivalent to a destructor is the Drop trait, which provides a method that gets called whenever an instance of the associated type goes out of scope. With Drop, we can implement the cleanup of our memory!
#![allow(unused)] fn main() { impl <T> Drop for Rc<T> { fn drop(&mut self) { unsafe { let ref_count_and_t = self.ref_count_and_t.as_mut().unwrap(); ref_count_and_t.ref_count -= 1; if ref_count_and_t.ref_count == 0 { let _as_box = Box::from_raw(self.ref_count_and_t); } //_as_box goes out of scope here, deallocating the memory of the `RefCountAndT` block } } } }
The code should look familiar: We obtain a mutable borrow to the RefCountAndT block, decrement the reference count, and if it reaches zero, we release the memory. Here, we use a small trick: We obtained our dynamic memory from a Box, so we can now put it back into a new Box, which we then let go out of scope, causing the Box to clean up the memory.
Here is another helpful trait that we can implement to make our Rc<T> type more usable: Deref:
#![allow(unused)] fn main() { impl <T> Deref for Rc<T> { type Target = T; fn deref(&self) -> &Self::Target { self.get() } } }
Deref enables automatic dereferencing from Rc<T> to &T, which allows us to call methods of T directly on an Rc<T>:
struct Test {} impl Test { pub fn foo(&self) { println!("Test -> foo"); } } pub fn main() { let rc1 = Rc::new(Test{}); rc1.foo(); }
Before moving on, here is an exercise for you:
Exercise 3.4: Implement the Clone trait for the Rc<T> type.
The problem with mutability and Rc<T>
Until now, our Rc<T> type only supported immutable access to the underlying instance of T. We would really like to mutate our values however! So let's implement this:
#![allow(unused)] fn main() { impl <T> Rc<T> { //... pub fn get_mut(&mut self) -> &mut T { unsafe { &mut self.ref_count_and_t.as_mut().unwrap().obj } } } }
Very simple, basically the same as get(). Look what happens if we use this though:
pub fn main() { let mut rc1 = Rc::new(Test{}); let mut rc2 = rc1.clone(); let mut1 : &mut Test = rc1.get_mut(); let mut2 : &mut Test = rc2.get_mut(); mut1.foo(); mut2.foo(); }
This example compiles and runs, even though we have two mutable borrows to the same instance! By the Rust borrow checking rules, this should not be allowed, yet here we are. The reason why this works is because we used unsafe code to bypass all borrow checking rules. Through unsafe, there is no way for the borrow checker to know that rc1 and rc2 refer to the same instance in memory, and that consequently mut1 and mut2 point to the same instance. While this code works, it is wrong! We bypassed the Rust rules and now we don't have any safety anymore when using this Rc<T> type.
Let's move to the Rc<T> type of the Rust standard library to see how we can do better! To distinguish between our Rc<T> implementation and the one from the Rust standard library, we will write the latter with its full path: std::rc::Rc<T>.
pub fn main() { let mut rc1 = std::rc::Rc::new(Test{}); let mut rc2 = rc1.clone(); let mut1 = rc1.get_mut(); let mut2 = rc2.get_mut(); mut1.foo(); mut2.foo(); }
If we just replace our Rc<T> by std::rc::Rc<T>, our code will stop to compile because std::rc::Rc<T> does not have a get_mut() method. Well, it does, just not one that you can call using the regular function call syntax. We can call std::rc::Rc::get_mut(&mut rc1) instead:
pub fn main() { let mut rc1 = std::rc::Rc::new(Test{}); let mut rc2 = rc1.clone(); let mut1 = std::rc::Rc::get_mut(&mut rc1).unwrap(); let mut2 = std::rc::Rc::get_mut(&mut rc2).unwrap(); mut1.foo(); mut2.foo(); }
std::rc::Rc::get_mut() returns again one of these Option things, so we can just unwrap() them again like last time, right?
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value'
Seems not to be the case? A quick look into the documentation of std::rc::Rc::get_mut() tells us the following:
Returns a mutable reference into the given Rc, if there are no other Rc or Weak pointers to the same allocation.
Returns None otherwise, because it is not safe to mutate a shared value.
The critical point is the second line: It is not safe to mutate a shared value. That's the issue we had before, and the standard library implementation of Rc<T> enforces this! The problem with this approach is that it is too strict. It prevents us from ever mutating the value behind an Rc<T>, as long as there are more than one Rc<T> instances pointing to this value. However, the other Rc<T>s might be perfectly harmless and don't do anything with the underlying value. So it might be fine to mutate the value, if we just knew that no one else is currently holding a borrow to this value.
Notice how this is very similar to what Rc<T> itself does? But instead of tracking how many owners there are for a value, we want to track how many borrows there are to the value. So we need something like reference counting, but for Rust borrows. Luckily, the Rust standard library has something for us: Cell<T> and RefCell<T>. To understand these types, we have to understand two concepts first: Inherited mutability and interior mutability.
Inherited vs. interior mutability
The concepts of inherited mutability and interior mutability all deal with how mutability (or immutability) propagates to nested types. Inherited mutability says that the nested types inherit their mutability status from the parent type:
struct Nested { a: i32, b: i32, } pub fn main() { let nested = Nested { a: 42, b: 43 }; nested.a = 23; }
In this example, the variable nested is immutable by default (because we wrote let instead of let mut). This immutability means that we can't assign something else to the nested variable, but it also means that we can't assign something to the nested fields of the Nested type! The mutability is inherited in this case.
The opposite of inherited mutability is interior mutability, which we often see in C++ when using pointers:
struct Nested {
int a;
int* b;
};
int main() {
int local_var = 43;
const Nested nested = Nested {
42,
&local_var
};
*nested.b = 23;
return 0;
}
Here, our Nested type contains a pointer, which is a type with interior mutability. Even though the nested variable is declared const, we can assign through the pointer b to manipulate local_var. Since interior mutability bypasses the mutability status of the outer type, it can be a bit dangerous since it potentially hides mutation. For the Rc<T> example however, it is just what we need!
Cell<T> and RefCell<T>
Both the Cell<T> and the RefCell<T> types can be use to introduce interior mutability to a type in Rust. Cell<T> works by replacing the underlying value using moves, whereas RefCell<T> provides references/borrows to the underlying value. If you want the nitty-gritty details of how exactly this is achieved in Rust, check out the documentation of UnsafeCell<T>, which is the underlying type that makes both Cell<T> and RefCell<T> possible. For us, all that matters is how we use these types. Let's expand our previous example a bit to illustrate the effects of mutability through an Rc<T>:
struct Test { text: String, } impl Test { pub fn foo(&self) { println!("Test -> {}", self.text); } } pub fn main() { let mut rc1 = std::rc::Rc::new(Test{ text: "hello".into() }); let mut rc2 = rc1.clone(); { let mut1 = std::rc::Rc::get_mut(&mut rc1).unwrap(); mut1.foo(); } { let mut2 = std::rc::Rc::get_mut(&mut rc2).unwrap(); mut2.foo(); } }
This is mostly what we were left with before, with some small additions. The Test type actually contains a value that we want to modify, and we slightly changed the order of our Rc::get_mut() calls. This order is important, because it is perfectly safe! We get the first borrow, do something with it, and then get the second borrow and do something with that. Potentially, this should work, because at no point in time do we have two mutable borrows to the same value, since we did our borrowing inside of two scopes! Still, this will give an error, because Rc::get_mut() checks for the number of Rcs that exist, not the number of borrows.
We can now use the RefCell<T> type, which allows us to mutate the underlying value through a regular borrow (&T) instead of a mutable borrow:
pub fn main() { let rc1 = std::rc::Rc::new(std::cell::RefCell::new(Test{ text: "hello".into() })); let rc2 = rc1.clone(); { let mut mut1 = rc1.borrow_mut(); mut1.text = "mutation 1".into(); mut1.foo(); } { let mut mut2 = rc2.borrow_mut(); mut2.text = "mutation 2".into(); mut2.foo(); } }
RefCell<T> gives us a nice borrow_mut() method that we can use to obtain a mutable borrow to the value T. We can use this for mutation and everything works just as we would expect, giving the desired output:
Test -> mutation 1
Test -> mutation 2
Note that the type returned from borrow_mut() is not &mut T, but instead a special wrapper type called RefMut<T> that keeps track of the mutable borrow. With this type, RefCell<T> can guarantee that there will never be more than one mutable borrow of the same value active at the same time (because this is invalid under the borrow checking rules of Rust)! So if we had dropped the local scopes from our example, we would have gotten an error like this: thread 'main' panicked at 'already borrowed: BorrowMutError'. It is now our responsibility as developers to make sure that we don't accidentally create two mutable borrows to the same value, but even if we do: Rust is there to tell us what went wrong, just not at compile time because we gave up on those guarantees.
The limits of reference counting - Circular datastructures
Reference counting is quite powerful, but it also has its limits. The most well-known limitation is that it can't deal well with circular references. Circular references occur every time where two (or more) values hold references to each other, either directly or indirectly. Here is a small example of a circular reference:
use std::rc::Rc; use std::cell::RefCell; struct A { ref_to_b: Option<Rc<RefCell<B>>>, } impl Drop for A { fn drop(&mut self) { println!("A was cleaned up"); } } struct B { ref_to_a: Option<Rc<RefCell<A>>>, } impl Drop for B { fn drop(&mut self) { println!("B was cleaned up"); } } pub fn main() { let mut a = Rc::new(RefCell::new(A { ref_to_b: None, })); let mut b = Rc::new(RefCell::new(B { ref_to_a: Some(a.clone()) })); a.borrow_mut().ref_to_b = Some(b.clone()); }
It is a bit hard to set up circular references in Rust, but with Rc<RefCell<T>> we can get the job done and end up with two types A and B that point to instances of each other. This example produces a memory leak! Both references hold on to each other, so neither can be cleaned up before the other. This leaves the whole system in a state where a waits on b to release its shared reference to a, and b waits on a to release its shared reference on b. We can manually break this cycle:
pub fn main() { let mut a = Rc::new(RefCell::new(A { ref_to_b: None, })); let mut b = Rc::new(RefCell::new(B { ref_to_a: Some(a.clone()) })); a.borrow_mut().ref_to_b = Some(b.clone()); //We have to manually break the cycle! b.borrow_mut().ref_to_a = None; }
From an ownership-perspective, such a circular reference situation means: A owns B, but B owns A, so A is its own owner. So A only gets cleaned up once A gets cleaned up, which of course can't happen.
Besides manually breaking these cycles, the way to resolve this is by introducing a second reference counting type called a weak pointer. A weak pointer is like a shared pointer (e.g. Rc<T>), but it does not affect the reference count. As such, a weak pointer might be alive while the corresponding Rcs have all been destroyed. To prevent the weak pointer to point into invalid memory, it has dedicated methods that try to obtain a reference to the pointed-to value but can fail if the underlying value has already been destroyed.
Adding weak pointers to the equation requires some small changes to the implementation of the corresponding smart pointers. In particular, the reference count has to stay on the heap until either the last smart pointer or the last weak pointer goes out of scope, whichever comes latest. For that reason, two reference counts are typically used, one for the number of shared references (Rc<T> instances) pointing to the value, and one for the number of weak pointers pointing to the value:
#![allow(unused)] fn main() { /// An adjusted reference count block that supports weak pointers struct RefCountAndT<T> { strong_references: usize, weak_references: usize, obj: T, } }
With the adjusted reference count block (sometimes called a control block), we can implement a weak pointer:
#![allow(unused)] fn main() { struct WeakPtr<T> { control_block: *mut RefCountAndT<T>, } impl <T> WeakPtr<T> { pub fn to_rc(&self) -> Option<Rc<T>> { todo!() } } impl <T> Drop for WeakPtr<T> { fn drop(&mut self) { todo!() } } impl <T> Rc<T> { pub fn as_weak(&self) -> WeakPtr<T> { todo!() } } }
Dereferencing the weak pointer directly is not possible, so instead we provide a method to_rc(), which tries to convert the weak pointer into a shared pointer (Rc<T>). This method either returns the Rc<T>, if the weak pointer still points to valid memory, or it returns a special None value, indicating that the weak pointer is not valid anymore. We also implement Drop of course, as well as a method on Rc<T> to obtain a weak pointer from the Rc. Let's look at the Drop implementation first:
#![allow(unused)] fn main() { impl <T> Drop for WeakPtr<T> { fn drop(&mut self) { unsafe { let ref_count_and_t = self.control_block.as_mut().unwrap(); ref_count_and_t.weak_references -= 1; if ref_count_and_t.has_no_remaining_references() { let _as_box = Box::from_raw(self.control_block); } } } } }
Here we decrement the number of weak references and then check if the reference count for both strong and weak references is zero (using a convencience method has_no_remaining_references()). If that is the case, we delete the reference count block together with the value of T.
Let's do the conversion from WeakPtr<T> to Rc<T> next:
#![allow(unused)] fn main() { impl <T> WeakPtr<T> { pub fn to_rc(&self) -> Option<Rc<T>> { unsafe { let ref_count_and_t = self.control_block.as_mut().unwrap(); if ref_count_and_t.strong_references == 0 { return None; } ref_count_and_t.strong_references += 1; Some(Rc::<T> { ref_count_and_t, }) } } } }
Here we can look at the strong reference count to figure out if the conversion is valid. If there are no strong references, we can't convert to Rc<T>, but if there are, we increment the number of strong references and create a new Rc<T> directly from the control block. Writing Some(...) is just special syntax with the Option<T> type that indicates that there is a value, as opposed to None which indicates no value.
The conversion from Rc<T> to WeakPtr<T> is quite similar:
#![allow(unused)] fn main() { impl <T> Rc<T> { pub fn as_weak(&self) -> WeakPtr<T> { unsafe { let ref_count_and_t = self.ref_count_and_t.as_mut().unwrap(); ref_count_and_t.weak_references += 1; } WeakPtr::<T> { control_block: self.ref_count_and_t, } } } }
Here, we know that this conversion is always valid, so we don't need the Option<T> type. We increment the number of weak references and create a new WeakPtr<T> from the control block.
As a final step, we have to adjust the Drop implementation of Rc<T>, because it must not destroy the control block if there are still weak references. It must however destroy the instance of T as soon as the last Rc<T> goes out of scope. This is a bit tricky, because the instance is stored within the control block:
#![allow(unused)] fn main() { impl <T> Drop for Rc<T> { fn drop(&mut self) { unsafe { let ref_count_and_t = self.ref_count_and_t.as_mut().unwrap(); ref_count_and_t.strong_references -= 1; // If this was the last strong reference, we have to drop the value of `T`! This is the // guarantee of a smart pointer: Once the last smart pointer goes out of scope, the pointed-to // instance is destroyed. It's a bit tricky to do so, because our value is part of the control // block... if ref_count_and_t.has_no_strong_references() { // We have to use this 'drop_in_place' method, which effectively calls the destructor of the value // but does not deallocate its memory std::ptr::drop_in_place(&mut ref_count_and_t.obj); } // Only drop the control block if there are neither strong nor weak references! if ref_count_and_t.has_no_remaining_references() { let _as_box = Box::from_raw(self.ref_count_and_t); } } } } }
We can then use our WeakPtr<T> type like so:
pub fn main() { let strong1 = Rc::new(42); let weak1 = strong1.as_weak(); println!("Strong: {}", strong1.get()); println!("Weak: {}", weak1.to_rc().unwrap().get()); drop(strong1); println!("Weak pointer still valid after last Rc<T> dropped? {}", weak1.to_rc().is_some()); }
The Rust standard library implementation is called Weak<T> and is quite similar to our WeakPtr<T> type. We can use it to break cycles in circular reference situations:
use std::rc::Rc; use std::rc::Weak; use std::cell::RefCell; struct A { ref_to_b: Option<Weak<RefCell<B>>>, } impl Drop for A { fn drop(&mut self) { println!("A was cleaned up"); } } struct B { ref_to_a: Option<Rc<RefCell<A>>>, } impl Drop for B { fn drop(&mut self) { println!("B was cleaned up"); } } pub fn main() { let mut a = Rc::new(RefCell::new(A { ref_to_b: None, })); let mut b = Rc::new(RefCell::new(B { ref_to_a: Some(a.clone()) })); a.borrow_mut().ref_to_b = Some(Rc::downgrade(&b)); }
As a closing remark, similar types are also available in C++: std::shared_ptr<T> is the equivalent of Rc<T> and std::weak_ptr<T> is the equivalent of Weak<T>.
Summary
This was another long chapter. We learned about all the smart pointer types that modern systems programming languages offer to make memory management simpler, while still retaining performance comparable to a hand-rolled implementation. The main types are slices, smart pointers (both single-ownership and multiple-ownership) and weak pointers. As a cheat sheet, here is an overview of the related types in both C++ and Rust, and what they are used for:
| Memory-Model | Rust Type(s) | C++ Type(s) | Low-level equivalent |
|---|---|---|---|
| Single value on heap/stack, borrowed | &T and &mut T | const T& and T& | T* |
| Single value on heap, single owner | Box<T> | std::unique_ptr<T> | T* |
| Single value on heap, multiple owners | Rc<T> and Weak<T>, potentially with Cell<T> or RefCell<T> | std::shared_ptr<T> and std::weak_ptr<T> | T* |
| Multiple adjacent values on heap/stack, borrowed | [T] in general and str for Strings | std::span<T> in general and std::basic_string_view<T> for Strings | T* + size_t length; |
| Multiple adjacent values on heap, single owner | Vec<T> | std::vector<T> | T* + size_t length; |
Multiple adjacent values on heap, multiple ownersEach owner owns all the values, because the underlying memory region is obtained with a single call to e.g. malloc(). | Rc<Vec<T>> | std::shared_ptr<std::vector<T>> | T* + size_t length; |
A first look at unsafe Rust
In this chapter, we will dive deeper into some of the container implementations from the Rust standard library, in particular Vec<T>. Whereas in previous chapters we ignored the hard questions such as "How do we work with uninitialized memory in Rust?", this chapter will explore them in their gory details by focusing on a advanced feature called unsafe: A subset of Rust without many of the guardrails that make Rust code memory-safe.
This chapter explores:
- The motivation for
unsafeRust based on the example of uninitialized memory - Interfacing with C functions
- A case study on
unsafecode using theheaplesscrate
Motivation for unsafe Rust: Uninitialized memory
In this chapter, you will learn about the motivation behind the unsafe feature of Rust using the concept of uninitialized memory, something that is very familiar to C programmers. It is not the only motivation for unsafe Rust, in the next chapter we will talk about interfacing with C functions which are unsafe by default, but it fits nicely within the context of this book chapter about the role of memory in systems programming. You will learn about the nitty-gritty details of how to implement the Vec<T> type, one of the most important container types in the Rust standard library, and learn why unsafe is required to implement an efficient Vec<T>.
unsafe Rust: When safety is not an option
First and foremost, unsafe is a keyword in Rust. It applies to functions as well as to scopes:
#![allow(unused)] fn main() { unsafe fn foo() { // Do lots of unsafe things here } fn bar() { let data = 42; // Do something unsafe here: unsafe { // ? } } }
When we use the unsafe keyword, we tell the compiler: "Disable many of the typical safety features while checking the following code". What safety features? Here is a (non-exhaustive) list:
- Allow calling other functions marked as
unsafe - Allow the usage of raw pointers, which have no lifetimes attached to them
- Allow accessing and mutating
static mutvariables - Allow interfacing with externally linked C functions (which are
unsafeby default)
Pointers are perhaps the biggest feature of unsafe Rust. They are a deliberate step back from the borrows+lifetimes type checking system that we spent so much time learning about. There are good reasons to use them, as we will see shortly, and their syntax is similar to what you might be used to from C and C++. Because raw pointers allow memory-unsafety (out-of-bounds accesses, race conditions etc.), the safety of code using raw pointers cannot always be guaranteed. If you encounter an unsafe function, you can think of it as a function for which the compiler cannot guarantee that it is always safe to use: It might corrupt memory, produce a race condition, or simply result in undefined behavior. A key observation is that this only happens if you use the function incorrectly! A function that always introduces undefined behavior is not very useful, so instead every unsafe function will have a set of safety guarantees that the caller must uphold, and which are not enforced by the compiler.
Let's look at an example:
unsafe fn front_unchecked<T>(array: *const T) -> T { unsafe { std::ptr::read(array) } } fn main() { let arr = [42; 4]; println!("{}", unsafe { front_unchecked(arr.as_ptr())}); }
This unsafe function takes a pointer to an array and returns the first element of that array. This is kind of like Vec::<T>::front, but with no bounds checking performed, and without any moves. It uses the unsafe function std::ptr::read, which has the following signature: unsafe fn read<T>(src: *const T) -> T. It implements the same behavior as the dereferencing operator * in C/C++. Calling front_unchecked requires a pointer to an array (or a single element), which we can obtain from a Rust slice using as_ptr.
🔎 Aside - unsafe blocks in unsafe functions
Prior to Rust Edition 2024, a function marked as unsafe allowed calling any number of unsafe functions from within the function body. In the code example above, you might notice that we use a dedicated unsafe block (unsafe {}) in addition to marking the whole function as unsafe. The reasoning behind this is that declaring a function as unsafe is different from calling unsafe code: The former defines safety conditions that the caller has to uphold, whereas the latter acts as a "defuse" of the unsafety of the called function. If you write an unsafe {} block, you (as in you the programmer) state that "I know that I am calling unsafe code, but it is safe to do so!" For that reason, unsafe {} blocks should typically be accompanied by a // SAFETY: comment stating why the current usage is safe. For a more in-depth discussion, see the explanation of the corresponding Rust compiler lint.
Ensuring safety when working with unsafe code
A big question when working with unsafe code is: "Is this usage of unsafe actually safe?" If we use an unsafe function in a way that violates its safety guarantees, our program contains a bug. Since the safety guarantees are not encoded in the type system, they are not checked automatically, meaning we have to do the check manually ourselves by reading the documentation of the unsafe function. This makes working with unsafe Rust much harder than with safe Rust!
Let's look at our front_unchecked function and see if its usage of std::ptr::read is safe or not. As a properly documented unsafe function, std::ptr::read has a Safety section, which reads:
Behavior is undefined if any of the following conditions are violated:
- src must be valid for reads.
- src must be properly aligned. Use read_unaligned if this is not the case.
- src must point to a properly initialized value of type T.
Note that even if T has size 0, the pointer must be properly aligned.
If you start to work with unsafe Rust code, you will see that it sometimes feels like going down a rabbit hole of tricky conditions. In this case, the innocent statement src must be valid for reads links to the general safety rules of the std::ptr module, which contain one crucial statement: The precise rules for validity are not determined yet. It continues with a list of things that are allowed and not allowed, but the fact that there is no clear rule set for pointer validity is one of the reasons that unsafe Rust is tricky to get right.
For now, let's stick with a definition for validity that simply means the memory is properly allocated, the pointer points within that memory, and there are no concurrent writes while we read from the pointer. On top of that come the other two requirements from std::ptr::read, namely proper alignment and proper initialization. The neat thing with our front_unchecked function is that we can simply pass these safety requirements onto the caller, as we cannot determine all these invariants from within the function body of front_unchecked. After all, we do not know where the pointer comes from that is passed to front_unchecked! But this is not where it ends. Try to answer the following question for yourself before reading on:
❓ Question
Does front_unchecked have additional safety requirements?
💡 Click to show the answer
It has two additional requirements:
- The pointer must point to at least one element
- The type
Tmust implementCopy, even though we did not specify this at the type level!
We can easily create a Rust program that has a memory safety issue using our front_unchecked function by exploiting a subtle requirement of this function:
fn main() { let arr2 = [vec![1,2,3,4,5,6]; 1]; println!("{:?}", unsafe { read_first(arr2.as_ptr())}); println!("{:?}", arr2[0]); }
Running this program in debug mode will result in a double-free error. This is exactly the kind of memory error that Rust aims to prevent in the first place. This is the price of using unsafe! We will see shortly what we get for paying this price, but first we have to figure out what exactly went wrong here.
Recall that Rust is move-by-default, whereas C++ was copy-by-default? You might have noticed that std::ptr::read creates a copy of the value pointed to by its argument. The signature of std::ptr::read is *const T -> T, not *const T -> &T after all! What happens is that a simple bitwise copy is created, but we never specified that the type T supports bitwise copies. Since we read a non-Copy type (Vec<i32>) using std::ptr::read, we end up with two vectors both pointing to the same dynamically allocated array internally. Once the first Vec<i32> goes out of scope (after the first println! statement), the underlying memory has been freed. When the second Vec<i32> goes out of scope (the one inside arr2), this triggers the double-free error!
We can fix this in one of two ways:
- Either we put "the type
Tmust be safe for bitwise copies" into the# Safetysection of the function documentation - Or we simply require that
T: Copyin the signature
Note that it is the rare exception that safety guarantees of unsafe functions can be encoded in the type system. If we could encode all safety guarantees in the type system, there would be no need for unsafe after all!
A more useful example: Implementing Vec<T>
The previous example was somewhat contrived. It was meant to illustrate how we work with unsafe code, but its usage is limited. The only benefit over using something like std::slice::first is that is skips the bounds check and returns T instead of Option<&T>. As promised, now is the time to look at a more useful example, namely the implementation of Vec<T> for arbitrary types.
Recall our first attempt at defining Vec<T> in chapter 3.3.6:
#![allow(unused)] fn main() { struct CustomVec<T: Copy> { data: Box<[T]>, size: usize, capacity: usize, } }
There are two problems with this approach:
- It requires that
T: Copy - We only deferred the difficult problem of handling the dynamic array to another standard library type
Box<[T]>
There is a third problem that will become apparent once we try to implement the grow function that grows the internal array whenever more space is needed. A simple strategy for vector growth is to start with an empty array, on the first allocation use a small number of elements, for example 4, and then double the size whenever the array is full and more space is required. Here is an attempt to implement this algorithm in Rust:
#![allow(unused)] fn main() { impl<T: Copy> CustomVec<T> { fn grow(&mut self) { const FIRST_ALLOC_LENGTH: usize = 4; let new_capacity = FIRST_ALLOC_LENGTH.max(self.capacity * 2); let mut new_array = Self::alloc_dynamic_array(self.capacity * 2); if self.capacity > 0 { new_array[..self.capacity].copy_from_slice(&self.data); } self.data = new_array; self.capacity = new_capacity; } } }
We use a magic function Self::alloc_dynamic_array with the signature usize -> Box<[T]> that allocates a Box<[T]> for us, more on that in a moment. First, verify that the algorithm is correct: We allocate a new array that is either twice the previous size, or has a small initial size in case we never allocated (self.capacity is zero). Then, if we had a previous allocation, we copy all elements from the old array over to the new array and overwrite self.data. This will release the dynamic memory for the old array if there was one, due to the way Box<[T]> works. Lastly, we update our capacity.
Notice that this whole function uses zero unsafe! Alas, this is only true because we hid all the nasty details inside Self::alloc_dynamic_array:
#![allow(unused)] fn main() { impl<T: Copy> CustomVec<T> { fn alloc_dynamic_array(capacity: usize) -> Box<[T]> { let arr = unsafe { std::alloc::alloc( Layout::array::<T>(capacity).expect("Failed to allocate new dynamic array"), ) }; unsafe { let slice = std::slice::from_raw_parts_mut(arr as *mut T, capacity); Box::from_raw(slice as *mut [T]) } } } }
Here we see lots of unsafe code, and a bunch of new functions. Dynamic memory allocations are supported by the Rust standard library through the std::alloc module. The way it works is we first have to create a memory layout using the Layout type. In our case we want an array of capacity elements of T, so Layout::array is the function we need. Then we call std::alloc::alloc with this layout. The layout creation part is safe, but it can fail, for brevity we simply .expect that it doesn't. The allocation itself is the unsafe part, so we have to read the documentation. The only thing we care about is this line here:
layout must have non-zero size. Attempting to allocate for a zero-sized layout may result in undefined behavior.
Since we already talked about memory layouts try working through the following exercise on your own before reading on:
🔤 Exercise 3.5.1.1
Write a unit test to check what happens if you use the CustomVec type with a zero-sized type T. What do you observe? On a conceptual level, how would you have to change the current behavior of grow to adhere to the safety requirements of std::alloc::alloc?
💡 Need help? Click here
First, we need to define a zero-sized type. Coming from C++, you might think this is impossible because in C++, every possible type has a non-zero size, but in Rust zero-sized types are allowed. The simplest one is the unit type (), but any struct without members is also zero-sized. A key observation here is that all possible instances of a zero-sized type are equal, at least in terms of their binary structure. Knowing this, we might get an idea of what push does: Instead of storing the instances in a dynamic array, it only counts how many of those instances are stored.
Transferring this to alloc_dynamic_array, we see that it is unnecessary to allocate any memory for a zero-sized type. We will see how to do that shortly, as it requires a change to the data members of our CustomVec!
A unit test exposing the faulty behavior might look like this:
#![allow(unused)] fn main() { #[test] fn vec_with_zero_sized_type() { let mut v = CustomVec::new(); v.push(()); } }
However, this is not guaranteed to fail! Notice how the safety comment on std::alloc::alloc said "Attempting to allocate for a zero-sized layout may result in undefined behavior." Depending on the memory allocator that you are using, it doesn't have to fail. This is one of these situations where there is subtlety in the behavior of the code we use that is not easily determined by writing a test.
Before we move on to fix the issues with our grow function, we still have to go over the other unsafe code, namely std::slice::from_raw_parts_mut. We use this function to turn our raw pointer to a dynamically-sized array into the Rust builtin slice type. Recall that a slice is a fat pointer containing both the memory address and the number of elements in the array. We have both pieces of information available to use, so we can create a slice from them. There are many safety requirements for std::slice::from_raw_parts_mut, you are encouraged to have a look at them as we won't list them all here. Informally speaking, they require that we pass in a correctly initialized array of the correct size, coming from a single memory allocation, with the additional requirement that the pointer is the sole owner and reference to the memory. This last point allows the borrow checker to reason about the lifetime of the memory, and ensure the rule of one for the mutable borrow that is returned.
🔎 Aside - But our memory is not correctly initialized!
If you read the safety requirements of std::slice::from_raw_parts_mut carefully, the following statement might have caused you to question what we are doing here:
data must point to len consecutive properly initialized values of type T
Before we push any elements into our vector, the allocated dynamic array by definition contains uninitialized elements! So our usage of from_raw_parts_mut violates the safety requirement of the function and our code is unsound! There are two way in which our code is wrong:
- If we assume that all elements inside the dynamically allocated array are initialized, the destructor of
Box<[T]>will also callDrop::dropon every element of the slice, even on the ones that are technically uninitialized. However, since we restrictedT: Copy, this will never happen, asCopytypes by definition must not have aDropimplementation - Even types that are safe to
memcpymay need some form of initialization. The simplest example is thebooltype, which has exactly 2 valid representations:0x00forfalse, and0x01fortrue, as defined by the Rust reference. Uninitialized memory obtained fromstd::alloc::allocis not required to be zeroed, so it can have any value. Therefore, a conversion from uninitialized memory to aboolis instant undefined behavior! There are other cases with similar requirements, for exampleenumtypes, so this is not an issue that only happens forCustomVec<bool>!
The last unsafe function we use is Box::from_raw, which has an even longer list of safety requirements. We turn our slice into a Box<[T]> simply because we want to utilize the automatic cleanup that Box provides. We need to both call the destructor (Drop::drop) of every element within the slice, as well as deallocate the memory of the slice itself. We have to do the gymnastics of first creating a mutable borrow to a slice of T (&mut [T]) and then convert that back into a pointer to a slice (*mut [T]) and pass that into Box::from_raw so that the Box correctly wraps a dynamic array of elements. If we had instead converted the *mut u8 pointer obtained from std::alloc::alloc into a *mut T and passed that into Box::from_raw, we would have ended up with a Box<T> pointing to a single element! Notice that Rust has different semantics even for raw pointers: We can clearly differentiate between a pointer to a single element (*mut T) and a pointer to an array of elements (*mut [T]).
Fixing issues with CustomVec::grow
We saw that we cannot rely on std::alloc::alloc to work correctly for zero-sized types, as it may result in undefined behavior. If you read the documentation for std::slice::from_raw_parts_mut carefully, you might have noticed that it offers a solution for working with arrays of zero-sized types:
data must be non-null and aligned even for zero-length slices or slices of ZSTs. One reason for this is that enum layout optimizations may rely on references (including slices of any length) being aligned and non-null to distinguish them from other data. **You can obtain a pointer that is usable as data for zero-length slices using NonNull::dangling().** (emphasis ours)
The last sentence is the interesting one: For zero-length slices there is something called NonNull::dangling() that we can call to obtain the correct type of pointer. In our case, we have a slightly different requirement---a slice to zero-sized types (ZSTs)---but the idea is similar. The problem that we are trying to solve is that we cannot use std::alloc::alloc for ZSTs, but we still need a pointer to something.
🔎 Aside - Design decisions of `CustomVec`
We decided to use the following members for our CustomVec<T>:
#![allow(unused)] fn main() { struct CustomVec<T> { data: Box<[T]>, size: usize, capacity: usize, } }
Specifically, we abstracted the dynamically-sized array using Box<[T]>, so we get automatic cleanup of the elements and the memory itself. If Rust would allow specialization of generic types similar to templates in C++, we could have written a different struct definition if T is zero-sized:
#![allow(unused)] fn main() { struct CustomVecZeroSized<T> { size: usize, } }
Rust does not support specializations of this nature, so we need to find a struct definition that works for all possible values of T that we want to support. Since a vector is perhaps the most important data structure in Rust, we want it to support as many possibles types as we can, and ZSTs are not uncommon. Therefore, we are looking for something that encapsulates a dynamically-sized array of elements of both sized and unsized types. Since slices of zero-sized types are already handled by the language, we built on that and tried our luck with Box<[T]>, however we will see in a moment that there is an even better way. Lastly, the previous aside already explained why we technically are not even allowed to use Box<[T]>.
NonNull::dangling() is one option for obtaining a pointer that satisfies the memory layout requirements of pointers for usage as slices. In particular, it is not null and it respects alignment even for ZSTs. The NonNull type is interesting: It is a wrapper around a raw mutable pointer *mut T that provides additional guarantees that *mut T does not give. For one, it ensures that the pointer is not null, which can be helpful in various situations that rely on pointers not being null. It also provides something called covariance, which refers to how type conversion propagate to wrapped types. The Rust language documentation on variance has more information if you are interested.
If we try to use NonNull::dangling() instead of std::alloc::alloc for ZSTs, we run into problems unfortunately: Since the dangling pointer does not come from an actual memory allocation, it is illegal to wrap it in a Box<[T]>, as the Drop implementation of the Box would try to deallocate the memory. ThisAnd the fact that Box<[T]> assumes all elements are properly initialized forces us to reconsider the usage of Box<[T]>, which felt like a bit of a cheat anyways given that Box<T> is a type from the Rust standard library and we don't really know how it handles allocation and destruction. So we adjust our CustomVec<T> definition to the following:
#![allow(unused)] fn main() { struct CustomVec<T> { data: NonNull<T>, size: usize, capacity: usize, } }
Your initial impulse might have been to use NonNull<[T]> instead, however that won't work because slice types don't have a well-known size at compile-time and therefore many of the functions on NonNull that we need are not usable. This is unfortunate as NonNull<T> for a dynamically-sized array does not match the intuition: We have a pointer to an array, not a single element after all! While there are reasons for this, a thorough understanding of them would require a more comprehensive explanation than we can reasonably give in this chapter. For now, we just have to accept this fact.
Before moving on to the implementation of this new CustomVec<T> type, first try to answer the following question:
❓ Question
What is the capacity of a vector if T is a zero-sized type?
💡 Click to show the answer
Theoretically, the capacity is infinite as the values have a size of zero. Practically, since we have to keep track of the number of elements, the capacity is limited by the capacity of the usize type, so usize::MAX
Creating a new CustomVec<T> looks like this:
#![allow(unused)] fn main() { pub fn new() -> Self { Self { // Zero-sized types take no space, hence in this case we have the maximum possible capacity and never // need to grow! capacity: if Layout::new::<T>().size() == 0 { usize::MAX } else { 0 }, data: NonNull::dangling(), size: 0, } } }
The alloc_dynamic_array function changed quite a bit:
#![allow(unused)] fn main() { fn alloc_dynamic_array(capacity: usize) -> NonNull<T> { let layout = Layout::array::<T>(capacity).expect("Failed to allocate new dynamic array"); let arr: *mut u8 = unsafe { std::alloc::alloc(layout) }; // alloc is allowed to return a null-pointer if there is not enough memory if arr.is_null() { panic!("Out of memory"); } // At this point we know our allocation succeeded and we have a proper non-null pointer // Since alloc returns `*mut u8`, we have to cast to `*mut T` unsafe { NonNull::new_unchecked(arr as *mut T) } } }
The return type changed, and we explicitly deal with failed allocations, something that we (silently) forgot to do in the previous version of the code! A dangerous property of this code is that we return a pointer to a single element (that is what NonNull<T> means), but we as the implementors know that it actually points to an array of elements! We have to keep that in mind in the rest of the implementation of CustomVec<T>!
Since we have a new return type of alloc_dynamic_array, the grow function changes as well:
#![allow(unused)] fn main() { fn grow(&mut self) { const FIRST_ALLOC_LENGTH: usize = 4; let new_capacity = FIRST_ALLOC_LENGTH.max(self.capacity * 2); let new_array: NonNull<T> = Self::alloc_dynamic_array(new_capacity); if self.capacity > 0 { // This doesn't work anymore because NonNull<T> is NOT a slice! // new_array[..self.capacity].copy_from_slice(&self.data); } self.data = new_array; self.capacity = new_capacity; } }
We now face the problem of copying the elements from the old array to the new array. Where previously we dealt with the builtin slice type and could use copy_from_slice, this doesn't work anymore with raw pointers such as NonNull<T>. Luckily, there are similar functions such as NonNull::copy_from_nonoverlapping that we can use:
#![allow(unused)] fn main() { unsafe { new_array.copy_from_nonoverlapping(self.data, self.capacity); } }
It copies self.capacity elements from the given memory address (self.data) into self (new_array in our case). The non_overlapping part simply means that the two memory regions do not overlap, which lets the compiler emit more efficient codeNon-overlapping copies in Rust are semantically equivalent to memcpy in C, whereas overlapping copies are equivalent to memmove. The function is unsafe because it performs a bitwise copy of types that might have stricter requirements (such as specific alignment), and the compiler cannot know if the memory pointed to actually contains the given number of elements. Lastly, the non-overlapping property is not checked to keep the code efficient, but accidentally passing in overlapping memory therefore causes undefined behavior. Again, it is crucial that we read the safety section in the documentation.
Before moving on to the interesting functions push and get, we have to remember that we now store a raw pointer to an allocated memory block inside our CustomVec type. This means we have to implement a destructor, which in Rust is done by implementing the Drop trait:
#![allow(unused)] fn main() { impl<T> Drop for CustomVec<T> { fn drop(&mut self) { // 1) Call "Drop" implementation for every element // TODO Drop elements implementation // 2) Deallocate memory, but only if we are not zero-sized and actually have elements if Self::SINGLE_VALUE_LAYOUT.size() == 0 || self.capacity == 0 { return; } // TODO Deallocation implementation } } }
Drop for CustomVec has to perform the exact same operations as operator delete[] would in C++: First, call the destructor of every element, then deallocate the memory. Deallocation is fairly easy, as there is std::alloc::dealloc:
#![allow(unused)] fn main() { unsafe { std::alloc::dealloc( // dealloc expects a pointer to u8, not to T, so we cast here self.data.as_ptr() as *mut u8, // dealloc needs the exact layout that we gave to alloc Layout::array::<T>(self.capacity).expect("Failed to create Layout for array of T"), ); } }
Concerning safety, we need to make sure that the pointer points to an allocation from the same allocator, and that we pass in the exact same Layout as we did to std::alloc::alloc. Both are true in our case.
Now what about calling the destructor of every element? As the Rust documentation tells us, we cannot call Drop::drop ourselves! There is std::mem::drop, which simply lets an instance of a type go out of scope, therefore invoking the destructor, but this is out of the question in our case, as multiple instances sit within a dynamically allocated memory block. One way to do that is to move every element out of the dynamic array, manually drop it, and then simply deallocate the whole array, as it now consists entirely of moved or uninitialized elements:
#![allow(unused)] fn main() { unsafe { for index in 0..self.size { let element = self.data.add(index).read(); drop(element); } // Then deallocate self.data // ... } }
This works, but is less efficient than it can be: The ptr::read function performs a bitwise copy of each element, which then immediately gets dropped. Compared to a (fictional) direct function call of Drop::drop, the resulting assembly code of the ptr::read solution will contain additional instructions to do the bitwise copy into a variable on the stack. A more efficient (and elegant) solution is to use a special function called std::ptr::drop_in_place:
#![allow(unused)] fn main() { unsafe { let valid_slice = std::slice::from_raw_parts_mut(self.data.as_ptr(), self.size); std::ptr::drop_in_place(valid_slice); } }
Reading the documentation of std::ptr::drop_in_place is insightful as it points out edge-cases that we might not have considered (such as dropping unsized types).
🔤 Exercise 3.5.1.2
Prove that std::ptr::drop_in_place is indeed at least as efficient as a handwritten loop using ptr::read
💡 Need help? Click here
Instead of a proof, here are possible approaches to demonstrate that std::ptr::drop_in_place is the better choice in terms of efficiency:
- Perform benchmarks and measure the resulting runtime
- Downside: Writing a correct benchmark in which you actually measure what you want (without the compiler optimizing things away that you think you measure) is hard
- Inspect the generated assembly code
- Downside: Reading assembly code can be more difficult, and we cannot be sure that a piece of code is faster than another piece of code only by e.g. counting the number of instructions (though it is a decent metric in general)
- If you want to challenge yourself, you might even look into the compiler implemetation, though this potentially requires reading both the
rustccode as well asllvmcode
In all cases, you have to consider different types, as any type that implements Copy does not need a Drop::drop call, causing the compiler to emit the whole loop as a no-op.
Note that the phrasing "is at least as efficient" implies that there might be situations where both approaches result in the same assembly code and therefore have the same performance, for example the aforementioned Copy types with an elided loop.
Writing and reading using push and get
To make our CustomVec usable, we need ways to insert elements and access existing elements. Let's start with the more difficult implementation of push first. The algorithm looks like this:
#![allow(unused)] fn main() { fn push(&mut self, element: T) { // 1) Is there no space left? If so, grow() first // 2) Write the element to the next free position // 3) Increment size } }
Bullet points 1) and 3) are trivial, but 2) requires some thought. Recall that we store our data through a NonNull<T>, which is not a Rust slice or something that we can index using the [] operator, but instead a raw pointer. Similar to C/C++, we need to use pointer arithmetic to obtain a pointer to the correct memory address and then write our element into that address. Luckily for us, there is std::ptr::write which does the second part:
#![allow(unused)] fn main() { fn push(&mut self, element: T) { if self.size == self.capacity { self.grow(); } let head = self.data.as_ptr(); unsafe { head.add(self.size).write(element); } self.size += 1; } }
It is worth looking into std::ptr::write because it performs an interesting operation with regard to the value semantics of the Rust language. We already learned that Rust is move-by-default, and we saw that a move is identical to a bitwise copy in many cases. What is different is that moved-from values cease to exist and therefore require no destructor call. A quick recap:
fn consume(data: String) {} fn main() { let s = String::new("Strings require Drop::drop calls!"); consume(s); // println!("{s}"); // Does not compile because `s` has been moved } // Instead of going out of scope at the end of `main`, `s` is already out of scope // So no destructor call at the end of `main` for `s`!
It is important to understand that the memory of the local variable s on the stack is unaffected by the move! Within the rules of the Rust language, you are not allowed to reference that memory anymore after the s has been moved, but on the machine level, it is perfectly valid if the stack space gets reclaimed only after main exits and not right when s is moved into consume!
The situation is similar for our std::ptr::write call: We copy the bits that make up our element into the dynamic array at the correct position and also mark the variable element as "has been moved". If we didn't do that second part we would risk a double-free, because the destructor of element would run at the end of push and then again once our CustomVec gets destroyed! It is for that reason that std::ptr::write does not call the destructor of its argument! Take a look at the following visualization together with the relevant code inside grow:
#![allow(unused)] fn main() { fn push(&mut self, element: T) { // (1) // ... let head = self.data.as_ptr(); unsafe { head.add(self.size).write(element); // (2) and (3) } // ... } }

Another important point to keep in mind when using std::ptr::write is that it also does not call the destructor of the current value at the memory location! In our case this is fine because our CustomVec guarantees that when we call push, the memory address at which we push contains uninitialized memory. Therefore no previous instance of T is overwritten! The fact that we work with uninitialized memory is one of the main reason why we needed unsafe in the first place: Within safe Rust, you will never encounter uninitialized memory. It is also the reason why the implementation of CustomVec from chapter 3.3.6 required T: Copy and yet still is subtly wrong: We convert uninitialized memory to a slice of T, but this is not allowed in Rust. The correct way to point to uninitialized value is through the MaybeUninit<T> type.
get luckily is a bit simpler:
#![allow(unused)] fn main() { pub fn get(&self, index: usize) -> Option<&T> { // Bounds checking so that we don't access uninitialized memory if index >= self.size { return None; } // Go from a pointer to the element to a Rust borrow. This is unsafe as the compiler can't // guarantee that the pointer has the same semantics as a reference (proper alignment, memory // is initialized, there are not mutable borrows to the memory etc.) unsafe { let element = self.data.add(index).as_ref(); Some(element) } } }
We still don't get away without using unsafe, as going from a pointer to a borrow is a dangerous operation.
🔤 Exercise 3.5.1.3
Implement an unsafe get_unchecked variant that returns &T instead of Option<&T> and performs no bounds checking. Add a # Safety block to the method documentation describing when this function is safe to use
💡 Need help? Click here
#![allow(unused)] fn main() { /// Obtain a reference to the element at `index` without bounds checking /// # Safety /// `index` must be within the bounds of the vector pub unsafe fn get_unchecked(&self, index: usize) -> &T { self.data.add(index).as_ref() } }
Recap
With this, we wrote our first low-level collection in Rust that is efficient and correctly uses unsafe code!
Try to answer the following questions for yourself:
- What problem does
unsafeRust solve? - How can we make sure that we correctly use an
unsafefunction? - What does
std::ptr::writedo with its argument? - What was the purpose of using
NonNull::dangling()in the constructor ofCustomVec<T>?
Interfacing with C functions
Under construction
A case-study of unsafe Rust using the heapless crate
Under construction
4. Zero-overhead abstractions - How to write fast, maintainable code
While the last chapter was all about the low-level details of memory, in this chapter we will take a more high-level look at systems programming and the abstractions that modern systems programming languages offer to write faster, more robust code with greater ease. Many of the abstractions that we will learn about in this chapter come from the domain of functional programming and have found their way into modern programming languages, not only for systems programming but application programming as well. What sets systems programming languages apart from other languages is the focus on zero-overhead abstractions, as we already saw in the previous chapter. To this end, we will not only learn about some useful abstractions such as optional types and iterators in this chapter, but we will also learn how they work under the hood and what enables these abstractions to be efficient.
Here is the roadmap for this chapter:
4.1. Product types, sum types, and the Option type
In this chapter, we will learn about optional types and the various ways we can represent such optional types using the type system. Here we will learn about the difference between product types and sum types, two concepts from the domain of functional programming.
The story of null
To understand what optional types are and why we should care, we will look at one of the most common and yet controversial concepts of computer science: null. Many programming languages support null as a concept to refer to some value that does not exist. In C this is realized through pointers with the value 0, C++ introduced a dedicated nullptr type, Java and C# have null, JavaScript even has two similar types null and undefined. If it is such a common feature, surely it is a great feature then?
From the authors personal experience, one of the more frustrating things while learning programming was dealing with null. Some languages are able to detect null values, for example Java or C#, other languages such as C and C++ just go into undefined behaviour mode where anything can happen. Checking for null values is something that was taught as an exercise in discipline to young programmers: You just have to learn to always check for null! Here is a small piece of code showing a situation where we 'forgot' to check for null:
#include <iostream>
void foo(int* ptr) {
std::cout << *ptr << std::endl;
}
int main() {
int bar = 42;
foo(&bar);
foo(nullptr);
return 0;
}
In a language that does not detect null values automatically, you are punished harshly for forgetting to check for null values, oftentimes resulting in a long and frustrating search for the reason of a program crash. But surely that's just what you get for not being disciplined enough, right? Over the history of programming, it has been shown time and again that relying on the infallability of humans is a bad idea. We make mistakes, that is just to be expected. After all, one of the main reasons why we even invented computers is so that they can do tedious calculations without making mistakes. In fact, many of the mechanisms built into programming languages are there to prevent common mistakes. Functions and variables in C, for example, automatically generate the correct code for managing stack memory, so that we as programmers don't have to do this by hand. So why should null be any different? Even the creator of the null concept, Tony Hoare, considers null to have been a bad idea, calling it his billion dollar mistake.
The problem with null is that it is a silent state. Think about a pointer type such as int*. In C, which does not know the concept of references, we have to use pointers to pass around references to other data. So we use a pointer type to tell a function: 'Here is a variable that lies at some other memory location.' So we use pointers for indirection. However pointers can be null, so suddenly, we have some added semantics that silently crept into our code: 'Here is a variable that lies at some other memory location or maybe nothing at all!' We never explicitly said that we want to pass something or nothing to the function, it is just a side-effect of how pointers work.
What is null, actually?
To get to the heart of why null can be frustrating to use, we have to understand what null actually represents. From a systems-level point of view, null is often equivalent to a null pointer, that is a pointer which points to the memory address 0x0. It has come to mean nothing over time, but nothing is a bit weird. Clearly a pointer with value 0x0 is not nothing, we just use it as a flag to indicate that a variable holds no content. There are multiple situations where this is useful:
- Indicating that something has not been initialized yet
- Optional parameters for functions or optional members in types
- Return values of functions for parameters that the function was not defined for (e.g. what is the return value of
log(0)?)
So already we see a bit of misuse here: We hijacked some special value from the domain of all values that a pointer can take, and declared that this value refers to the absence of a valueIf you think about it, why would the address 0x0 even be an invalid memory address? In a physical address space, it would be perfectly reasonable to start using memory from the beginning of the address space, so starting from the location 0x0. There are some systems where reading from and writing to 0x0 is valid, but nowadays with virtual addressing, 0x0 is generally assumed to be an invalid address for programs to access. The C standard explicitly defines that the value 0 corresponds to the null-pointer constant.. It would be better if we could separate the domain of possible memory addresses from the concept of a 'nothing' value. In the JavaScript language, there is the special undefined type, which is an attempt at encoding the absence of a value into a type. But since JavaScript is dynamically typed, forgetting to check for the presence of undefined is as real a possibility as checking for null is in other languages. But it should be possible to implement a special 'nothing' type in a statically typed programming language as well!
The main problems with null
To summarize, the two main problems with null are:
- It (silently) infiltrates a seemingly unrelated type (e.g. pointer types) and adds the concept of the absence of a value to this type
- The type system does not force us to handle
nullvalues
Think about what the first point means in C for a moment. We used pointers for a specific task, namely indirection, and now have to deal with a second concept (absence of a value) as well, even if we don't need this second concept! Conversely, if we want to indicate the absence of a value, for example in the return value of log(0), we would have to use a pointer type. Which doesn't make sense, the value 0 might be invalid for a pointer but is certainly valid as a return value of the logarithm function (log(1) == 0). What we would like instead is a special way to indicate that a value can either be some valid value, or 'nothing'.
Regarding the second problem: There is no way for the type system to know whether a pointer is null or not, and hence the compiler can't force us check for this situation. The whole point of a statically-typed language was that the compiler checks certain invariants on types for us. So why couldn't we have a language that forces us to check for the presence of null, for example like this:
void foo(int* ptr) {
deref ptr {
nullptr => return;
int& derefed => std::cout << derefed << std::endl;
}
}
It is possible to achieve something like this, and several modern programming languages already actually abandoned null for something better. In the next sections, we will understand how to build such a type form the ground up, and will see how such a type is a central part of the Rust programming language.
Using the type system to encode the absence of a value
To achieve our goal of replacing null with something better, we have to understand types a bit better. In chapter 2.3 we learned that types were these special properties that get assigned to your code that the compiler can use to enforce rules on your code (e.g. we can only assign variables with matching types to each other). This hand-wavy definition was enough to explain what a compiler does, but to build our own null-replacement, we need more knowledge.
Like most things in computer science, types come from the domain of math. A type is essentially a set: If defines the range of all possible values that a value of this type can take. A simple example for types are numbers: The number 5 is a natural number, because it is part of the set of natural numbers \( \mathbb{N} \), so we could say that the type of 5 is 'natural number'.
The number \( \frac{3}{8} \) is not part of \( \mathbb{N} \), so it's type can't be 'natural number'. Instead, it comes from the set of rational numbers (\( \mathbb{Q} \)), so it has the type 'rational number'. What the type system now does is to enforce set membership, that is to say it checks that a value declared as type A actually belongs to the set of values that A defines. So if we have the following pseudo-code:
NaturalNumber nn = 4.8;
It is the job of the type system and compiler to check whether the value 4.8 belongs to the type NaturalNumber. In this case, it does not, so an error could be raised by the compiler.
Moving to the domain of actual programming languages, we can look at some primitive types to understand how the type system treats them. The Rust-type bool, for example, is represented by the set \( \{ true, false \} \). As another example, the Rust type u8 is represented by the set \( \{ 0, 1, ..., 255 \} \). For all primitive types, these sets of valid values are well defined and relatively easy to figure out. You can try for yourself:
Exercise 4.1: What are the sets that belong to the primitive types i8, u32 and f32 in Rust? What about void* on a 64-bit system in C++? (Hint: f32 is a bit special, how does it relate to the set of real numbers \( \mathbb{R} \)?)
So what about more complex types, such as std::string in C++ or Vec<T> in Rust? We call these types composite types, because they are composed (i.e. made up of) zero or more primitive types. The builtin features for creating composite types are the struct and class keywords in C++ and the struct and enum keywords in Rust. Disregarding the enum keyword for now, both struct and class in C++ and Rust can be used to group primitive types (or other composite types) together into composite types. An interesting property of composite types can be observed now: Since all primitive types are described by finite sets, all composite types are also described by finite sets. That is to say: There are only finitely many possible values for any possible composite type. Which might seem unintuitive at first: Clearly, a type like std::string can store any possible string (disregarding memory capacity). We could store the textual representation of any natural number in a std::string, and we know there are infinitely many natural numbers. So the set of all values for the type std::string should be inifinitely large!
Our misconception here comes from the fact that we confuse the array of character values that make up the string with the actual value of type std::string. A trivial definition of the std::string type might look like this:
struct string {
char* characters;
size_t length;
};
It is composed of a pointer to the characters array, potentially allocated on the heap, as well as an integer value for the length of the stringsize_t is an unsigned integer value as big as a pointer on the target machine. On a 64-bit system, it might be equivalent to the type unsigned long long, which is 8 bytes large.. A value of this type string will be 16 bytes large in memory on a 64-bit system. Irregardless of what data the characters pointer points to, the string value itself is always just a pointer and an integer. Since they make up 16 bytes, there are \( 2^{128} \) possible values for the string type, which is a large but finite number. To check if a value matches the type string, the compiler only has to check if the value in question is made up of one value from the set of all values dictated by the char* type, and one value from the set of all values dictated by the size_t type. Note that the trick with using the size of a type to determine the number of possible values is not strictly correct. Look at the following type in Rust:
#![allow(unused)] fn main() { struct Foo { a: u32, b: bool, } }
Due to memory alignment, this type will probably be 8 bytes large. Even if we use the packed representation, the type will take 5 bytes, but not all of these bytes are actually relevant to the type. Since the b member is of type bool, the only two values it can take are true and false, for which we need only one bit instead of one byte. Using the size of the type, it would indicate that there are \( 2^{(32+8)} \) possible values, when in fact there are only \( 2^{(32 + 1)} \) possible values. So we need a different formula to determine the number of valid values for a type.
We can try to enumerate the possible values of the Foo type and try to deduce something from this enumeration. If we represent Foo as a tuple struct, it gets a bit easier to enumerate the possible values:
#![allow(unused)] fn main() { struct Foo(u32, bool); }
The possible values of Foo are: (0, false), (0, true), (1, false), (1, true), ..., (4294967295, false), (4294967295, true). For every possible value of the u32 type, there are two possible values of Foo, because bool has two possible values. So we multiply the number of possible values for each type together to obtain the number of possible values of the composite type. The mathematical operation which corresponds to this is the cross-product, since the set of all possible values of the composite Foo type is equal to the cross-product of the set of values of u32 and the set of values of bool. For this reason, we call structs in Rust and structs/classes in C++ product types.
Now, where does null come in? We already decided that we need a type that indicates the absence of a value, and we want to be able to 'glue' this type onto other types. So for example for a log function that computes a logarithm, the return value would be a floating-point number, or nothing if the value 0 was passed to log. Since it is a bit hard to enumerate all possible floating-point numbers, we will assume that the log function returns a natural number as an i32 value instead. If we enumerate the possible return values of this function, we get this set: -2147483648, ..., -1, 0, 1, ..., 2147483647, Nothing. We used a special value named Nothing to indicate the absence of a value. How could we define a type whose set of valid values is equal to this set? We could try a struct:
#![allow(unused)] fn main() { struct Nothing; struct I32OrNothing { val: i32, nothing: Nothing, } }
But we already learned that structs are product types, so the set of possible values for I32OrNothing is this: (-2147483648, Nothing), ..., (-1, Nothing), (0, Nothing), (1, Nothing), ..., (2147483647, Nothing). Not what we want! When we declare a struct with two members of type A and B in Rust (or C++), what we tell the compiler is that we want a new type that stores one value of type AAND one value of type B. To use our I32OrNothing type, we instead want a value of type i32 OR a value of type Nothing! So cleary a struct is not the right concept for this.
Enter sum types
Where with structs, we defined new types whose sets were obtained as the product of the sets of its members, we now want a type whose set of values is the sum of the set of possible values of its members. Rust supports such types with the enum keyword, and these types are aptly named sum types. C++ sadly does not support sum types, but we will see in a bit what we can do about that, for now we will work with what Rust gives us!
enums in Rust work by declaring zero or more variants. These variants define possible values of the type. enum is actually a shorthand for enumeration, and many languages support enumerations, but only a few support enumerations that are as powerful as the ones in Rust. C++ supports enumerations, but here they are simply primitive types (integer types to be exact) with a restricted set of values. So where the unsigned int type in C++ might take values from the set {0, 1, ..., 2^32-1}, with an enum in C++ we can restrict this set to specific named values:
enum class Planet {
MERCURY = 0,
VENUS = 1,
EARTH = 2,
MARS = 3,
JUPITER = 4,
SATURN = 5,
URANUS = 6,
NEPTUNE = 7,
};
The Planet type is in principle identical to the unsigned int type, but its valid set of values is smaller: {0,1,...,7}. By defining an enum, we state that any variable of this enum type will always contain exactly one of the stated variants (MERCURY, VENUS etc.). What we can't do in C++ is to have one value be of type unsigned int and another value be of another type, such as float or even a non-primitive type such as std::string. In Rust however, this is possible! So in Rust, we can define a variant that contains another type:
#![allow(unused)] fn main() { enum U8OrNone { Number(u8), NoNumber(Nothing), } }
The set of values of this type would be: {Number(0), Number(1), ..., Number(255), NoNumber(None)}. Our Nothing type now looks a bit redundant, we can actually use an empty variant for this:
#![allow(unused)] fn main() { enum U8OrNone { Number(u8), None, } }
The neat thing about enums in Rust is that they are full-fledged types, so the compiler will enforce all its type rules on variables of enum types. In particular, the compiler knows about all the possible variants and forces us to handle them. Let's look at an example in practice:
fn add_one(number: U8OrNone) -> U8OrNone { match number { U8OrNone::Number(num) => U8OrNone::Number(num + 1), U8OrNone::None => U8OrNone::None, } } fn main() { let num = U8OrNone::Number(42); let no_num = U8OrNone::None; println!("{:?}", add_one(num)); println!("{:?}", add_one(no_num)); }
Using an enum in Rust is done through pattern matching using the built-in match construct: You match on a value of an enum and provide one match arm for each of the possible variants. The match arms are structured like this: variant => statement, where variant is one of the variants and statement can be any statement. Perhaps most interestingly, we can get access to the internal data of a variant inside a match arm: U8OrNone::Number(num) gives a name (num) to the value inside the Number(u8) variant, and we can work with this value. In this case, we write a function that takes a number or nothing and try to add one to the number. If there is no number, we simply return None, but if there is a number, we unpack the value using the match arm, add one to it and pack it back into another U8OrNone.
Notice how we never could have forgotten that there is a special None value here? Because we encoded this value into a type, the compiler enforced us to handle this special value! This is much better than null, which was part of a types value set silently. If we try to use the U8OrNone type directly, for example to add a value to it, we get a compile error:
#![allow(unused)] fn main() { fn add_one_invalid(number: U8OrNothing) -> U8OrNothing { number + 1 } }
error[E0369]: cannot add `{integer}` to `U8OrNothing`
--> src/chap4_optional.rs:9:12
|
9 | number + 1
| ------ ^ - {integer}
| |
| U8OrNothing
|
= note: an implementation of `std::ops::Add` might be missing for `U8OrNothing`
The error message is pretty clear: We can't add an integer to a value of type U8OrNothing. We thus have achieved our first goal: No more silent null values that we might forget to check for. The compiler forces us to check for the Nothing case!
Since this pattern ('I want either a value or nothing') is so common, it has a special name: This is an optional type. Rust has a built-in type called Option<T> for this: It encapsulates either a value of an arbitrary type T, or the special value None. The definition of the Option<T> type is very simple:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
C++ also has a similar optional type, but not in the language itself, only in the standard library: std::optional<T>. Since C++ does not support pattern matching, it is arguably not as nice to use as Rust's Option<T> type.
With Option<T>, we could write a good log function that only returns an output when the input is greater than zero:
#![allow(unused)] fn main() { fn log2(num: f32) -> Option<f32> { if num <= 0.0 { None } else { Some(num.log2()) } } }
How optional types map to the hardware
As systems programmers, we want to know how we can map such a high-level construct onto our machine. In particular, we want our optional type to work as efficiently as possible! This is a fundamental principle of many systems programming languages: First and foremost, we want the ability to write code that is as efficient as possible, then we want our code to be nice and easy to write. Sometimes, it is possible to get both at the same time. C++'s creator Bjarne Stroustrup coined a term for an abstraction that is as efficient as a hand-rolled solution, but nicer to write: Zero-overhead abstraction. This is what we are looking for in systems programming: Abstractions that make it easier to write correct code (such as the Option<T> type in Rust), but are just as efficient if we had written the underlying mechanism by hand. So, what is the underlying mechanism making optional types possible?
Let's look back at the type sets that we analyzed previously, for example the set of valid values for the U8OrNone type: {0, 1, ..., 255, None}. When the compiler translates code using this type into machine code, it has to figure out how big this type is to allocate the appropriate amount of memory on the stack. Here is a neat trick: The minimum size of a type in bits is the base-2 logarithm of the magnitude of the set of values of this type, rounded up to the next integer:
\(sizeof(Type) = \lceil log_2 \lVert Type \rVert \rceil\).
Applying this formula to our U8OrNone type gives: \(sizeof(U8OrNone) = \lceil log_2 \lVert U8OrNone \rVert \rceil = \lceil log_2 257 \rceil = \lceil 8.0056 \rceil = 9 \). So we need 9 bits to represent values of the U8OrNone type, which intuitively makes sense: 8 bits for the numbers, and a single bit to indicate the absence of a number. Note that when the None bit is set, the value of the other bits don't matter: With 9 bits we can represent 512 different values, but we only need 257 values!
From here, we can see how we might implement our U8OrNone type in a language that does not support sum types natively: By adding a bit-flag that indicates the absence of a value:
#include <stdint.h>
#include <iostream>
#include <stdexcept>
struct U8OrNone {
U8OrNone() : _has_value(false) {}
explicit U8OrNone(uint8_t value) : _value(value), _has_value(true) {}
uint8_t get_value() const {
if(!_has_value) throw std::runtime_error{"Can't get_value() when value is None!"};
return _value;
}
bool has_value() const {
return _has_value;
}
private:
uint8_t _value;
bool _has_value;
};
int main() {
U8OrNone none;
U8OrNone some{42};
std::cout << "None: " << none.has_value() << std::endl;
std::cout << "Some: " << some.get_value() << std::endl;
// Note that there is no separate type here for `None`. We could
// still just do get_value() on `none` and it would be a bug that
// the compiler can't catch...
std::cout << none.get_value() << std::endl;
return 0;
}
Since the smallest addressable unit on most systems will be a single byte, the U8OrNone type will actually be two bytes instead of one byte (on x64 Linux using gcc 11). This might seem somewhat wasteful, but it is the best we can do in this scenario.
One thing worth debating is why we don't simply use the value 0 to indicate None. That way, we could store all values inside a single byte in our U8OrNone type. Think on this for a moment before reading on!
The problem is that the value 0 might be a perfectly reasonable value that users want to store inside the U8OrNone type. If you want to store the number of eggs in your fridge, 0 and None might be equivalent, but for an account balance for example, they might be different: An account balance of 0 simply indicates that there is no money in the account, but None would indicate that there is not even an account. These things are distinctly different!
Now, in some scenarios, the set of values of a type does contain a special type that indicates the absence of a value. This is exactly what the null value for pointers does! In these cases, we can use the special value to store our None value and safe some memory. This is called a null pointer optimization and Rust does this automatically! So Option<T> has the same size as T, if T is a pointer or reference type!
Exercise 4.2: Implement a simple optional type for C++ that can hold a single value on the heap through a pointer. What can you say about the relationship of this optional type and simple reference types in C++?
Using Option<T> in Rust
Option<T> is an immensely useful tool: It is everything that null is, but safer. Since it is one of the most fundamental types in Rust (besides the primitive types), we don't even have to include the Option<T> type from the standard library with a use statement, like we would have to do with other standard library files! Let's dig into how we can use Option<T>!
Option<T> has two variants: Some(T) and None. These can be used in Rust code like so:
#![allow(unused)] fn main() { let some = Some(42); let none : Option<i32> = None; }
Note that when using the None type, we might have to specify exactly what kind of Option<T> we want, as None fits any Option<T>! In many cases, the Rust compiler can figure the correct type out, but not always.
If we want to use the (potential) value inside an Option<T>, we have two options: We can either use a match statement, or we can use the unwrap function. match statements are the safer bet, as we will never run into the danger of trying to use the inner value of the Option<T> when it has no value, since we can't even access the value in the None arm of the match statement! Only if we are really 100% sure that there is a value, we can bypass the match statement and access the value directly using unwrap. If we try to call unwrap on an Option<T> that holds None, it will result in a panic, which in Rust will terminate the current thread (or your whole program if you panic on the main thread). Generally, panic is used whenever a Rust program encounters an unrecoverable condition. Trying to get the value of a None optional type is such a situation!
Take a look at the following example to familiarize yourself with the way Option<T> is used in Rust:
#![allow(unused)] fn main() { fn add_one_builtin(number: Option<u8>) -> Option<u8> { match number { Some(num) => Some(num + 1), None => None, } } fn add_one_builtin_verbose(number: Option<u8>) -> Option<u8> { if number.is_none() { None } else { let num = number.unwrap(); Some(num + 1) } } }
To figure out whether an Option<T> is Some(T) or None, we can also use the is_some and is_none functions. This is essentially the way option types work in C++, since C++ does not support the match syntax that Rust has.
This kind of operation right here - applying some transformation to the value contained within the Option<T>, but only if there is actually a value - is a very common pattern when using optional types. If we think of Option<T> as a boxJust a regular box. Not to be confused with the Rust Box<T>! Think cardboard, not heap! around a T, this is equivalent to unboxing the value (if it exists), performing the transformation, and putting the new value back into a box:
Notice from the picture that this transformation really can be anything. We don't have to add one, we could multiply by two, always return zero, as long as we take a value of type T and return some other value, this behaviour would work. We can even return something different, like turning a number into a string. So any function works, as long as it has the right input and output parameters. The set of input and output parameters to a function defines its type in RustRust is a bit simpler in that regard to C++, where functions can also be const or noexcept or can be member-functions, all of which contributes to the type of a function in C++.. So a function such as fn foo(val: i32) -> String has the type i32 -> String. The names of the parameters don't really matter, only their order and types. This syntax X -> Y is very common in functional programming languages, and it matches the Rust function syntax closely (which is no coincidence!), so we will use this syntax from now on. We can also talk about the signature of generic functions: The Rust function fn bar<T, U>(in: T) -> U has the signature T -> U.
Armed with this knowledge, we are now ready to bring Option<T> to the next level!
Higher-order functions
If we look at the add_one_builtin function from the previous example, we see that its type is Option<u8> -> Option<u8>. Now suppose that we instead had a function like this:
#![allow(unused)] fn main() { fn add_one_raw(num: u8) -> u8 { num + 1 } }
This function does the same thing as our add_one_builtin function, but on u8 values instead of Option<u8> values. The signature looks similar though: u8 -> u8. In our box-picture, here is where the function would sit:
The interesting thing is that we could use any function of type u8 -> u8 here! The process of taking the value out of the box and putting the new value back into the box would be unaffected by our choice of function. So it would be annoying if we could not simply use our existing add_one_raw function with Option<u8> types. Why write a new function just to add the boilerplate of taking values out of the Option<u8> and putting them back in? We would have to do this every time we want to use some function with signature u8 -> u8 with Option<u8>. That would be a lot of unnecessary code duplication.
Luckily, Rust supports some concepts from the domain of functional programming. In particular, it is possible to pass functions as function arguments in Rust! So we can write a function that takes another function as its argument! So we could write a function that takes a value of type Option<u8> together with a function of type u8 -> u8 and only apply this function if the value is Some:
#![allow(unused)] fn main() { fn apply(value: Option<u8>, func: fn(u8) -> u8) -> Option<u8> { match value { Some(v) => Some(func(v)), None => None, } } }
In Rust, the type of a function u8 -> u8 is written as fn(u8) -> u8, so this is what we pass here. We then match on the value: If it is None, we simply return None, but if it is Some, we extract the value from the Some, call our function on this value and put the new value into another Some. We could say that we apply the function to the inner value, hence the name apply. We can now use this apply function to make existing functions work together with the Option<T> type:
fn add_one_raw(num: u8) -> u8 { num + 1 } fn mul_by_two(num: u8) -> u8 { num * 2 } pub fn main() { println!("{:?}", apply(Some(42), add_one_raw)); println!("{:?}", apply(Some(42), mul_by_two)); println!("{:?}", apply(None, add_one_raw)); }
This is perhaps one of the most powerful concepts that functional programming has to offer: Functions taking other functions as their arguments. We call such functions higher-order functions, and we will see a lot of those in the next chapters. Here is a picture that illustrates the process of apply visually:
Of course, such a powerful function is already part of the Rust language: Option<T>::map. It is a bit more convenient to use, as it is a member function of the Option<T> type. The Rust documentation has a good example on how to use map:
#![allow(unused)] fn main() { let maybe_some_string = Some(String::from("Hello, World!")); let maybe_some_len = maybe_some_string.map(|s| s.len()); assert_eq!(maybe_some_len, Some(13)); }
Here, instead of using a named function (like we did with add_one_raw or mul_by_two), a closure is used, which is Rust's way of defining anonymous functions. Think of it as a short-hand syntax for defining functions. It is very handy together with higher-order functions like map that take other functions as arguments. Note that not every programming language allows passing functions around as if they were data. Earlier versions of Java for example did not allow this, which is why there you will see interfaces being passed to functions instead.
Besides map, which takes functions of type T -> U, there is also and_then, which takes functions that themselves can return optional values, so functions of type T -> Option<U>. Calling such a function with map would yield a return-value of type Option<Option<U>>, so a nested optional type. We often want to collapse these two Options into one, which is what and_then does.
Take some time to familiarize yourself with the API of Option<T>, as it is used frequently in Rust code!
Summary
In this chapter, we learned about the difference between product types and sum types and how we can use them to represent different sets of values. We learend that Rust has built-in support for sum types through the enum keyword, and that we can work with sum types using pattern matching using the match keyword. We learned how we can fairly easily fix the problems that null has by using a sum type called Option<T>. We also saw how sum types are represented on the hardware.
In the next section, we will build on this knowledge and look at another powerful abstraction: Iterators.
4.2. Iterators
In the previous chapter, we talked about an abstraction (Option<T>) that lets us deal with two situations: We either have one value of a certain type, or we have zero values. While this something/nothing dichotomy is important - computers work with only two states (zero and one) after all - as programmers we almost always want to work with more than one value of a type. In this chapter we will learn about the concept of iterators, which is an abstraction over multiple values of a type. The iterator abstraction is one of the key pieces that made the C++ standard template library (STL) so successful, because it maps very well onto hardware. Besides learning what iterators are, we will see how C++ and Rust differ in their approach to this abstraction.
What is iteration?
Iteration is one of the first concepts that is taught to new programmers. The notion of doing the same thing multiple times is one of the cornerstones of computer science and the reason why computers are so successful, since they exceed at repetition. Many of the most fundamental operations in computer science rely on iteration: Counting, searching, sorting, to name just a few. The name 'iteration' comes from the latin word 'iterare', which translates as 'to repeat'.
If you learned a language such as C, C++, or Java, the basic language primitive for iteration is the for-loop, which can be described as 'doing something as long as a condition holds'. A simple implementation for calculating the sum of the first N natural numbers in C++ can be realized with a for-loop:
int sum(int n) {
int summand = 0;
for(int i = 1; i <= n; ++i) {
summand += i;
}
return summand;
}
We can translate this loop into a series of instructions in the english language:
- Initialize the variable
iwith the value1 - As long as
iis less than or equal ton:- Add
ionto the variablesummand - Add
1toi
- Add
Remember back to chapter 2, when we talked about programming paradigms? This is the imperative programming paradigm: A simple series of step-by-step instructions. There is nothing wrong with this way of programming, it maps very well onto computer hardware, but less well onto the way most people think, especially before they learn programming.
A different way of thinking about this problem is to restate it. What is the sum of the first N natural numbers? It is a special combination of the set of natural numbers \(\{1, 2, ..., N\}\), namely the addition of all its elements. The algorithm to compute this sum could be states as:
Starting with a sum of zero, for each element in the set \(\{1, 2, ..., N\}\), add this element to the sum.
Now instead of an imperative program, we have a declarative program, where we state what we want to do, not how it is done. Notice that we now deal with a collection of elements (the set of natural numbers up to and including N), and this algorithm involes iterating over all elements of this set! This is different from the for-loop that we had before. The for-loop stood for 'do something while a condition holds', now we have 'do something with each element in a collection'. Let's try to express this with C++ code:
int sum(const std::vector<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
The code is pretty similar to what we had before, but now we iterate over the elements in a collection (std::vector in this case). Naturally, the next step would be to make this code more generic. The algorithm that we described above does not really care what memory layout we use to store the numbers, so it should work with arbitrary collections. Let's try a linked-list:
int sum(const std::list<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
Unfortunately, this example does not compile! The problem here is that our implementation did make an assumption regarding the memory layout of the collection: We used operator[] to access elements by their index within the collection. But this requires that our collection provides random access in constant time. std::vector has random access, because it is just a linear array of values internally, but the whole point of a linked-list is that its elements are linked dynamically, so there is no way to index an element in constant time. Other collections don't even have the notion of an index. A set for example is - by definition - unordered, it only matters whether an element is part of the set or not, its position in the set is irrelevant.
But we can still iterate over the elements in a linked-list in C++:
int sum(const std::list<int>& numbers) {
int summand = 0;
for(auto number : numbers) {
summand += number;
}
return summand;
}
Here we are using the range-based for loop syntax that was introduced with C++11. In other languages, this is sometimes called a for-each loop, which describes pretty well what it does: It does some action for each element in a collection. But to realize this loop, the compiler has to know the memory layout and other details of the actual collection. Random-access collections such as std::vector can access elements using simple pointer arithmetic, a linked-list however requires chasing the link pointers. So what we really want is an abstraction for the concept of iteration. Enter iterators.
Iterators in C++
The C++ STL defines the concept of an iterator, which is any type that satisfies a set of operations that can be performed with the type. While there are many different variations of the iterator concept in C++, all iterators share the following three capabilities:
- They are comparable: Given two iterators
aandb, it is possible to determine whether they refer to the same element in a collection or not - They can be dereferenced: Given an iterator
a, it is possible to obtain the element thatacurrently refers to - They can be incremented: Given an iterator
a, it is possible to advanceato the next element
With these three capabilities, the concept of iteration is pretty well defined. Let's assume for a moment that we have some type Iterator<T> that we can obtain from a collection such as std::vector<T>. How would we write code with this type? Let's try something:
// Does not compile, just an example
int sum(const std::list<int>& numbers) {
int summand = 0;
for(
Iterator<T> iter = get_iterator(numbers);
???;
iter.advance()
) {
int number = iter.current();
summand += number;
}
return summand;
}
We can implement most things that are needed, in particular advancing it to the next element and obtaining the current element. But how do we know that we have reached the end of our iterator? There are several ways to do this, which will result in slightly different iterator abstractions:
- We can give our iterator a method
bool is_at_end()that we can call to determine whether we are at the end or not - We can compare out iterator against a special iterator that points to the end of the collection
Before reading on, what advantages and disadvantages do these two approaches have? Would you prefer one over the other?
C++ went with the second approach, while Rust went with the first. We will first examine the C++ approach and then move on to the Rust approach.
Since our C++ iterator has the ability to be compared to another iterator, if we can get an iterator that represents the end of our collection, we can rewrite our code like so:
// Does not compile, just an example
int sum(const std::list<int>& numbers) {
int summand = 0;
for(
Iterator<T> start = get_start(numbers), Iterator<T> end = get_end(numbers);
start != end;
start.advance()
) {
int number = start.current();
summand += number;
}
return summand;
}
This is exactly what the range-based for loop syntax in C++ does internally! The methods for getting the start and end iterators are called begin and end in C++ and are available on all collections in the STL. So every collection that provides begin and end methods can be used with the for(auto x : collection) syntax, thanks to the iterator abstraction. The return type of the begin and end expressions will depend on the type of collection, so there is no single Iterator<T> type in C++, only a bunch of specialized types that all satisfy the three conditions (comparable, dereferencable, incrementable) that we defined earlier.
To understand how exactly begin and end behave, we can look at a picture of an array:
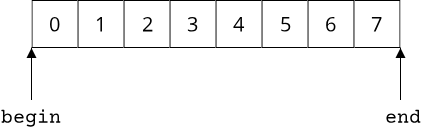
The position of the begin iterator is trivial: It points to the first element of the array, so that it can immediately be dereferenced to yield the first element. The end iterator is a bit more challenging. It must not point to the last element, because then the check begin != end in our for-loop would be wrong, causing the loop to terminate before the last element instead of after the last element. So end has to point to the element after the last element. This is not a valid element, so we must never dereference the end iterator, but using it in a comparison is perfectly valid.
Together, the begin and end iterator define what is known as a range in the C++ world, which is the jargon for any sequence of elements that can be iterated over. The following image illustrates how iterators can be used to iterate over an array with 3 values:
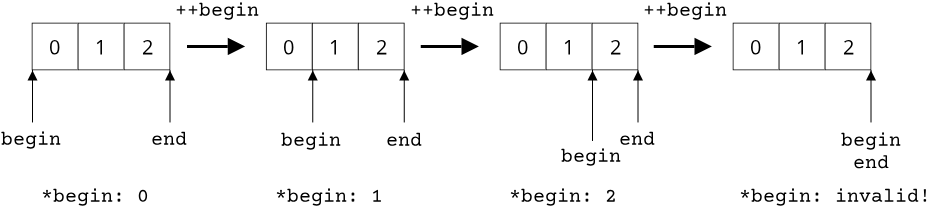
Examples of iterators in C++
So what types are iterators? The simplest type of iterator is a pointer. Iterating over the elements in an array can be achieved with a pointer, because the pointer supports all necessary operations:
int main() {
int values[] = {1, 2, 3, 4, 5};
int* begin = values;
int* end = values + 5;
for(; begin != end; ++begin) {
std::cout << *begin << std::endl;
}
return 0;
}
We can increment a pointer, which in C++ advances the pointer by however many bytes its type takes up in memory. For an array of type T, the elements are all sizeof(T) large and thus start at an offset that is N*sizeof(T) from the start of the array. So simply calling operator++ on a T* moves us to the right offsets, given that we started at the beginning of the array. Comparing pointers is easy as well, as pointers are just numbers. Lastly, dereferencing a pointer is what we are doing all the time to get access to the value at its memory location. So pointers are iterators.
What collections can we iterate over with a pointer? Arrays work, since they are densely packed, and in theory std::vector would also work (but in practice std::vector defines its own iterator type). In general, pointers are valid iterators for any collection whose elements are densely packed in memory. We call such a collection a contiguous collection. Built-in arrays, std::vector, std::array, std::basic_string (the actual type of std::string) as well as std::basic_string_view are all examples of contiguous collections.
We already saw std::list, a doubly-linked list, as an example for a non-contiguous collection. We can access the elements of std::list using a pointer during iteration, however we can't use operator++ on this pointer, as the elements of std::list are not guaranteed to be adjacent in memory:
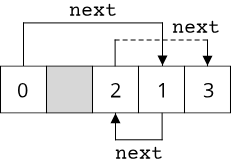
Incrementing the iterator for a std::list means chasing a pointer to the next link. So for iteration over std::list, we have to define a custom iterator type that encapsulates this behaviour:
template<typename T>
struct list {
struct node {
T val;
node* next;
node* prev;
};
//...
};
template<typename T>
struct list_iterator {
list_iterator& operator++() {
_current = _current->next;
return *this;
}
T& operator*() {
return *_current;
}
bool operator!=(const list_iterator& other) const {
return _current != other._current;
}
private:
typename list<T>::node* _current;
};
In C++, such an iterator is called a forward iterator, because we can use it to traverse a collection in forward-direction from front to back. Naturally, there should also be an iterator to traverse a collection in the opposite direction (back to front). As moving in the forward direction is achieved through operator++, moving backwards is achieved through operator--. An iterator that supports moving backwards using operator-- is called a bidirectional iterator. We could adapt our list iterator to also support iterating backwards:
template<typename T>
struct list_iterator {
list_iterator& operator++() {
_current = _current->next;
return *this;
}
list_iterator& operator--() {
_current = _current->prev;
return *this;
}
T& operator*() {
return *_current;
}
bool operator!=(const list_iterator& other) const {
return _current != other._current;
}
private:
typename list<T>::node* _current;
};
Corresponding to the begin and end functions, which returned an iterator to the first and one-after-last element respectively, when we want to iterate over a collection in reverse order, we can use the rbegin and rend functions. rbegin will point to the last element in the collection, rend to the element before the first element:
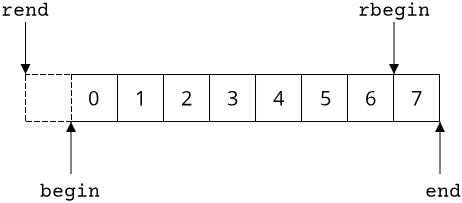
Iterators without collections
All the iterators that we have seen thus far always pointed to memory within a collection. There are situations where this is not desireable or simply not needed. Remember back to our initial method for calculating the sum of the first N natural numbers:
int sum(int n) {
int summand = 0;
for(int i = 1; i <= n; ++i) {
summand += i;
}
return summand;
}
This code is quite memory-efficient: At no point during the computation do we have to store all N numbers in memory. Switching to iterators introduced this requirement:
int sum(const std::vector<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
Here we have to pass in a std::vector which has to store in memory all the numbers that we want to sum. It would be nice if we could define iterators that don't point to memory inside a collection, but simply generate their elements on the fly, just as the naive for-loop does it. Such iterators are called input iterators and output iterators in C++. An input iterator only supports reading values, whereas an output iterator only supports writing values. Both iterator types are single-pass iterators, which means that we can only use them once, as opposed to the iterators pointing to collections, which can be re-used as often as we want.
Since input iterators are able to generate values on the fly, dereferencing will generally return a raw value (T) instead of a reference (T&). Let's try to write an input iterator for iterating over a sequence of adjacent numbers (an arcane procedure sometimes known as counting):
struct CountingIterator {
explicit CountingIterator(int start) : _current(start) {}
CountingIterator& operator++() {
++_current;
return *this;
}
bool operator!=(const CountingIterator& other) const {
return _current != other._current;
}
int operator*() {
return _current;
}
private:
int _current;
};
To make this usable, we need some type that provides begin and end functions which return our CountingIterator type, so let's write one:
struct NumberRange {
NumberRange(int start, int end) : _start(start), _end(end) {}
CountingIterator begin() const {
return CountingIterator{_start};
}
CountingIterator end() const {
return CountingIterator{_end + 1};
}
private:
int _start, _end;
};
We can use these two types to rewrite our initial code to work with iterators that don't belong to any collection:
int main() {
int sum = 0;
for(auto num : NumberRange(1, 100)) {
sum += num;
}
std::cout << sum << std::endl;
return 0;
}
If you ever wrote code in Python, this syntax might look familiar, since Python does not have an index-based for-loop:
for number in range(100):
print(number)
Iterators in Rust
Now let's take a look at how Rust handles iterators. We already saw that C++ uses a stateless approach to iterators, where the iterator instance itself does not know whether it is at the end of its underlying range or not. Rust goes a different route: Iterators in Rust do know once they have reached the end of the underlying range. Instead of defining the iterator capabilities in terms of its supported operators, Rust defines a trait called Iterator. The definition of Iterator is very simple:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; } }
Here we first encounter the concept of associated types, which are useful to let implementors of a trait communicate extra type information to users of the trait. In the case of Iterator, implementors of Iterator have to declare what type of items the iterator yields.
Rust then collapses all requirements for an iterator into a single method called next(). It returns an Option<Self::Item>, so either the next item of the underlying range, or a None value to indicate that the end of the range has been reached. Since next() takes a &mut self parameter, calling next() will mutate the iterator. Since Rust iterators communicate whether or not they have reached the end through the next() method, Rust iterators are stateful. This also means that iterator instances are not reusable in Rust!
Depending on who you ask, people might say that the way Rust handles iteration is closer to what the word 'Iterator' actually means, and that the C++ approach is more like a 'Cursor' since it contains no real state about the underlying range. We will refer to both C++ and Rust iterators simply by the term 'Iterator', as this is what is used in the respective documentation for both languages. Both abstractions are also known as external iteration, since the process of iterating over the range is controlled by an external object, not the range (or collection) itself.
C++ had the begin and end methods to obtain iterators for a collection or range. Since Rust iterators hold all necessary state in a single object, in Rust we don't need iterator pairs to represent ranges, and consequently don't need two methods to obtain iterators for a collection. Instead, Rust collections typically provide an iter() method that returns a new iterator instance. Just as C++, Rust provides built-in support for iterating over an iterator using a for loop:
pub fn main() { let numbers = vec![1, 2, 3, 4]; for number in numbers.iter() { println!("{}", number); } }
This could be the end of the story and we could move on to the next chapter, looking at the cool things we can do with iterators. Alas, Rust has strict lifetime rules, and they can become complicated when it comes to iterators. So we will take some time to understand how iterators and lifetimes play together before we can move on!
Rust iterators and lifetimes
To understand the problems with iterators and lifetimes in Rust, we will try to implement our own iterator for the Vec<T> type.
Vec<T> implements all of this already, but doing it ourselves is quite enlightening.
We start with a custom iterator type:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<T> { vec: &Vec<T>, } }
Since Rust iterators need to know when they have reached the end of their underlying range, we borrow the Vec<T> type inside the iterator. You already learned that borrows in structs require explicit lifetime annotations, so let's do that:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<'a, T> { vec: &'a Vec<T>, } }
Now we can implement the Iterator trait on our new type:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIter<'a, T> { type Item = &'a T; fn next(&mut self) -> Option<Self::Item> { todo!() } } }
The first thing we have to decide is what type our iterator yields. We could simply yield T by value, but then we would have to constrain T to be Copy, otherwise iterating over the collection would move the elements out of the vector. So instead we can return a borrow of the current element: &T. Surely this borrow can't outlive the vector, so its full type is &'a T.
How can we implement next()? For this, we have to keep track inside our MyAwesomeVecIter type where in the Vec we currently are. Since we know that our Vec type has contiguous memory, we can simply use an index for this:
#![allow(unused)] fn main() { struct MyAwesomeVecIter<'a, T> { vec: &'a Vec<T>, position: usize, } impl <'a, T> MyAwesomeVecIter<'a, T> { fn new(vec: &'a Vec<T>) -> Self { Self { vec, position: 0, } } } }
Implementing next() is easy now:
#![allow(unused)] fn main() { fn next(&mut self) -> Option<Self::Item> { if self.position == self.vec.len() { None } else { let current_element = &self.vec[self.position]; self.position += 1; Some(current_element) } } }
This iterator is useable now:
pub fn main() { let numbers = vec![1,2,3,4]; for number in MyAwesomeVecIter::new(&numbers) { println!("{}", number); } }
That was fairly easy to implement. Let's try something more interesting: Mutating values through an iterator! Since in Rust, iterators are tied to the type of item that they yield, we need a new type to iterate over mutable borrows:
#![allow(unused)] fn main() { struct MyAwesomeVecIterMut<'a, T> { vec: &'a mut Vec<T>, position: usize, } impl <'a, T> MyAwesomeVecIterMut<'a, T> { fn new(vec: &'a mut Vec<T>) -> Self { Self { vec, position: 0, } } } }
It's basically the same type as before, but since we want to mutate the values, we have to borrow the underlying Vec<T> as mut. Now to implement Iterator on this type:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> { type Item = &'a mut T; fn next(&mut self) -> Option<Self::Item> { if self.position == self.vec.len() { None } else { let current_element = &mut self.vec[self.position]; self.position += 1; Some(current_element) } } } }
Nothing much changed besides a few mut keywords that we had to add. Unfortunately, this code does not compile, and what an error message we get:
error[E0495]: cannot infer an appropriate lifetime for lifetime parameter in function call due to conflicting requirements
--> src/chap4_iter.rs:52:40
|
52 | let current_element = &mut self.vec[self.position];
| ^^^^^^^^^^^^^^^^^^^^^^^
|
note: first, the lifetime cannot outlive the anonymous lifetime defined on the method body at 48:13...
--> src/chap4_iter.rs:48:13
|
48 | fn next(&mut self) -> Option<Self::Item> {
| ^^^^^^^^^
note: ...so that reference does not outlive borrowed content
--> src/chap4_iter.rs:52:40
|
52 | let current_element = &mut self.vec[self.position];
| ^^^^^^^^
note: but, the lifetime must be valid for the lifetime `'a` as defined on the impl at 45:7...
--> src/chap4_iter.rs:45:7
|
45 | impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> {
| ^^
note: ...so that the types are compatible
--> src/chap4_iter.rs:48:46
|
48 | fn next(&mut self) -> Option<Self::Item> {
| ______________________________________________^
49 | | if self.position == self.vec.len() {
50 | | None
51 | | } else {
... |
55 | | }
56 | | }
| |_____^
= note: expected `Iterator`
found `Iterator`
The problem is that we take a mutable borrow inside the next() method to something that belongs to self. next() itself takes a mutable borrow to self, which defines an anonymous lifetime. If we were to give this lifetime a name, it would look like this: fn next<'b>(&'b mut self). But next must return a borrow that is valid for the lifetime 'a. The Rust compiler has no way of figuring out whether 'a and 'b are related, so it complains that these two lifetimes are incompatible.
Ok, simple enough, let's just constraint the &mut self borrow with our 'a lifetime:
#![allow(unused)] fn main() { impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> { type Item = &'a mut T; fn next(&'a mut self) -> Option<Self::Item> { //... } } }
But this also does not compile:
error[E0308]: method not compatible with trait
--> src/chap4_iter.rs:48:5
|
48 | fn next(&'a mut self) -> Option<Self::Item> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ lifetime mismatch
|
= note: expected fn pointer `fn(&mut MyAwesomeVecIterMut<'a, T>) -> Option<_>`
found fn pointer `fn(&'a mut MyAwesomeVecIterMut<'a, T>) -> Option<_>`
note: the anonymous lifetime #1 defined on the method body at 48:5...
--> src/chap4_iter.rs:48:5
|
48 | fn next(&'a mut self) -> Option<Self::Item> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
note: ...does not necessarily outlive the lifetime `'a` as defined on the impl at 45:7
--> src/chap4_iter.rs:45:7
|
45 | impl <'a, T> Iterator for MyAwesomeVecIterMut<'a, T> {
| ^^
Because the signature of the next() method is given by the Iterator trait, and it expects an anonymous lifetime parameter. Unfortunately, this is the end of our effort to implement a mutable iterator on Vec<T>: The lifetime rules of Rust, together with the definition of the Iterator trait make it impossible to implement a mutable iterator using only safe Rust. If we take a look at the mutable iterator for Vec<T>Which is actually an iterator over a mutable slice &mut [T], we will see that it uses raw pointers internally to circumvent the lifetime requirements:
#![allow(unused)] fn main() { pub struct IterMut<'a, T: 'a> { ptr: NonNull<T>, end: *mut T, _marker: PhantomData<&'a mut T>, } }
Instead of arguing whether this is a good idea or not, we will instead conclude this chapter by understanding why Rust's lifetime guarantees actually require Rust iterators to be stateful.
Why Rust iterators are stateful
C++ iterators are neat because they are so light-weight, both in terms of the data that an iterator instance stores as well as the information that it carries with it about the source container. We saw that pointers are valid iterators in C++, and pointers are very simple data types. This simplicity however comes with a cost: There is more information that we as programmers have to be aware about that is not encoded in the iterator type. Take a look at the following code:
#include <iostream>
#include <vector>
template<typename T>
void print_range(T begin, T end) {
for(; begin != end; ++begin) {
std::cout << *begin << std::endl;
}
}
int main() {
std::vector<int> numbers{1,2,3,4};
auto begin = std::begin(numbers);
auto end = std::end(numbers);
//Ah forgot to add something to 'numbers'!
numbers.push_back(42);
print_range(begin, end);
return 0;
}
In this code, we have a collection of numbers, obtain the necessary begin and end iterators from it and want to print the numbers using the iterators. Before we call the print_range function however, we add another number into the collection. A possible output of this code looks like this:
0
0
22638608
0
(But successful program termination!)
What went wrong here? Simple: We violated one of the invariants for the iterators of the std::vector type! We manipulated the std::vector while holding iterators to it. If we look at the documentation for std::vector::push_back, here is what it tells us:
If the new size() is greater than capacity() then all iterators and references (including the past-the-end iterator) are invalidated. Otherwise only the past-the-end iterator is invalidated.
One of the fundamental principles of std::vector is that adding new elements can cause a reallocation of the internal memory block, to accomodate the new elements. Since the begin and end iterators for std::vector are basically pointers to the start and end of the underlying memory block, calling push_back potentially causes our iterators to point to a freed memory block. Accessing freed memory results in undefined behaviour, hence the strange program output. Since iterators in C++ have so little state attached to them, we as programmers have to track their validity - the time in which they are valid - manually.
What does this mean for the Rust programming language? The closest thing to a raw pointer in safe Rust code is a borrow (&T), but borrows have much stricter semantics than pointers. Of the three operations that C++ iterators require (comparing, dereferencing, and incrementing), Rust borrows only support one: Dereferencing. So right of the bat we are stuck since Rust does not offer a suitable primitive type that we could use for a stateless iterator. If we could somehow use borrows to elements directly, the Rust borrow checker would prevent us from modifying the collection while we hold an iterator to it:
pub fn main() { let mut numbers = vec![1,2,3,4]; let begin = &numbers[0]; let end_inclusive = &numbers[3]; numbers.push(42); println!("{}", *begin); }
The push method takes a &mut self parameter, but we can't borrow numbers as mutable since we also borrowed it as immutable in begin and end_inclusive. So even if borrows don't have the right semantics, at least they would prevent the sort of mistakes that we can make with C++ iterators.
There is another reason why stateless iterators are difficult to realize in Rust. Note that with stateless iterators, we always require two iterators to define a range of elements. For working with an immutable range, the Rust borrow rules would suffice, but what if we wanted to manipulate the values in the range? This would require at least one mutable borrow (for the begin iterator) as well as an immutable borrow (for the end iterator, which is never dereferenced), but we can't have both due to the Rust borrow rules. We could do some stuff with unsafe code, but that would defeat the purpose of these rules. So stateful iterators are the better alternative. In the next chapter, when we look at applications of iterators, we will see that stateful iterators are often simpler to work with because they are easier to manipulate.
Rust iterators and conversions
In C++, if you have a type that you want to use with e.g. a range-based for-loop, you provide the begin and end functions for this type (either as member-functions or a specialization of the free functions with the same name). It is helpful to understand how to achieve the same behaviour in Rust, which is possible through the trait IntoIterator:
#![allow(unused)] fn main() { pub trait IntoIterator { type Item; type IntoIter: Iterator; fn into_iter(self) -> Self::IntoIter; } }
It provides two associated types Item and IntoIter, as well as a single function into_iter that returns the iterator. Item is simply the type of item that the iterator will yield, so for a Vec<i32>, we would implement IntoIterator with type Item = i32Of course, Vec<T> already implements IntoIterator in the Rust standard library.. The IntoIter type is the type of iterator that your type will yield when calling into_iter. It has to implement the Iterator trait, but otherwise you are free to use whatever type you want. Here is the implementation of IntoIterator for the Vec<T> type in the Rust standard library:
#![allow(unused)] fn main() { impl<T, A: Allocator> IntoIterator for Vec<T, A> { type Item = T; type IntoIter = IntoIter<T, A>; fn into_iter(self) -> IntoIter<T, A> { // Details... } } }
So for a Vec<T>, its iterator iterates over values of type T, which makes sense. The iterator type returned is some special type IntoIter<T, A> which is implemented elsewhere. We don't really care about the implementation of this type here. into_iter then simply returns a value of this IntoIter<T, A> type.
Let's look more closely at the into_iter method: Notice that it takes the self parameter by value. This is common for conversions in Rust: The value that is converted is consumed in the conversion. This has some interesting implications when implementing IntoIterator on your own types: If you call into_iter on your type, the value of your type is consumed. This is exactly what happens when calling into_iter on Vec<T>:
pub fn main() { let vec = vec![1,2,3,4]; for val in vec.into_iter() { //simply writing 'in vec' has the same behaviour println!("{}", val); } println!("Vec has {} elements", vec.len()); }
Since into_iter consumes its self argument, we can't use the vec variable after the for loop! This is a bit unfortunate, because there are many situations were we want to obtain a read-only iterator for our type and continue to use our type afterwards. Rust allows this behaviour, but it is somewhat pedantic on how we have to express this. Since Rust is move-by-default, obtaining an iterator from a collection by value means that we also iterate over the collections elements by value. Since this moves the values out of the collection, we can't use the collection after we have obtained the iterator, since the iterator requires ownership of the collection to perform these moves. If we want to iterate not over a collection by value, but instead by reference, we have to tell Rust that we want this to be possible. We do so by implementing the IntoIterator trait for borrows of the collection:
#![allow(unused)] fn main() { impl<'a, T, A: Allocator> IntoIterator for &'a Vec<T, A> { type Item = &'a T; type IntoIter = slice::Iter<'a, T>; fn into_iter(self) -> slice::Iter<'a, T> { // Details } } }
It might seem unusual, but traits can be implemented not only on a type T, but also on borrows of T (&T), or mutable borrows (&mut T). This works because &T is a different type than T, kind of like how in C++ T and T& are different types. Since Rust uses ad-hoc polymorphism, if we have a value of type U and call into_iter on it, the compiler simply checks if there is an implementation of into_iter on the type U in the current scope. If U is &T and we have an impl IntoIterator for &T, then the into_iter call can be resolved by the compiler.
The difference between IntoIterator on Vec<T> and &Vec<T> is that we now have type Item = &'a T, which means that if we obtain an iterator over a borrow of a Vec<T>, we will iterate over borrows of the vector's values. We also have a lifetime parameter 'a here all of a sudden. This is necessary because every borrow needs an associated lifetime, and in a declaration like type Item = &T, the compiler can't figure out an appropriate lifetime, so we have to use a named lifetime 'a here. This lifetime has to be equal to the lifetime of the borrow of the Vec<T> for obvious reasons: The borrows of the elements of the Vec<T> must not outlive the Vec<T> itself. In this special case, the iterator type is slice::Iter<'a, T>, which is a type that internally stores a borrow to the vector that it iterates over, so it carries the lifetime of the Vec<T> over to its signature.
Now take a look at into_iter again: It still takes self by value, but because we now impl IntoIterator on &Vec<T>, self is a borrow as well! Borrows always implement Copy, so taking a borrow by value does not make our value unusable. This way, we can iterate over a Vec<T> by reference and still use it afterwards:
pub fn main() { let vec = vec![1,2,3,4]; for val in &vec.into_iter() { //Notice the added '&' println!("{}", val); } println!("Vec has {} elements", vec.len()); }
Naturally, the next step would be to provide an impl IntoIterator for &mut Vec<T> as well, so that we can iterate over mutable borrows to the elements of a Vec<T>. This impl exists on Vec<T> as well and looks basically identical to the impl for &Vec<T>, so we won't show it here.
This covers the conversion from a type to an iterator. Of course, sometimes we also want to go in the opposite direction: We have an iterator and want to convert it to a type. The best example for this is the collect method on the Iterator trait in Rust. We use it all the time to collect the elements of an iterator into a collection. This can be a Vec<T>, but it is also possible to collect an iterator into other collections, such as HashMap<K, V> or HashSet<T>. The signature of Iterator::collect tells us how this is possible:
#![allow(unused)] fn main() { fn collect<B>(self) -> B where B: FromIterator<Self::Item>; }
There is a special trait FromIterator that types can implement to signal that they can be constructed from an iterator. Here is the signature of the FromIterator trait:
#![allow(unused)] fn main() { pub trait FromIterator<A> { fn from_iter<T>(iter: T) -> Self where T: IntoIterator<Item = A>; } }
It provides only a single method from_iter, but this method has an interesting signature. It takes a single value of a type T, where T has to implement IntoIterator<Item = A>. A itself is a generic parameter on the FromIterator trait, and it refers to the type of item that we are collecting. So if we had a type Foo that can be constructed from values of type Bar, we would write impl FromIterator<Bar> for Foo. So why does from_iter take a generic type T and not simply a specific iterator type? The problem is that there are lots of specific iterator types. Recall the three impl statements for IntoIterator on Vec<T>, which used three different iterator types (IntoIter<T>, slice::Iter<'a, T> and slice::IterMut<'a, T>). Do we really want to tie FromIterator to any of these specific types, thus preventing all other iterator types from being used with FromIterator? This is not really an option, so instead from_iter takes a generic argument with the only constraint that this argument is convertible into an iterator over items of type A. This is a very powerful and very generic trait, which means we can write funny code like this:
#![allow(unused)] fn main() { let v1 = vec![1,2,3,4]; let v2 = Vec::<i32>::from_iter(v1); }
Which is (almost) identical to writing:
#![allow(unused)] fn main() { let v1 = vec![1,2,3,4]; let v2 = v1; }
Can you figure out what the difference between these two examples is?
To conclude, the two traits IntoIterator and FromIterator are quite useful to enable conversions between collections and iterators. If you want to make a custom type iteratable, consider implementing IntoIterator. If you want to create an instance of a custom type from an iterator, consider implementing FromIterator.
Summary
In this chapter, we learned about the concept of iterators, the abstraction for dealing with ranges of things in many programming languages. We learned how iterators work in C++ through a set of simple operations: compare, dereference, increment. We saw that iterators can be both for collections of values in memory, as well as for ranges that are calculated on the fly. We then saw how Rust handles iterators differently to C++: C++ iterators come in pairs and are mostly stateless, Rust iterators are single objects that are stateful.
4.3. Algorithms
In this chapter, we will look at the many applications of iterators. Iterators are one of these abstractions that have found their way into basically all modern programming languages, simply because they are so powerful, making it easy to write maintainable code that clearly states its intent. The concepts of this chapter are equally well suited for systems programming and applications programming.
Algorithms give names to common tasks
Iterators are an abstraction for the concept of a range of values. Working with ranges is one of the most fundamental operations that we as programmers do. It turns out that many of the things that we want to do with a range of values are quite similar and can be broken down into a set of procedures that operate on one or more iterators. In the programming community, these procedures are often simply called algorithms, which of course is a label that fits to any kind of systematic procedure in computer science. In a sense, the algorithms on iterators are among the simplest algorithms imaginable, which is part of what makes them so powerful. They are like building blocks for more complex algorithms, and they all have memorable names that make it easy to identify and work with these algorithms. We will learn the names of many common algorithms in this chapter, for now let's look at a simple example:
pub fn main() { let numbers = vec![1,2,3,4]; for number in numbers.iter() { println!("{}", number); } }
This code takes an iterator to a range of values and prints each value to the standard output. A very simple program, and an example of the first algorithm: for_each. Rust has built-in support for the for_each algorithm using for loops, which is why perhaps this might not feel like an algorithm at all. We simply wrote a loop after all. And indeed, there is one step missing to promote this code to one of the fundamental algorithms on iterators. Algorithms on iterators are always about finding common behaviour in programs and extracting this behaviour into a function with a reasonable name. So let's write a more complicated function to see if we can find some common behaviour:
pub fn main() { let numbers = vec![2, 16, 24, 90]; for number in numbers.iter() { let mut divisor = 2; let mut remainder = *number; while remainder > 1 { if (remainder % divisor) == 0 { print!("{} ", divisor); remainder = remainder / divisor; } else { divisor += 1; } } println!(); } }
This piece of code prints all prime factors for each number in a range of numbers. Disregarding that the numbers are different, what has changed between this example and the previous example? We can look at the code side-by-side:
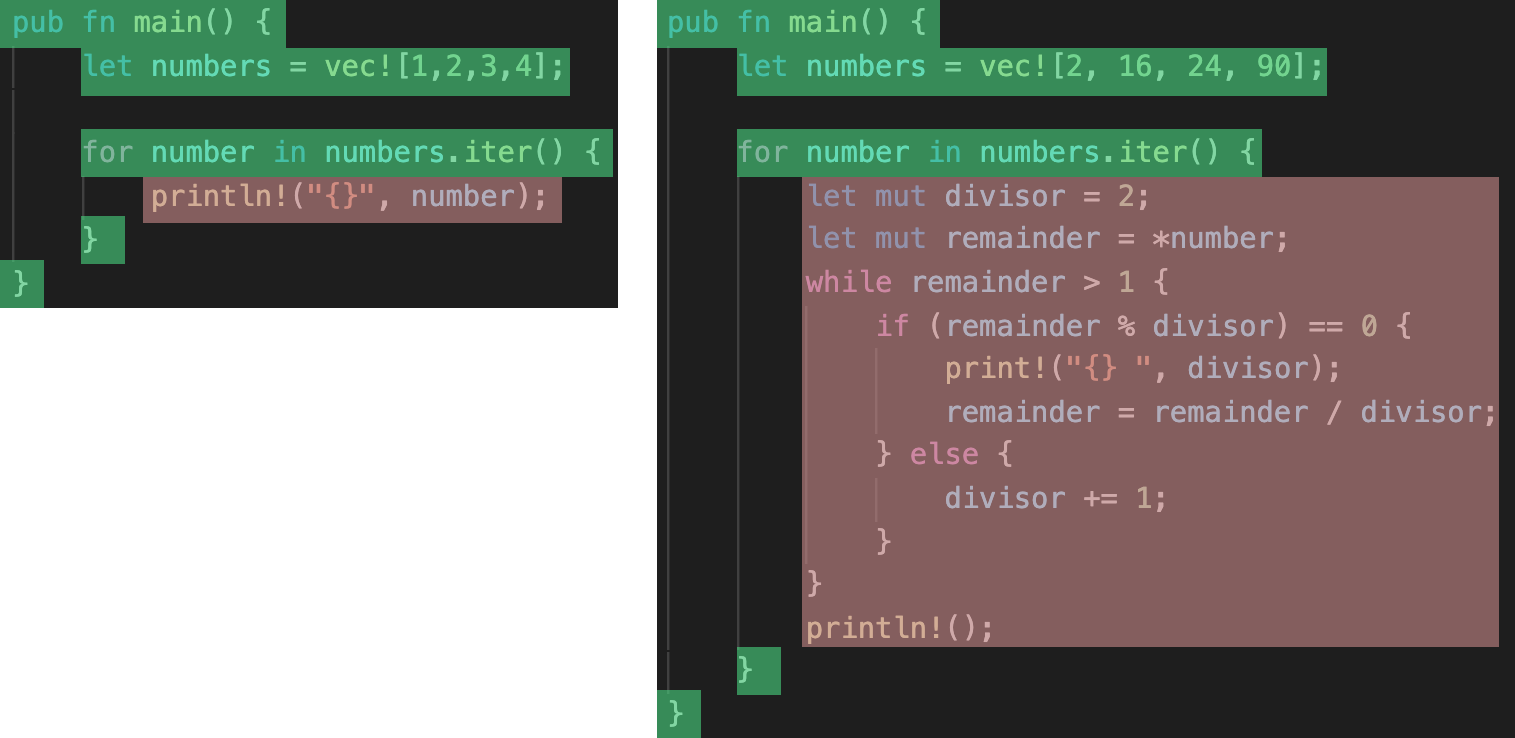
The only thing that is really different is the body of the loop. This is the operation that we want to apply for each value in the range. To clean up the loop in the second example, we could extract the loop body into a separate function print_prime_divisors:
fn print_prime_divisors(number: i32) { let mut divisor = 2; let mut remainder = number; while remainder > 1 { if (remainder % divisor) == 0 { print!("{} ", divisor); remainder = remainder / divisor; } else { divisor += 1; } } println!(); } pub fn main() { let numbers = vec![2, 16, 24, 90, 72, 81]; for number in numbers.iter() { print_prime_divisors(*number); } }
Now the two examples look very much alike, the only different is that one example uses the println! macro in the loop body and the other example calls the print_prime_divisors function. Now it becomes apparent what the idea of the for_each algorithm is: for_each applies a function to each element in a range! We could write a function named for_each that encapsulates all the common code of the last examples:
fn for_each<T, U: Iterator<Item = T>, F: Fn(T) -> ()>(iter: U, f: F) { for element in iter { f(element); } } pub fn main() { let numbers = vec![2, 16, 24, 90, 72, 81]; for_each(numbers.into_iter(), print_prime_divisors); }
The signature of the for_each function is a bit complicated, because of all the constraints that we have to enforce on our types. Let's try to unmangle it:
fn for_each<T is simple: A function that iterates over any possible value, hence the unconstrained type T. U: Iterator<Item = T> tells our function that it accepts any type U that implements the Iterator trait with the Item type set to T. This is Rusts way of saying: Any type that iterates over values of type T. Lastly, F: Fn(T) -> () encapsulates the function that we want to apply to each element in the range. Since this function has to be able to accept values of type T, we write Fn(T). We also don't care about a possible return value of the function (since it is discarded anyways), so we require that our function does not return anything: -> (). The function arguments then indicate a value of the iterator type U (iter: U) and a function (f: F).
We can call this for_each function with any iterator and matching function. We have to use into_iter() here, because the iterator returned from calling iter() on a Vec<i32> iterates over borrows to each element (&i32), but our print_prime_divisors function takes a number by value (i32). into_iter() instead returns an iterator that iterates over the raw values.
It is also possible to visualize the for_each algorithm schematically:
Now, we called our for_each function with two arguments: The iterator and the function to apply. Sometimes the function call syntax (a.b()) is easier to read, so it would be nice if we could apply to for_each function directly to a range: range.for_each(do_something). It turns out that this is rather easy when using stateful iterators as Rust does! If the iterator itself were to provide the for_each method, we could call it in such a way. We would have to provide for_each for all types that are iterators in Rust though. Luckily, all iterator types in Rust implement the Iterator trait, so into this trait is where the for_each method should go. Of course, Iterator already defines for_each (along with tons of other helpful methods that we will learn about shortly):
pub fn main() { let numbers = vec![2, 16, 24, 90, 72, 81]; numbers.into_iter().for_each(print_prime_divisors); }
The signature of Iterator::for_each is worth investigating:
fn for_each<F>(self, f: F) where F: FnMut(Self::Item)
Notice that it takes the self parameter by value, not as a mutable borrow as one might expect. This is because for_each consumes the iterator. Once we have iterated over all elements, we can't use the iterator anymore, so we have to make sure that no one can access the iterator after calling for_each. This is done by taking the self parameter by value, a neat trick that Rust allows to define functions that consume the value that they are called on.
You might have noticed that Rust is lacking the typical for loop that many other languages have, where you define some state, a loop condition and statements for updating the state in every loop iteration. for(int i = 0; i < 10; ++i) {} is not available in Rust. With iterators and for_each, we can achieve the same result, using a special piece of Rust syntax that enables us to create number-ranges on the fly:
pub fn main() { (0..10).for_each(|idx| { println!("{}", idx); }); // Which is equivalent to: for idx in 0..10 { println!("{}", idx); } }
The algorithms zoo
As mentioned, there are many algorithms in the fashion of for_each. In Rust, many interesting algorithms are defined on the Iterator trait, and even more can be found in the itertools crate. Even though C++ does not have a common base type for iterators, it also defines a series of algorithms as free functions which accept one or multiple iterator pairs. In C++, these algorithms reside in the <algorithm> header. It is also worth noting that C++ got an overhauled iterators and algorithms library with C++20, called the ranges library. The study of the ranges library is fascinating, as it enables many things that were lacking in the older algorithms, however in this lecture we will not go into great detail here and instead focus on the corresponding algorithms in Rust.
We will look at many specific algorithms on iterators in the next sections, but before we dive into them we will first look at a rough classification of the types of algorithms on iterators that we will encounter in Rust. For C++, there is already a nice classification by Jonathan Boccara called The World Map of C++ STL Algorithms, which is worth checking out. He groups the C++ algorithms into 7 distinct families and we will do something quite similar for the Rust algorithms on iterators.
Eager and lazy iteration
At the highest level, there are two types of algorithms: Eager algorithms and lazy algorithms. Since Rust iterators are stateful, we have to do something with them (i.e. call the next() function on them) so that computation happens. For iterators that point into a collection of elements, this distinction seems to be pedantic, but we already saw iterators that generate their elements on the fly, such as the C++ NumberRange iterator that we wrote in the last chapter, and the number-range syntax (0..10) in Rust. The actual computation that generates the elements happens at the moment of iteration, that is whenever we call next() on the iterator. We call an iterator that does not compute its results right away a lazy iterator, and an iterator that computes its elements before we ever use it an eager iterator. This distinction becomes important when the amount of work that the iterator has to perform grows. Think back to this example that we saw in the last chapter:
int sum(const std::vector<int>& numbers) {
int summand = 0;
for(size_t idx = 0; idx < numbers.size(); ++idx) {
summand += numbers[idx];
}
return summand;
}
Here we used a container to store numbers that we then wanted to sum. We later saw that we could achieve something similar with an iterator that generates the elements on the fly. Using a container that has to store all numbers before we actually calculate our sum is a form of eager iteration; using the NumberRange type that generates the numbers on the fly is an example of lazy iteration. In the limit, lazy iterators enable us to work with things that you wouldn't normally expect a computer to be able to handle, for example infinite ranges. The Rust number-range syntax enables us to define half-open ranges by only specifying the start number. This way, we can create an (almost) infinite range of numbers, far greater at least than we could keep in memory:
pub fn main() { for number in 2_u64.. { if !is_prime(number) { continue; } println!("{}", number); } }
The syntax 2_u64.. generates a lazy iterator that generates every number from 2 up to the maximum number that fits in a u64 value, which are about \(1.84*10^{19}\) numbers. If we were to store all those numbers eagerly, we would need \(8B*1.84*10^{19} \approx 1.47*10^{20}B = 128 EiB\) of memory. 128 Exbibytes of working memory, which is far beyond anything that a single computer can do today. At the moment of writing, the most powerful supercomputer in the world (Fugaku) has about 4.85 Petabytes of memory, which is less than a thousandth of what our number-range would need. With lazy iteration, we can achieve in a single line of code what the most powerful computer in the world can't achieve were we to use eager iteration.
Algorithms grouped into eager and lazy
Since Rust iterators are lazy, we have to evaluate them somehow so that we get access to the elements. A function that takes a lazy iterator and evaluates it is called an eager function. for_each is such an eager function, as it evaluates the iterator completely. Other examples include last (to get the last element of a range) or nth (to get the element at index N within the range). The fact that some algorithms are eager raises the question if all algorithms are eager. It turns out that many algorithms are not eager but lazy themselves, and that these lazy algorithms are among the most useful algorithms. But how can an algorithm be lazy?
Simply put, lazy algorithms are algorithms that take an iterator and return another iterator that adds some new behaviour to the initial iterator. This is best illustrated with an example. Rember back to our example for printing the prime factors for a range of numbers. Here we had a range of numbers (an iterator) and a function that calculated and printed the prime factors for any positive number. Wouldn't it be nice if we had an iterator that yielded not numbers themselves, but the prime factors of numbers? We could write such an iterator:
#![allow(unused)] fn main() { struct PrimeIterator<I: Iterator<Item = u64>> { source_iterator: I, } }
First, we define a new iterator PrimeIterator, which wraps around any Iterator that yields u64 values. Then, we have to implement Iterator for PrimeIterator:
#![allow(unused)] fn main() { impl <I: Iterator<Item = u64>> Iterator for PrimeIterator<I> { type Item = Vec<u64>; fn next(&mut self) -> Option<Self::Item> { self.source_iterator.next().map(get_prime_divisors) } } }
Our PrimeIterator will yield a Vec<u64>, which will contain all prime factors for a number. We can then take the code that we had for calculating and printing the prime divisors of a number and modify it so that it only calculates the prime divisors and stores them in a Vec<u64>. We can then use the map method of the Option<T> type that we already know to apply this new get_prime_divisors method to the result of a single iteration step of the source iterator. And that's it! We now have an iterator that yields prime factors:
fn main() { for prime_divisors in PrimeIterator::new(20..40) { println!("{:?}", prime_divisors); } }
Notice that the implementation of Iterator for our PrimeIterator was very simple. The only specific code in there was the Item type (Vec<u64>) and the function that we passed to map (get_prime_divisors). Notice that the Item type is actually defined by the return type of the get_prime_divisors function. If we could somehow 'extract' the return type of the function, we could make our PrimeIterator so generic that it could take any function with the signature u64 -> U. If we would then add a second generic parameter to the PrimeIterator type that defines the items of the source_iterator, we would end up with something like an adapter that can turn any Iterator<Item = T> into an Iterator<Item = U>, given a suitable function T -> U. Does this sound familiar to you?
This is exactly what the map function for Option<T> does, but for iterators! On Option<T>, map had the signature (Option<T>, T -> U) -> Option<U>, and we now defined a function (Iterator<Item = T>, T -> U) -> Iterator<Item = U>. It would make sense to name this function map as well. Lo and behold, the Iterator trait already defines this function: Iterator::map. Schematically, it looks almost identical to Option::map:
Compared to for_each, map is a lazy algorithm: It returns a new lazy iterator, the function T -> U is only called if this new iterator is evaluated (i.e. its elements are accessed by calling next). Besides map, there are many other lazy algorithms, such as filter, chain or enumerate. In the Rust standard library, these algorithms can be identified because they return new iterator types. map for example returns the special Map<I, F> iterator type.
Queries: The first specific group of algorithms
Now that we know about the difference between lazy and eager algorithms, we can look at the first group of useful algorithms called the query algorithms. Wikipedia defines a query as a precise request for information retrieval, which describes the query algorithms quite well. A query algorithm can be used to answer questions about a range of elements.
A quick primer on predicate functions
The question to ask is typically encoded in a so-called predicate function, which is a function with the signature T -> bool. The purpose of a predicate is to determine whether a value of type T is a valid answer for a specific question. In one of the examples in this chapter, we used a function fn is_prime(number: u64) -> bool to determine whether a specific u64 value is a prime number or not. is_prime is a predicate function! Predicate functions are often pure functions, which means that they have no side-effects. A pure function will give the same result when called repeatedly with the same arguments. is_prime(2) will always return true, so it is a pure function. Pure functions are nice because they are easy to understand and, since they have no side-effects, easy to handle in code. If we can encode a specific question with a predicate function and make it pure, we often end up with nice, readable, and safe code.
The actual query algorithms
These are the query algorithms that are available on the Iterator trait:
allwith the signature(Iterator<Item = T>, T -> bool) -> bool: Do all elements in the given range match the predicate?anywith the signature(Iterator<Item = T>, T -> bool) -> bool: Is there at least one element in the given range that matches the predicate?filterwith the signature(Iterator<Item = T>, T -> bool) -> Iterator<Item = T>: Returns a new iterator which only yields the elements in the original iterator that match the predicate.filter_mapwith the signature(Iterator<Item = T>, T -> Option<U>) -> Iterator<Item = U>: Combinesfilterandmap, returning only the elements in the original iterator for which the predicate returnsSome(U).findwith the signature(Iterator<Item = T>, T -> bool) -> Option<T>: Returns the first element in the original iterator that matches the predicate. Since there might be zero elements that match, it returnsOption<T>instead ofT.find_mapwith the signature(Iterator<Item = T>, T -> Option<U>) -> Option<U>: Likefilter_map, combinesfindandmap, returning the first element in the original iterator for which the predicate returnsSome(U), converted to the typeU.is_partitionedwith the signature(Iterator<Item = T>, T -> bool) -> bool: Returnstrueif the original range is partitioned according to the given predicate, which means that all elements that match the predicate precede all those that don't match the predicate. There are also variants for checking if a range is sorted (is_sorted,is_sorted_by,is_sorted_by_key).positionwith the signature(Iterator<Item = T>, T -> bool) -> Option<usize>: Likefindbut returns the index of the first matching element. For getting the index from the back, there is alsorposition.
The following image illustrates all query algorithms schematically:
Evaluators: The next group of algorithms
The next group of algorithms has no real name, but we can group all algorithms that evaluate a whole range or part of it into one category that we will call the evaluators. Here are all the evaluators:
collectwith the signatureIterator<Item = T> -> B, whereBis any kind of collectionThis is a simplification. The more detailed answer is thatBis any type that implements theFromIteratortrait, which is a trait that abstractions the notion of initializing a collection from a range of elements. If you have an iterator and want to put all its elements into a collection, you can implementFromIteratoron the collection and put the relevant code on how to add the elements to the collection into this implementation. Then, you can either use thecollectfunction on theIteratortrait, or useYourCollection::from_iterator(iter).: This is perhaps the most common iterator function that you will see, as it allows collecting all elements from an iterator into a collection. As an example, if you have an iterator and want to put all its elements into aVec<T>, you can writelet vec: Vec<_> = iter.collect();.countwith the signatureIterator<Item = T> -> usize: Evaluates the iterator, callingnextuntil the iterator is at the end, and then returns only the number of elements that the iterator yielded.foldwith the signature(Iterator<Item = T>, B, (B, T) -> B) -> B. This signature is quite complicated and consists of three parts: The iterator itself, an initial value of an arbitrary typeB, and a function that combines a value of typeBwith an element from the iterator into a new value of typeB.foldapplies this function to every element that the iterator yields, thus effectively merging (or folding) all values into a single value.foldis quite abstract, but a very common use-case forfoldis to calculate the sum of all numbers in a range, in which case the initial value is0and the function to combine two values is simply+.for_eachwith the signature(Iterator<Item = T>, T -> ()) -> (), which we already know.lastwith the signatureIterator<Item = T> -> Option<T>. This evaluates the iterator until the end and returns the last element that the iterator yielded. Since the iterator might already be at the end, the return type isOption<T>instead ofT.maxandminwith the signatureIterator<Item = T> -> Option<T>. This evaluates the iterator until the end and returns the maximum/minimum element that the iterator yielded. Just aslast, since the iterator might already be at the end, the return type isOption<T>instead ofT. These functions use the default orderThe default order of a typeTin Rust is given by its implementation of theOrdorPartialOrdtrait. This is Rust's abstraction for comparing two values for their relative order.Ordis for all types that form a total order,PartialOrdfor all types that form a partial order. of the typeT, if you want to get the maximum/minimum element by another criterion, there are alsomin_by/max_byandmin_by_key/max_by_key. The first variant takes a custom function to compare two values, the second variant takes a function that converts fromTto some other typeUand uses the default order ofU.productwith the signatureIterator<Item = T> -> PwherePis the result type of multiplying two values of typeTwith each other. This is a special variant offoldfor multiplying all values in a range with each other. For numerical types, it is equivalent to callingfoldwith initial value1and*as the function.reducewith the signature(Iterator<Item = T>, (T, T) -> T) -> Option<T>. This is a variant offoldthat does not take an initial parameter and does not support transforming the elements of the iterator to another type.sumwith the signatureIterator<Item = T> -> SwhereSis the result type of adding two values of typeTto each other. This is a special variant offoldfor adding all values in a range to each other. For numerical types, it is equivalent to callingfoldwith initial value0and+as the function.
Where the query algorithms extracted information from parts of a range, most of the evaluators evaluate all elements in the range and do something with them. Knowing only collect and for_each from this category of algorithms is already sufficient for many applications, but it also pays off to understand fold, which is one of the most powerful algorithms there are. As we saw, there are several specific variants of fold, and the fact that seemingly fundamental operations such as sum and product are actually specializations of the fold algorithm should give you an idea of the power of fold. fold is one of the favorite tools of many functional programmers, as it can make code quite elegant, but for people not used to fold it can also make the code harder to read, so that is something to be aware of.
Here are all the evaluators visualized:
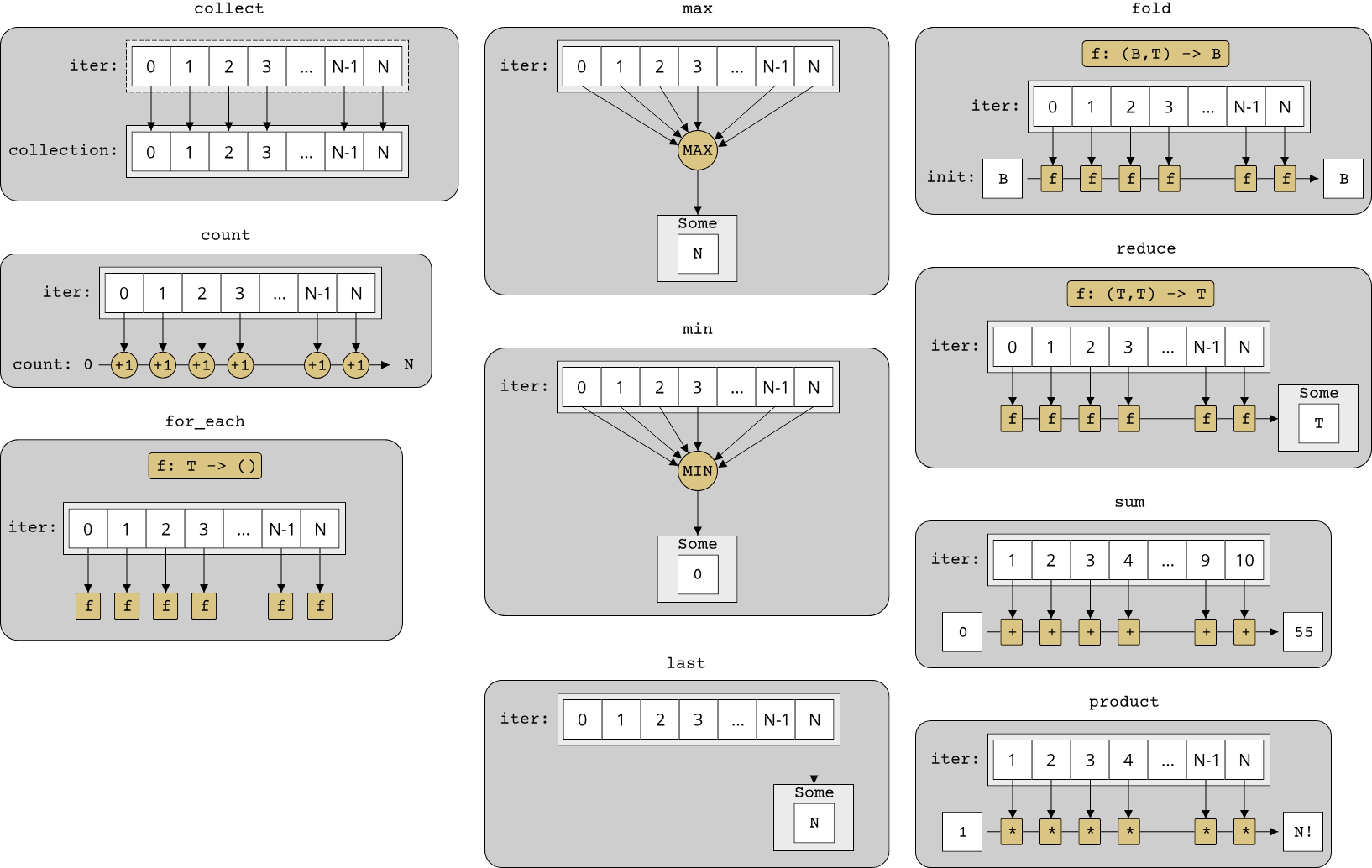
The transformations: The third group of algorithms
The third group of algorithms is all about transforming the way an iterator behaves. We already saw some variants of this group when we examined the query algorithms, namely filter_map and find_map, which are variants of the map algorithm that we already know. With iterators, there are two things that we can transform: The item type of an iterator, or the way the iterator steps through its range. map belongs to the first category, an algorithm that reverses the order of an iterator would belong to the second category.
Here are all the transformations:
clonedwith the signatureIterator<Item = &T> -> Iterator<Item = T>. For an iterator over borrows, this returns a new iterator that instead returnscloned values of the item typeT. As the Rust documentation states:This is useful when you have an iterator over &T, but you need an iterator over T.copiedwith the signatureIterator<Item = &T> -> Iterator<Item = T>. This is identical toclonedbut returns copies instead of clones. Whereclonedonly required that the typeTimplementsClone,copiedrequires thatTimplementsCopy. SinceCopyallows potentially more efficient bit-wise copies,copiedcan be more efficient thancloned.cyclewith the signatureIterator<Item = T> -> Iterator<Item = T>. This returns a new iterator that starts again from the beginning once the initial iterator has reached the end, and will do so forever.enumeratewith the signatureIterator<Item = T> -> Iterator<Item = (usize, T)>. This very useful algorithm returns a new iterator that returns the index of each element together with the element itself, as a pair(usize, T).filterandfilter_mapalso belong to this category, because they change the behaviour of the iterator. As we already saw those in an earlier section, they are not explained again.flattenwith the signatureIterator<Item = Iterator<Item = T>> -> Iterator<Item = T>: Flattens a range of ranges into a single range. This is useful if you have nested ranges and want to iterate over all elements of the inner ranges at once.flat_mapwith the signature(Iterator<Item = T>, T -> U) -> Iterator<Item = U>, whereUis any type that implementsIntoIterator: This is a combination ofmapandflattenand is useful if you have amapfunction that returns a range. Only calling map on an iterator with such a function would yield a range of ranges,flat_mapyields a single range over all inner elements.fusewith the signatureIterator<Item = T> -> Iterator<Item = T>: To understandfuse, one has to understand a special requirement for iterators in Rust, namely that they are not required to always returnNoneon successive calls tonextif the first call returnedNone. This means that an iterator can temporarily signal that it is at the end, but upon a future call tonext, it is perfectly valid that the same iterator can returnSome(T)again. To prevent this behaviour,fusecan be used.inspectwith the signature(Iterator<Item = T>, T -> T) -> Iterator<Item = T>: Allows you to inspect what is going on during iteration by adding a function that gets called for every element in the iterator during iteration. This is similar tofor_each, howeverfor_eacheagerly evaluated the iterator, whereasinspectreturns a new iterator that will lazily call the given function.interspersewith the signature(Iterator<Item = T>, T) -> Iterator<Item = T>: Allows you to add a specific value between any two adjacent values in the original iterator. So a range like[1, 2, 3]with a call tointersperse(42)becomes[1, 42, 2, 42, 3]. If you want to generate the separator on the fly from a function, you can useintersperse_with.map, which we already know. There is alsomap_while, which takes a map function that might returnNoneand only yields elements as long as this function is returningSome(T).peekablewith the signatureIterator<Item = T> -> Peekable<Item = T>: Adds the ability to peek items without advancing the iterator.revwith the signatureIterator<Item = T> -> Iterator<Item = T>: Reverses the direction of the given iteratorscanwith the signature(Iterator<Item = T>, U, (&mut U, T) -> Option<B>) -> Iterator<Item = Option<B>>: This is the lazy variant offoldskipwith the signature(Iterator<Item = T>, usize) -> Iterator<Item = T>: This is the lazy variant ofadvance_by. If you want to skip elements as long as they match a predicate, you can useskip_whilewhich takes a predicate function instead of a count.stepwith the signature(Iterator<Item = T>, usize) -> Iterator<Item = T>: Returns an iterator that steps the given amount in every iteration. Every iterator by default has a step-size of 1, so e.g. if you want to iterate over every second element, you would usestep(2).takewith the signature(Iterator<Item = T>, usize) -> Iterator<Item = T>: Returns an iterator over the firstNelements of the given iterator. IfNis larger than or equal to the number of elements in the source iterator, this does nothing. Like withskip, there is alsotake_whilewhich returns elements as long as they match a predicate. The difference tofilteris that bothskip_whileandtake_whilestop checking the predicate after the first element that does not match the predicate, whereasfilterapplies the predicate to all elements in the range.
As you can see, there are a lot of transformation algorithms available on the Iterator trait. Arguably the most important ones are the filter and map variants, enumerate, skip, and take, as you will see those most often in Rust code.
Here are all the transformations visualized:
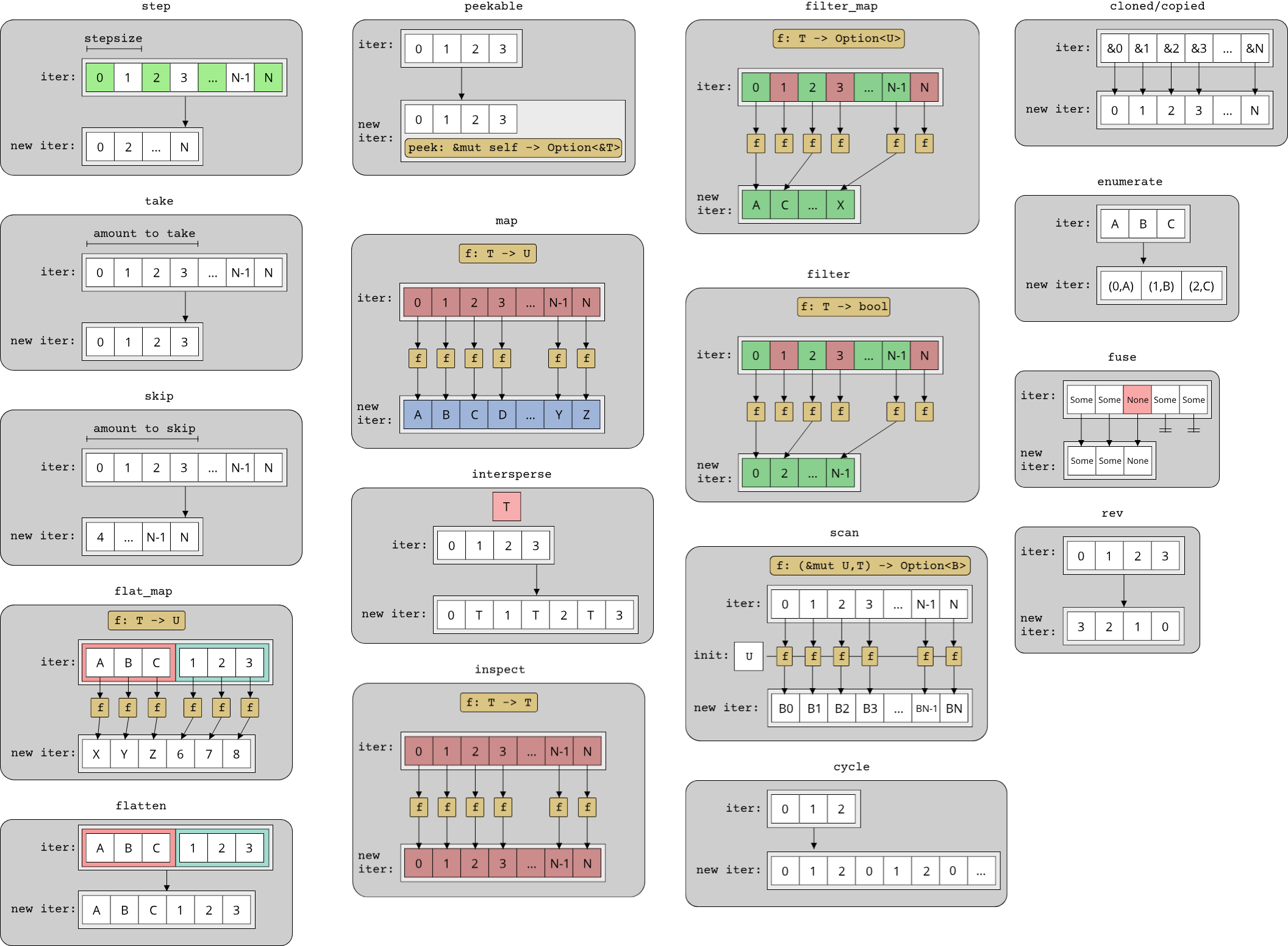
The groupings
The next category of algorithms is all about grouping multiple ranges together:
chainwith the signature(Iterator<Item = T>, Iterator<Item = T>) -> Iterator<Item = T>: It puts the second iterator after the first iterator and returns a new iterator which iterates over both original iterators in succession. This is useful if you want to treat two iterators as one.zipwith the signature(Iterator<Item = T>, Iterator<Item = U>) -> Iterator<Item = (T, U)>: Just like a zipper,zipjoins two iterators into a single iterator over pairs of elements. If the two iterators have different lengths, the resulting iterator will be as long as the shorter of the two input iterators.zipis very useful if you want to pair elements from two distinct ranges.unzipwith the signatureIterator<Item = (T, U)> -> (Collection<T>, Collection<U>): This is the reverse ofzip, which separates an iterator over pairs of elements into two distinct collections, where one collection contains all first elements of the pairs and the other collection all second elements of the pairs.
The grouping algorithms are useful to know when you have multiple ranges that you want to treat as a single range. It is sometimes possible to create clever solutions for certain problems using zip.
Here are the groupings visualized:
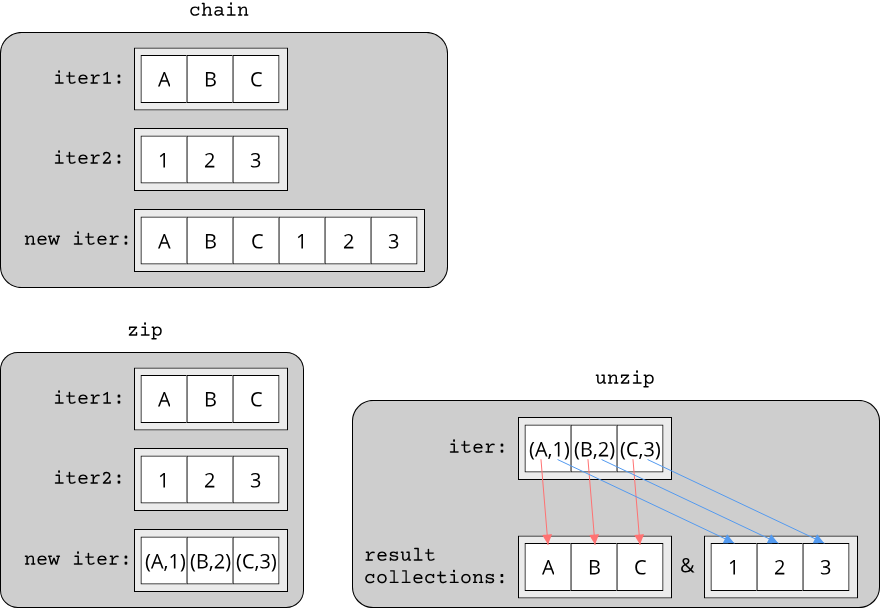
The orderings
The last category of algorithms is all about the order of elements. There are a bunch of functions to compare two iterators based on their elements, as well as one function that changes the order of elements:
cmpwith the signature(Iterator<Item = T>, Iterator<Item = T>) -> Ordering: Performs a lexicographic comparison of the elements of both iterators. The definition for what exactly a lexicographic comparison entails can be found in the Rust documentation. If you don't want to use the default ordering of the elements, you can usecmp_byto specify a custom comparison function. For typesTthat only define a partial order,partial_cmpandpartial_cmp_bycan be used.- For all possible orderings (
A < B,A <= B,A == B,A != B,A >= B, andA > B), there are functions that check this ordering for any two iterators with the same type:lt,le,eq,ne,ge, andgt.eqalso has aeq_byvariant that takes a custom comparison function. is_partitionedand theis_sortedvariants also belong to this category of algorithms.maxandminand their variants also belong to this category of algorithms.partitionwith the signature(Iterator<Item = T>, T -> bool) -> (Collection<T>, Collection<T>): Partitions the range of the given iterator into two collections, with the first collection containing all elements which match the predicate and the second collection containing all elements which don't match the predicate. There is also an experimentalpartition_in_placewhich reorders the elements in-place without allocating any memory.
Here are all the orderings visualized (excluding the variants of cmp and eq):
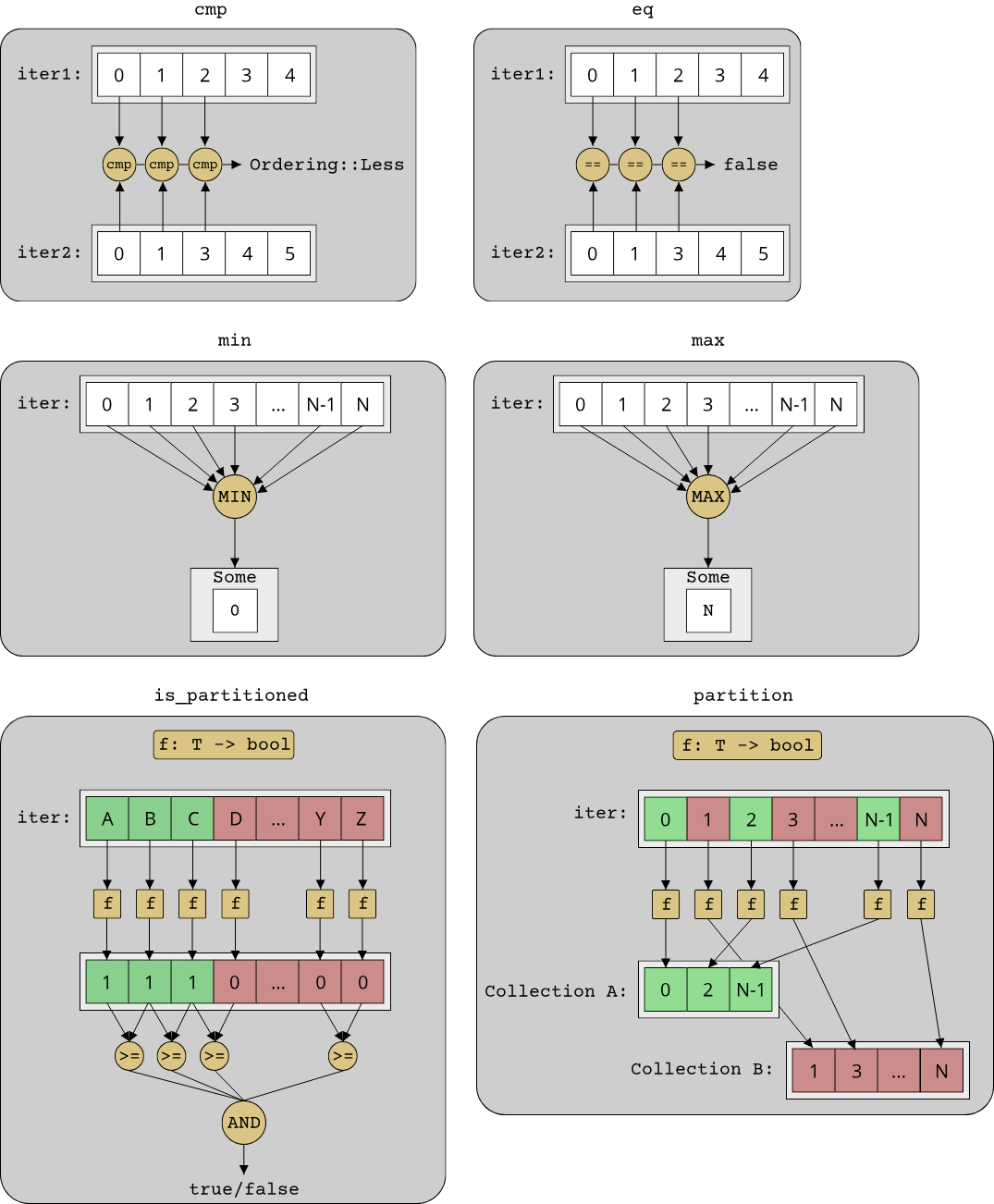
Upon seeing this list, a reasonable question to ask is if there is a sort algorithm. The answer is that there is no sort for iterators in Rust. Sorting is what is known as an offline algorithm, which is the technical term for an algorithm that requires all data at once. Intuitively, this makes sense: The element that should be put at the first position after sorting might be the last element in the original range, so any sorting algorithm has to wait until the very end of the range to identify the smallest element. But Rust iterators are lazy, so they don't have all elements available up-front. It is for this reason that it is impossible to write a sort function that works with an arbitrary iterator. Instead, sort is implemented on the collections that support sorting, such as Vec<T> or LinkedList<T>.
Why we should prefer algorithms over for-loops
Algorithms on iterators are very useful because they make code a lot more readable. They do this by giving names to common patterns in our code. In particular, they help us to untangle loops, since most loops actually perform the same action as one or multiple of these algorithms. Here are some examples:
#![allow(unused)] fn main() { // This is `filter`: for element in collection.iter() { if condition(element) { continue; } // Do stuff } // This is `map`: for element in collection.iter() { let data = element.member; // or let data = func(element); // Do stuff } // This is `find`: let mut result = None; for element in collection.iter() { if condition(element) { result = Some(element); break; } } }
In the C++-world, the usage of algorithms is actively taught by many professionals in the industry, as many talks indicate. The main reason is that C++ traditionally was close to C, and in C raw for-loops were often the way to go. In the Rust-world, for-loops play a lesser role and hence using algorithms on iterators comes more naturally here. For both languages, algorithms on iterators are often the preferred way to write code that deals with ranges, since they are in many cases easier to understand than an equivalent for-loop.
When not to use algorithms
Of course there is no silver bullet in programming, and algorithms are certainly no exception to this rule. While it is often a good idea to use these algorithms instead of a regular for-loop, algorithms do have some downsides. Perhaps the biggest downside is that they can make debugging hard, because they hide a lot of code in the internal implementation of the algorithm functions (map, filter, for_each). Since these functions are part of the standard library, they tend to be more complicated than one might expect, due to certain edge cases and general robustness requirements for library functions. When trying to debug code that makes heavy use of these algorithms, it can be hard to find suitable code locations to add breakpoints, and a lot of the state that might be interesting for debugging will often be located in a different function or be hidden somewhat, compared to a regular for-loop.
The second downside to using algorithms is that they are not always the best solution in terms of readability. If you are wrestling a lot to get some piece of code to work with an algorithm because of this one weird edge case where you have to skip over one item but only if you observed some other item two steps before and instead you have to terminate after five items and.... Then it might just be better to use a regular loop with some comments. Particularily once one gets the hang of algorithms, it can become quite addictive to see how one can turn all possible loops into multiple algorithm calls.
Summary
In this chapter we learned about algorithms on iterators, which are small building blocks for common programming patterns when working with ranges of elements. We learned how to use the Iterator trait in Rust, which provides all sorts of useful functions, such as for_each, filter, or map. We also learned about the difference between eager and lazy iteration, and how lazy iteration even enables us to work with (almost) infinite ranges.
This chapter is meant as much as an introduction to algorithms as it is a reference for all the common algorithms that Rust provides. The visual representation of all agorithms might just help you in understanding an algorithm that you have seen in other code but didn't quite grasp.
This concludes chapter 4, which was all about zero-overhead abstractions. We learned about optional types and iterators, which are the bread and butter of programming in Rust. With this, we have a solid foundation to look at more specific aspects of systems programming, starting with error handling in the next chapter.
Error handling - How to make systems software robust
When learning programming, one of the biggest struggles is to get your code to behave in the way you want it. Be it that nasty off-by-one error in a binary search, or wrong pointers in a linked list, a lot of time is spent on fixing mistakes that we as programmers make. An equally important part of software development is how our software deals with errors not in our own code, but errors that we have no control over. Files might be missing, a network connection might be dropped, we can run out of memory, users might input data in the wrong format, the list goes on. Handling all these error conditions gracefully is an important part of software development. Little is more frustrating to users than software that behaves unexpectedly or even crashes due to a small mistake the user made, or even just unlucky circumstances. While error handling is certainly important for applications software, it is much more critical for systems software. In an application, you have direkt interaction with the user, who can just retry an operation, close an error-popup, or even quickly restart the application in the worst case. Systems software is meant to communicate with other systems, so closing a popup (even showing a popup for that matter) or quickly restarting the system manually is often not an option.
In this chapter, we will learn about error handling in systems software and how to write robust systems that can recover from errors. We will learn about the different ways of communication error conditions in code, especially in C++ and Rust, and how to react to these conditions. We will also learn about the role that the operating system plays in error handling.
Here is the roadmap for this chapter:
- 5.1. Hardware exceptions - How your machine deals with errors
- 5.2. Error codes - A simple way to signal errors in code
- 5.3. Software exceptions - A more sophisticated error handling mechanism for your code
- 5.4.
Result<T, E>- Error handling in Rust
Hardware exceptions - How your machine deals with errors
When working with computers, a lot can go wrong in many places. In this chapter, we will look at how your hardware deals with errors, in the later chapters we will look at how to deal with errors in code.
Types of errors
First things first: What are things that can go wrong? Here it makes sense to start form the perspective of an application and then work our way down to see how this relates to your hardware. Here is a (non-exhaustive) list of things that can go wrong in an application:
- A division by zero is encountered
- A file cannot be found
- The program has the wrong permission to access file
- The program runs out of memory
- The program is accessing memory that is read/write protected
- The program is accessing memory that is not paged in (page fault)
- An integer overflow occurrs
- The program is dereferencing a null pointer (which it turns out is the same as accessing read/write protected memory)
To make sense of all these errors, we can classify them into programmer errors, user errors and system errors. Programmer errors are errors that the programmer makes in their logic, for example dereferencing a null pointer without checking whether the pointer is null. User errors are things that the user of the software does that do not match the expected usage of the software. Wrong user inputs are a good example for this: The software expects a birthday in the format DD.MM.YYYY and the user inputs their name instead. Lastly, system errors are errors which relate to the current state of the system that the program is running on. A missing (or inaccessible) file is an example for a system error, as is a dropped network connection. These are neither the programmers nor the users fault, however we as programmers still have to be aware of system errors and have to take precautions to handle them.
In addition to these three error categories, we can also classify errors into recoverable and non-recoverable errors. In an ideal world, our software can always recover from any possible error condition, however that is rarely the case. Whether a particular error is recoverable or non-recoverable depends largely on the context of the software. A missing file error might be recovered from by providing a default file path or even default data, or it might be non-recoverable because the file is crucial to the workings of the program. For most programs, running out of heap memory will be a non-recoverable condition resulting in program termination, but there are programs that have to be able to recover even from such a critical situation. Generally speaking, we as programmers can develop our application with a specific set of recoverable errors in mind and take precautions to either prevent or handle these errors gracefully. At the most extreme end of recovering from errors are things like the Mars Rovers, which have to work autonomously for many years and thus have to be able to deal with all sorts of crazy errorsThere is a great video on how the people at the NASA Jet Propulsion Laboratory (JPL) had to write their C++ code for the Mars Rovers to deal with all sorts of errors..
Notice that some errors are closer to the hardware than others: Wrong user input can be handled on a much higher level than accessing memory within a page that is not paged into working memory.
The general term for errors in computer science is exceptions, as they signify an exceptional condition. This term is very broad, referring not only to the errors that we have seen so far, but also for signals from I/O devices or a hardware timer going off. When talking about errors that can occur in your code, the more specific term software exception is used, to distinguish them from these other kinds of hardware-related exceptional conditions.
How your hardware deals with exceptions
So how does your hardware deal with these exceptional conditions? Typically, this is done by your processor, which has built-in mechanisms for detecting all sorts of exceptional conditions. When such an exception is detected by the processor, it can refer control flow of your program to a special function that can deal with the exception. Such functions are called exception handlers and they are managed by the operating system in a special table called the exception table. All exception types have unique IDs through which they can be identified, and for each such ID a function is registered in the exception table by the operating system on system startup. This way, once your system is up and running, the operating system guarantees that all exceptions that the processor might detect will get handled appropriately. The exception table itself resides somewhere in memory and there is a special CPU register, called the exception table base register, which points to the start of the exception table in memory.
Let's look at how this works in practice. Imagine that you wrote some code that accidentally divides a number by zero. You CPU is running your code and encounters the instruction for dividing two numbers, which results in the division by zero. Your CPU detects this condition at the point of executing the division instruction. For a division error, the exception code on a Linux-system will be 0, so the CPU then defers control to the exception handler for exception type 0. We call this situation exceptional control flow, to distinguish it from the regular control flow of your program. Exception handlers run in kernel mode and thus have access to all the systems resources directly, even if the program in which the exception occurred was running in user mode. Depending on the type of exception, the exception handler either retries the failed instruction (after doing some additional work), moves on to the next instruction, or terminates the current process. For our division error, the exception handler will send a special signal to the process (SIGFPE), which, if unhandled, will terminate the process. If the process is running in a debugger, the SIGFPE signal gets translated into a different signal which causes the debugger to display that a division error occurred in the process. Exceptions and signals thus are an important part of what makes debuggers work.
On the hardware level, we distinguish between 4 different types of exceptions, based on the default behaviour of their exception handlers:
- Interrupts: These are things like signals from I/O devices to notify that data can be read from them
- Traps: These are intentional exceptions which require some action from the operating system, for example system calls
- Faults: These are potentially recoverable errors, for example page faults (accessing memory in a page that is not cached in working memory)
- Aborts: These are unrecoverable hardware errors, for example memory failures
The operating system and hardware closely interact when dealing with exceptions, with some exception types (such as divide-by-zero and page fault) being defined by the hardware, and others (such as system call) being defined by the operating system.
Hardware errors are a big topic that we could delve much deeper into, however a lot of this stuff is covered in an operating systems course, so we will leave it at that for now.
Error codes - A simple way to signal errors in code
Besides hardware errors, there are many situations where things can go wrong in our code. Basically any time our code interfaces with some external system:
- Reading/writing files
- Network connections
- Using the graphics processing unit (GPU)
- Getting user input
A fundamental insight in software development is that errors are not to be treated as some unfortunate event that we try to ignore, but instead to plan for errors and handle them correctly in code. Essentially, we accept that errors are a natural part of any program that is as important as the regular control flow of the program. In this and the next chapters, we will look at how we as programmers can deal with errors in our code and make it explicit that a piece of code might encounter an error. In fact, this is already the fundamental principle of error handling in code:
Whenever something might go wrong in our code, we have to signal this fact to the calling code!
It is important to realize that with errors, we do not know upfront if a piece of code might succeed or not! This is different from e.g. the usage of Option<T> that we saw in the last chapter, i.e. the log function which only produces an output if a number > 0 is passed in. When downloading something through the network, we can't ask beforehand 'will this download succeed?'. Accordingly, when requiring user input, we don't know beforehand what our users will input (after all, that's kind of the reason for writing software for users: That they can do arbitrary things with it). So while Option<T> was nice, it does not help us all that much with error handling.
Three ways of signaling errors to calling code
In programming languages today, we mainly encounter three different ways of signaling errors to calling code:
- Error codes (covered in this chapter)
- Exceptions (covered in chapter 5.3)
- Result types (covered in chapter 5.4)
Not all languages support all three types of errors, neither C nor Rust have exceptions for example, and not all are equally useful in every situation. Let's start with the simplest way of signaling errors: Error codes.
Using the function return value to signal an error
Perhaps the simplest way to signal a potential error in a function is to the return value of the function. We could return a number that indicates either success or the reason for failure. We call this approach error codes and this is what C does. It is very simple, can be realized with every language that supports functions (which is like, 99% of all languages in use today) and has little performance overhead. Here are some examples for error codes in functions from the C standard library:
fclosefor closing a file (int fclose( std::FILE* stream );): Returns0on success and an error codeEOFon failurefopen, which has the signaturestd::FILE* fopen( const char* filename, const char* mode ): It returns a pointer, which will benullif the file could not be opened.pollfrom the Linux API, which can be used to check if a network connection is ready for I/O. It has the signatureint poll(struct pollfd *fds, nfds_t nfds, int timeout);and returns-1if an error has occurred.
As you can see, many functions use the return value to indicate whether an error occurred or not, but often, you are left wondering what kind of error occured exactly. For this, Linux has a global variable called errno, which contains the error code of the last failed operation. Error codes include things such as:
ENOENT 2 No such file or directoryEACCES 13 Permission denied
By checking the value of errno, we can get more information about the cause of an error after a failed operation. This approach has traditionally been used in other libraries as well. For example, the OpenGL library for accessing the GPU also uses error codes excessively. Just like Linux, it has a global error variable that can be queried with a call to glGetError.
The problem with error codes
Error codes are used a lot in low-level code, because they are so simple. There are a lot of problems with error codes though:
- They take up the return value of a function. Since you often want to return something else besides an error, many systems instead keep a global error variable somewhere and write error codes into this variable (such as
errno). You has programmer have to remember to keep looking into this variable to ensure that no error occurred. - If you use the return value of the function for an error code, you get weird-looking code that mixes regular behaviour with error checking (e.g.
if(!do_something(...)) { /* Success */ }orif(do_something(...) == FAILED) { })- Also this becomes quite annoying if you combine functions with error handling because you then have to pipe through the error to calling functions. If you have multiple different error codes, how do you combine them?
- Error codes don't permit exceptional control flow easily. If you have three functions
a(),b()andc(), wherea()callsb()callsc(),c()can return an error and you want to handle it ina(), you have to add error handling code also tob()
- Error codes are not obvious and the compiler does not force you to handle them in any way. It is perfectly fine to ignore the error code:
do_something(); do_something_else();Since usually integer numbers are used for error codes, it can be hard to tell whether the return value of a function is a regular integer value, or an error code. Especially in C-code, you might see something liketypedef int error_tto make the return value more explicit, there is still zero compiler support for checking how the return value is used. Recall thattypedefin C (and C++) does not introduce a new type, it is just an alias for an existing type.
So really, error codes are not a great tool for error handling. They are fine mostly due to legacy reasons, some people might even like them because they are so simple, but they leave a lot to be expected. So in the next chapter, we will look at a more powerful alternative: Exceptions.
5.3. Software exceptions - A more sophisticated error handling mechanism for your code
In the previous section, we saw that error codes were a simple way for reporting errors to calling code, however they had several shortcomings:
- They block the return type of the function
- They are easy to miss and don't really have good support from the compiler
- They can't handle non-linear control flow
For these reasons, several modern programming languages introduced the concept of software exceptions. A software exception is similar to a hardware exception, but (as the name implies) realized purely in software. It provides a means for notifying code about error conditions without (ab)using the return type of a function, like you would with error codes. Just like hardware exceptions, software exceptions provide a means to escape the regular control flow of a program and thus provide non-linear control flow.
A software exception is typically a fancy name for a datastructure containing information about any sort of exceptional condition that might occur in your code. Most often, these will be errors, such as 'file not found' or 'unable to parse number from string' etc. Depending on the language, there are either specialized types for software exceptions (like in Java or C#) or almost every type is valid as an exception datastructure (like in C++).
A key part of exception handling, both in hardware and software, is the exceptional control flow that it enables: The occurrence of an exception causes the program to divert from its regular control flow and execute different code than it typically would. Just as hardware exceptions get deferred to exception handlers, so do software exceptions, with the difference that the hardware exception handlers are defined by the operating system, whereas software exception handlers are defined by the programmer.
Languages that have built-in support for exceptions do so by providing a bunch of keywords for raising exceptions (signaling other code that an exceptional condition has occurred) and for handling exceptions. For raising exceptions, typical keywords are throw (C++, Java, JavaScript, C#) or raise (Python, OCaml, Ruby, Ada). For handling exceptions, two keywords are used most of the time, one to indicate the region in the code for which the exception handler should be valid, and a second one for the actual exception handler. Most often, try/catch is used (C++, Java, JavaScript, C#, D), but there are other variants, such as try/with (OCaml), try/except (Python) or begin/rescue (Ruby).
Exceptions in C++
C++ is one of the few systems programming languages that support exceptions. Here is a small example on how to use exceptions in C++:
#include <iostream>
#include <exception>
void foo() {
throw 42;
}
int main() {
try {
foo();
} catch(...) {
std::cout << "Exception caught and handled!" << std::endl;
}
return 0;
}
As you can see, we use throw to throw an exception (here simply the value 42). When we want to handle exceptions, we surround the code for which we want to handle exceptions with a try/catch clause. Code that might throw exceptions goes inside the try clause, and the code that handles exceptions goes inside the catch clause. If we write catch(...) we are catching every possible exception, at the cost of not knowing what the actual exception value is.
Instead of throwing raw numbers, C++ provides a number of standard exception types in the STL. There is a base type std::exception, and then a bunch of subtypes for various exceptional conditions. We can use these types to specialize our catch statement to catch only the types of exceptions that we are interested in:
#include <iostream>
#include <exception>
void foo() {
throw std::runtime_error{"foo() failed"};
}
int main() {
try {
foo();
} catch(const std::runtime_error& ex) {
std::cout << "Exception '" << ex.what() << "' caught and handled!" << std::endl;
}
return 0;
}
Since the exception types are polymorphic, we can also write catch(const std::exception& ex) and catch every exception type that derives from std::exception. You can even write your own exception type deriving from std::exception and it will work with this catch statement as well. As you can see from the example, all subtypes of std::exception also carry a human-readable message, which is defined when creating the exception (std::runtime_error{"foo() failed"}) and can be accessed through the virtual function const char* what().
Examples of exceptions in the STL
There are many functions in the C++ STL that can throw exceptions, as a look into the documentation tells us. Here are some examples:
std::allocator::allocate(): The default memory allocator of the STL will throw an exception if the requested amount of memory exceeds the word size on the current machine, or if the memory allocation failed, typically because the underlying system allocator (malloc) ran out of usable memory.std::thread: As an abstraction for a thread of execution managed by the operating system, there are many things that can go wrong when using threads. An exception is thrown if a thread could not be started, if trying to detach from an invalid thread, or if trying to join with a thread that is invalid or unjoinable.- The string conversion functions
std::stoiandstd::stof(and their variants): Since these functions convert strings to integer or floating-point numbers, a lot can go wrong. They are a great example for a function that uses exceptions, because the return value of the function is already occupied by the integer/floating-point value that was parsed from the string. If parsing fails, either because the string is not a valid number of its size exceeds the maximum size of the requested datatype, an exception is thrown. std::vector: Some of its methods can throw an exception, for example if too many elements are requested inreserveor an out-of-bounds index is passed toat.std::future::get: We will cover futures in a later chapter, but they are essentially values that might be available in the future. If we callgeton such a future value and the value has not yet been computed, an exception can be raised. An interesting feature ofstd::futureis that computing the value may itself raise an exception, but it won't do so right away. Instead, it will raise the exception oncegetis called.
Exception best practices in C++
Exception handling in C++ can be tricky because there are little rules built into the language. As such, there are a handful of hard rules that the C++ language enforces on the programmer when dealing with exceptions, and a plethora of 'best practices'. Let's start with the hard rules!
Exception rule no. 1: Never throw exceptions in a destructor
The reasoning for this rule is a bit complicated and has to do with stack unwinding, a process which we will learn about later in this chapter. In a nutshell, when an exception is thrown, everything between the throw statement and the next matching catch statement for this exception has to be cleaned up properly (i.e. all local variables). This is done by calling the destructor of all these local variables. What happens if one of these destructors throws an exception as well? Now we have two exceptions that have to be handled, but we can handle neither before the other. For that reason, the C++ language defines that in such a situation, std::terminate will be called, immediately terminating your program. To prevent this, don't throw exceptions in destructors!
Since C++11, destructors are implicitly marked with the noexcept keyword, so throwing from a destructor will immediately call std::terminate once the exception leaves the destructor. Note that catching the exception within the destructor is fine though!
Exception rule no. 2: Use noexcept to declare that a function will never throw
C++11 introduced the noexcept keyword, which can be appended to the end of a function declaration, like so:
void foo() noexcept {}
With noexcept, you declare that the given function will never throw an exception. If it violates this contract and an exception is thrown from this function, std::terminate is immediately called! There are also some complicated rules for things that are implicitly noexcept in C++, such as destructors or implicitly-declared constructors. noexcept is also part of the function signature, which means that it can be detected as a property of a function in templates. A lot of the STL containers make use of this property to adjust how they have to deal with operations on multiple values where any one value might throw. To undestand this, here is an example:
Think about std::vector::push_back: It might require a re-allocation and copying/moving all elements from the old memory block to the new memory block. Suppose you have 10 elements that must be copied/moved. The first 4 elements have been copied/moved successfully, and now the fifth element is throwing an exception is its copy/move constructor. The exception leaves the push_back function, causing the vector to be in a broken state, with some of its elements copied/moved and others not. To prevent this, push_back has to deal with a potential exception during copying/moving of every single element, which can be a costly process. If instead push_back detects that the copy/move constructor of the element type is noexcept, it knows that there can never be an exception during copying/moving, so the code is much simpler! The way a function on an object behaves when it encounters an exception is called the exception guarantee and is the subject of the next rule!
Exception rule no. 3: Always provide some exception guarantee in your functions
There are four kinds of exception guarantees: No exception guarantee, basic exception guarantee, strong exception guarantee, and nothrow exception guarantee. They all deal with what the state of the program is after an exception has occurred within a function, and they are all strict supersets of each other.
A function with no exception guarantee makes no assumptions over the state of the program after an exception as occurred. This is equivalent to undefined behaviour, there might be memory leaks, data corruption, anything. Since exceptions are a form of errors, and errors are to be expected in any program, it is a bad idea to have no exception guarantee in a function.
The next stronger form is the basic exception guarantee. It just states that the program will be in a valid state after an exception has occurred, leaving all objects intact and leaking no resources. This however does not mean that the state of the program is left unaltered! In the case of std::vector::push_back, it would be perfectly valid to end up with an empty vector after an exception has occurred, even if the vector contained elements beforehand.
If you want an even stronger exception guarantee, the strong exception guarantee is what you are looking for. Not only does it guarantee that the program is in a valid state after an exception has occured, it also defines that the state of the program will be rolled back to the state just before the function call that threw an exception. std::vector::push_back actually has the strong exception guarantee, so an exception in this function will leave the vector in the state it was in before push_back was called!
The last level of guarantee is the nothrow exception guarantee, which is what we get if we mark a function noexcept. Here, we state that the function is never allowed to throw an exception.
Exception rule no. 4: Use exceptions only for exceptional conditions
This rules sounds obvious, but it still makes sense to take some time to understand what we mean by 'exceptional conditions'. In general, these are situations which, while being exceptional, are still expected to happen in the normal workings of our program. In the end this comes down to likelyhood of events. If our program reads some data from a file, how likely is it that the file we are trying to open does not exist or our program does not have the right permissions? This depends on your program of course, but let's say that the likelyhood of the file not existing is between 1%-5%. Most of the time, it won't happen, but are you willing to bet your life on it? Probably not, so this is a good candidate for an 'exceptional condition' and hence for using exceptions (or any other error handling mechanism). We might go as far as saying that anything that has a non-zero chance of failing is a candidate for an exceptional condition (we will see what this means in the next chapter), however for some situations, it is no practical to assume that they will ever occur in any reasonable timeframe. There are probably situations where a bug in a program was caused by a cosmic ray flipping a bit in memory, but these conditions are so rare (and almost impossible to detect!) that we as programmers typically don't care about themIn addition to the rarity of such an event, it is also a hardware error, not a software error! As a sidenote: While the average programmer might not care about bit flips due to ionizing radiation, the situation is different in space, where radiation-hardened electronics are required!.
So you use exceptions (or any kind of error handling) for exceptional conditions, fine. But what is not an exceptional condition? There are two other categories of situations in a program that stand apart from exceptional conditions, even though they also deal with things straying from the expected behaviour: Logical conditions and assertions.
Logical conditions are things like bounds-checks when accessing arrays with dynamic indices, or null-checks when dereferencing pointers. In general, these are part of the program logic. Take a look at a possible implementation of the std::vector::at function:
template <class T, class Alloc>
typename vector<T, Alloc>::const_reference
vector<T, Alloc>::at(size_t idx) const
{
return this->_begin[idx];
}
What happens if we call this function with an index that is out of bounds (i.e. it is greater than or equal the number of elements)? In this case, we would access memory out of bounds, which results in undefined behaviour, meaning our program would be wrong! Now we have to ask ourselves: Can this function be called with an index that is out of bounds? Here, a look at the domain of the function helps, which is the set of all input parameters. For the function std::vector::at, which has the signature size_t -> const T&, the domain is the set of all values that a size_t can take. Recall that size_t is just an unsigned integer-type as large as the word size on the current machine, so it is the same as uint64_t on a 64-bit machine. Its maximum value is \( 2^{64}-1 \), which is a pretty big value. Clearly, most vectors won't have that many elements, so it is a real possiblity that our function gets called with an argument that would produce undefined behaviour. To make our program correct, we have to recognize this as a logical condition that our program has to handle. How it does this is up to us as programmers, but it does have to handle it in one way or another. The typical way to do this is to use some sort of check in the code that separates the values from the domain into valid and invalid values for the function, and use some error handling mechanism for the invalid values, for example exceptions:
template <class T, class Alloc>
typename vector<T, Alloc>::const_reference
vector<T, Alloc>::at(size_t idx) const
{
if (idx >= size())
this->throw_out_of_range();
return this->_begin[idx];
}
What about assertions? Assertions are invariants in the code that must hold. If they don't, they indicate an error in the program logic. For functions, invariants refer to the conditions that your program must be in so that calling the function is valid. It would be perfectly valid to define the std::vector::at function with the invariant that it must only be called with an index that lies within the bounds of the vector. In fact, this is exactly what std::vector::operator[] does! Its implementation would be equal to our initial code for std::vector::at:
template <class T, class Alloc>
typename vector<T, Alloc>::const_reference
vector<T, Alloc>::operator[](size_t idx) const
{
return this->_begin[idx];
}
Notice how it is a design choice whether to use explicit error reporting (and thus allowing a wider range of values) or using function invariants. std::vector::operator[] is faster due to its invariants (it does not have to perform a bounds check), but it is also less safe, because violating the invariants results in undefined behaviour, which can manifest in strange ways. As a compromise, we can use assertions, which are checks that are only performed in a debug build. If an assertion is violated, the program is terminated, often with an error message stating which assertion was violated. We can use assertions like this:
template <class T, class Alloc>
typename vector<T, Alloc>::const_reference
vector<T, Alloc>::operator[](size_t idx) const
{
assert(idx < size(), "Index is out of bounds in std::vector::operator[]");
return this->_begin[idx];
}
So assertions are for reporting programmer errors, while exceptions are for reporting runtime errors.
Lastly, error reporting should not be abused to implement control flow that could be implemented with the regular control flow facilities of a language (if, for etc.). Here is an example of what not to do:
#include <iostream>
#include <exception>
#include <vector>
void terrible_foreach(const std::vector<int>& v) {
size_t index = 0;
while(true) {
try {
auto element = v.at(index++);
std::cout << element << std::endl;
} catch(const std::exception& ex) {
return;
}
}
}
int main() {
terrible_foreach({1,2,3,4});
return 0;
}
While this code works, it abuses the non-linear control flow that exceptions provide to implement something that would be much easier and more efficient if it were implemented with a simple if statement.
How exceptions are realized - A systems perspective
We will conclude this chapter with a more in-depth look at how exceptions are actually implemented under the hood. The non-linear control flow has a somewhat magical property, and it pays off to understand what mechanisms modern operating systems provide to support software exceptions.
At the heart of exception handling is the ability to raise an exception at one point in the code, then magically jump to another location in the code and continue program execution from there. In x86-64 assembly language, jumping around in code is not really something magical: We can use the jmp instruction for that. jmp just manipulates the instruction pointer to point to a different instruction than just simply the next instruction. So say we are in a function x() and throw an exception, with a call chain that goes like main() -> y() -> x(), and a catch block inside main(). We could use jmp to jump straight from x() to the first instruction of the catch block in main().
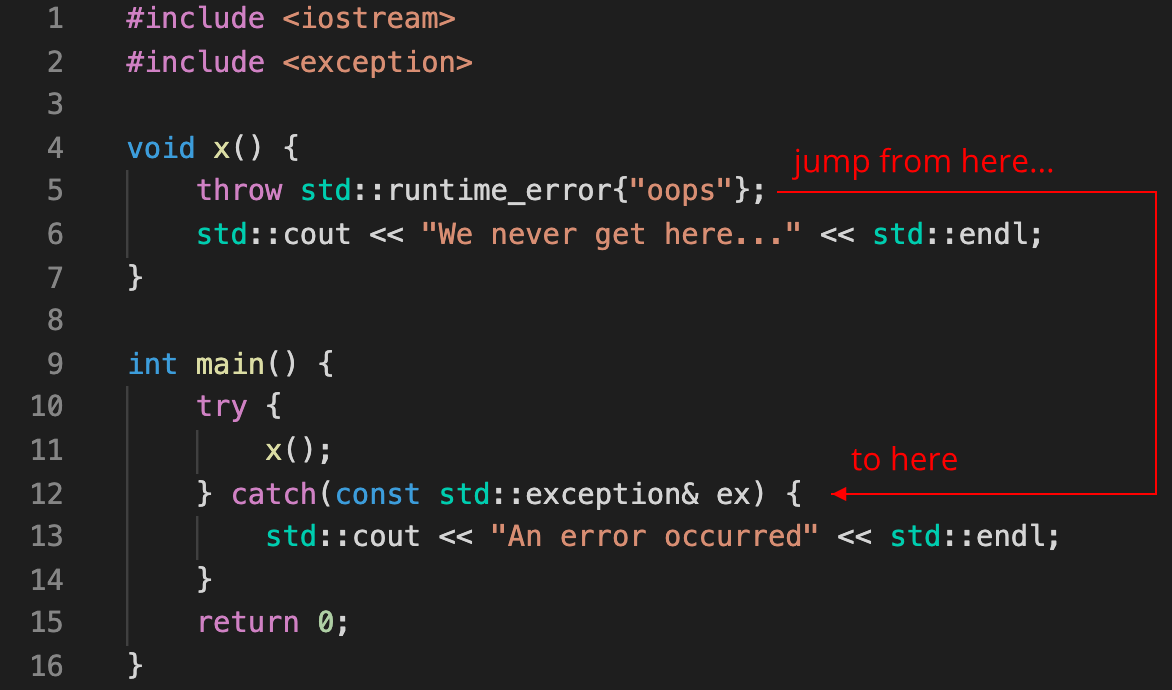
If we do this, we skip over a lot of code that never gets executed. Recall that functions include automatic cleanup of the stack in C++. The compiler generated a bunch of instructions for stack cleanup for the functions x() and y(). If we use jmp to exit x() early, we skip these stack unwinding instructions. This has the effect that our variables are not cleaned up correctly...
This is not the only problem with using jmp! We also have to figure out where to jump to, i.e. where the correct exception handler for our exception is located in the code. For the simple example, the compiler might be able to figure this out, but as soon as dynamic dispatch comes into play, the location of the next matching exception handler can only be determined at runtime!
To automatically clean up the stack, we have to get some help from the operating system. Linux provides two functions called setjmp and longjmp for doing non-local jumps in the code while correctly cleaning up stack memory. setjmp memorizes the current program state (registers, stack pointer, instruction pointer) at the point where it is called, and longjmp resets the information to what was stored with setjmp. Windows has a similar mechanism, and the C standard library even provides a platform-agnostic implementation for these functions (also called setjmp and longjmp). setjmp is also one of those strange functions that return twice (like fork): Once for the regular control flow, and once after resuming from a longjmp call. Wikipedia has a great example that illustrates how these two functions can be used to realize exceptions in the C language (which has no built-in exception support):
#include <setjmp.h>
#include <stdio.h>
#include <stdlib.h>
enum { SOME_EXCEPTION = 1 } exception;
jmp_buf state;
int main(void)
{
if (!setjmp(state)) // try
{
if (/* something happened */)
{
exception = SOME_EXCEPTION;
longjmp(state, 0); // throw SOME_EXCEPTION
}
}
else switch(exception)
{
case SOME_EXCEPTION: // catch SOME_EXCEPTION
puts("SOME_EXCEPTION caught");
break;
default: // catch ...
puts("Some strange exception");
}
return EXIT_SUCCESS;
}
Now, in C we don't have destructors, so simply cleaning up the stack memory might be enough, but in C++ we also have to call the destructor for every object within the affected stack region. setjmp/longjmp don't help here. Instead the compiler effectively has to insert code that memorizes how to correctly unwind the stack in every function that might throw an exception. When an exception gets thrown, the code then walks up the stack using these markers to perform correct clean up, until an appropriate exception handler has been found.
The details depend on the compiler and hardware architecture. As an example, gcc follows the Itanium C++ ABI. ABI is shorthand for application binary interface (similar to API, which is application programming interface) and defines how function calls and data structures are accessed in machine code.
Correctly handling exceptions requires extra code, which can be slower than if we didn't use exceptions. Older implementations incured a cost even if an exception never occurred, modern compilers have gotten better at optimizing this, so exceptions often have virtually zero overhead in the 'happy path', i.e. when no exception is raised. Raising an exception and handling it still has overhead though. Which brings us to the downsides of using exceptions!
The downsides of using exceptions
While exceptions are quite convenient for the programmer, they also have quite substantial downsides. In the past, the performance overhead of exceptions was the major argument against using them. C++ compilers usually provide flags to disable exceptions, such as -fno-exception in the gcc compiler. Nowadays, this is not such a strong argument anymore as compilers have gotten better at optimizing exceptions.
The non-local control flow is actually one of the bigger downsides of exceptions. While it is very convenient, it can also be hard to grasp, in particular when call stacks get very deep. Jumping from c() to a() can be mildly confusing to figure out, jumping from z() to a() through 24 different functions will become almost impossible. This issue is closely related to the next issue: Exceptions are silent. This is really more of a C++ problem than a general problem with exceptions, but in C++, just from looking at the signature of a function, there is no way of knowing what - if any - exception(s) this function might throw. Sure, there is noexcept, but it only tells you that a function does not throw. A function that is not noexcept might throw any exception, or - even worse - it could also be noexcept but it was not written as suchThis is similar to const. A function that is not const might mutate data, but it could also be that someone simply forgot to add const to the function signature. For this reason, the term const-correctness has been established in the C++ community, and it is pretty well understood that making as many things const as possible is a good idea. As we saw, Rust takes this to its extreme and makes everything immutable ('const') by default.. There are mechanisms in other languages for making exceptions more obvious, Java for example has checked exceptions which are part of the function signature and thus have to be handled, but C++ does not have such a feature.
Lastly, from a systems programming perspective, exceptions are not always the right call. There still might be a larger performance overhead in an error case than if error codes are used, and not every error can be modelled with an exception. You can't catch a segmentation fault in a catch block! So catch might give a false sense of security in the context of systems programming.
Where to go from here?
So, error codes are bad, exceptions are also kind of bad. Where do we go from here? As you might have realized from the lack of Rust-code in this chapter, Rust does not support exceptions and instead has a different error handling mechanism. Where the Option<T> type from the last chapter was used to get rid of null, we will see in the next chapter how Rust's Result<T, E> type makes error handling quite elegant in Rust.
5.4. Result<T, E> - Error handling in Rust
As we said, Rust does not support exceptions. Which would leave error codes as the only error handling mechanism, but we already saw that they are hard to use and not really elegant. Rust goes a different route and provides a special type called Result<T, E> for error handling.
To understand how it works, let's think a bit about what it means for an error to occur in the code. Let's take a Rust function foo() that attempts to read a file from disk and returns its contents as a Vec<u8>: fn foo(file_path: &str) -> Vec<u8>{ todo!() }. The signature of such a function is &str -> Vec<u8>, so a function taking a string slice and turning it into a Vec<u8>. Of course there are a million ways to turn a string slice into a Vec<u8> (we could take the bytes of the string, compute a hash, interpret the string as a number and take its bytes etc.), but of course our function has special semantics that are not encoded in the type: It assumes the string is a file path and will return the file contents. We can use a more specific type here for the file path: fn foo(file_path: &Path) -> Vec<u8>{ todo!() }. Now recall what we learned about functions and types: A function is a map between values of certain types. In our case, foo is a map between file paths and byte vectors. Since both Path and Vec<u8> can be arbitrarily large (Path is like a string, which is like a Vec<char>), this is a function mapping an infinite set of paths to an infinite set of vectors. An interesting question to ask is how exactly this mapping behaves: Does every path map to one unique vector? Can two paths map to the same vector? Are there vectors that can never be returned from the function?
Mathematically, this question is equivalent to asking whether the function foo is injective, surjective, or bijective. These three properties of (mathematical) functions define how the elements from the input set (called the domain of the function) map to elements of the output set (called the codomain of the function). Wikipedia has a great image explaining these concepts:
Even though the image depicts finite domains and codomains, the same concept can also be applied to functions with infinite domains and codomains. So which one is our foo function: Injective, surjective, bijective, or none of these? And what does this have to do with errors?
We can have multiple paths pointing to the same file and hence to the same byte vector: On Linux, /bar.txt and /baz/../bar.txt both point to the same file, but are different values for a Path object. So our function can't be injective!
To be surjective, every possible byte vector would have to correspond to at least one file path. That of course depends utterly on the current file system, but in principle, we could enumerate all possible byte vectors and assign them a path, for example by concatenating all the bytes, and use this as a file name. So our function could be surjective.
But there is a problem! What does our function do when it encounters a path to a file that does not exist? To what value should our function map this path? It could map it to an empty vector, as no bytes could be loaded for a file that does not exist, but this would make it impossible to distinguish between an empty file and a file that does not exist. Also, what about files that do exist, but are read-protected?
Let's look at this from a users perspective: If a user tries to open a file in some software, for example a text editor, and they specify an invalid path, what should happen? If we map invalid and inaccessible paths to an empty byte vector, the text editor might show an empty document. This might confuse the user, especially if they chose an existing file: Why is this existing file empty all of a sudden? It would be much better if the text editor notified the user that the file could not be opened. Even better would be if the user gets notified about the reason why the file could not be opened.
Is our function &Path -> Vec<u8> able to convey this information? Clearly not, because the codomain (Vec<u8>) has no way of encoding error information! Sure, we could take an error message and put its bytes into the Vec<u8>, but then how would we know that the returned vector contains an error message and that the bytes are not just the bytes that were loaded from the file?
To fix this mess, we do the same thing that we did in chapter 4.1 when we learned about the Option<T> type: We extend the set of return values! One possible way to do this would be to just use error codes and return a tuple like (Vec<u8>, ErrorCode) from the function. On ErrorCode::Success the Vec<u8> would contain the file data, otherwise the reason for the error would be encoded in the ErrorCode. But recall from our discussion on Option<T> that tuples are product types: Our function now returns a vector and an error code. But we never really need both: Either the function succeeds, in which case we just care about the Vec<u8>, or the function fails, in which case we don't care about the Vec<u8> and only need the ErrorCode to figure out what went wrong. On top of that, we might just use the Vec<u8> and forget to check the ErrorCode, resulting in a bug in our code!
So instead of using a product type, let's use a sum type:
#![allow(unused)] fn main() { enum SuccessOrError<T> { Success(T), Error(ErrorCode), } }
Now our function looks like this: fn foo(file_path: &Path) -> SuccessOrError<Vec<u8>> { todo!() }. It now returns either a successful result (the byte vector) or an ErrorCode. As an added benefit, Rust forces us to handle both cases separately (just like with Option<T>):
fn main() { match foo("/bar") { SuccessOrError::Success(bytes) => (), SuccessOrError::Error(error_code) => eprintln!("Error reading file: {}", error_code), } }
Maybe we don't want to return an ErrorCode but something else, like a message or some piece of contextual information. So it would be better if our SuccessOrError type were generic over what kind of error as well. This is exactly what the Rust built-in type Result<T, E> is:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
We can use this type like so:
#![allow(unused)] fn main() { fn foo(file_path: &Path) -> Result<Vec<u8>, String> { match std::fs::read(file_path) { Ok(bytes) => Ok(bytes), Err(why) => Err(format!("Could not read file ({})", why)), } } }
Here we used the standard library function std::fs::read, which reads the contents of a file into a Vec<u8> (just what our foo function was intended to do), which itself returns a Result<T, E>. The functions in the std::fs module return a special error type std::io::Error if they fail. Since we want to return a String instead, we match on the result of std::fs::read and convert the error into a message. Since foo also returns a Result<T, E>, we wrap both the contents of the happy path (bytes) and the error path (our message) in the appropriate literals of the Result<T, E> type. Since Result<T, E> is such a common type, it is automatically imported into every Rust file, so we can simply write Ok(...) and Err(...) instead of Result::Ok(...) and Result::Err(...).
With Result<T, E>, we have a mechanism to include failure as a first-class citizen in our code, by adding error types to the codomain (i.e. return type) of our functions. With Result<T, E>, we can explicitly state that a function might fail, similar to what we did with error codes, but a lot more explicit and flexible, since Result<T, E> can store anything as the error type.
Working with Result<T, E>
The Result<T, E> type has similar methods as the Option<T> type: Besides matching, we can check if a Result<T, E> contains an Ok value with is_ok() or an Err value with is_err(). If we only care about either of those values, we can convert from a Result<T, E> to an Option<T> with ok(), or to an Option<E> with err(). Both the ok() and the err() function consume the Result<T, E> value, which can be seen from the function signature:
#![allow(unused)] fn main() { pub fn ok(self) -> Option<T> }
It takes self by value, thus consuming the value it is called on. We already saw this pattern with some of the itereator algorithms in chapter 4.3.
One of the most useful functions on Option<T> was map(), and it exists on Result<T, E> as well. Since Result<T, E> has two possible types that could be mapped, there are multiple methods:
map()has the signature(Result<T, E>, (T -> U)) -> Result<U, E>and converts theOkvalue from typeTto typeUusing the given mapping function. If the givenResult<T, E>instead contains anErrvalue, the function is not applied and theErrvalue is just passed on.map_err()has the signature(Result<T, E>, (E -> F)) -> Result<T, F>and converts theErrvalue from typeEto typeFusing the given mapping function. If the givenResult<T, E>instead contains anOkvalue, the function is not applied and theOkvalue is just passed on.map_or_else()has the signature(Result<T, E>, T -> U, E -> F) -> Result<U, F>and is a combination ofmap()andmap_err()that takes two mapping functions to map both theOkvalue and theErrvalue to a new type.
With map_err() we can rewrite our foo function:
#![allow(unused)] fn main() { fn foo(file_path: &Path) -> Result<Vec<u8>, String> { std::fs::read(file_path). map_err(|e| format!("Could not read file ({})", e)) } }
Similar to Option<T>, we can chain multiple function calls that return a Result<T, E> value using and_then():
#![allow(unused)] fn main() { fn reverse_file(src: &Path, dst: &Path) -> Result<(), String> { std::fs::read(src) .and_then(|mut bytes| { bytes.reverse(); std::fs::write(dst, bytes) }) .map_err(|e| format!("Could not read file ({})", e)) } }
Notice how both Result<T, E> and Option<T> behave a little like a range of values, where you either have exactly one value (Some(T) or Ok(T)) or no values (None and disregarding the value of Err(E)). This is similar to an iterator, and indeed both Option<T> and Result<T, E> can be converted to an iterator using the iter() and iter_mut() functions.
The ? operator
Once we start using Result<T, E> in our code, we will often encounter situations where we use multiple functions that return a Result within a single function. A simple example would be to read a text-file, parse all lines as numbers, and compute the sum of these numbers:
#![allow(unused)] fn main() { fn sum_numbers_in_file(file_path: &Path) -> Result<i64, String> { let lines = match read_lines(file_path) { Ok(lines) => lines, Err(why) => return Err(why.to_string()), }; let numbers = match lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>() { Ok(numbers) => numbers, Err(why) => return Err(why.to_string()), }; Ok(numbers.into_iter().sum()) } }
We are using a helper function read_lines here, which is not part of the Rust standard library. All it does is reading a file line-by-line into a Vec<String>. Since this operation can fail, it returns std::io::Result<Vec<String>>. Also note that String::parse<T> returns a Result as well. If we were to collect the result of the map call into Vec<_>, we would get a Vec<Result<i64, ParseIntError>>. This would mean that we have to unpack every result and check if it is Ok or not. There is a shorter way, which is shown here: Collecting into a Result<Vec<i64>, ParseIntError>. This way, either all parse operations succeed, in which case an Ok value is returned, or the whole collect function early-exits with the first error that happened.
What we see in this code is a repeated pattern of matching on a Result<T, E>, continuing with the Ok value or early-exiting from the function with the Err value. This quickly becomes difficult to read. Since this is such a common pattern when working with Result<T, E>, the Rust language has a bit of syntactic sugar to perform this operation: The ? operator.
The ? operator is shorthand for writing this code:
#![allow(unused)] fn main() { // res is Result<T, E> let something = match res { Ok(inner) => inner, Err(e) => return Err(e), }; }
It only works in functions that return a Result<T, E> for Result<T, F> types, where F is convertible into E. With the ? operator, we can make our code much more readable:
#![allow(unused)] fn main() { fn sum_numbers_in_file_cleaner(file_path: &Path) -> Result<i64, String> { let lines = read_lines(file_path).map_err(|e| e.to_string())?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>() .map_err(|e| e.to_string())?; Ok(numbers.into_iter().sum()) } }
Unfortunately, since our function returns Result<i64, String>, we have to convert other error types into String by using map_err(). Let's try to fix that!
It is not uncommon that different functions that return Result values will have different error types. read_lines returned Result<_, std::io::Error>, while String::parse::<i64> returned Result<_, ParseIntError>. There is a common trait for all error types called Error. This is what Error looks like:
#![allow(unused)] fn main() { pub trait Error: Debug + Display { fn source(&self) -> Option<&(dyn Error + 'static)> { ... } fn backtrace(&self) -> Option<&Backtrace> { ... } // These two functions are deprecated: fn description(&self) -> &str { ... } fn cause(&self) -> Option<&dyn Error> { ... } } }
All types implementing Error have to implement the Debug and Display traits, so that the error can be converted into a human-readable representation. The Error trait also allows chaining errors together: source() returns the Error that caused the current error, if it is available. This is nice if you have a larger system with different subsystems where errors can propagate through many functions. Lastly there is a function to obtain a stack trace (backtrace()), but it is experimental at the moment of writing.
With the Error trait, we can try to write a function that returns an arbitary error, as long as it implements Error:
#![allow(unused)] fn main() { fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> { let lines = read_lines(file_path)?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>()?; Ok(numbers.into_iter().sum()) } }
This does not compile unfortunately. We try to use a trait like we would use a regular type and get both an error and a warning from the compiler:
warning: trait objects without an explicit `dyn` are deprecated
--> src/bin/chap5_result.rs:38:71
|
38 | fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> {
| ^^^^^^^^^^^^^^^^^ help: use `dyn`: `dyn std::error::Error`
|
= note: `#[warn(bare_trait_objects)]` on by default
= warning: this is accepted in the current edition (Rust 2018) but is a hard error in Rust 2021!
= note: for more information, see issue #80165 <https://github.com/rust-lang/rust/issues/80165>
error[E0277]: the size for values of type `(dyn std::error::Error + 'static)` cannot be known at compilation time
--> src/bin/chap5_result.rs:38:59
|
38 | fn _sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, std::error::Error> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
::: /Users/pbormann/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/src/rust/library/core/src/result.rs:503:20
|
503 | pub enum Result<T, E> {
| - required by this bound in `Result`
|
= help: the trait `Sized` is not implemented for `(dyn std::error::Error + 'static)`
The warning states that we have to use the dyn keyword when we refer to trait objects. Trait objects are Rusts way of dealing with types that implement some trait but whose type cannot be known at compile time. Think of trait objects like abstract base classes or interfaces in other languages. The compilation error actually relates to this: Objects whose type is not known at compile-time don't have a size known to the compiler. This is why the Rust compiler is complaining that our trait object (dyn std::error::Error) does not implement the Sized trait. Sized is a marker trait that is automatically implemented for all types that have a fixed size known at compile-time. Types that don't implement Sized are called dynamically sized types or DST for short. If you recall what we learned about how the compiler translates types into assembly code, one of the important properties was that the compiler has to figure out the size of types so that it can generate the appropriate instructions for memory access and so on. It is for this reason that Rust disallows storing DSTs in structs, enums, tuples, or to pass them by value to functions. The only option we have if we want to store an instance of a DST in some type is to store it on the heap, similar to how we used pointers and heap-allocations in C++ to store objects by their base class/interface. So let's use Box<T> to fix this problem:
#![allow(unused)] fn main() { fn sum_numbers_in_file_common_error(file_path: &Path) -> Result<i64, Box<dyn std::error::Error>> { let lines = read_lines(file_path)?; let numbers = lines .into_iter() .map(|str| str.parse::<i64>()) .collect::<Result<Vec<_>, _>>()?; Ok(numbers.into_iter().sum()) } }
This now happily compiles and we also got rid of the map_err() calls! This is called 'boxing errors' and is the standard way in Rust to deal with arbitrary errors returned from functions. Since it is so common, there is actually a crate for working with arbitrary errors, called anyhow!
The anyhow crate
The anyhow crate is a good default crate to include in your Rust projects because it makes dealing with arbitrary errors easy. It defines a new error type anyhow::Error and a default Result type Result<T, anyhow::Error>, which is abbreviated as anyhow::Result<T>, or simply Result<T> if you add a use statement: use anyhow::Result;. When using anyhow, anyhow::Result<T> can be used as the default return type for all functions that might fail:
#![allow(unused)] fn main() { use anyhow::Result; fn foo() -> Result<String> { Ok("using anyhow!".into()) } }
anhyow provides several convenience functions for working with errors. The context() function can be used by importing the Context trait (use anyhow::Context;) and allows you to add some contextual information to an error to make it more readable. It also comes in a lazy variant with_context, which takes a function that generates the context information only when an error actually occurs:
#![allow(unused)] fn main() { let file_data = std::fs::read(path).context(format!("Could not read file {}", path))?; let file_data = std::fs::read(path).with_context(|| format!("Could not read file {}", path))?; }
If you want to early-exit from a function with an error, you can use the bail! macro:
#![allow(unused)] fn main() { fn foo(parameter: &str) -> Result<()> { if !parameter.starts_with("p") { bail!("Parameter must start with a 'p'"); } } }
panic!
Sometimes, you encounter conditions in your code that are so bad that your program can't possibly recover from them. In such a situation, it is often best to simply terminate the program, ideally printing an error message to the standard output. To do this, Rust provides the panic! macro. panic! immediately terminates the current programActually it terminates the thread that it is called from, but since we won't talk about threads until chapter 7, it's easier to understand this way for now. and prints an error message to the standard output (technically to stderr), along with information about where in the code the panic! happened. We can use it like so:
pub fn main() { panic!("Panic from main"); }
Which gives the following output:
thread 'main' panicked at 'Panic from main', /app/example.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
panic! has an intimate relationship with the Result<T, E> and Option<T> types. Both types provide a method called unwrap(), which accesses the Ok(T) or Some(T) value directly without any pattern matching. In case that the Result<T, E> contains an Err(E) instead, or the Option<T> contains None, unwrap() will panic! and terminate the program. It is tempting to use unwrap() because it often produces shorter code and skips all the nasty error handling business, but terminating a program is pretty extreme. You will see unwrap() being used mostly in example/prototype code, or in rare situations where you as a programmer know that an Option<T> will never contain None or a Result<T, E> will never contain Err(E). Apart from that, prefer pattern matching or functions such as map() or is_some()/is_ok() over unwrap().
By using the environment variable RUST_BACKTRACE, we can also see where in the code the panic occurred.
Systems level I/O - How to make systems talk to each other
A core aspect of writing system software is to write it in a way that it can communicate with other software. These can be distributed systems in the cloud or on multiple servers, but also multiple systems on a single machine interacting with each other. To work together, systems have to exchange information with each other. There are a few different ways of doing this, which we are going to learn about in this section. All ways use some form of input/output (I/O), which refers to the process of copying data from external devices to main memory (input) or from main memory to external devices (output) {{#cite Bryant03}}.
In this chapter, we will learn about how to perform I/O with various external devices, such as the disk, a network or a terminal. In addition to that, we will learn about ways that the operating system provides to exchange signals between processes running on the same machine.
Here is the roadmap for this chapter:
- 6.1. The file abstraction
- 6.2. Network communication
- 6.3. Interprocess communication using signals and shared memory
- 6.4. Command line arguments, environment variables and program exit codes
6.1. The file abstraction
In this chapter, we will know about one of the most fundamental abstractions of modern computers: Files. Most people who have worked with a computer will have some rough intutition about what a file is. It's this thing that stores data, right? Except, we also store data in working memory, and in CPU registers, and on our GPU, and so on. But we don't call our CPU a file. So what makes a file special?
The basics of files
In technical terms, a file is defines as a sequence of bytes, nothing more and nothing less. Files can be stored persistently on a hard drive, but they can also come from non-persistent devices such as networks or a terminal. Here is an image of a file in memory:
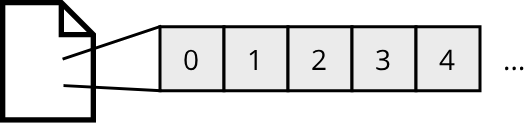
The file abstraction became very popular with the Unix-family of operating systems. Unix is built on the idea that all I/O operations can be modeled using files. So very input/output operation is based on a couple of 'atomic' operations on sequences of bytes called files:
- Open a file
- Read a range of bytes from a file
- Write a range of bytes to a file
- Changing the current position within a file
- Close a file
With these operations, we can read from the disk the same way as we would read from the network or any other I/O device. This is a powerful abstraction, because it reduces the complexity of various I/O operations (think about how using a network might be different from using a disk) to a simple set of operations. For us developers, this is very convenient.
Managing files and handling access to files is usually done by a part of the operating system called the file system. There are many different file system implementations in use today, such as ext4, ntfs, fat32 or zfs. You will even find file systems in other domains, such as distributed object storing services such as Amazon's AWS S3 service, which has its own file system. The study of file systems itself is not part of this course though.
One file system that is particularily interesting is the procfs file system on Linux. With procfs, we can get access to information about running processes using a bunch of files that we can read from (or write to to pass information to the process). This is very convenient because we can use standard command line tools such as cat or grep to work with processes.
A fundamental part of file systems is the management of file access. Programs have to be able to unqiuely identify each file through some sort of identifier. We call such an identifier a file path. Since users often interact with files, it makes sense to use text as the data type for file identifiers, so file paths are usually human-readable strings. Depending on the file system, file paths might contain additional information which is useful for grouping files together. On both Unix-systems and Windows, the file system can group multiple files together into directories, and this fact is represented in the file path. With directories, a hierarchical file structure can be formed, and this structure is represented through a path separator. Let's look at an example:
/home/asp/hello.txt
This path uniquely identifies a single file in a file system (ext4 in this case, though paths in most other file systems look similar). The path itself is simply a string, but we can break it up into several components using the path separator /:
/home: A directory namedhomewithin the root directory/of the file system. If all we had was the path/home, this could also point to a regular file, but since our path continues, we know thathomeis a directory./asp: A directory namedaspwithin thehomedirectory./hello.txt: A file namedhello.txtwithin theaspdirectory. The.txtpart is what is known as a file extension, which is a little piece of information that software can use to filter for files of a specific type (.txtis a common extension for text files, for example).
Seeing a path split up like this, the name path makes a lot of sense: It describes the path to a specific item within a tree-like structure (the file system)! The information whether an item within this tree is a file or a directory is stored within the file system itself. A simplified view of things is that the file system really is this tree-structure, where the entries are files and directories. In the ext4 file system (and several others), files and directories are different, but there are also file systems which do not have the concept of a directory, for example Amazon AWS S3.
The path separator itself is based on convention. Back in the early days of computing, Unix chose the / character for this, but Windows (more specifically its precursor MS DOS) chose \ (the backslash character) as the path separator. Modern Windows versions also support /, but the difference in path separators caused a lot of confusion in the past and is something to keep in mind.
The meaning of files
Since files are simply a sequence of bytes, what we use them for is up to us as developers. The meaning of these bytes comes solely from the interpretation of these bytes. A text file is a text file only because we define a special encoding that maps the positions and values of the bytes to text. For writing programs that work with files, this means that our programs have to know what kinds of files to expect. Working with text is often a good idea because text is such a fundamental data representation that many programming languages already provide mechanisms to interpret data as text when working with files. Sadly, text is not always an efficient representation, so many programs use different encodings to store their data in a more efficient format.
Here is an example to illustrate this: Suppose you have an image, which is made up of pixels. A common way to store image data is with red, green, and blue intensities for each pixel, so each pixel in the image is represented by 3 numbers. A sensible default for these numbers are 8-bit unsigned integers, giving 256 shades for each red-, green-, and blue-channel, or a total of \( 256^{3}=16777216 \) unique colors. If we represent each pixel in a binary format, using 8-bit unsigned integers, a single pixel takes exactly 3 bytes of memory. Since we know that each pixel has the same size, we can store the pixels tightly packed in memory, like this: rgbrgbrgb.... If we instead were to use a textual representation for the numbers, a single number can be between 1 and 3 characters long (e.g. 6, 95, 255). So either we add some separating character, or we pad with zeroes so that every number has the same amount of characters. If we assume that each character takes one byte of memory, we see that a textual representation takes three times the amount of memory than a binary representation.
Luckily, there are many standardized file formats available for various types of data. For compatibility reasons, it often makes sense to use a well-established file format instead of inventing a new format. The main factors are often efficiency and usability. Binary formats by their nature are more efficient to read and write, because no text-encoding/decoding has to be performed, but they are not human-readable. If files have to be inspected by humans, text-based formats are often preferred.
Common misconceptions about files
Since files are such a fundamental abstraction, there are a lot of misconceptions about files. First and foremost, we have to distinguish between the Unix file abstraction, which is an abstraction over an I/O device as we have seen, and files on a disk. We can have files in Unix systems that represent network connections, for example, and thus don't exist anywhere on the disk.
There is another common misconception that files on Windows systems are different than files on Unix systems. In general, this is not true, with two exceptions: Windows uses a different path separator, and Windows treats text files differently. A fundamental part of every text file is the concept of lines. Since text files really are just binary files with a special interpretation, some bytes within a text file have to represent the concept of a new line. There are two special characters that are often used for this, called the line feed (LF) and the carriage return (CR)These terms are old printer terminology. A line feed was equal to moving the printer head one row down, whereas a carriage return moved the printer head to the beginning (left) of the current line.. Unix systems use just a line feed to represent a new line, whereas Windows uses both a carriage return and a line feed.
The last misconception is about the meaning of file extensions, so things such as .txt or .pdf. Since the meaning of the bytes in a file depends on the interpretation of these bytes (called the file format), software has to know how to interpret a file to work with it. From just a raw sequence of bytes, how would anyone know what the correct file format of this file is? As a hint for applications, the file extension was established, which can help an application to filter for files that match an expected file format. The file extension however is purely encoded within the file path, it has no effect on the contents of the file! So you could rename a file foo.txt into foo.pdf, and this would leave the contents of the file unaltered. A PDF reader application might now think that this is a valid PDF file, but it probably won't be, because it was a text file initially (assuming that the initial file extension correctly represented the file in the first place).
Working with files on Linux
Access to files is managed through the operating system. On Linux, we have the POSIX API for this, with the following basic functions for handling files:
int open(char *filename, int flags, mode_t mode);int close(int fd);ssize_t read(int fd, void *buf, size_t n);ssize_t write(int fd, const void *buf, size_t n);
Linux also exposes some functions to access the file system directly, to get information about files and directories:
int stat(const char *filename, struct stat *buf);andint fstat(int fd, struct stat *buf);
On top of that, there are convenience functions in the C standard library for handling files:
fopen,fclose,fread,fwrite- Also for strings
fgetsandfputs - And for formatted I/O
scanfandprintf - Where the raw POSIX functions returned a file descriptor (an integer number identifying an open file for the operating system), the C standard library functions return a pointer to the opaque
FILEtype:FILE*
The advantage of the C standard library functions is that they are operating-system agnostic, which is a fancy term of saying: 'These functions work on any operating system (that supports a C library)'. If you were to use the raw POSIX functions, you would have to write different code when compiling your program for Windows. So what is called open on Linux is called CreateFileA on Windows.
Rust as a systems programming language should also work on multiple platforms, so we expect that Rust provides some abstractions for working with files as well, similar to the C standard library. The remainder of this chapter will deal with how files are represented in Rust.
Files in Rust
The Rust standard library has a lot of functionality in the standard library for working with files. Let's look at the first module for handling files: std::fs
If we look into std::fs, we will find a lot of functions and types for managing files and directories, such as create_dir or the Metadata type, but not a lot on how to read/write specific files. There is the File type and two functions to read an entire file into a String or vector as well as one function to write a slice as a whole file, but most other functions don't have anything to do with reading/writing files:
Remember when we said that the file abstraction is not the same thing as files in a file system? Rust makes this distinction as well, and the types for working with the file abstraction are located inside the std::io module instead! So let's look at std::io first!
The std:io module
std::io defines two core traits for doing I/O operations: Read and Write. It's not hard to guess what these two traits do: They provide means for reading and writing data. Since these are traits, they don't make any assumption on the source/target of these read and write operations. It could be a file, and indeed std::fs::File implements both Read and Write, but it could also be a network connection or even some in-memory buffer. In addition to these two traits, there is also the Seek trait, which provides useful functions for random access within a stream of bytes.
Here is what the Read trait looks like:
#![allow(unused)] fn main() { pub trait Read { fn read(&mut self, buf: &mut [u8]) -> Result<usize>; } }
It has one mandatory method that implementors have to define: read. When calling read, data from the type will be written into the provided buffer buf in the form of raw bytes (u8). Since read is an I/O operation, and I/O operations can frequently fail, the method returns the success status as a Result<usize> value, which will contain the number of bytes that were read in the Ok case, or the reason for failure in the Err case. The documentation of read has a lot more information on how this method is meant to behave, for now this is all we care about.
Here is what the Write trait looks like:
#![allow(unused)] fn main() { pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; } }
It is similar to Read, but requires two methods: write and flush. write is analogous to read, in that it takes a buffer of raw bytes and returns a Result<usize>. Where read took a mutable buffer, because this is where data is read into, write takes an immutable buffer for the data to be written. The return value of write indicates how many bytes were written in the Ok case, or the reason for failure in the Err case. Since writing is often buffered, there is also the flush method, which guarantees that all buffered data gets written to whatever destination the Write instance uses internally.
A quick look at Seek completes the picture for Rust's I/O abstractions:
#![allow(unused)] fn main() { pub trait Seek { fn seek(&mut self, pos: SeekFrom) -> Result<u64>; } pub enum SeekFrom { Start(u64), End(i64), Current(i64), } }
Seek also requires just one method to be implemented: seek. With seek, the current position to read from / write to within a Read/Write type can be manipulated. Since it is useful to either seek to an offset from the start, end, or current position of an I/O type, Seek uses the SeekFrom enum with the three variants Start(u64), End(i64), and Current(i64).
Exercise 6.1: Why does SeekFrom::Start wrap an unsigned integer, but SeekFrom::End and SeekFrom::Current wrap signed integers?
The std::fs and std::path modules
Now let's look at how to access files in a file system. As we already saw, the std::fs module contains functions and types to interact with the file system. The simplest way to access a file is by using the File type, like this:
use std::fs::File; use std::io::prelude::*; pub fn main() -> std::io::Result<()> { let mut file = File::create("test.txt")?; file.write_all(b"Test")?; Ok(()) }
Since files are typically either read or written, there are two convenience functions File::open and File::create for opening a file in read-only (open) or write-only (create) mode. For more control, the Rust standard library also provides the OpenOptions type. Since a file might not exist or might be inaccessible, these operations can fail and thus return Result<File>, so we use the ? operator here to simplify the code and get access to the File value in the success case. Since File implements both Read and Write, we can use all methods on these traits (if they are in scope, which is why we use std::io::prelude::*, which contains the two traits). write_all is a convenience method on Write that ensures that the whole buffer is written. b"Test" is some fancy syntax to create a byte array that corresponds to the text Test, since the methods on Write accept u8 slices and not str. We will see later how we can write string data more conveniently.
If you are curious, you might miss a call to flush in this code. In our case, File is not buffered internally, so there is no need to call flush. If a type requires a flush operation, one option is to implement Drop for the type and either call flush when the value of the type is dropped, or raise an error that the user forgot to call flush.
We accessed our file through a file path which we specified as a string literal: "test.txt". If we look at the definition of the File::create function, this is what we will see:
#![allow(unused)] fn main() { pub fn create<P: AsRef<Path>>(path: P) -> io::Result<File> { ... } }
It accepts a generic type P with the interesting constraint AsRef<Path>. AsRef is a trait for cheaply converting between borrows. It is similar to From, but is meant for situations where it is possible to cheaply obtain a borrow to a new type U from a borrow to a type T. As an example, the type &String implements AsRef<str>, indicating that there is a cheap way to go from a &String to a &str. Since &str is a borrowed string slice, and &String is a borrowed string, the conversion makes sense (&str will just point to the memory behind the String value). So here we have a constraint for AsRef<Path>, which means that any type is valid that can be converted to a borrow of a Path type (&Path). &str implements AsRef<Path>, so our code works.
Now, what is Path? It is a special type that represents a slice of a file path. It contains special methods for working with paths, like splitting a path into its components or concatenating paths. Since Path is only a slice, it is an unsized type and can only be used behind pointer types. There is an owned equivalent called PathBuf. Path and PathBuf are like str and String, but for file paths.
Working with paths in Rust takes some getting used to, because file paths are very close to the operating system but also include a lot of string handling, which is a complicated area in itself. Here are the most common ways of creating paths illustrated:
use std::path::*; fn main() { // Create a path from a string slice let p1 = Path::new("foo.txt"); // Create an owned PathBuf from a string slice let p2: PathBuf = "foo.txt".into(); //or PathBuf::from("foo.txt") // ...or from a Path let p3 = p1.to_owned(); //or p1.to_path_buf() // Getting a Path from a PathBuf let p4 = p3.as_path(); // Getting the string slice back from a path let str_slice = p1.to_str(); //Might fail if the Path contains invalid Unicode characters, which is valid for some operating systems // Building paths from separate components let p5 = Path::new("/usr").join("bin").join("foo.txt"); assert_eq!(p5.as_path(), Path::new("/usr/bin/foo.txt")); // Building paths from separate components using PathBuf let mut p6 = PathBuf::from("/usr"); p6.push("bin"); p6.push("foo.txt"); assert_eq!(p6, p5); // But beware: PathBuf::push behaves a bit weird if you add a path separator p6.push("/bin"); assert_eq!(p6.as_path(), Path::new("/bin")); //NOT /usr/bin/foo.txt/bin !! }
Path also has convenient methods to access the different components of a path (i.e. all the directories, potential file extension(s) etc.). To get every single component as an iterator, we can use components. To get a path to the parent directory of the current path, we can use parent, and to get only the file name of a path, file_name is used. Since paths are just strings with separators, all these methods don't have to allocate new memory and can instead return path slices (&Path) as well.
A Path also provides information about the file or directory it points to:
is_fileandis_dircan be used to determine if aPathpoints to a file or directory.metadatacan be used to get access to metadata about the file/directory (if possible). This includes the length of the file in bytes, last access time, or the access permissions.- For getting access to all files/directories within a directory, the useful
read_dirfunction can be used, which returns an iterator over all entries within the directory (if thePathrefers to a valid, accessible directory)
Writing strings to a Write type
In a previous section we saw that writing string data to a Write type can be a bit tricky, since the write method accepts a byte slice (&[u8]). The String type has a handy method bytes which returns a byte slice for the string, so we could simply use this. This works if we already have a String and just want to write it, but often we also have to create an appropriate String first. This is where the write! macro comes in! It combines the functionality of format! and writing data to a Write type:
use std::fs::File; use std::io::Write; fn main() -> std::io::Result<()> { let mut file = File::create("foo.txt")?; let the_answer: i32 = 42; write!(&mut file, "The answer is: {}", the_answer)?; Ok(()) }
Running this example will create a new file foo.txt with the contents: The answer is: 42. Notice the ? at the end of the write! macro call: Just as how calls to the raw write function on Writer could fail, calling the write! macro can fail as well, so write! returns a Result (in this case a Result<()>).
Buffered reading and writing
Under the hood, the read and write methods on File will use the file API of the current operating system. This results in system calls that have some overhead in addition to the raw time it takes to read from or write to the target I/O device. When frequently calling read or write, this overhead can slow down the I/O operations unnecessarily. For that reason, buffered I/O is often used. With buffered I/O, data is first written into an intermediate in-memory buffer, and only if this buffer is full (or flush is explicitly called) are the whole contents of the buffer written to the file using a single call to write. The process is similar for reading: First, as many bytes as possible are read into the buffer with a single read call, and then data is read from the buffer until the buffer has been exhausted, in which case the next chunk of data is read from the file.
Since this is such a common operation, Rust provides wrapper types for buffered reading and writing: BufReader and BufWriter. We can use these types like so:
use std::fs::File; use std::io::BufWriter; use std::io::Write; fn main() -> std::io::Result<()> { let mut file = BufWriter::new(File::create("foo.txt")?); let the_answer: i32 = 42; write!(&mut file, "The answer is: {}", the_answer)?; file.flush()?; Ok(()) }
Since BufWriter implements Write, our code is almost identical, the only difference to before is that we wrap our File instance in a BufWriter and that we explicitly call flush at the end. This last part is important: While BufWriter does call flush when it is dropped (by implementing Drop), dropping happens automatically, but flush can fail. To make this work, BufWriter ignores all potential errors of the flush call while being dropped, so we have no way of knowing whether our writes really succeeded or not.
When using BufReader and BufWriter, we usually pass the inner type (for example a File instance) by value to the new function of BufReader or BufWriter:
#![allow(unused)] fn main() { impl<W: Write> BufWriter<W> { pub fn new(inner: W) -> BufWriter<W> {...} } }
Since Rust is move-by-default, this consumes our inner type, which makes sense, because we only want to use it through the buffered I/O type now! But sometimes, it is useful to get the inner type back from a BufReader or BufWriter. For this, we can use the into_inner method:
#![allow(unused)] fn main() { pub fn into_inner(self) -> Result<W, IntoInnerError<BufWriter<W>>> }
into_inner consumes self, so after calling it, the BufReader or BufWriter instance is not usable anymore. This is neat, because it guarantees that there is always exactly one owner of the underlying I/O type. We can start out with a File, then pass it to BufWriter::new, at which point we can only do I/O through the BufWriter, because the File has been moved. At the end, we call into_inner, effectively destroying the BufWriter and giving us back the File. As a caveat, into_inner has to perform a flush operation before returning the inner type, otherwise some buffered data might be lost. Since this can fail, into_inner returns a Result whose Err variant returns the BufWriter type itself. If you don't want to flush, consider using into_parts instead!
More I/O convenience functions
Sometimes, all you really want is to read the whole contents of a file into either a String (if it is a text file) or a vector of bytes (Vec<u8>). Rust has you covered:
fn main() -> std::io::Result<()> { let file_as_string: String = std::fs::read_to_string("foo.txt")?; let file_as_bytes: Vec<u8> = std::fs::read("bar.bin")?; Ok(()) }
These convenience functions take the size of the file into account, if it is known, and thus are generally very efficient.
Exercise 6.2: Compare different ways of reading the contents of a file into a Vec<u8>. Try: 1) std::fs::read, 2) a single call to File::read using a preallocated Vec<u8>, 3) a single call to BufReader::read with a preallocated Vec<u8>, and 4) the bytes function on Read together with collect::<Result<Vec<_>, _>>?. Try to measure the performance using Instant::now. What do you observe?
Recap
In this chapter, we learned about the file abstraction. Files are simply sequences of bytes, and they are a useful abstraction for input/output (I/O) operations. We learned about how Unix systems treat files and then looked at what abstractions Rust provides for I/O and files. We saw that Rust strictly separates between I/O (using the Read and Write traits) and the file system (using the std::fs module). Lastly we saw how to use the necessary types and functions in practice, with things like buffered I/O and string writing.
6.2. Network communication
In this chapter we will look at network communication to enable processes running on different computers to exchange information.
Communication between computers
Using the file system is an easy way to have multiple processes communicate with each other, under the requirement that the processes run on the same machine. Modern computing architectures are increasingly moving towards networks of computers. The most prominent concept here is cloud computing: The availability of compute resources and storage without knowing (or caring about) the actual topology of the machines that do the work.
To connect multiple machines that are physically disjoint, we use computer networks, whose study warrants a lecture series on its own. In its essence, computer networks work through a combination of physical components and a bunch of protocols that dictate how data is exchanged between multiple computers. The most important technologies include Ethernet for wired connections and the IEEE 802.11 standard for wireless connections, as well as the protocols TCP/IP and HTTP. Describing the way computer networks work is the OSI model, which defines seven abstraction layers that cover everything from the physical connection of computers to the interpretation of bytes by applications:

On the level of systems programming, we usually deal with everything from level 4 (the transport layer) upwards. Rust for example provides APIs in the standard library for the levels 4 and 5, to create connections using the TCP or UDP protocols. Higher level protocols are then covered by libraries. Some application programming languages, for example JavaScript, focus solely on level 7 protocols, mainly HTTP. To get lower level support, things like WebSockets can be used.
Connections - The basic building block of network communication
Network communication is based on connections between two machines or processes. All network communication is based on a client-server principle, where one process (the server) provides access to some resource through a service to other processes called the clients.
At this point you might think: 'Wait a minute! What about peer-to-peer networks? Aren't they like the opposite of the client-server model?' Which is a viable question, especially seeing that more peer-to-peer technologies such as blockchains have emerged in recent years. At its core, any peer-to-peer network still uses a client-server model internally, the only difference is that in a peer-to-peer network, every machine or process can be both server and client at the same time.
Servers are always systems software! This is because they are meant to provide their functionality to other software, not to users directly. Communication with a server always works through client software, since most server applications don't have any form of user interface. As a systems programming language, Rust is thus a good choice for writing (high-performance) server code!
So how do network connections actually work? There are different technologies for establishing network connections, we will look at connections in the internet using the internet protocol (IP). Every network connection over the internet has to fulfill a bunch of requirements (as per {{#cite Bryant03}}):
- It is a point-to-point connection, meaning that it always connects a pair of processes with each other. This requires that each process can be uniquely identified. We will see in a moment how this works.
- It has to be a full-duplex connection, which is the technical term for a communications channel in which data can flow in both directions (client to server, and server to client).
- In general we want our network connections to be reliable, which means that the data sent from the source to the target eventually does reach the target. While Bryant et al. define this as a requirement for network connections, this does depend on the type of protocol used. If we want a reliable connection, TCP (transmission Control Protocol) is typically used nowadays, which guarantees that all data arrives in the same order it was sent and no data must be dropped. If this degree of reliability is not needed, for example in media-streaming services, Voice-over-IP applications or some multiplayer games, a simpler protocol called UDP (User Datagram Protocol) can be used, which makes no guarantees over order or reliability of the data transmission.
Identifying processes to establish connections using the Internet Protocol
Before we can establish a network connection, we need a way to identify processes so that we can connect them together. For this to work, we first need a way to uniquely identify machines connected to a network. We can use the Internet Protocol (IP) for this, which is a network layer protocol (layer 3 of the OSI model). With IP, data sent over a network is augmented with a small header containing the necessary routing information in order to deliver the data to the desired destination. Part of this header are unique addresses for the source and target machines called IP addresses.
There are two major versions of the IP protocol: Version 4 (IPv4) and version 6 (IPv6). Version 4 is currently (as of late 2021) the most widely used version in the internet, and it defines an IP address as an unsigned 32-bit integer. For us humans, IP addresses are usually written as a sequence of 4 bytes in decimal notation, separated by dots. As an example, 127.0.0.1 is a common IP address referring to the local machine, and it is the human-readable form of the IP address 0x7F000001. Since IPv4 uses 32-bit addresses, it can encode an address space of \(2^{32}=4,294,967,296\) unique addresses. Due to the large number of computers connected to the internet around the world, this address space is not sufficient to give a unique address to every machine, requiring techniques such as network address translation (NAT) which allows private networks of many machines to operate under one public IP address. Ultimately, IPv6 was devised to solve the problem of IP address shortage. IP addresses in IPv6 are 128-bit numbers, allowing a total of \(2^{128}=3.4*10^{38}\) unique addresses. Similar to IPv4 addresses, IPv6 addresses also have a human-readable form, consisting of up to eight groups of four hexadecimal digits each, separated by colons instead of dots: 2001:0db8:0000:0000:0000:8a2e:0370:7334 or 2001:db8::8a2e:370:7334 in a shortened form, is an example of an IPv6 address.
So with IP addresses, we can uniquely identify machines on a network. What about processes on a machine? Here, the operating system comes to help, and a trick is used. Instead of uniquely identifying processes, which would restrict each process to allow only one connection at most, we instead identify connection endpoints on a machine. These endpoints are called sockets and each socket has a corresponding address, which is a combination of the IP address of the machine and a 16-bit integer port number. If we know the IP address and port number of a service running on a server, we can establish a connection with this service from any other machine that is connected to the same network (disregarding network security aspects). Consequently, any service running on a server has to expose itself for incoming connections on a specific port so that clients can connect to this service. The concept of a socket is not part of the network layer, but instead of the transport layer (layer 4 of the OSI model), and as such is handled by protocols such as TCP and UDP. A socket address can look like this: 10.20.30.40:8000, which is a concatenation the IPv4 address 10.20.30.40 and the port number 8000 using a colon. This also works with IPv6 addresses, which have to be enclosed in square brackets however, because they already use a colon as separating character: [2001:db8::8a2e:370:7334]:8000 is the concatenation of the IPv6 address 2001:db8::8a2e:370:7334 and the port number 8000. A network connection can thus be fully identified by a pair of socket addresses.

When establishing a connection to a server, the client socket gets its port number assigned automatically from the operating system. For connections on the internet, we thus always use sockets. Many high level programming languages provide abstractions around sockets for higher-level protocols, for example to fetch data from the internet using the HTTP protocol, but ultimately, every connection is built around sockets.
Working with sockets in Rust
For the operating system, sockets are endpoints for connections and the operating system has to manage all low-level details for handling this connection, such as establishing the connection, sending and receiving data etc. Using the file abstraction, from the point of view of a program, a socket is nothing more than a file that data can be read from and written to. This is very convenient for development of network applications, because we can treat a network connection similar to any other file (illustrating the power of the file abstraction).
On Linux, the low-level details of working with sockets are handled by the socket API, but we will not cover it in great detail here. Instead, we will look at what Rust offers in terms of network connections. Sockets typically are covered in an introductory course on operating systems, so you should be somewhat familiar with them.
The Rust standard library provides a bunch of useful functions and types for networking in the std::net module. Let's look at the most important things:
First, there are a bunch of types for IP and socket addresses, with support for both IPv4 and IPv6: Ipv4Addr, Ipv6Addr, SocketAddrV4, and SocketAddrV6. These types are pretty straightforward, as the Rust documentation shows:
#![allow(unused)] fn main() { use std::net::{Ipv4Addr, SocketAddrV4}; let socket = SocketAddrV4::new(Ipv4Addr::new(127, 0, 0, 1), 8080); assert_eq!("127.0.0.1:8080".parse(), Ok(socket)); assert_eq!(socket.ip(), &Ipv4Addr::new(127, 0, 0, 1)); assert_eq!(socket.port(), 8080); }
Then there are the main types for managing network connections. Rust provides support for the two main layer-4 protocols UDP and TCP in the form of the types UDPSocket, TcpListener and TcpStream. Since UDP uses a connectionless communications model, there is no need to differentiate between the server and client side of the connection. For TCP, there is a difference, which is why Rust defines two different types for TCP connections. TcpListener is for the server-side of a connection: It exposes a specific port to clients and accepts incoming connections. The actual connections are handled by the TcpStream type.
Looking at the TcpStream type, we see that it implements the Read and Write traits, just like File does! This is the file abstraction at work in the Rust ecosystem. The neat thing about this is that we can write code that processes data without caring whether the data comes from a file or over the network. All the low-level details of how the data is transmitted over the network is handled by the Rust standard library and the operating system.
Writing network applications in Rust
Understanding network code is a bit harder than understanding regular code, because network code always requires multiple processes (at least one client and one server) that work together. So for our first venture into the world of network code, we will write only a server and use another piece of software to send data to the server: curl. curl is a command line tool for transferring data and can be used to easily connect to various servers to send and receive data.
Here is our first server application written in Rust, which accepts TCP connections at a specific port 9753, reads data from the connected client(s), prints the data to the console and sends the data back to the client(s) in reverse order:
use anyhow::{Context, Result}; use std::io::{Read, Write}; use std::net; fn main() -> Result<()> { let listener = net::TcpListener::bind("127.0.0.1:9753")?; for connection in listener.incoming() { let mut connection = connection.context("Error while accepting TCP connection")?; let mut buf: [u8; 1024] = [0; 1024]; let bytes_read = connection.read(&mut buf)?; let buf = &mut buf[..bytes_read]; println!("Got data from {}: {:?}", connection.peer_addr()?, buf); // Reverse the bytes and send back to client buf.reverse(); connection.write(buf)?; } Ok(()) }
This example uses the anyhow crate to deal with the various kinds of errors that can occur during network connections. As we can see, using the Rust network types is fairly easy. Calling TcpListener::bind("127.0.0.1:9753") creates a new TcpListener that listens for incoming connections to the port 9753 on the local machine (127.0.0.1). We get access to these connections by using the incoming method, which returns an iterator over all incoming connections, one at a time. Since there might be errors while establishing a connection, incoming actually iterates over Result<TcpStream, std::io::Error>. To get some more error information in case of failure, we use the context method that the anyhow crate provides. Once we have an established connection, we can call the usual methods from the Read and Write traits on it.
If we run this server, we can send data to it using curl. To send textdata, we can use the we can use the telnet protocol, like so: curl telnet://127.0.0.1:9753 <<< hello Running this from a terminal yields the following output:
curl telnet://127.0.0.1:9753 <<< hello
olleh%
If we inspect the server output, this is what we see:
Got data from 127.0.0.1:60635: [104, 101, 108, 108, 111, 10]
We see that our client connection ran on port 60635, which was a randomly assigned port by the operating system, and that the server received the following sequence of bytes: [104, 101, 108, 108, 111, 10]. If we translate these bytes into text using ASCII encoding, we see that they correspond to the string helloLF. The last character is a new-line character (LF), which explains why the response message starts with a new line.
Using our Rust server, we can write our first network client in Rust. Instead of using the TcpListener to listen for incoming connections, we directly create a TcpStream using TcpStream::connect:
use anyhow::Result; use std::io::{Read, Write}; use std::net::TcpStream; fn main() -> Result<()> { let mut connection = TcpStream::connect("127.0.0.1:9753")?; let bytes_written = connection.write(&[2, 3, 5, 7, 11, 13, 17, 23])?; let mut buf: [u8; 1024] = [0; 1024]; let bytes_read = connection.read(&mut buf)?; if bytes_read != bytes_written { panic!("Invalid server response"); } let buf = &buf[..bytes_read]; println!("Server response: {:?}", buf); Ok(()) }
It simply sends a series of bytes containing some Fibonacci numbers through the network connection to the server and reads the server response. Running our client from a terminal gives the following output:
Server response: [23, 17, 13, 11, 7, 5, 3, 2]
As expected, the server returned the numbers in reverse order. With these, we have laid the foundation for writing network code in Rust!
Protocols
With the functionality from the std::net module, we can send raw bytes between different processes, however this is very hard to use, because neither server nor client know what bytes they will receive from the other end. To establish a reasonable communication, both sides have to agree on a protocol for their communication. This happens on the last layer of the OSI model, layer 7, the application layer. Here applications define what byte sequences they use to communicate with each other, and how these byte sequences are to be interpreted. If you write your own server, you can define your own protocol on top of the lower-level protocols (TCP, UDP), or you can use one of the established protocols used for network communication between applications in the internet, such as HTTP.
You could implement these protocols manually, they are fully standardized, but there are many good implementations in the form of libraries available. Working with these libraries will require a bit more knowledge of Rust, in particular about asynchronous code, and we won't cover this until chapter 7, so we won't cover using HTTP in Rust until we know about these other features.
Exercise - Writing a prime number server
Without knowing any protocols, the range of network applications that we can reasonably implement in Rust is limited. To get a better feel for why protocols are necessary, try to implement the following server application in Rust using the TCP protocol:
Write a server that can compute compute prime factors for numbers, and can also compute prime numbers. It should support the following operations:
- Compute the
Nthprime number. By sending the positive integer numberNto the server, the server should respond with theNthprime number.- Example: Send
10to the server, and the server responds with29. Try to come up with a reasonable response ifNis too large for the server to handle!
- Example: Send
- Compute the prime factors of the positive integer number
N. The server should respond with all prime factors ofNin ascending order.- Example: Send
30to the server, and the server responds with2 3 5.
- Example: Send
- Check whether the positive integer
Nis a prime number.- Example: Send
23to the server, and the server responds with either1oryes
- Example: Send
To implement these functionalities, you will need some kind of protocol so that the server knows which of the three functions (compute prime, compute prime factors, check prime) it should execute. For the responses, you also need a protocol, because they will vary in length and content. Think about the following questions:
- Calling
readfrom the client on the connection to the server works with a fixed-size buffer. How can you ensure that you read the whole server response? - Both the
readandwritefunctions send raw bytes, but your server should support numbers larger than a single byte. Decide whether you want to send numbers in binary format or as strings. What are the advantages and disadvantages of each solution?
6.3. Interprocess communication using signals and shared memory
In the previous section, we talked about communication between processes using a network connection. While this is a very general approach, there are situations where you might want more performance, in particular if you have multiple processes on the same machine that have to communicate. In this chapter, we will cover techniques for exchanging data between processes on a single machine. This process is called interprocess communication.
Besides using network connections, there are two main ways for interprocess communication in modern operating systems:
- Signals
- Shared memory
Signals
Signals are a mechanism provided by the operating system to exchange small messages between processes. These messages interrupt the regular control flow of a process and are useful to notify a process that some event has happended. Signals are used to notify a process about some low-level system event, for example:
- An illegal instruction was encountered by the CPU
- An invalid memory address was being accessed
- A program tried to divide by zero
- A program has received a stop signal from the terminal
Signals are not useful if you have a lot of data to send to a process. Instead, signals are often used to communicate fatal conditions to a program, causing program termination. Some signals, such as the one for stopping a process, halt the program until another signal is received that tells the program to continue executing.
So what exactly is a signal? The concept of signals is implemented by the operating system, and here signals are basically just numbers that have a special meaning. All valid signals are specified by the operating system and can be queried from a terminal using man 7 signal on Linux (or just man signal on MacOS). For each number, there is also a (semi) human-readable name, such as SIGILL for an illegal instruction or SIGSEGV for invalid memory accesses.
When using signals, you always have one process (or the OS kernel) that sends the signal, and another process that receives the signal. Many signals are sent automatically by the OS kernel when their respective conditions are encountered by the hardware, but processes can also explicitly send a signal to another process using the killThe name kill is a historical curiosity. The kill function can be used to send various signals to a process, not just for killing the process, as the name would imply. Historically, this was the main reason for the function, but over time, the ability to send different signals than the default SIGKILL signal for terminating a process was added, but the name stayed. function. Processes react to incoming signals using signal handlers, which are functions that can be registered with the operating system that will be called once the process receives a certain signal. All signals have default behaviour if no signal handler is in place, but this behaviour can be overwritten by adding a signal handler in your program. On Linux, registering a function as a signal handler is done using the signal() function.
Signals are most useful for process control, for example putting a process to sleep, waking it again, or terminating it. Signals themselves have no way to carry additional information besides the signal number, so their use for interprocess communication is limited. If for example you want to send some string message from one process to another, signals are not the way to do that. It is nonetheless good to know about signals as you will encounter them when doing systems programming. Especially in C++, the dreaded SIGSEGV comes up whenever your program tries to access invalid memory. We will not go into more detail on signals here, if you are interested, most operating systems courses typically cover signals and signal handling in more detail.
Shared memory
To exchange more information between processes, we can use shared memory. Shared memory is a concept closely related to virtual memory. Remember back to chapter 3.2 when we talked about virtual memory. Every process got its own virtual address space, and the operating system together with the hardware mapped this virtual address space to physical memory. This meant that virtual pages in one process are distinct from virtual pages of another process. To enable two processes to share memory, they have to share the same virtual page(s), which can be done through special operating system routines (for example mmap on Linux).
Shared memory depends heavily on the operating system, and the way it is realized is different between Unix-like operating systems and Windows, for example. Even within Linux, there are multiple different ways to realize shared memory. We will look at one specific way using the mmap function, but keep in mind that other ways are possible as well.
The main idea behind shared memory is that two processes share the same region of a virtual address space. If two processes share a single virtual page, no matter where in physical memory this page is mapped, both processes will access the same memory region through this virtual page. This works similar to using a file that both processes access, however with mmap we can guarantee that the memory is always mapped into working memory. This way, a fast shared address space can be established between two processes.
Let's take a look at the mmap function and its parameters:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
- The first argument
void* addracts as a hint to the operating system where in the process' address space the mapping should happen, i.e. at which address. Since mapping virtual pages has page size granularity, an adjacent page boundary is chosen on Linux - The
size_t lengthargument determines the number of bytes that the mapping shall span int prodrefers to some flags for the kind of memory protection of the mapping. These are equal to the read and write protection flags that we saw in the chapter on virtual memory. On Linux, pages can also be protected for the execution of code.int flagsdefines flags for the mapping. We can useMAP_SHAREDto create a mapping that can be shared with other processes.int fdis a file descriptor (i.e., the file handle) to a file that should be mapped into the process' virtual address space.mmapis useful for more than just establishing shared memory, it is also one of the fastest ways for reading files (by mapping their whole contents to a virtual address range)- The
off_t offsetparameter is not relevant for this example, but can be used to map a specific region of an existing file into memory
If both processes use the same file descriptor when calling mmap, the same region of the physical address space gets mapped into the virtual address space of both processes and shared memory has been established. We can use an existing file for this mapping, or use the shm_open function to create a new shared memory object, which is simply a handle to be used for calling mmap to establish shared memory. When using shm_open, you can set the size of the shared memory region using ftruncate. Once the shared memory mapping is no longer needed, call munmap to unmap the shared memory object, and then close to close the file handle you obtained from shm_open.
The biggest caveat when using shared memory is that both reads and writes are unsynchronized. Think about what happens when one process writes a larger piece of data to shared memory, while the other process is reading from the same region of shared memory. Without any synchronization between the two processes, the process that reads might read first, reading only old data, or read somewhere inbetween while the data has been partially written. This is called a data race, we will learn more about it in the next chapter when we talk about concurrent programming. For now it is sufficient to understand that it is impossible to write a correct program without getting rid of data races, which we do by introducing some synchronization mechanism. These are also provided by the operating system and typically include ways to be used from multiple processes at the same time. Semaphores are one example.
Shared memory in Rust
The routines for creating and managing shared memory depend heavily on the used operating system. In contrast to memory management routines such as malloc, which are abstracted in the Rust standard library, shared memory has not made its way into the standard library. Instead, we have to use a crate such as shared_memory that provides a platform-independent abstraction over shared memory. This crate also provides some examples on how to use shared memory in Rust.
6.4. Command line arguments, environment variables and program exit codes
In this chapter, we will look at how you can control processes as a developer. This includes how to run multiple processes, how to react to process results and how to configure processes for different environments.
The standard input and output streams: stdin, stdout, and stderr
When starting a new process on Linux, the operating system automatically associates three files with the process called stdin, stdout, and stderr. These files can be used to communicate with the process. stdin (for standard input) is read-only from the process and is meant to feed data into the process. stdout (for standard output) and stderr (for standard error) are both write-only and are meant to move data out of the process. For output, there is a distinction made between 'regular' data, for which stdout is meant, and error information (or diagnostics), for which stderr is meant.
We are used to starting processes from a command line (which is itself a process). Command lines launch new processes by forking themselves and overwriting the forked process with the new executable. Both stdout and stderr are then automatically redirected to the corresponding files of the command line, which is why you see the output of a process invoked from the command line in the command line itself.
Rerouting of files is a common operation that command lines use frequently to combine processes. If we have two processes A and B, process A can feed information to process B simply by rerouting stdout of A to stdin of B.
So what can we use these input and output streams for? Here are some examples:
- Reading user input from the command line using
stdin - Passing data (text or binary) to a process using
stdin - Outputting text to the user through the command line using
stdout - Outputting diagnostic and error information using
stderr. It is very common thatstderr(andstdout) are redirected into named files in the filesystem, for example on servers to store logging information.
Command line arguments
stdin is a very flexible way to pass data into a process, however it is also completely unstructured. We can pass any byte sequence to the process. Often, what we want is a more controlled manner of passing data into a process for configuration. This could be a URL to connect to (like in the curl tool) or a credentials file for an SSH connection or the desired logging level of an application.
There are two ways for these 'configuration' parameters to be passed into a process: Command line arguments and environment variables. Both are related in a way but serve different purposes. We will look at command line arguments first.
You will probably know command line arguments as the arguments to the main function in C/C++: int main(int argc, char** argv). Each command line argument is a string (typically a null-terminated C-stringAs a quick reminder: C-strings (or null-terminated strings) are arrays of characters representing a text string, where the end of the string is indicated by a special value called the null-terminator, which has the numeric value 0.), and the list of command line arguments (argv) is represented by an array of pointers to these C-strings. This explains the somewhat unusual char** type: Each argument is a C-string, which is represented by a single char*. An array of these equals char**). By convention, the first command line argument usually equals the name of the executable of the current process.
Command line arguments are typically passed to a process when the process is being launched from the command line (or terminal or shell), hence their name. In a command line, the arguments come after the name of the executable: ls -a -l. Here, -a and -l are two command line arguments for the ls executable.
Since the command line is simply a convenience program which simplifies running processes, it itself needs some way to launch new processes. The way to do this depends on the operating system. On Linux, you use the execve system call. Looking at the signature of execve, we see where the command line arguments (or simply program arguments) come into play: int execve(const char *pathname, char *const argv[], char *const envp[])
execve accepts the list of arguments and passes them on to the main function of the new process. This is how the arguments get into main!
Using command line arguments
Since command line arguments are strings, we have to come up with some convention to make them more usable. You already saw that many command line arguments use some sort of prefix (like the -a parameterWindows tools tend to prefer /option over --option, which wouldn't work on Unix-systems because they use / as the root of the filesystem.). Often, this will be a single dash (-) for single-letter arguments, and two dashes (--) for longer arguments.
Command line arguments are unique to every program because they depend on the functionality that the program is trying to achieve. Generally, we can distinguish between several types of command line arguments:
- Flags: These are boolean conditions that indicate the presence of absence of a specific feature. For example: The
lsprogram prints a list of the entries in the current directory. By default, it ignores the.and..directory entries. If you want to print those as well, you can enable this feature by passing-aas a command line argument tols. - Parameters: These are arguments that represent a value. For example: The
cpcommand can be used to copy the contents of a source file into a destination file. These two files have to be passed as parameters tocp, like thiscp ./source ./destination - Named parameters: Parameters are typically identified by their position in the list of command line arguments. Sometimes it is more convenient to give certain parameters a name, which results in named parameters. For example: The
curltool can be used to make network requests on the command line, for example HTTP requests. HTTP requests have different types (GET,POSTetc.) which can be specified with a named parameter:curl -X POST http://localhost:1234/test- Named parameters are tricky because they are comprised of more than one command line argument: The parameter name (e.g.
-X) followed by one (or more!) arguments (e.g.POST)
- Named parameters are tricky because they are comprised of more than one command line argument: The parameter name (e.g.
All this is just convention, the operating system just passes an array of strings to the process. Interpreting the command line arguments has to be done by the process itself and is usually one of the first things that happens in main. This process is called command line argument parsing. You can implement this yourself using string manipulation functions, but since this is such a common thing to do, there are many libraries out there that do this (e.g. boost program_options in C++)
Command line arguments in Rust
In Rust, the main function looks a bit different from C++: fn main() {}. Notice that there are not command line arguments passed to main. Why is that, and how do we get access to the command line arguments in Rust?
Passing C-strings to main would be a bad idea, because C-strings are very unsafe. Instead, Rust goes a different route and exposes the command line arguments through the std::env module, namely the function std::env::args(). It returns an iterator over all command line arguments passed to the program upon execution in the form of Rust String values.
This is a bit more convenient than what C/C++ does, because the command line arguments are accessable from any function within a Rust program this way. Built on top of this mechanism, there are great Rust crates for dealing with command line arguments, for example the widely used clap crate.
Writing good command line interfaces
Applications that are controlled solely through command line arguments and output data not to a graphical user interface (GUI) but instead to the command line are called command line applications. Just as with GUIs, command line applications also need a form of interface that the user can work with. For a command line application, this interface is the set of command line arguments that the application accepts. There are common patterns for writing good command line interfaces that have been proven to work well in software. Let's have a look at some best practices for writing good command line interfaces:
1. Always support the --help argument
The first thing that a user typically wants to do with a command line application is to figure out how it works. For this, the command line argument --help (or -h) has been established as a good starting point. Many applications print information about the supported parameters and the expected usage of the tool to the standard output when invoked with the --help option. How this help information looks is up to you as a developer, though libraries such as clap in Rust or boost program_options in C++ typically handle this automatically.
Here is what the git command line client prints when invoked with --help:
usage: git [--version] [--help] [-C <path>] [-c <name>=<value>]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p | --paginate | -P | --no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
<command> [<args>]
These are common Git commands used in various situations:
start a working area (see also: git help tutorial)
clone Clone a repository into a new directory
init Create an empty Git repository or reinitialize an existing one
[...]
Here is a small command line application written in Rust using the clap crate:
use clap::{App, Arg}; fn main() { let matches = App::new("timetravel") .version("0.1") .author("Pascal Bormann") .about("Energizes the flux capacitor") .arg( Arg::with_name("year") .short("y") .long("year") .help("Which year to travel to?") .takes_value(true), ) .get_matches(); let year = matches.value_of("year").unwrap(); println!("Marty, we're going back to {}!!", year); }
Building and running this application with the --help argument gives the following output:
timetravel 0.1
Pascal Bormann
Energizes the flux capacitor
USAGE:
timetravel [OPTIONS]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-y, --year <year> Which year to travel to?
2. Provide both short (-o) and long (--option) versions of the same argument
This is really a convenience to the user, but often-used arguments should get shorthand versions. A good example of this can again be found in git: git commit -m is used to create a new commit with the given message. Here, the -m option is a shorthand for --message. It is simpler to type, but still has some resemblance to the longer argument, since m is the first letter of message. For single-letter arguments, make sure that they are reasonably expressive and don't lead to confusion.
In Rust using clap, we can use the short and long methods of the Arg type to specify short and long versions of an argument specifier.
3. Use the multi-command approach for complex tools
Some command line applications have so many different functionalities that providing a single command line argument for each would lead to unnecessary confusion. In such a situation, it makes sense to convert your command line application to a multi-command tool. Again, git is a prime example for this. It's primary functions can be accessed through named arguments after for git, such as git pull or git commit, where pull and commit are commands of their own with their own unique sets of arguments. Here is what git commit --help prints:
NAME
git-commit - Record changes to the repository
SYNOPSIS
git commit [-a | --interactive | --patch] [-s] [-v] [-u<mode>] [--amend]
[--dry-run] [(-c | -C | --fixup | --squash) <commit>]
[-F <file> | -m <msg>] [--reset-author] [--allow-empty]
[--allow-empty-message] [--no-verify] [-e] [--author=<author>]
[--date=<date>] [--cleanup=<mode>] [--[no-]status]
[...]
As we can see, the commit sub-command has a lot of command line arguments that only apply to this sub-command. Structuring a complex command line application in this way can make it easier for users to work with it.
Environment variables
Besides command line arguments, there is another set of string parameters to the exec family of functions. Recall the signature of execve: int execve(const char *pathname, char *const argv[], char *const envp[]). After the command line arguments, a second array of strings is passed to execve, which contains the environment variables. Where command line arguments are meant to describe the current invocation of a program, environment variables are used to describe the environment that the program is running in.
Environment variables are strings that are key-value pairs with the structure KEY=value. Since they are named, they are easier to user from an application than command line arguments.
Environment variables are inherited from the parent process. This means that you can set environment variables for your current terminal session, and all programs launched in this session will have access to these environment variables.
If you want to see the value of an environment variable in your (Linux) terminal, you can simply write echo $VARIABLE, where VARIABLE is the name of the environment variable.
There are a bunch of predefined environment variables in Linux that are pretty useful. Here are some examples:
$PATH: A list of directories - separated by colons - in which your terminal looks for commands (executables). Notice that when you write something likels -a, you never specified where thelsexecutable is located on your computer. With the$PATHenvironment variable, your terminal can find thelsexecutable. On the author's MacOS system, it is located under/bin/ls, and/binis part of$PATH$HOME: The path of the current user's home directory$USER: The name of the current user$PWD: The path to the current directory in the terminal. This is the same as calling thepwdcommand without arguments
If you want to see all environment variables in your terminal, you can run printenv on most Linux shells.
In Rust, we can get access to all environment variables in the current process using the std::env::vars function, which returns an iterator over key-value pairs.
An interesting question is whether to use command line arguments or environment variables for program configuration. There is no definitive answer, but it is pretty well established in the programming community that command line arguments are for things that change frequently between executions of the program (like the arguments to cp for example), whereas environment variables are for parameters that are more static (like a logging level for a server process). If you answer the question 'Is this parameter part of the environment that my program is running in?' with yes, then it is a good candidate for an environment variable.
Configuration files
If your process requires a lot of configuration, a better idea than to provide dozens of command line arguments can be to support configuration files. Command line arguments are only one way to get information into a process, no one is stopping you from implementing some file reading and pulling all the configuration parameters your program requires from a file. We call such a file a configuration file. How such a configuration file looks is a decision that each process has to make, however there are some standardized formats established today which are frequently used for configuration files:
- Linux traditionally uses mainly text-based key-value formats with file extensions such as
.confor.ini. Some tools also require some commands to be run at initialization, which are often specified in a special type of configuration file with an.rcprefix. On Linux, go check out your/etcdirectory, it contains lots of configuration files - For more complex configuration parameters, key-value pairs are often insufficient and instead, some hierarchical data structures are required. Here, common serializiation formats such as
JSON,XML, or the simplerYAMLformat are often used.
It is a good idea to make the path to the configuration file configurable as well, using either a command line argument or an environment variable.
Program exit codes
Up until now we only talked about getting data in and out of processes at startup or during the execution. It is often also helpful to know how a process has terminated, in particular whether an error occurred or the process exited successfully. The simplest way to do this is to make use of the program exit code. This is typically an 8-bit integer that represents the exit status of the process.
In Linux, we can use the waitpid function to wait for a child process to terminate and then inspect the status variable that waitpid sets to see how the child process terminated. This is how your shell can figure out whether a process exited successfully or not.
By convention, an exit code of 0 represents successful program termination, and any non-zero exit code indicates a failure. In C and C++, there are two constants that can be used: EXIT_SUCCESS to indicate successful termination, and EXIT_FAILURE to indicate abnormal process termination.
Running processes in Rust
Let's put all our knowledge together and work with processes in Rust. Here, we can use the std::process module, which contains functions to execute and manage processes from a Rust program.
The main type that is used for executing other processes is Command. We can launch the program program with a call to Command::new("program").spawn() or Command::new("program").output(). The first variant (spawn()) detaches the spawned process from the current program and only returns a handle to the child process. The second variant (output()) waits for the process to finish and returns its result. This includes the program exit code, as well as all data that the program wrote to the output streams stdout and stderr. Here is the signature of output:
#![allow(unused)] fn main() { pub fn output(&mut self) -> Result<Output> }
It returns a Result because spawning a process might fail. If it succeeds, the relevant information is stored in the Output structure:
#![allow(unused)] fn main() { pub struct Output { pub status: ExitStatus, pub stdout: Vec<u8>, pub stderr: Vec<u8>, } }
Notice that the output of stdout and stderr is represented not as a String but as a Vec<u8>, so a vector of bytes. This emphasizes the fact that the output streams can be used to output data in any format from a process. Even though we might be used to printing text to the standard output (e.g. by using println!), it is perfectly valid to output binary data to the standard output.
Putting all our previous knowledge together, we can write a small program that executes another program and processes its output, like so:
use std::process::Command; use anyhow::{bail, Result}; fn main() -> Result<()> { let output = Command::new("ls").arg("-a").output()?; if !output.status.success() { bail!("Process 'ls' failed with exit code {}", output.status); } let stdout_data = output.stdout; let stdout_as_string = String::from_utf8(stdout_data)?; let files = stdout_as_string.trim().split("\n"); println!( "There are {} files/directories in the current directory", files.count() ); Ok(()) }
In this program, we are using Command to launch a new process, even supplying this process with command line arguments themselves. In this case, we run ls -a, which will print a list of all files and directories in the directory it was executed from. How does ls know from which directory it was executed? Simple: It uses an environment variable, which it inherits from our Rust program, which itself inherits it from whatever process called the Rust program. The environment variable in question is called PWD and always points to the current directory. You can try this from your command line (on Linux or MacOS) by typing echo $PWD.
Back to our Rust program. We configure a new process, launch it and immediately wait for its output by calling output(). We are using the ? operator and the anyhow crate to deal with any errors by immediately exiting main in an error case. Even if we successfully launched the ls program, it might still fail, so we have to check the program exit code using output.status.success(). If it succeeded, we have access to the data it wrote to the standard output. We know that ls prints textual data, so we can take the bytes that ls wrote to stdout and convert them to a Rust String using String::from_utf8. Lastly, we use some algorithms to split this string into its lines and count the number of lines, which gives us the number of files/directories in the current directory.
While this program does not to much that you couldn't achieve on the command line alone fairly easily (e.g. using ls -a | wc -l), it illustrates process control in Rust, and shows off some of the other features that we learned about, like iterator algorithms (count) and error handling.
Recap
This concludes the section on process control, and with it the chapter on systems level I/O. We learned a lot about how processes communicate with each other and how we can interact with other devices such as the disk or the network in Rust. The important things to take away from this chapter are:
- The Unix file abstraction (files are just sequences of bytes) and how it translates to the Rust I/O traits (
ReadandWrite) - The difference between a file and the file system. The latter gives access to files on the disk through file paths and often supports hierarchical grouping of files into directories
- Network communication using the IP protocol (processes on remote machines are identified by the machine IP address and a socket address) and how network connections behave similar to files in Rust (by using the same
ReadandWritetraits) - Processes communicate simple information with each other through signals. If we want to share memory, we can do that by sharing virtual pages using shared memory
- Processes have default input and output channels called
stdin,stdout, andstderr, which are simply files that we can write to and read from - For process configuration, we use command line arguments and environment variables
Fearless concurrency - Using compute resources effectively
In this chapter, we will look at how to access the last of the important hardware resources: CPU cycles and with it, multiple CPU cores. We will learn about ways to write code in Rust that explicitly runs on multiple CPU cores using threads. We will learn about the ways things can go horribly wrong when we venture into the domain of parallel programming with threads, and how Rust helps us to keep our code safe. We will also look at a different concept for writing code that does many things concurrently, which is called asynchronous programming.
Here is the roadmap for this chapter:
- Threads and synchronization
- Applied concurrent programming in Rust using the
rayonandcrossbeamcrates - Asynchronous programming using
asyncandawait
Threads and synchronization
In the previous chapters, we learned a lot about memory as one of the major hardware resources. The other main hardware resource is of course the CPU itself, or more specifically the CPU cycles. We never really had to think about how to access CPU cycles because modern operating systems handle this for us. For many years however, processors have become faster not by increasing their clock rates, but instead by improving in their ability to execute multiple instructions in parallel. In this chapter, we will look at one way of accessing multiple CPU cores explicitly in our programs by using the operating system concept of a thread.
To understand threads, we will first look at how a modern CPU can execute instructions in parallel, and then move on to the role of the operating system, which provides the thread abstraction. Equipped with this knowledge, we will look at how to use threads in the Rust programming language, and which additional concepts are required to correctly use threads.
How your CPU runs instructions in parallel
As we saw in the chapter on memory management, there are physical limits to how fast we can compute things with electronic circuits (or any kind of circuit, really). To circumvent this problem for memory, we saw that cache hierarchies are used. How do we deal with the physical limitations when it comes to doing actual computations? Clearly, we can't just execute our instructions arbitrarily fast. So instead of running single instructions faster and faster, we try to run multiple instructions at the same time. This is called parallelism. Recall from chapter 2.2 that parallelism is a stronger form of concurrency. Where we did multiple things during the same time period with concurrency, parallelism implies that multiple things are happening at the same instant in time.
Modern processors have multiple ways of achieving parallelism. The most widely known concept is that of a multi-core processor, which is effectively one large processor made up of many smaller processors that can execute instructions (mostly) independent from each other. But even at the level of a single processor there are mechanisms in place to execute instructions in parallel. The major concepts here are called instruction-level parallelism, hyperthreading, and single instruction, multiple data (SIMD).
Instruction-level parallelism refers to the ability of a single processor core to execute multiple instructions at the same time. This is possible because executing a single instruction requires your processor to perform multiple steps, such as fetching the next instruction, decoding its binary representation, performing a computation, or loading data from memory. By running all these steps in a pipeline, multiple instructions can be in flight at the same time, as the following image shows:
While using such a pipeline does not mean that a single instruction executes faster (it does not increase the latency of an instruction), it means that more instructions can be processed in the same time (increasing the throughput).
Hyperthreading moves beyond the pipelining concept and instead duplicates some parts of the circuits on a processor core. Not every instruction requires all parts of the processor all the time. An instruction might have to wait for a memory access, during which time it doesn't require the circuits which perform the actual computations (the arithmetic logical unit (ALU)). By duplicating certain parts of the processor circuits, in particular the registers and program counter, multiple sequences of instructions and be executed in parallel. If one sequence encounters an instruction that has to wait on memory, the other sequence might be able to continue with an instruction that needs the ALU.
The last concept is single instruction, multiple data (SIMD), and refers to special hardware which can process larger amounts of data with a single instruction. Think of a regular add instruction. On x86-64, add can use the general-purpose registers two add two values of up to 64 bits length to each other. SIMD introduces larger registers, such as the XMM registers, which can store 128 bits and thus up to four 32-bit floating point values at once. The special part about SIMD instructions is that a single instruction operates on all values in an XMM register at the same time. So with a single SIMD instruction, it is possible to add four 32-bit floating point values together at once. Used correctly, these instructions make it possible to process multiple pieces of data simultaneously, thus achieving parallelism.
What are threads and why are they useful?
We saw that there are many ways in which a CPU can run instructions in parallel. What does this mean for us as programmers? How can we access the latent potential for parallelism in our CPUs?
Instruction-level paralleism and hyperthreading are things that the CPU does automatically, we as developers have no control over these features. SIMD can be used by writing code that explicitly uses the SIMD registers and instructions. We can either do this ourselves by using the appropriate assembly instructions, or hope that our compiler will generate SIMD code. This leaves multiple CPU cores as the last area. How do we explicitly run our code on multiple cores at the same time?
When using a modern operating system, the operating system helps us here. When we run our code, we do so by asking the operating system to create a new process and execute the code from a given binary within the context of this process. So this code has to get onto the CPU somehow. Luckily for us, the operating system manages this by using the process scheduler, which is a piece of code that maps processes onto CPU cores. The details of this are usually covered in an introductory operating systems course, so here is the brief version:
A typical operating system scheduler runs each CPU core for a short amount of time, a few milliseconds for example, then interrupts the CPU core, effectively halting its current computation. At this point, a single process has been executing on this CPU core. What about all the other processes on this machine? It is not unusual for a modern computer to run hundreds of processes at the same time. If there are only 4 CPU cores available, clearly we can't run all processes on these CPU cores, because each CPU core can process one, maybe two (with hyperthreading) sequences of instructions at once. So all other processes are sitting idly on this machine, which their state (the content of the registers) being stored somewhere in memory. During the interruption of a CPU core, the scheduler now takes another process which hasn't run in some time and moves this process onto the CPU core. To not disturb the process that was running on the core before, the data of the old process is cached in memory, and the data for the new process is restored from memory. This process repeats very frequently, thus giving your computer the ability to run many more programs than there are CPU cores.
So there we have it: Our program is put onto an arbitrary CPU core automatically by the schedulerThis is only true for general-purpose operating systems such as Linux or Windows. There are also real-time operating systems where scheduling can be controlled more closely by the developer.. But only a single core at a time. What if we want our program to run on multiple cores at the same time? How would that even look like from our code?
To understand how to run a single program on multiple cores, we have to understand the concept of a thread of execution.
Bryant and O'Hallaron define a thread as a 'logical flow that runs in the context of a process' {{#cite Bryant03}}. In other terms, threads are sequences of instructions that can operate independently from each other. In a typical imperative program, we have exactly one sequence of instructions that gets executed, as the following image shows:
This sequence of instructions is defined by the program counter, the CPU register that always points to the next instruction that is to be executed. Just as we can have multiple processes that each have their own program counter, we can have multiple threads with their own program counter running within the same process. Where two processes have their own separate address spaces, two threads within a process share the same address space. Threads thus can be seen as a more light-weight alternative to processes.
Each thread has a unique thread context, which is simply all the information unique to each thread, such as the program counter, other CPU register values, a unique address range for the stack, the stack pointer, as well as a unique thread ID. Compared to a process, a thread is much more lightweight. Since all threads within a process share the same address space, it is also easier to share data between threads as it is to share data between processes.
How the operating system manages threads
Threads are a concept for concurrency realized on the level of the operating system, and they are thus managed by the operating system. A thread behaves similar to any other resource in that it can be acquired from the operating system and has to be released back to the operating system once it is no longer needed. For threads, creating a new thread is often called spawning a new thread, and releasing a thread back to the operating systems is done by joining with the thread.
The necessary resources attached to a thread, such as its stack space, are created on demand by the operating system when a new thread is created, and are released again when the thread is joined with. Similar to heap memory or file handles, if we forget to join with a thread, the operating system will clean up all remaining threads once its parent process terminates. This can have suprising effects, as these threads might still do some useful work, so we better make sure that we join with these threads.
In all of the major operating systems, each process starts out with exactly one active thread at startup, called the main thread.
On Linux, we can use the POSIX API for managing threads, which contains functions such as pthread_create and pthread_join that we can use for creating a thread and joining with another thread. The signature of pthread_create is interesting:
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
Besides a pointer to the resource handle for the thread (pthread_t* thread), pthread_create expects a function pointer (void*(*start_routine)(void*)). This pointer refers to the function that will be the entry point of the newly created thread. For this thread, execution will start with the function pointed to by start_routine, just as how the entry point for a process in a C program is the main function. Since threads in a process share an address space, it is also possible to pass data directly into the newly created thread, using the void* arg argument.
Working with these C functions can become cumbersome quickly for the same reasons that we saw when working with memory and files. For that reason, systems programming languages such as C++ or Rust provide abstractions for threads in their standard libraries that provide a safer interface and abstract over operating system details. In C++, threads are handled by the std::thread type, in Rust we use the std::thread module.
Threads in Rust
Here is an overview of the std::thread module in Rust:
Spawning a new thread is a simple as calling std::thread::spawn in Rust:
pub fn main() { let join_handle = std::thread::spawn(|| { println!("Hello from new thread"); }); println!("Hello from main thread"); join_handle.join().unwrap(); }
Just as the low-level POSIX API, the Rust API for creating threads expects that we pass a function to spawn. This function is then executed on the newly created thread. To make sure that we actually clean up this new thread, spawn returns a handle to the thread that we can use to join with the thread. We do so by calling the join() function on this handle. join() waits for the new thread to finish its execution, which it does by waiting until the new thread exits the function that we provided to it, either successfully or with an error (e.g. by calling panic!). Because of this, join() returns a Result.
Let's try to do something more elaborate and do some computation on the newly created thread. In Rust, we can return a value from a thread and get access to this value as the return value of join() in the Ok case:
fn is_prime(n: &usize) -> bool { let upper_bound = (*n as f64).sqrt() as usize; !(2_usize..=upper_bound).any(|div| *n % div == 0) } fn nth_prime(n: usize) -> usize { (2_usize..).filter(is_prime).nth(n).unwrap() } pub fn main() { let prime_index = 1000; let join_handle = std::thread::spawn(|| { nth_prime(prime_index) }); let prime = join_handle.join().unwrap(); println!("The {}th prime number is: {}", prime_index, prime); }
Unfortunately, this example doesn't compile. Let's see what the compiler has to say:
error[E0373]: closure may outlive the current function, but it borrows `prime_index`, which is owned by the current function
--> <source>:12:42
|
12 | let join_handle = std::thread::spawn(|| {
| ^^ may outlive borrowed value `prime_index`
13 | nth_prime(prime_index)
| ----------- `prime_index` is borrowed here
|
note: function requires argument type to outlive `'static`
--> <source>:12:23
|
12 | let join_handle = std::thread::spawn(|| {
| _______________________^
13 | | nth_prime(prime_index)
14 | | });
| |______^
help: to force the closure to take ownership of `prime_index` (and any other referenced variables), use the `move` keyword
|
12 | let join_handle = std::thread::spawn(move || {
| ++++
The problem is that the function we pass to spawn might live longer than the current function (main). This makes sense, since a thread is an independent strand of execution, that might execute longer than main. In fact, we see this in the signature of spawn:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
The function f has to have 'static lifetime, and we know that a variable declared inside main does not have 'static lifetime.
Looking back at our error, the problem is not that the function might live longer than main, but that this function borrows a variable that we declared inside main (the variable prime_index). The Rust compiler gives us the solution: Instead of borrowing the value, we have to take ownership of the value. We do this by prefixing our anonymous function with the move keyword. This way, all data that was borrowed previously now gets moved into the body of the function. Since our prime_index is Copy, this is no problem. Fixing this little error makes our program run successfully:
pub fn main() { let prime_index = 1000; let join_handle = std::thread::spawn(move || { nth_prime(prime_index) }); let prime = join_handle.join().unwrap(); println!("The {}th prime number is: {}", prime_index, prime); }
Writing code with threads
With threads, we can write code that potentially executes in parallel, meaning that multiple instructions are executed at the same point in time. This of course requires that our CPU has more than a single logical core, but most modern CPUs have multiple cores. So how do we make good use of this power?
The study of concurrent and parallel code is a huge field that we can't possibly hope to cover as part of this course. We will cover some basics here and in the process illustrate some of the measures that Rust takes to make concurrent code safe to execute. At its core, working with threads (or any other concurrency concept) is typically about identifying parts of an algorithm that can be executed concurrently without changing the outcome of the algorithm. While not a strict requirement, we typically want the concurrent algorithm to run faster than the sequential algorithm. 'Running faster' is a losely defined term here, there are some more precise definitions that we won't cover because they are not necessary to our understanding of concurrent code.
Broadly speaking, we can use threads for two scenarios: Doing more things at once, or doing the same thing faster.
An example of doing more things at once is a server that wants to deal with multiple connections at the same time. We can put each connection onto a separate thread and thus handle multiple connections concurrently.
An example for making something faster through using threads would be a concurrent search algorithm. Instead of looking through a large collection sequentially, we can split the collection up into disjoint subsets and search each subset on a separate thread. In an ideal world, if we use N threads running in parallel, our algorithm will run N times faster because each thread only has one Nth of the work to do, but all threads perform their work at the same time, so the total runtime is 1 / N.
We will mainly cover the second type of concurrent code in the remainder of this chapter, by working through an example of a concurrent search algorithm.
A text search algorithm
To see how we can use threads to speed up a program, we will implement a simple text search application. The idea is to take a String and some keyword and count the number of non-overlapping occurrences of they keyword within the String. Here is how this might look like using the regex crate:
#![allow(unused)] fn main() { fn search_sequential(text: &str, keyword: &str) -> usize { let regex = Regex::new(keyword).expect("Can't build regex"); regex.find_iter(text).count() } }
Since neither the text nor the keyword need to be mutated, we use string slices for both arguments. The find_iter function of the Regex type then gives us an iterator over all non-overlapping occurrences of our keyword within text.
How would we go about implementing this algorithm using threads? One way is to use the fork-join pattern {{#cite mattson2004patterns}}. The idea of fork-join is to split up the data into several smaller units that can be processed independently ('fork'), and then combine the results of these parallel computations into the final result ('join'):
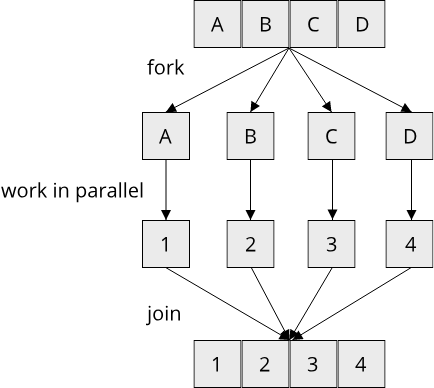
Applying the fork-join pattern to our text search application, we see that we first have to split our text into smaller chunks that we can process independently. To make our algorithm easier, we will restrict the keyword that we are looking for to be a single word that must not include any whitespace. Then, the order in which we search through our text becomes irrelevant. We could start at the beginning and move towards the end, or start at the end and move towards the beginning, or look at all words in random order. In all cases, the number of matches will stay the same. This is good news for our effort to parallelize the text search algorithm, as it means that we can process parts of the text in parallel without changing the outcome.
So let's split up our text into smaller chunks so that we can process each chunk on a separate thread. To make sure that all threads process an equal amount of data, we want to split our text into equally-sized chunks. We can't split in the middle of a word however, as this would change the outcome of the algorithm, so we have to split at a whitespace character.
We will simply assume that we have a magical function fn chunk_string_at_whitespace(text: &str, num_chunks: usize) -> Vec<&str> that splits a single string into num_chunks disjoint substrings at whitespace boundaries. If you want, you can try to implement this function yourself. With this function, we can then start to use threads to implement a parallel word search algorithm. The idea is to split the string first and run our sequential word search algorithm on each substring (the fork phase), then combine the results of each sequential word search into a single number using addition (the join phase):
#![allow(unused)] fn main() { fn search_parallel_fork_join(text: &str, keyword: &str, parallelism: usize) -> usize { let chunks = chunk_string_at_whitespace(text, parallelism); let join_handles = chunks .into_iter() .map(|chunk| std::thread::spawn(move || search_sequential(chunk, keyword))) .collect::<Vec<_>>(); join_handles .into_iter() .map(|handle| handle.join().expect("Can't join with worker thread")) .sum() } }
There is a lot to unpack here. First, we create our chunks using the chunk_string_at_whitespace function. Then, we want to run search_sequential for each chunk, so we use chunks.into_iter().map(). Inside the map function, we spawn a new thread and call search_sequential on this thread. We then collect the join handles for all threads into a collection. We then join() with all threads, which returns the result of each search_sequential call. To get the final number of matches, we sum() the individual results.
The fork-join pattern becomes clearly visible in this code: First we fork by mapping over our split data and creating a thread for each chunk, then we join by joining with the join handles of the threads and combining the results (in this case using the sum algorithm).
This would be great and fairly simple, except that there is a slight problem. Let's try to compile this code:
error[E0759]: `text` has an anonymous lifetime `'_` but it needs to satisfy a `'static` lifetime requirement
--> src/bin/chap7_textsearch.rs:72:18
|
71 | fn search_parallel_fork_join(text: &str, keyword: &str, parallelism: usize) -> usize {
| ---- this data with an anonymous lifetime `'_`...
72 | let chunks = chunk_string_at_whitespace(text, parallelism);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^----^^^^^^^^^^^^^^
| |
| ...is captured here...
...
76 | .map(|chunk| std::thread::spawn(move || search_sequential(chunk, keyword)))
| ------------------ ...and is required to live as long as `'static` here
Remember that std::thread::spawn required a function with 'static lifetime? Neither our text nor our keyword has 'static lifetime, so the compiler doesn't accept this code. This is a bit unfortunate, because we know that the threads only live as long as the search_parallel_fork_join function, because we are joining with them at the end of the function! But the Rust standard library doesn't know this and also has no way of figuring this out, so it makes the safest assumption, which is that everything that gets moved onto the thread has 'static lifetime.
The easiest (but not necessarily most efficient) way to fix this is to use String instead of &str and give each thread a unique copy of the data:
#![allow(unused)] fn main() { let chunks = chunk_string_at_whitespace(text, parallelism) .into_iter() .map(|str| str.to_owned()) .collect::<Vec<_>>(); let join_handles = chunks .into_iter() .map(|chunk| { let keyword = keyword.to_owned(); std::thread::spawn(move || search_sequential(chunk.as_str(), keyword.as_str())) }) .collect::<Vec<_>>(); }
So instead of splitting our text into a Vec<&str>, we now split into Vec<String>, which assures that we can move an owned chunk into each thread. For the keyword, we create a local owned copy by calling keyword.to_owned() prior to spawning the thread and move this copy into the thread as well.
Now lets reap the fruits of our labor and run our parallel text search algorithm. First, let's check for correctness. The following example searches for a specific genome sequence in the GRCh38 Reference Genome Sequence, which is about 3.3 GB large, so a good candidate for a fast text search algorithm.
fn get_large_text() -> Result<String> { let genome = std::fs::read_to_string("GRCh38_latest_genomic.fna")?; Ok(genome.to_uppercase()) } fn main() -> Result<()> { let text = get_large_text().context("Can't load text")?; let keyword = "TTAGGG"; //The telomere repeat sequence println!( "Matches (sequential): {}", search_sequential(text.as_str(), keyword) ); println!( "Matches (parallel): {}", search_parallel_fork_join(text.as_str(), keyword, 12) //12 is the number of cores on the test machine ); Ok(()) }
Running this code yields the following output:
Matches (sequential): 541684
Matches (parallel): 541684
Great, our code is correct! Now let's see if we actually got a performance improvement from running on multiple threads. We can do some simple performance measurements by using the std::time::Instant type, which can be used to measure elapsed time. We can write a little helper function that measures the execution time of another function:
#![allow(unused)] fn main() { fn time<F: FnOnce() -> ()>(f: F) -> Duration { let t_start = Instant::now(); f(); t_start.elapsed() } }
With this, let's check the runtime of our two algorithms:
fn main() -> Result<()> { let text = get_large_text().context("Can't load text")?; let keyword = "TTAGGG"; //The telomere repeat sequence println!( "Time (sequential): {:#?}", time(|| { search_sequential(text.as_str(), keyword); }) ); println!( "Time (parallel): {:#?}", time(|| { search_parallel_fork_join(text.as_str(), keyword, 12); }) ); Ok(()) }
Which gives the following output:
Time (sequential): 1.359097456s
Time (parallel): 1.942474468s
Well that's disappointing. Our parallel algorithm is a lot slower than our sequential algorithm. What is happening here? If we investigate closer, we will find that the majority of time is spent on splitting our text into chunks and converting those chunks to owned strings. Splitting the text at whitespace itself is super fast and takes less than a millisecond, but converting the Vec<&str> into a Vec<String> takes a whooping 1.7s. Here we see a good example of why copying data can have a large performance impact!
The good news is that there are ways to prevent copying the data, however we will have to postpone the study of these ways to a later chapter. First, we will look at a slightly different way of tackling the text search algorithm with multiple threads.
Mutating data from multiple threads
With the fork-join model, we worked exclusively with immutable data: All data that the threads worked on was immutable, and the thread results were immutable as well. The code for this was fairly clean, however it came at the cost of increased copying. Let's specifically look at the output data of our parallelized text search algorithm:
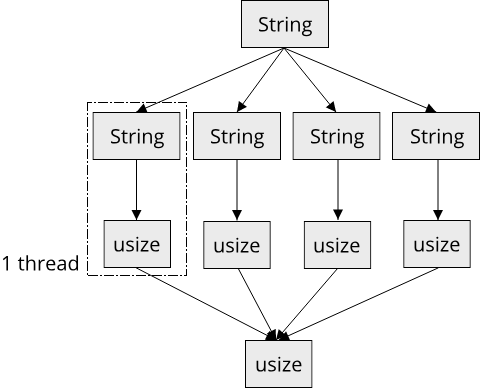
For our algorithm, the data that each thread generates is fairly small, a single usize value. Since we don't have a lot of threads, this is fine, compared to the sequential solution we do generate N times more output data, where N is the number of threads, but the difference is miniscule because each output value only takes 8 bytes on a 64-bit machine. But suppose we didn't want to only find all occurrences of a keyword in a string, but instead overwrite them with another string. Now the output of our algorithm becomes a mutated version of the input:
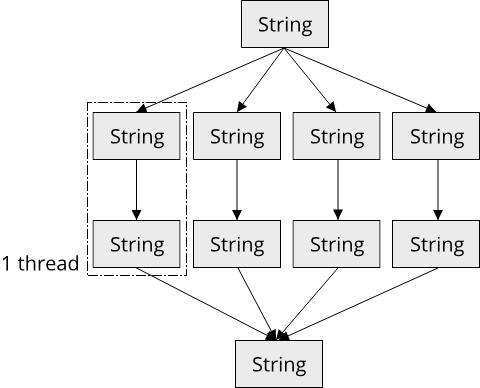
If our input data is a gigabyte large, duplicating it N times suddenly doesn't seem like such a good idea anymore. It would be better if each thread could simply mutate the original data. Unfortunately, overwriting strings in-place in Rust is almost impossible due to the fact that Rust strings are using Unicode as their encoding. So to make our lives easier, instead of overwriting strings, let's overwrite values in a Vec instead. The DNA example is neat, overwriting DNA sequences has a sort-of Frankenstein vibe, so we will use a Vec<Nucleobase>, where Nucleobase is a simple enum defining the four different nucleobases existing within the DNA:
#![allow(unused)] fn main() { #[derive(Copy, Clone, Debug, PartialEq, Eq)] enum Nucleobase { A, G, C, T, } }
We also implement TryFrom<char> for Nucleobase so that we can convert our human genome text into a Vec<Nucleobase>. Now let's try to write our magic DNA editing function:
#![allow(unused)] fn main() { fn dna_editing_sequential( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], ) { // ... omitted some checks for correctness of sequence lengths let sequence_len = old_sequence.len(); let mut start: usize = 0; let end = source.len() - sequence_len; while start < end { let is_match = { let cur_sequence = &source[start..start + sequence_len]; cur_sequence == old_sequence }; if is_match { source[start..start + sequence_len].copy_from_slice(new_sequence); start += sequence_len; } else { start += 1; } } } }
We can't use our Regex type anymore unfortunately, so we have to implement the sequence search manually. We go over the whole string and whenever we find a matching sequence, we use the copy_from_slice method to overwrite the old sequence with the new sequence within the source slice. Note how we don't have to pass a &mut Vec<Nucleobase> and instead can pass a mutable slice!
We now want to parallelize this algorithm using threads, just as we did with the text search before. But instead of using the fork-join pattern, we want to mutate the source value in-place. To make this work, we want to give each thread a unique subset of the source slice to work on. We can use a powerful method called chunks_mut which splits a single mutable slice into multiple disjoint chunks. That is exactly what we want, how nice of the Rust standard library to support something like this! Let's try it out:
#![allow(unused)] fn main() { fn dna_editing_parallel( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], parallelism: usize, ) { if old_sequence.len() != new_sequence.len() { panic!("old_sequence and new_sequence must have the same length"); } let chunk_size = (source.len() + parallelism - 1) / parallelism; let chunks = source.chunks_mut(chunk_size).collect::<Vec<_>>(); let join_handles = chunks .into_iter() .map(|chunk| { std::thread::spawn(move || dna_editing_sequential(chunk, old_sequence, new_sequence)) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); } }
This almost works, but of course the compiler complains again because of wrong lifetimes. Our slices don't have 'static lifetime, so the thread function is not accepting them. Previously, we solved this by copying the data, but we saw that this can have quite the performance overhead. The problem is that every thread wants to own the data it works on. Do we know of a way to have multiple owners to the same data?
Turns out we do: Rc<T>! Maybe we can use reference counting to give each thread a clone of the Rc<T>? Let's try this:
#![allow(unused)] fn main() { fn dna_editing_parallel( source: Vec<Nucleobase>, old_sequence: Vec<Nucleobase>, new_sequence: Vec<Nucleobase>, parallelism: usize, ) { let source = Rc::new(RefCell::new(source)); let join_handles = (0..parallelism) .into_iter() .map(|chunk_index| { let source_clone = source.clone(); let old_sequence = old_sequence.clone(); let new_sequence = new_sequence.clone(); std::thread::spawn(move || { let mut source = source_clone.borrow_mut(); dna_editing_sequential( &mut *source, old_sequence.as_slice(), new_sequence.as_slice(), ) }) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); } }
For now, we ignore the splitting-up-into-chunks parts and only focus on getting each thread their own clone of the source data behind a Rc. We are also using RefCell so that we can get mutable access to the data within the Rc. If we compile this, we get an interesting error message:
error[E0277]: `Rc<RefCell<Vec<Nucleobase>>>` cannot be sent between threads safely
--> src/bin/chap7_textreplace.rs:108:13
|
108 | std::thread::spawn(move || {
| _____________^^^^^^^^^^^^^^^^^^_-
| | |
| | `Rc<RefCell<Vec<Nucleobase>>>` cannot be sent between threads safely
109 | | let mut source = source_clone.borrow_mut();
110 | | dna_editing_sequential(
111 | | &mut *source,
... |
114 | | )
115 | | })
| |_____________- within this `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`
|
= help: within `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`, the trait `Send` is not implemented for `Rc<RefCell<Vec<Nucleobase>>>`
= note: required because it appears within the type `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`
We see a new requirement pop up, namely that our type Rc<RefCell<Vec<Nucleobase>>> does not implement a trait called Send, which is required in order for the type to be 'sent between threads safely'. Prepare for a deep dive into the world of Rust concurrency, this is where things are getting spicy!
Send and Sync - How Rust guarantees thread safety at compile-time
Remember that super-important rule in Rust that we can never have more than one mutable borrow to the same variable at the same time? How does this situation look like with threads?
If we have two threads running at the same time and they both access the same memory location, there are three possible scenarios, depending on whether each thread is reading from or writing to the memory location:

To understand these three scenarios, we have to understand what it means that the two threads are running at the same time. We don't generally know on which processor cores a thread is running, and since threads are scheduled by the operating system, we also can't be sure that threads are actually running in parallel or one after another. The way we tend to think about these scenarios is by assuming the worst case, namely that any possible order of operations is possible. If thread A is executing 5 instructions, and thread B is executing 5 different instructions, both instructions might be executed in parallel on different CPU cores, or thread A might get interrupted by thread B, meaning that only the first couple of instructions of thread A are executed, followed by some instructions of thread B and then the remaining instructions of thread A:
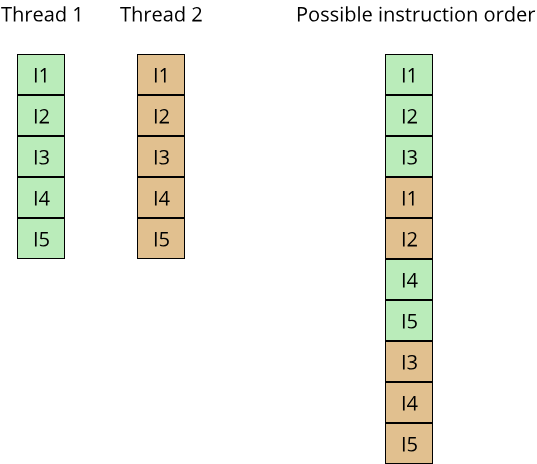
Armed with this knowledge, we can now make sense of the three scenarios for two concurrent threads accessing the same memory location. Scenario 1) (both threads are reading from the memory location) is simple to understand: Since no state is modified, the order of the read operations between the two threads does not change the outcome, as the following C++ code shows:
#include <thread>
#include <iostream>
#include <chrono>
int main() {
using namespace std::chrono_literals;
auto val = 42;
std::thread t1{[&val]() {
for(auto idx = 0; idx < 10; ++idx) {
std::this_thread::sleep_for(100ms);
std::cout << "Thread: " << val << std::endl;
}
}};
for(auto idx = 0; idx < 10; ++idx) {
std::this_thread::sleep_for(100ms);
std::cout << "Main: " << val << std::endl;
}
t1.join();
}
Scenario 2) (one thread reads, the other thread writes) is more interesting. We have again three different possibilities:
- a) Thread
Areads first, then threadBwrites - b) Thread
Bwrites first, then threadAreads - c) The read and write operations happen at the same instant in time
Clearly there is a difference in outcome between possibilities a) and b). In the case of a), thread A will read the old value of the memory location, whereas in the case of b), it will read the value that thread B has written. Since thread scheduling generally is not in our control in modern operating systems, it seems impossible to write a deterministic program with two threads accessing the same memory location. And what about option c)? How are simultaneous read and write requests to a single memory location resolved? This is heavily dependent on the processor architecture and CPU model, made even more complicated by the fact that modern CPUs have several levels of memory caches. Bryant and O'Hallaron go into more detail on how this cache coherency concept is realized {{#cite Bryant03}}, for us it is enough to know that simulatenous accesses to the same memory location from multiple threads become unpredictable as soon as one writer is involved.
The situation is similar when we have the two threads both write to the memory location (scenario 3): Either thread A overwrites the value of thread B or the other way around. Any such situation in code where two (or more) threads 'race' for the access of a shared memory location is called a race condition, and it is one category of nasty bugs that can happen in a multithreaded program.
Now the Rust borrow rules really make sense: By disallowing simultaneous mutable and immutable borrows, race conditions become impossible! But what does this all have to do with the Send trait?
As we saw from the error message, Send is a trait that signals to the Rust compiler that a type that implements Send is safe to be moved to another thread. At first, this might seem a pretty weird requirement. If we look at the primitive types in Rust (i32, usize etc.), we can't easily come up with a scenario where it might not be ok to move a value of one of these types onto another thread. Why is this even something that Rust cares about? You might have an intuition that it relates to preventing race conditions, but it is not trivial to see how moving a value from one thread to another could introduce a race condition.
To understand Send, we have to think about ownership again. We saw that the Rust function std::thread::spawn accepts a move closure, which takes ownership of the captured values. For types that are Copy, this is fine, since the thread will receive a copy of the value, which lives in a different memory location:
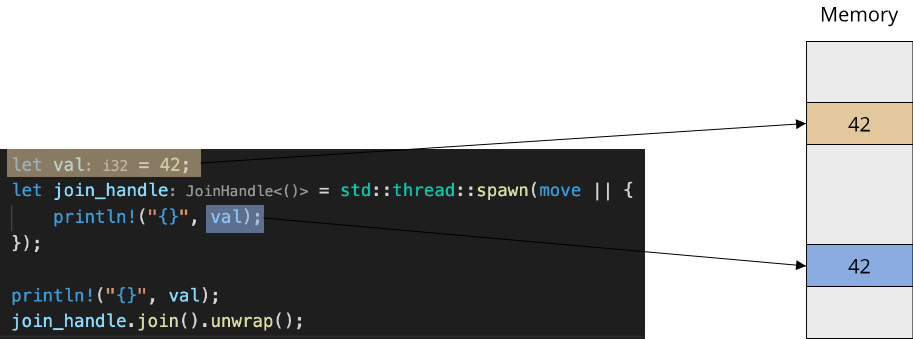
For types that are not Copy, it gets more interesting. In general, a type is not Copy if it has some non-trivial internal state, possibly refering to some other memory location. Let's look at one such type, Vec<i32>. We know that a single Vec<i32> value contains an indirection in the form of a pointer to the dynamically allocated array on the heap. Vec<i32> is the owner of this region of heap memory, and by moveing it onto the thread, we move the ownership onto a different thread. This is ok, because Vec<i32> is a single-ownership type, meaning that no one else can have a reference to the underlying memory block:
fn main() { let vec = vec![1, 2, 3, 4]; std::thread::spawn(move || { println!("{:#?}", vec); }); println!("Main: {:#?}", vec); }
As expected, this example does not compile, because we can't use a value after it has been moved. And if we were to clone the Vec<i32>, the spawned thread would receive a completely disjoined region of memory. So Vec<i32> is Send because we can move it onto a different thread safely since it is a single-ownership type.
But we also know multiple-ownership types, for example Rc<T>! Remember back to chapter 3.4 where we looked at the implementation of Rc<T>. It's key component was a region of memory (the control block) that was shared between multiple Rc<T> values. We needed this to keep track of the number of active references to the actual value of type T, and the only way we found to implement this in Rust was by using unsafe code with raw pointers so that each Rc<T> instance could mutate the control block. So let's look at how Rust treats raw pointers when we try to move them between threads:
fn main() { let mut val = 42; let val_ptr = &mut val as *mut i32; std::thread::spawn(move || unsafe { *val_ptr = 43; }); println!("Main: {}", val); }
Since raw pointers have neither lifetime nor borrow rules associated with them, we can easily obtain a mutable pointer to a variable, which gives us more than one point of mutation for the variable (val and val_ptr). If we move the pointer onto a different thread, this thread now has mutable access to the memory location pointed to by val_ptr, and we could create a race condition! Interestingly enough, Rust disallows this, even though we are using unsafe code:
error[E0277]: `*mut i32` cannot be sent between threads safely
--> src/bin/send_sync.rs:7:5
|
7 | std::thread::spawn(move || unsafe {
| _____^^^^^^^^^^^^^^^^^^_-
| | |
| | `*mut i32` cannot be sent between threads safely
8 | | *val_ptr = 43;
9 | | });
| |_____- within this `[closure@src/bin/send_sync.rs:7:24: 9:6]`
|
= help: within `[closure@src/bin/send_sync.rs:7:24: 9:6]`, the trait `Send` is not implemented for `*mut i32`
= note: required because it appears within the type `[closure@src/bin/send_sync.rs:7:24: 9:6]`
note: required by a bound in `spawn`
--> /Users/pbormann/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/src/rust/library/std/src/thread/mod.rs:621:8
|
621 | F: Send + 'static,
| ^^^^ required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
We get the same error message as before when we tried to move an Rc<T> onto another thread: the trait 'Send' is not implemented. Because Rust can't make any assumptions about raw pointers in terms of who uses them to mutate a memory location, raw pointers cannot be moved to another thread in Rust! Rust models this by not implementing the Send trait for raw pointers. Curiously enough, the Rust language also prevents const pointers from being send to other threads, because we can still obtain a const pointer from a variable that is mut.
Notice how we never explicitly said that anything implements Send or not? Send is a marker trait, meaning that it has no methods, and is implemented automatically by the Rust compiler for suitable types! All primitive types and all composite types made up only of primitive types or other composite types automatically implement Send, but as soon as a type has a raw pointer as one of its fields, the whole type is no longer Send. Which explains why Rc<T> is not Send: It contains a raw pointer to the control block internally!
There is a second related trait called Sync, which is basically the stronger version of Send. Where Send states that it is safe to move a type from one thread onto another, Sync states that it is safe to access the same variable from multiple threads at the same time. There is a simple rule that relates Sync to Send: Whenever &T implements Send, T implements Sync! Let's think about this for a moment to understand why this rule exists: If we can send a borrow of T to another thread, the other thread can dereference that borrow to obtain a T, thus accessing the value of T. Since the borrow must come from outside the thread, we have at least two threads that can potentially access the same value of T. Thus the rule must hold.
Things that are not Send and Sync, and how to deal with them
We saw that Rc<T> was neither Send nor Sync. To make matters worse, the Cell<T> and RefCell<T> types also are not Sync, so even if Rc<T> were Send, we still couldn't use Rc<T> in any reasonable way in a multithreaded program, because we need Cell<T>/RefCell<T> to get mutable access to the underlying data. The reason why neither Cell<T> nor RefCell<T> are Sync is similar to the reason for Rc<T> not being Send: Both Cell<T> and RefCell<T> enable shared mutable state (through the concept of interior mutability), so accessing a value of one of these types from multiple threads simultaneously could lead to race conditions.
The problem that we face in all of these situations is not so much that we have shared mutable state, but that the order in which we might access this state from multiple threads is generally undefined. What we want is a way to synchronize accesses to the shared mutable state, to guarantee that we never get a data race! To make this possible, we can either ask the operating system for help, or use special CPU instructions that can never result in race conditions. The operating system provides us so-called synchronization primitives, the special CPU instructions are called atomic instructions.
Atomicity
Data races can happen because one thread might interrupt another thread in the middle of a computation, which might result in one thread seeing data in an incomplete state. This can happen because many interesting operations that we might perform in a program are not atomic. An atomic operation is any operation that can't be interrupted. What exactly this means depends heavily on context. In computer science, we find atomic operations in different domains, such as concurrent programming (what we are talking about right now) or databases.
A common example to illustrate the concept of atomic operations is addition. Let's look at a very simple line of code:
val += 1;
Assuming that val is an i32 value less than its maximum value, this single line of code adds 1 to val. This might look like an atomic operation, but it turns out that it typically isn't. Here is the assembly code for this line of codeCompiled with the clang compiler, version 13.0.0 for x86-64. Other compilers might give different results. On x86-64, the add instruction can add a value directly to a memory address, but it can't add the values of two memory addresses for example.:
mov eax, dword ptr [rbp - 8]
add eax, 1
mov dword ptr [rbp - 8], eax
Our single line of code resulted in three instructions! To add 1 to val, we first load the value of val into the register eax, then add 1 to the register value, then store the value of eax back into the memory address of val. It becomes clear that there are several points during this computation where another thread might interrupt this computation and either read or write a wrong value.
Exercise 7.1: Assume that two threads execute the three assembly instructions above on the same memory location in parallel on two processor cores. What are the possible values in the memory address [rbp - 8] after both threads have finished the computation?
As far as modern processors are concerned, looking at the assembly code is only half of the truth. As we saw, there are different memory caches, and a read/write operation might hit a cache instead of main memory. So even if our line of code resulted in a single instruction, we still couldn't be sure that multiple threads see the correct results, because we don't know how the caches behave.
Luckily, most CPU instruction sets provide dedicated atomic operations for things like addition, subtraction, or comparing two values. Even better, both C++ (since C++11) and Rust provide special types in their respective standard libraries that give us access to these atomic instructions without writing raw assembly code. In C++, this might look something like this:
#include <atomic>
int main() {
std::atomic<int> val{42};
val.fetch_add(1);
return val;
}
The relevant method is fetch_add, which will translate to the following assembly instruction:
lock xadd DWORD PTR [rax], edx
Here, the lock keyword makes sure that the operation executes atomically, making sure that it can never get interrupted by another thread, and no thread ever sees an intermediate result.
The corresponding Rust code is pretty similar:
use std::sync::atomic::{AtomicI32, Ordering}; pub fn main() { let val = AtomicI32::new(42); val.fetch_add(1, Ordering::SeqCst); println!("{}", val.load(Ordering::SeqCst)); }
The only difference is that fetch_add expects an Ordering as the second parameter. This Ordering defines how exactly memory accesses are synchronized when using atomic operations. The details are quite complicated, and even the Rust documentation just refers to the memory model of C++, going as far as to state that this memory model '[is] known to have several flaws' and 'trying to fully explain [it] [...] is fairly hopeless'. The only thing we have to know here is that Ordering::SeqCst (which stands for sequentially consistent) is the strongest synchronization guarantee that there is and makes sure that everyone always sees the correct results. Other memory orderings might give better performance while at the same time not giving correct results in all circumstances.
There is one little fact that might seem very weird with our current understanding of Rust. Notice how the val variable is declared as immutable (let val), but we can still modify it using fetch_add? Indeed, the signature of fetch_add accepts an immutable borrow to self: pub fn fetch_add(&self, val: i32, order: Ordering) -> i32. This is an interesting but necessary side-effect of atomicity. The Rust borrow checking rules and their distinction between immutable and mutable borrows are there to prevent mutating data while someone else might read the data, but for atomic operations this distinction is irrelevant: When an operation is atomic, no one will ever see an inconsistent state, so it is safe to mutate such a value through an immutable borrow!
Synchronization through locks
If we look at the atomic types that Rust offers, we see that only integer types (including bool and pointers) are supported for atomic operations. What can we do if we have a larger computation that we need to be performed atomically? Here, we can use tools that the operating system provides for us and use locking primitives. Arguably the most common locking primitive is the mutex, which stands for 'MUTual EXclusion'. A mutex works like a lock in the real world. The lock can either be unlocked, in which case whatever it protects can be accessed, or it can be locked, preventing all access to whatever it protects. Instead of protecting real objects, a mutex protects a region of code, making sure that only a single thread can execute this region of code at any time. This works by locking the mutex at the beginning of the critical piece of code (sometimes called a critical section) and unlocking it only after all relevant instructions have been executed. When another thread tries to enter the same piece of code, it tries to lock the mutex, but since the mutex is already locked, the new thread has to wait until the mutex is unlocked by the other thread. The implementation of the mutex is given to us by the operating system, and both C++ and Rust have a mutex type in their respective standard libraries. Here is an example of the usage of a mutex type in C++:
std::mutex mutex;
mutex.lock(); //<-- Acquire the lock
/**
* All code in here is protected by the mutex
* Only one thread at a time can execute this code!
*/
mutex.unlock(); //<-- Release the lock
Let's look at the Mutex type in Rust. Since we only need synchronization when we have shared state, the Mutex is a generic type that wraps another type, providing mutually exclusive access to the value of this wrapped type. So compared to the C++ std::mutex, the Rust Mutex type always protects data, but we can use this to also protect regions of code by extension. We get access to the data by calling the lock method on the Mutex, which returns a special type called MutexGuard. This type serves two purposes: First, it gives us access to the underlying data protected by the Mutex. A MutexGuard<T> implements both Deref and DerefMut for T. Second, MutexGuard is an RAII type that makes sure that we don't forget to unlock the Mutex. When MutexGuard goes out of scope, it automatically unlocks its associated Mutex. Notice that a mutex is just like any other resource (e.g. memory, files) and thus has acquire/release semantics.
Here is a bit of code that illustrates how a Mutex never allows accessing its protected data from more than one location at the same time:
use std::sync::Mutex; fn main() { let val = Mutex::new(42); { let mut locked_val = val.lock().unwrap(); *locked_val += 1; val.lock().unwrap(); println!("We never get here..."); } }
The first call to lock locks the Mutex, returning the MutexGuard object that we can use to modify the data. The second call to lock will block, because the Mutex is still locked. In this case, we created what is known as a deadlock: Our program is stuck in an endless waiting state because the second lock operation blocks until the Mutex gets unlocked, which can only happen after the second lock operation.
Does Mutex remind you of something? Its behaviour is very similar to that of RefCell! Both types prevent more than one (mutable) borrow to the same piece of data at the same time at runtime! Mutex is just a little bit more powerful than RefCell, because Mutex works with multiple threads!
Let's try to use Mutex in a multithreaded program:
use std::sync::Mutex; fn main() { let val = Mutex::new(42); let join_handle = std::thread::spawn(move || { let mut data = val.lock().unwrap(); *data += 1; }); { let data = val.lock().unwrap(); println!("From main thread: {}", *data); } join_handle.join().unwrap(); }
Unfortunately, this doesn't compile:
error[E0382]: borrow of moved value: `val`
--> src/bin/send_sync.rs:11:20
|
4 | let val = Mutex::new(42);
| --- move occurs because `val` has type `Mutex<i32>`, which does not implement the `Copy` trait
5 | let join_handle = std::thread::spawn(move || {
| ------- value moved into closure here
6 | let mut data = val.lock().unwrap();
| --- variable moved due to use in closure
...
11 | let data = val.lock().unwrap();
| ^^^^^^^^^^ value borrowed here after move
For more information about this error, try `rustc --explain E0382`.
Of course, we have to move data onto the thread, and this moves our val variable so that we can't access it anymore from the main thread. Our first instinct might be to move a borrow of val onto the thread, however we already know that this won't work because spawn requires all borrows to have 'static lifetime, because the thread might life longer than the function which called spawn. Realize what this implies: Both the main thread as well as our new thread have to own the Mutex! So our Mutex requires multiple ownership! So let's put the Mutex inside an Rc!
...except this also doesn't work, because we already saw that Rc does not implement Send! Rc has this shared reference count that might get mutated from multiple threads at the same time, and of course this isn't safe. But wait! Recall that the reference count is just an integer? We know a type that let's us safely manipulate an integer from multiple threads at the same time: AtomicI32 (or better yet, AtomicUsize). If we were to write an Rc implementation using atomic integers in the control block, then it would be safe to send an Rc to another thread!
Rust has got us covered. Enter Arc<T>! Where Rc stood for 'reference-counted', Arc stands for 'atomically reference-counted'! How cool is that? By wrapping our Mutex inside an Arc, we can safely have multiple threads that own the same Mutex:
use std::{ sync::{Arc, Mutex}, }; fn main() { let val = Arc::new(Mutex::new(42)); let val_clone = val.clone(); let join_handle = std::thread::spawn(move || { let mut data = val_clone.lock().unwrap(); *data += 1; }); { let data = val.lock().unwrap(); println!("From main thread: {}", *data); } join_handle.join().unwrap(); }
Arc works very much the same as Rc, so we already know how to use it! There is one small caveat when using Arc with std::thread::spawn: Since we have to move values into the closure but also want to use our val variable after the thread has been spawned, we have to create a second variable val_clone that contains a clone of the Arc before calling std::thread::spawn. The sole purpose of this variable is to be moved into the closure, so it might look a bit confusing in the code.
A closing note on the usage of Mutex: The code above is still not strictly deterministic, because we don't know which thread will acquire the lock first (the main thread or the spawned thread), so the println! statement might either print a value of 42 or 43. This seems like a critical flaw of Mutex, but instead it is simply an artifact of the way we wrote our code. Using a Mutex does not establish any order between threads, it only guarantees that the resource protected by the Mutex can never be accessed by two threads at the same time. The discussion of ordering of concurrent operations is beyond the scope of this course, but it is an interesting one, as many concurrent algorithms don't care all that much about the order of operations. In fact, this is one of the fundamental properties of concurrent programming: The fact that operations can run in parallel often means that we give up on knowing (or caring about) the explicit ordering of operations.
Our DNA editing algorithm using Arc and Mutex
We can now replace our usage of Rc<RefCell<...>> in our previous attempt to parallelize the DNA editing algorithm with Arc<Mutex<...>>:
#![allow(unused)] fn main() { fn dna_editing_parallel( mut source: Vec<Nucleobase>, old_sequence: Vec<Nucleobase>, new_sequence: Vec<Nucleobase>, parallelism: usize, ) -> Vec<Nucleobase> { let source = Arc::new(Mutex::new(source)); let join_handles = (0..parallelism) .into_iter() .map(|chunk_index| { let source_clone = source.clone(); let old_sequence = old_sequence.clone(); let new_sequence = new_sequence.clone(); std::thread::spawn(move || { let mut source = source_clone.lock().unwrap(); let sequence_start = chunk_size * chunk_index; let sequence_end = if chunk_index == parallelism - 1 { source.len() } else { (chunk_index + 1) * chunk_size }; dna_editing_sequential( &mut source[sequence_start..sequence_end], old_sequence.as_slice(), new_sequence.as_slice(), ) }) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); let mutex = Arc::try_unwrap(source).unwrap(); mutex.into_inner().unwrap() } }
With the Arc<Mutex<...>> pattern, we can then access the source vector from inside the thread functions and pass the appropriate range of elements to the dna_editing_sequential implementation. If we compile this, we get zero errors, and the program runs without any crashes! Is all well then? Did we write a correct, high-performance program in Rust?
Unfortunately, there are two major problems with our code, that stem from our lack of understanding of concurrent programming patterns at the moment. One is a correctness problem, the other a performance problem. The correctness problem arises because we split our DNA sequence into chunks and process each chunk concurrently on its own thread. But what if the pattern we are looking for spans two chunks? Then, neither thread will recognize the whole pattern, because it has only part of the data available:
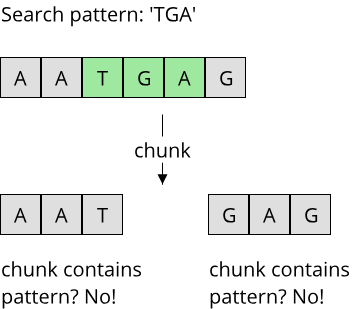
This is a fundamental problem of the way we structured our algorithm, and it is not easy to fix unfortunately. We could try to add a second phase to the algorithm that only checks the chunk borders for occurrences of the search pattern, but then we would have to make sure that our initial replacement of the pattern didn't yield new occurrences of the pattern in the edited DNA sequence. Even if we were to fix this issue, there is still the performance problem! Notice how each thread tries to lock the Mutex immediately after it starts running, and only releases the Mutex once it is finished? This means that there will never be two threads doing useful work at the same time, because the Mutex prevents this! So we effectively wrote a sequential algorithm using multiple threads and poor usage of a Mutex. This is not uncommon if we try to naively port a sequential algorithm to multiple threads.
Unfortunately, this chapter has to end with this disappointing realization: Our implementation is neither correct nor fast. Even with all the safety mechanisms that Rust provides for us, we still require knowledge of concurrent programming to come up with efficient and correct implementations. A more practical discussion of concurrent programming thus will have to wait until the next chapter.
Conclusion
In this chapter, we learned about the fundamental concepts for executing code concurrently in Rust. Threads are the main building blocks for running code concurrently within a single process. Since concurrent accesses to the same memory locations can result in race conditions, Rust provides the two traits Send and Sync to assure that concurrent accesses stay safe. We saw some caveats to using threads in Rust when it comes to lifetimes, namely that the default threads that the Rust standard library provides requires 'static lifetime for all borrows used from a thread. To circumvent these problems, we saw how we can use synchronization primitives such as the Mutex, together with thread-safe smart pointers (Arc) to make concurrent resource accesses from multiple threads safe.
While this chapter layed the groundwork of understanding concurrent programming in Rust, in reality these low-level concepts can be hard to use and several crates are utilized instead which provide easier mechanisms for concurrent programming. In the next chapter, we will therefore look at applied concurrent programming in Rust.
Applied concurrent programming in Rust using the rayon and crossbeam crates
Time to take our newly acquired knowledge of concurrent programming in Rust to the next level! In this chapter, we will learn about two useful crates called crossbeam and rayon, which will help us to write better concurrent code. Let's dive right in!
Scoped threads
Recall from the previous chapter that the threads from the Rust standard library required all borrows to have 'static lifetime? This forced us to use the thread-safe multi-ownership smart pointer type Arc<T>, so that each thread could take ownership of shared data. But we already suspected that this requirement is overly strict! Look at the following code:
fn main() { let text = format!("Current time: {:?}", std::time::SystemTime::now()); let text_borrow = text.as_str(); let join_handle = std::thread::spawn(move || { println!("Thread: {}", text_borrow); }); join_handle.join().unwrap(); println!("Main thread: {}", text); }
This code fails to compile with the error 'text' does not live long enough [...] requires that 'text' is borrowed for 'static. But both the thread and the text variable have the same lifetime, because we join with the thread from within main! This is a nuisance: We as developers know that our code is correct, but the Rust standard library is preventing us from writing this code. This is made even worse by the fact that the 'intended' solution (using Arc<Mutex<String>>) has worse performance than our 'borrow-only' solution!
What we would like is a thread that obeys the scope that it is launched from, so that the thread function only has to be valid for the lifetime of that scope. This is exactly what the crossbeam crate offers!
crossbeam contains a bunch of utilities for writing concurrent Rust code, for our purposes we will need the crossbeam::scope method. With scope, we get access to a special Scope type that lets us spawn threads that live only as long as the Scope. The Scope type has a function spawn which looks similar to std::thread::spawn, but with different lifetime requirements:
#![allow(unused)] fn main() { pub fn spawn<F, T>(&'scope self, f: F) -> ScopedJoinHandle<'scope, T> where T: Send + 'env, F: FnOnce(&Scope<'env>) -> T + Send + 'env }
All we care about for now is the 'env lifetime, which is the lifetime of the Scope type that we get from calling the crossbeam::scope function. Putting the two functions together, we can rewrite our initial code like this:
fn main() { let text = format!("Current time: {:?}", std::time::SystemTime::now()); let text_borrow = text.as_str(); crossbeam::scope(|scope| { scope.spawn(|_| { println!("Thread: {}", text_borrow); }) .join() .unwrap(); }) .unwrap(); println!("Main thread: {}", text); }
Notice that the crossbeam::scope function accepts another function and passes the Scope instance to this function. Only from within this function is the Scope valid, so we have to put all our code that launches threads inside this function. This is a bit of Rust gymnastics to make sure that all lifetimes are obeyed. In particular, since the Scope is created from within the crossbeam::scope function, which itself is called from main, the lifetime of the Scope will never exceed that of the main function, which allows us to use borrows from the stack frame of main inside the threads spawned from the Scope. Neat!
Let's take the DNA editing example from the previous chapter and rewrite it using crossbeam:
#![allow(unused)] fn main() { fn dna_editing_crossbeam( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], parallelism: usize, ) { if old_sequence.len() != new_sequence.len() { panic!("old_sequence and new_sequence must have the same length"); } crossbeam::scope(|scope| { let chunk_size = (source.len() + parallelism - 1) / parallelism; let chunks = source.chunks_mut(chunk_size).collect::<Vec<_>>(); for chunk in chunks { scope.spawn(move |_| dna_editing_sequential(chunk, old_sequence, new_sequence)); } }) .unwrap(); } }
Not only is this code a lot simpler than the code we had previously, it also runs much faster! We have zero copying of our source data, and because we can now use borrows together with chunks_mut, each thread only has access to its own unique slice of source. Using 12 threads, this code runs about 10 times faster than the sequential code on the tested system. Another useful side-effect of using the crossbeam::scope function is that we don't have to explicitly join with our spawned threads, crossbeam does this automatically for us once the scope gets destroyed!
Channels
Up until now, we only worked with the fork-join concurrent programming model. This model works well if we have all data that is to be processed available, so that we can split the data up into chunks and process them in parallel. We don't always have a problem where we have all data available upfront. In addition, spinning up a thread everytime we fork our data might introduce unnecessary overhead, especially if the amount of data processed per thread is small. To grow our concurrent programming toolkit, we have to learn about a new concurrent programming model, called the message passing model.
Message passing is one of the most successful models for concurrent programming. In fact, we already used message passing in the chapter on network programming: Every client/server system works through exchanging messages, and client/server applications are inherently concurrent! Where we used a network connection to exchange messages between processes in the networking chapter, we can also exchange messages between threads running in the same process by using thread-safe queues. In Rust, they are called channels, and both the Rust standard library as well as crossbeam provide implementations for channels.
Good candidates for applying the message passing paradigm are producer/consumer problems. These are scenarios in which one or more producers of a certain piece of work exist, and one or more consumers that can process these work items. A real-world example would be a restaurant, where you have a bunch of customers that produce work for the kitchen (by ordering food), and one or more chefs in the kitchen which work on the ordered food and thus consume the food requests. It also works in the other way of course, with the kitchen being the producer and all customers being consumers.
For a more computer-friendly application, we will look at a program which checks numbers whether they are prime or not. The user can input numbers from the command line and a dedicated thread processes each number to figure out whether it is a prime number or not. Using a separate thread to do the heavy computations means that the main thread is always free to handle user input and text output. This is a good thing, because the user will never see the program hang on a long-running computation! In this scenario, the user is the producer and the thread is the consumer. Let's implement this:
fn main() { let (sender, receiver) = std::sync::mpsc::channel(); let consumer_handle = consumer(receiver); producer(sender); consumer_handle.join(); }
The main function is simple and illustrates the producer/consumer nature of our application. To handle the communication between producer and consumer, we are using the aforementioned channel, in this case the one provided by the Rust standard library. Every channel has two ends: A sending end and a receiving end, represented by the two variables sender (of type Sender<T>) and receiver (of type Receiver<T>) in the code. The channel itself handles all synchronization so that one thread can send arbitrary data to another thread without any data races. Let's see how we can produce values:
#![allow(unused)] fn main() { fn producer(sender: Sender<u64>) { loop { let mut command = String::new(); println!("Enter number:"); std::io::stdin().read_line(&mut command).unwrap(); let trimmed = command.trim(); match trimmed { "quit" => break, _ => match trimmed.parse::<u64>() { Ok(number) => { sender.send(number).unwrap(); } Err(why) => eprintln!("Invalid command ({})", why), }, } } } }
Although this function looks a bit messy, all that it does is read in a line from the command line and interpret it either as a number, or as the quit command, which will exit the program. The important line is right here: sender.send(number).unwrap(). Here, we send the number to be checked through the channel to the consumer. Since a channel has two ends, we can't be sure that the other end of the channel is still alive (the corresponding thread might have exited for example). For this reason, send returns a Result, which we handle quite ungracefully here.
The consumer is more interesting:
#![allow(unused)] fn main() { fn consumer(receiver: Receiver<u64>) -> JoinHandle<()> { std::thread::spawn(move || { while let Ok(number) = receiver.recv() { let number_is_prime = is_prime(number); let prime_text = if number_is_prime { "is" } else { "is not" }; println!("{} {} prime", number, prime_text); } }) } }
We launch a new thread and move the receiving end of the channel onto this thread. There, we call the recv function on the channel, which will return the next value in the channel if it exists, or block until a value is put into the channel by the producer. Just as the sender, the receiver also has no way of knowing whether the other end of the channel is still alive, so recv also returns a Result. And just like that, we have established a message-passing system between the main thread and our consumer thread! If we run this program and put in a large prime number, we will see that our program does not hang, but it takes some time until the answer comes in. We can even have multiple potential prime numbers in flight at the same time:
Enter number:
2147483647
Enter number:
1334
Enter number:
2147483647 is prime
1334 is not prime
You might have noticed the weird module name that we pulled the channel from: mpsc. mpsc is shorthand for 'multi-producer, single-consumer', which describes the scenario that this type of channel can be used for. We can have multiple producers, but only one consumer. Consequently, the Sender<T> type that channel() returns implements Clone so that we can have multiple threads send data to the same channel. The Receiver<T> type however is not clonable, because we can have at most one receiver (consumer). What if we want this though? In our prime-checker example, it might make sense to have multiple consumer threads to make good usage of the CPU cores in our machine. Here, the crossbeam crate has the right type for us: crossbeam::channel::unbounded creates a multi-producer, multi-consumer channel with unlimited capacity. With this, we can have as many consumers as we want, because the corresponding Receiver<T> type also implements Clone. The channel itself will store an unlimited amount of data that is sent but not yet received, if we don't want this and instead want senders to block at a certain point, we can use crossbeam::channel::bounded instead.
Message-passing is a good alternative to explicitly synchronizing data between threads, and Rust gives us several easy-to-use tools to implement message-passing. This pattern is so popular for concurrent programming that another systems programming language called Go has channels as a built-in language feature. In Go, one very popular piece of advice goes like this: Do not communicate by sharing memory; instead, share memory by communicating{{#cite effectiveGo}}.
Parallel iterators using rayon
The last practical application of concurrency in Rust that we will look at are parallel iterators. Sometimes, it is useful to take an existing iterator and process it concurrently, for example on multiple threads at once. This is closely related to the fork/join pattern that we used in the previous chapter, but instead of having an array that we split up into chunks to process on threads, why not use the more general iterator abstraction and process each element of the iterator on a different thread? The advantage of this would be that we can take sequential code that uses iterators and parallelize it easily by switching to a 'thread-based iterator'. This is exactly what the rayon crate offers!
Let's take our string search algorithm from the previous chapter and implement it in parallel using rayon! To get access to all the cool features that rayon provides, we typically start with a use rayon::prelude::*; statement, which imports all necessary types for parallel iterators. Then, the actual implementation of a parallel string search algorithm is very simple:
#![allow(unused)] fn main() { fn search_parallel_rayon(text: &str, keyword: &str, parallelism: usize) -> usize { let chunks = chunk_string_at_whitespace(text, parallelism); chunks .par_iter() .map(|chunk| search_sequential(chunk, keyword)) .sum() } }
The only difference to a sequential implementation is that we are using the par_iter() function that rayon provides, which returns a parallel iterator instead of a sequential iterator. Internally, rayon uses a bunch of threads that process the elements of parallel iterators, but we don't have to spawn those threads ourselves. rayon provides a lot of the iterator algorithms that we saw in chapter 4.3, but they execute in parallel! This is very helpful, because figuring out how to correctly and efficiently parallelize these algorithms can be tough.
Let's try to understand rayon a bit better. Somehow, rayon is creating an appropriate number of threads in the background to handle the parallel iterators on. How does rayon know how many threads to create? If the iterator comes from a container that has a known size, i.e. the iterator implements ExactSizeIterator, then we know upfront how many items there are, but in all other cases the length of the iterator is unknown. And does it even make sense to create more threads than there are CPU cores in the current machine? If there are 8 cores and 8 threads that run instructions at full speed, then adding more threads doesn't magically give us more CPU power.
Looking back at our application of the fork/join pattern, what did we actually do if we had more items to be processed than CPU cores? Instead of creating more threads, we grouped the items into a number of equally-sized chunks, equal to the number of CPU cores. Then, we moved each chunk onto a thread and processed it there. Now suppose that we don't know how many items we have and thus can't create an appropriate number of chunks, because we don't know the chunk size. What if we could move items onto threads one at a time? Then it doesn't matter how many items we have, we can move each item onto a thread one-by-one, moving through the threads in a round-robin fashion:
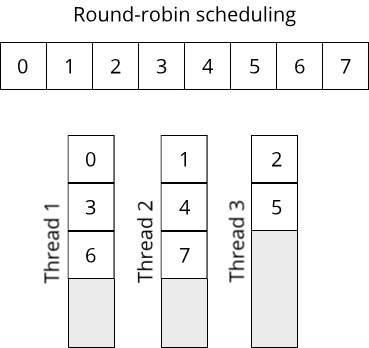
This requires that our threads have the ability to wait for new items, but we already saw that this is achieved easily by using channels. Whenever we have a bunch of active threads that are waiting for data to be processed, we call this a thread pool (or task pool). This is exactly what rayon is using under the hood to do all parallel processing. Since rayon is a library aimed at data parallelism (the fork/join pattern is an example of data parallelism), it focuses on data-intensive parallel computations. If we map such computations onto threads, we typically assume that one thread is able to saturate one CPU core, which means that it executes instructions at or near its maximum speed. The internal thread pool that rayon uses thus has one thread per CPU core running and waiting for work. If we look into the documentation of rayon, we see that it also offers some configuration options to create a thread pool ourselves using a ThreadPoolBuilder type.
Conclusion
In this chapter we looked at some useful crates and patterns that make concurrent programming easier in Rust. We can overcome the lifetime problems by using the scoped threads that the crossbeam crate offers. If we can't use fork/join, we can use message passing for which both the Rust standard library and crossbeam provide channels that can send data between threads. Lastly, we saw that we can use the rayon crate to turn code using regular iterators into parallel code through parallel iterators.
Asynchronous programming using async and await
In this last chapter on fearless concurrency using Rust, we will look at a different approach to concurrent programming which is very helpful for writing I/O heavy code, particular network code. The feature that we are going to look at is called async/.await in Rust, and the broader term is asynchronous programming. Note that several of the examples in this chapter are heavily insipired by the Rust async book, which describes the idea behind asynchronous programming in Rust in a lot of detail.
The problem with threads and I/O heavy code
As we saw, threads are a great way to utilize compute resources efficiently. At the same time, launching a thread takes a bit of time, and each thread has a non-trivial amount of state attached to it (for example its own stack). For that reason, having too many active threads at once is not always the best solution, in particular if each thread does little work. This often happens in scenarios that are heavily I/O bound, in particular when we have to wait for a lot of I/O operations to complete. Network programming is the main example for this, as we often have to wait for our sockets to become ready for reading data that has arrived over a network connection. Let's look at an example:
fn handle_connection(mut connection: TcpStream) { ... } fn main() -> Result<()> { let listener = net::TcpListener::bind("127.0.0.1:9753")?; let mut number_of_connections: usize = 0; for connection in listener.incoming() { let connection = connection.context("Error while accepting TCP connection")?; number_of_connections += 1; println!("Open connections: {}", number_of_connections); // Move connection onto its own thread to be handled there std::thread::spawn(move || { handle_connection(connection); }); } Ok(()) }
This code is pretty similar to the code for our little server application from chapter 6.2, but instead of accepting one connection at a time, we move each connection onto its own thread. This way, our server can deal with lots of connections at once. How many connections? Let's try it out by writing a client application that opens lots of connections to this server (since we probably don't have thousands of machines at hand to test a real situation):
fn main() -> Result<()> { // Open as many connections as possible to the remote host let connections = (0..) .map(|_| TcpStream::connect("127.0.0.1:9753")) .collect::<Result<Vec<_>, _>>()?; // Wait for input, then terminate all connections let _ = std::io::stdin().read(&mut [0u8]).unwrap(); Ok(()) }
If we run the two programs on a 2019 MacBook Pro, this might be an example output of the server application:
...
Open connections: 8188
Open connections: 8189
Open connections: 8190
Open connections: 8191
Open connections: 8192
thread 'main' panicked at 'failed to spawn thread: Os { code: 35, kind: WouldBlock, message: "Resource temporarily unavailable" }', /rustc/0b6f079e4987ded15c13a15b734e7cfb8176839f/library/std/src/thread/mod.rs:624:29
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
So about 8192 simultaneous connections, which seems to be limited by the number of threads that we can create. 8192 seems like a suspicious number (it is a power-of-two after all), and indeed this is the limit of threads for a single process on this machine, as sysctl kern.num_taskthreads tells us:
kern.num_taskthreads: 8192
Whether or not it makes sense to have 10'000 or more open TCP connections for a single process can be debated, it is clear however that we want to utilize our system resources efficiently if we want to write the highest performing software that we can. Within the modern web, handling lots of concurrent connections is very important, so we really would like to have efficient ways of dealing with many connections at once.
So let's take a step back and look at what a network connection actually does. The TcpStream type in the Rust standard library is simply a wrapper around the low-level sockets API of the operating system. In its simplest form, calling read on a TcpStream on a Linux system would result in the recv system call. Part of this system call is its ability to block until data becomes available. Indeed, the documentation of recv states: If no messages are available at the socket, the receive calls wait for a message to arrive [...]. This is why we used one thread per connection: Since reading data from a connection can block the current thread, having one thread per connection ensures that no two connections are blocking each other. If we read further in the documentation of recv, we stumble upon an interesting fact: [...] the receive calls wait for a message to arrive, **unless the socket is nonblocking** [...] The select(2) or poll(2) call may be used to determine when more data arrives. So there are also non-blocking sockets! Let's try to understand how they work.
Non-blocking sockets and I/O multiplexing
The documentation of recv stated that a socket might be non-blocking, in which case calling recv on that socket might result in an error if the socket does not have data available. Which means that we have to make sure that we only call recv when we know that there is data to read from the socket. The POSIX manual even gives us a hint how we can achieve that: Using the select or poll system calls. So suppose we have our socket s and want to read data from it. Instead of calling recv, we set the socket to non-blocking upon initialization, then we call poll with s and once poll returns we know that there is data available on the socket so we can call recvThe reality is a bit more complicated since there are different types of events that can occur on a socket. The event we might be interested in is called POLLIN in POSIX..
But how does this help us? Instead of blocking on recv, we now block on poll, which doesn't seem like much of an improvement. Here comes the interesting part. Take a look at the signature of poll:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
poll actually takes an array of file descriptors to listen on, and will return once an event occured on any of these file descriptors! This means that we can open 10 sockets, set them all to non-blocking and then repeatedly call poll in a loop on all 10 socket file descriptors. Whenever poll returns, it sets a flag in the pollfd structure for each file descriptor that registered an event, so that we can figure out which sockets are ready to read. Then, we can call recv on the corresponding sockets. Now, we can handle multiple connections on a single thread without any two connections interfering with each other! This is called I/O multiplexing and is our first step towards asynchronous programming!
Non-blocking I/O using the mio library
In order to rewrite our connection benchmark from before using I/O multiplexing, we need access to the low-level system calls like poll. Since they are operating-system-specific, we will use a Rust library called mio which gives us access to I/O event polling on all platforms. mio exposes a Poll type to which we can register event sources such as mios TcpListener and TcpStream types, which are special non-blocking variants of the types in std::net. With this we can write a single-threaded server that can accept lots of connections:
fn main() -> Result<()> { let mut poll = mio::Poll::new().expect("Could not create mio::Poll"); let mut events = mio::Events::with_capacity(1024); let mut connections = HashMap::new(); let mut listener = mio::net::TcpListener::bind("127.0.0.1:9753".parse().unwrap())?; const SERVER_TOKEN: mio::Token = mio::Token(0); poll.registry() .register(&mut listener, SERVER_TOKEN, mio::Interest::READABLE)?; loop { poll.poll(&mut events, None)?; for event in events.iter() { match event.token() { SERVER_TOKEN => { handle_incoming_connections(&mut listener, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; } } }
At the heart of asynchronous I/O lies the event loop, which in our case calls poll on the mio::Poll type. This is basically the Rust version of the POSIX system call poll: It waits until one or more events have occurred on any of the registered event sources. To start out, we only register one event source: The TcpListener. We also specify which events we are interested in, which in our case is just mio::Interest::READABLE, meaning we want to be able to read from the TcpListener. Since the Poll type can wait on multiple event sources at once, we need a way to identify the event sources, for which the Token type is used for. It is simply a wrapper around a usize value. Within our event loop, once poll returns, we can iterate over all events that occurred using the Event type. Each event has the associated Token for its source, which we can use to identify whether our TcpListener or some other event source triggered the event. If the TcpListener is ready, we can immediately accept incoming connections, as the handle_incoming_connections function shows:
#![allow(unused)] fn main() { fn handle_incoming_connections( listener: &mut TcpListener, connections: &mut HashMap<Token, TcpStream>, poll: &mut Poll, ) -> Result<()> { loop { match listener.accept() { Ok((connection, _)) => { let token = Token(connections.len() + 1); connections.insert(token, connection); let connection = connections.get_mut(&token).unwrap(); poll.registry() .register(connection, token, Interest::READABLE)?; println!("Got {} open connections", connections.len()); } Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(e) => bail!("TcpListener error {}", e), } } Ok(()) } }
It's a bit more complicated as one might think, but not too terrible. We start in a loop and call listener.accept(), because there might be multiple incoming connections ready. Our exit condition for the loop is when accept() returns with an error whose kind() is equal to std::io::ErrorKind::WouldBlock, which signals that we have accepted all connections that were ready. If we have a ready connection, we memorize it in a HashMap and assign it a unique Token, which we then use to register this TcpStream of the connection with the Poll type as well. Now, the next poll call will listen not only for incoming connections on the TcpListener, but also for incoming data on the TcpStreams.
Back in the main function, we have this piece of code here:
#![allow(unused)] fn main() { match event.token() { SERVER_TOKEN => { handle_incoming_connections(&mut listener, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; }
If the event source is not the TcpListener - which is identified by the SERVER_TOKEN - we know that one of our connections is ready to receive data, which we handle using the handle_readable_connection function:
#![allow(unused)] fn main() { fn handle_readable_connection( token: Token, connections: &mut HashMap<Token, TcpStream>, poll: &mut Poll, ) -> Result<()> { let mut connection_closed = false; if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { Ok(0) => { // Connection is closed by remote connection_closed = true; break; } Ok(n) => println!("[{}]: {:?}", connection.peer_addr().unwrap(), &buffer[0..n]), Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Err(e) => bail!("Connection error {}", e), } } } if connection_closed { let mut connection = connections.remove(&token).unwrap(); poll.registry().deregister(&mut connection)?; } Ok(()) } }
This function is pretty complicated, so let's break it down into its main parts:
#![allow(unused)] fn main() { let mut connection_closed = false; if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { //... } } } }
We first try to obtain the associated TcpStream based on the Token of the event. Then, we prepare a buffer to read data and call read in a loop, since we don't know how much data we can read from the connection. read has a couple of possible return values, which are handled like so:
#![allow(unused)] fn main() { Ok(0) => { // Connection is closed by remote connection_closed = true; break; } Ok(n) => println!("[{}]: {:?}", connection.peer_addr().unwrap(), &buffer[0..n]), Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => break, Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Err(e) => bail!("Connection error {}", e), }
By definition, if read returns Ok(0) this indicates that the connection has been closed by the remote peer. Since we still hold a borrow to the TcpStream, we can't remove it from the HashMap immediately and have to instead set a flag to clean up the connection later. When Ok(n) is returned with a non-zero n, we just print the data to the standard output. Then, there are three error cases:
- If the error kind is
std::io::ErrorKind::WouldBlock, we have read all the data and can exit the loop, similar to what we did with theTcpListener - If the error kind is
std::io::ErrorKind::Interrupted, it means thereadoperation was interrupted and we just have to try again in the next loop iteration - In all other cases, we treat the error as a critical error and exit the function with the error message
What remains is the closing of a connection from the server-side:
#![allow(unused)] fn main() { if connection_closed { let mut connection = connections.remove(&token).unwrap(); poll.registry().deregister(&mut connection)?; } }
This is as simple as removing the connection from the HashMap and calling deregister on the Poll object.
Putting it all together, we can run this program as our new server with just a single thread and see how many connections we can handle:
...
Got 10485 open connections
Got 10486 open connections
Got 10487 open connections
Error: TcpListener error Too many open files (os error 24)
A little more than before, but now we hit a different operating system limit: Too many open files (os error 24). On the machine that this program was run on, ulimit -n gives 10496, which is the maximum number of open file descriptors for the current user. So a bit more than with out thread-based example, but still not orders of magnitude more. The good news is that we are able to handle more connections than before from just a single thread. The memory usage of the poll-based implementation is also much betterThe amount of residual memory, which is the memory that is actively paged in and in use by the program, is not vastly different between the two solution (about 1MB for the single-threaded solution vs. 8.8MB for the multithreaded solution), but the amount of virtual memory that is allocated is very different! Since each thread needs its own stack space, which on the test machine is 8MiB large, the program allocates 8MiB of virtual memory per thread, for a total of about 64GiB of virtual memory!. The downside is that the code is significantly more complex than what we had in the thread-based implementation.
Besides the pure numbers, the poll-based implementation actually does something remarkable: It runs multiple separate logical flows within a single thread! Notice how each connection encapsulates its own logical flow and is disjoint from all other connections? This is what the term multiplexing actually means: Running multiple signals (our I/O operations on the network connections) over a single shared resource (a single thread). In computer-science terms, we realized concurrent programming using a single thread. We could of course extend our implementation to use multiple threads on top of poll, to make it even more efficient. Still, the fact that we effectively have interwoven multiple logical flows into a single-threaded application is pretty neat!
The road towards asynchronous programming
Where do we go from here? Clearly, the ergonomics of using poll leave a lot to be desired, so maybe we can find a good abstraction for it? Without spoiling too much: Our aim is to 'invent' what is know as asynchronous programming, which Rust has as a core language feature.
The term asynchronous means that we can have multiple concurrent logical flows in the context of one or a handful of threads. We saw that we could achieve this for network connections using poll: Multiple connections were open concurrently, we could even read from them, all from a single thread. As a consequence, we lost the order of operations in our code. What do we mean by that? Suppose we have 4 connections A, B, C, and D. In a synchronous program, we always have an established order in which we read from these connections, for example ABCD. In an asynchronous program, we don't know in which order we will read from these connections. It could be ABCD, but it could also be any other order, such as DCBA or even ABAACAD.
A fundamental property of asynchronous code is the decoupling of computations from their result. In a synchronous program, these two are tied together: We call a function (computation) and once the function exits we get its result. We call read on a TcpStream and get the bytes from the stream. In an asynchronous program, we request the computation, then do something else and only return to the computation once its result is available! This is exactly what we did with poll: We requested to be notified when data is ready to be read from a network connection, but instead of waiting on that specific connection, we might read from another connection that is ready, accept a new connection or do anything else, before finally returning to this specific network connection and reading the data.
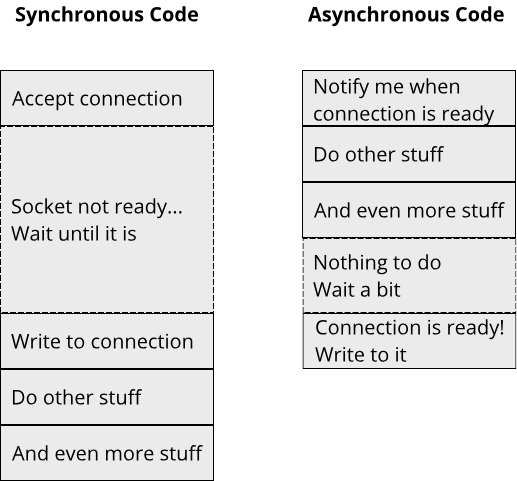
Making our poll based server easier to use
The first step on our journey towards asynchronous programming is to make our previous server code easier to use. We saw that we could use the mio library and handle multiple concurrent connections using the Poll type, but the code itself was pretty complex. The main problem is that the actual reading of data from a TcpStream is now tightly coupled with the event loop. Recall this code:
#![allow(unused)] fn main() { if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; loop { match connection.read(buffer.as_mut_slice()) { // ... } } } }
If we want to do something with the data that was read, we have to insert this new code right here after the end of this loop, deep within the event loop code. It would be great if we could register a callback function that gets called from this code with the &[u8] buffer containing all read data. Callbacks are a good tool for making asynchronous code possible, because the code within the callback might be called at some later point, but we can write it very close to where we initiate the asynchronous computation.
So let's write a Connection type that provides an asynchronous read method:
#![allow(unused)] fn main() { type OnReadCallback = fn(&[u8]) -> (); /// Wraps a TCP connection and gives it async functions (with callbacks) struct Connection { stream: TcpStream, callbacks: Vec<OnReadCallback>, } impl Connection { pub fn new(stream: TcpStream) -> Self { Self { stream, callbacks: vec![], } } pub fn read_sync(&mut self, buffer: &mut [u8]) -> std::io::Result<usize> { self.stream.read(buffer) } pub fn read_async(&mut self, on_read: OnReadCallback) { self.callbacks.push(on_read); } fn notify_read(&mut self, data: &[u8]) { for callback in self.callbacks.drain(..) { callback(data); } } } }
The Connection type wraps a TcpStream as well as a bunch of callbacks. It provides a read_sync method that just delegates to stream.read, and a read_async method that takes in a callback which will be called once the next data has been read from within the event loop. The event loop needs a way to trigger these callbacks, for which we have the notify_read function. With this, we can change our server function handle_readable_connection a bit to use this new Connection type:
#![allow(unused)] fn main() { fn handle_readable_connection( token: Token, connections: &mut HashMap<Token, Connection>, poll: &mut Poll, ) -> Result<()> { // ... if let Some(connection) = connections.get_mut(&token) { let mut buffer = vec![0; 1024]; let mut bytes_read = 0; loop { match connection.read_sync(&mut buffer[bytes_read..]) { Ok(n) => { bytes_read += n; if bytes_read == buffer.len() { buffer.resize(buffer.len() + 1024, 0); } } // ... } } if bytes_read != 0 { connection.notify_read(&buffer[..bytes_read]); } } // ... } }
Now, we read all the data into a single buffer and then call notify_read on the Connection object with this buffer. Notice that we changed the HashMap to store Connection objects instead of TcpStreams.
We can do the same thing with our TcpListener and wrap it in a Server type:
#![allow(unused)] fn main() { type OnNewConnectionCallback = fn(&mut Connection) -> (); /// Wraps a TCP connection and gives it async functions (with callbacks) struct Server { listener: TcpListener, callbacks: Vec<OnNewConnectionCallback>, } impl Server { // Assume just one server pub const TOKEN: Token = Token(0); pub fn new(listener: TcpListener, poll: &Poll) -> Result<Self> { let mut ret = Self { listener, callbacks: vec![], }; poll.registry() .register(&mut ret.listener, Self::TOKEN, Interest::READABLE)?; Ok(ret) } pub fn accept_sync(&mut self) -> std::io::Result<(TcpStream, SocketAddr)> { self.listener.accept() } pub fn accept_async(&mut self, on_new_connection: OnNewConnectionCallback) { self.callbacks.push(on_new_connection); } fn notify_new_connection(&mut self, connection: &mut Connection) { for callback in self.callbacks.iter() { callback(connection); } } } }
Here, we created two variants of the TcpListener::accept function: accept_sync just delegates to listener.accept, whereas accept_async takes a callback which will be passed the new Connection object once a connection has been established. Just as before, we also add a notify... method that the event loop can call to trigger all callbacks.
With this, we can rewrite our main method:
fn main() -> Result<()> { let mut poll = Poll::new().expect("Could not create mio::Poll"); let mut events = Events::with_capacity(1024); let mut connections = HashMap::new(); let listener = TcpListener::bind("127.0.0.1:9753".parse().unwrap())?; let mut server = Server::new(listener, &poll)?; // ... Awesome code goes here ... loop { poll.poll(&mut events, None)?; for event in events.iter() { match event.token() { Server::TOKEN => { handle_incoming_connections(&mut server, &mut connections, &mut poll) } _ => handle_readable_connection(event.token(), &mut connections, &mut poll), }?; } } }
Again, very similar to before, we just wrap the TcpListener in the Server type and pass this to handle_incoming_connections. Now look what we can do with the Server:
#![allow(unused)] fn main() { server.accept_async(|connection| { connection.read_async(|data| { if let Ok(string) = std::str::from_utf8(data) { println!("Got data from remote: {}", string); } else { println!("Got data from remote (binary): {:?}", data); } }); }); }
We can write asynchronous code which looks almost like synchronous code: Accept a new connection, and if it is ready, read data from the connection, and if the data is ready, do something with the data (print to standard output). The only downside is that the code still does not look super nice, due to all the callbacks we get lots of nesting which can be hard to follow. Let's see how we can fix that!
Future - An abstraction for an asynchronous computation
Let's look at this line of code right here: server.accept_async(|connection| { ... }). It's not unreasonable to say that accept_async is a computation that completes at some point in the future. Because we wanted to write asynchronous code, we couldn't write accept_async as a regular function returning a value - we don't want to block to wait for the value after all! But maybe we could return some sort of proxy object that encapsulates a value that becomes available at some point in the future.
Enter Future, a trait that represents an asynchronous computation which yields some value T at some point in the future. The idea of a Future type exists in many languages: C++ has std::future, JavaScript has a Promise type, C# has Task<T>, to name just a few. Some languages explicitly tie futures to threads (C++ does this), while other languages use a poll-based model (both Rust and JavaScript do this). Here is what the Future trait looks line in Rust:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
It is a bit complicated because it uses a bunch of new types, namely Pin<&mut Self> and the Context<'_> type, but for now we don't have to worry about those to understand what futures do in Rust. A Rust Future<T> provides just one method named poll. We can poll a future to ask if it is already finished, in which case it will return Poll::Ready(T). If it is not finished, Poll::Pending will be returned instead. This is similar to the TcpListener (and TcpStream) type of mio: We called listener.accept() until it returned an error that signalled that the listener is not ready to accept another connection. Instead of calling listener.accept() in a loop until it does not return an error anymore, we used the mio::Poll type to get notified when our listener is ready. Rust futures work in the same way, which is what the Context<'_> type is for. If the future is polled but is not ready, a callback is registered with the Context<'_> type which gets invoked once the future is ready to make progress! This is exactly like what we did in the previous example of our server using mio and callbacks!
The Future type by itself doesn't seem very useful at first: It only has a poll method, and it takes a lot of special parameters. It becomes powerful only in conjunction with a bit of Rust syntactic sugar and an executor. We will look at executors shortly, but first let's look at the syntactic sugar that Rust provides, namely the keywords async and .await!
async and .await in Rust
Recall the Server type that we wrote which has a method to accept connections asynchronously. This is how the method looked like:
#![allow(unused)] fn main() { pub fn accept_async(&mut self, on_new_connection: OnNewConnectionCallback) { self.callbacks.push(on_new_connection); } }
We couldn't return anything from accept_async because the return value (a Connection object) might not be available right now but instead at some point in the future. Notice something? Why not use a Future<Output = Connection> as return value for this function? Since Future is just a trait, we have to return some specific type that implements Future<Output = Connection>. We don't know what that type is at the moment, but let's just assume that we had such a type. Then we could rewrite our function to look like this:
#![allow(unused)] fn main() { pub fn accept_async(&mut self) -> impl Future<Output = Connection> { // magic } }
By itself, that still doesn't look like much, but here is where the .await keyword comes into play. We can write code that looks almost like sequential code but runs asynchronously using Future and .await, like so:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; let connection : Connection = server.accept_async().await; }
The type annotation is not strictly necessary, but illustrates that even though accept_async returns a Future, by using .await, we get back the Connection object from within the future. We can build on this and call multiple asynchronous functions in a row:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; let mut connection : Connection = server.accept_async().await; let data : Vec<u8> = connection.read_async().await; }
Notice how powerful this Rust feature is: We are still writing asynchronous code, so neither accept_async nor read_async will block, but it reads just like sequential code. No more callbacks and very little noise besides the .await call. There are a few caveats however that we have to be aware of.
First, .async is only allowed to be called from within an asynchronous function itself. So this right here won't work:
fn main() { // ... let mut server = Server::new(listener, &poll)?; let mut connection : Connection = server.accept_async().await; let data : Vec<u8> = connection.read_async().await; }
How does Rust know whether a function is asynchronous or not? For this, we have to use the second keyword: async. We can declare a function or a local block as async, turning it into an asynchronous function. So this would work:
#![allow(unused)] fn main() { let mut server = Server::new(listener, &poll)?; async { let mut connection: Connection = server.accept_async().await; let data: Vec<u8> = connection.read_async().await; }; }
As would this:
#![allow(unused)] fn main() { async fn foo(poll: &Poll) { let mut server = Server::new(listener, &poll).unwrap(); let mut connection: Connection = server.accept_async().await; let data: Vec<u8> = connection.read_async().await; } }
The second caveat becomes clear once we take a closer look at the .await calls. Asynchronous code shouldn't block, after all this was why we tried to do things asynchronously in the first place, so calling .await should not block our program. But we get a result back from our function when we call .await. How does that work, and where did the waiting go?
async and .await together create a state machine under the hood that represents the different stages in which our asynchronous computation can be in. Where previously we used a callback that gets invoked at some point in the future, .await goes the other way around and yields control back to whoever is responsible for managing our asynchronous code. In our callback-based code, we had an event loop that managed all asynchronous computations and called the respective callbacks whenever ready:
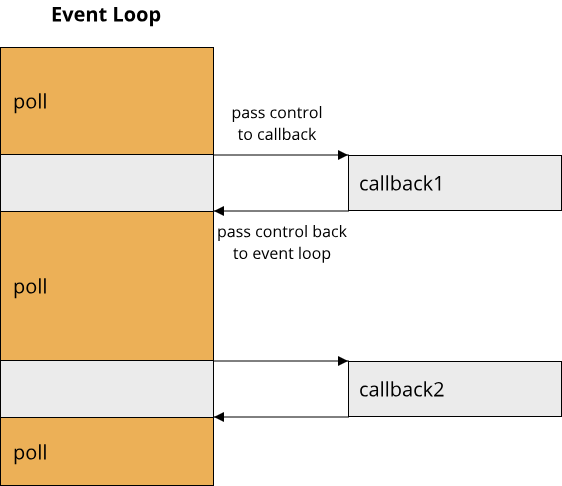
So our overall code was still sequential, we just split it up into the event loop and the various callback-based asynchronous functions. With async and .await, the picture is similar. There has to be a piece of code that drives the asynchronous code (by polling futures), and we call this piece of code the executor of our asynchronous code. This executor runs the code of our async block as far as possible, and whenever an .await statement is reached that is not ready, control is handed back to the executor, which will then continue with some other async block. So for our async-based server code, execution might look like this:
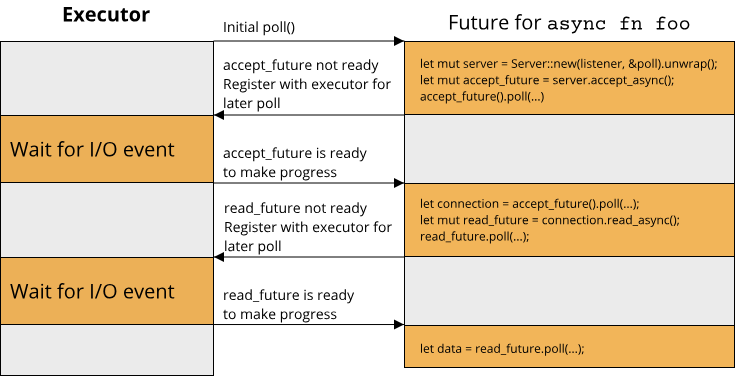
Notice that the code within the async function is made up of multiple Futures: accept_async returns a Future, as does read_async. The whole async function itself also returns a Future. So the .await statements are effectively points at which the execution of our function can halt for it to be resumed at some later point. It's like we had three separate, consecutive functions that read like a single function. This is why async creates a state machine, so that one Future that is 'made up' of other Futures can keep track of where it currently is within its strand of execution.
The whole point of asynchronous code is that we can effectively do multiple things at once. If we only have a single async function that gets executed, this function behaves very similar to the synchronous, blocking version. Only once we have multiple async functions executing at once do we see the benefits of asynchronous code:
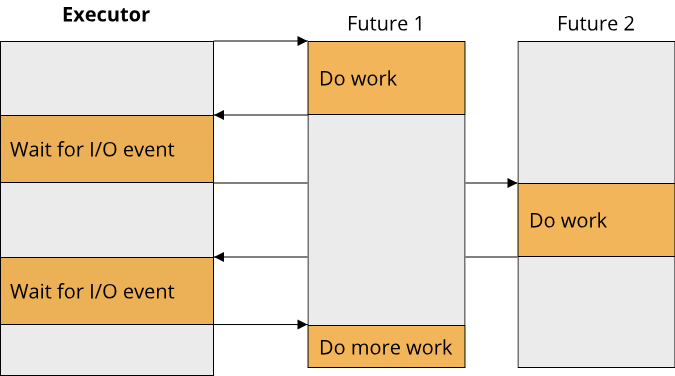
For the sake of completeness, here is how a Future for accepting connections from our Server type might be implemented:
#![allow(unused)] fn main() { struct ServerAccept<'a> { server: &'a mut Server, } impl<'a> Future for ServerAccept<'a> { type Output = Connection; fn poll( mut self: std::pin::Pin<&mut Self>, cx: &mut std::task::Context<'_>, ) -> std::task::Poll<Self::Output> { match self.server.accept_sync() { Ok((stream, _)) => { std::task::Poll::Ready(Connection::new(stream, self.server.executor.clone())) } Err(ref e) if e.kind() == std::io::ErrorKind::WouldBlock => { // Register callback to get notified if this specific listener is ready to accept another connection let waker = cx.waker().clone(); let executor = self.server.executor.clone(); let token = self.server.token; executor.register_io_event(token, &mut self.as_mut().server.listener, waker); std::task::Poll::Pending } Err(e) => panic!("Error while accepting connection: {}", e), } } } }
Without knowing what exactly the executor does, it is a bit harder to understand, but we will get to executors in the next section. The main point to take away from this piece of code is that within poll, it simply calls the synchronous accept_sync function! Since we are using the mio TcpListener type, this will return an error if it would have to block for data. We can use this error to figure out when the Future is not ready to make progress, and in this case register the Future itself with the executor to continue execution once a certain event has been registered by the executor. Once the executor registers the event in question - in this case that the TcpListener of the Server is ready to read from - it will poll the Future again. Access to the Future is given to the executor through the waker object. So let's look at how an executor might work then!
Executors for asynchronous code
The only missing piece in order to understand asynchronous code in Rust are the executors. An executor is responsible for polling Futures. Remember, by calling poll we make sure that a Future either makes progress or schedules itself to be polled again once it is ready to make progress. Each executor thus has to provide an interface through which asynchronous functions can be registered with it. This way the executor knows which Futures it must poll.
Here is a very simple executor called block_on:
#![allow(unused)] fn main() { use futures::pin_mut; fn block_on<T, F: Future<Output = T>>(f: F) -> T { pin_mut!(f); let mut context = ...; loop { if let Poll::Ready(result) = f.as_mut().poll(&mut context) { return result; } } } }
block_on always executes exactly one asynchronous function and simply blocks the current thread until the function has completed. The asynchronous function is represented by a single value that implements Future, and block_on calls poll on this Future in a loop until Poll::Ready is returned. Since poll has this weird signature that accepts not a &mut self but instead a Pin<&mut Self>, we have to create an appropriate Pin instance from our Future. For this, we can use the pin_mut! macro from the futures crate. We also need a Context to pass to poll. Context itself just acts as wrapper around a Waker object. Waker is the object that provides the wake method, which has to be called by the executor once the Future is ready to make progress. There are many different ways to implement the Waker type, for simplicity we will use the WakerRef type, also from the futures crate. WakerRef introduces another layer of indirection because it wraps a value of type &Arc<W> where W: ArcWake. ArcWake itself is a trait that has a single method wake_by_ref which implements the logic of what happens with a Future if it is waked by its associated Waker.
Quite complicated, so let's work through a bunch of examples. Our block_on executor as it is now has no notion of waking any Futures, because it just calls poll in a busy-loop. We really don't need any Waker behaviour, so let's implement a NoOpWaker:
#![allow(unused)] fn main() { struct NoOpWaker; impl ArcWake for NoOpWaker { fn wake_by_ref(_arc_self: &std::sync::Arc<Self>) {} } }
With this, we can create a Context like so:
#![allow(unused)] fn main() { let noop_waker = Arc::new(NoOpWaker); let waker = waker_ref(&noop_waker); let mut context = Context::from_waker(&waker); }
With block_on, we can already execute async functions and blocks:
fn main() { let connection = block_on(async { let listener = TcpListener::bind("127.0.0.1:9753".parse().unwrap()) .expect("Could not bind TcpListener"); let mut server = Server::new(listener); server.accept_async().await }); println!("Got connection to {}", connection.peer_addr().unwrap()); }
As it stands now, block_on is not great. Compared to simply calling server.accept_sync(), block_on consumes much more CPU resources because it is running a busy-loop. We also don't use the waking functionality that is one of the key parts of Futures in Rust. Because we don't use waiting, we have to busy-loop and call poll constantly - we just have no other way of knowing when our Future might be ready to make progress. For our accept_async function, we would have to implement an executor that uses the mio::Poll type, but instead of doing something so complicated, let's look at a simpler Future that can actually use the waking functionality quite easily: A Timer!
For our purposes, a Timer is a piece of code that calls another piece of code after a given number of seconds have elapsed. When using async code, we don't have to memorize what code we want to call because we can model the Timer as a single Future that completes when the given number of seconds have elapsed. If we .await this Future, any code after the .await will be called once the Timer has finished. So our Timer is a type that implements Future:
#![allow(unused)] fn main() { struct Timer {} impl Timer { pub fn new(duration: Duration) -> Self { std::thread::spawn(move || { std::thread::sleep(duration); // TODO notify that we are ready }); Self {} } } impl Future for Timer { type Output = (); fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { // TODO How do we know that we are ready or not? } } }
We can realize the waiting portion of the Timer with a separate thread using std::thread::sleep, which blocks the thread for the given amount of time. Only, once std::thread::sleep returns, we need a way to signal to our Future that we are ready to progress. Ideally, we would be able to call upon this completion status within the poll method. Since this is a shared piece of information between multiple threads, let's give our Timer some shared state:
#![allow(unused)] fn main() { struct TimerState { ready: bool, } struct Timer { shared_state: Arc<Mutex<TimerState>>, } impl Timer { pub fn new(duration: Duration) -> Self { let state = Arc::new(Mutex::new(TimerState { ready: false, })); let state_clone = state.clone(); std::thread::spawn(move || { std::thread::sleep(duration); let mut state = state_clone.lock().unwrap(); state.ready = true; }); Self { shared_state: state, } } } }
With this shared state, we can check during poll whether the timer has elapsed or not:
#![allow(unused)] fn main() { fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let mut state = self.shared_state.lock().unwrap(); if state.ready { Poll::Ready(()) } else { Poll::Pending } } }
Let's run this code using our block_on executor:
fn main() { println!("Starting to wait..."); block_on(async { timer(Duration::from_secs(1)).await; println!("One second elapsed"); }); }
This prints Starting to wait... and then after about a second One second elapsed. So it works! The thing is, we still are using this busy-loop from within our executor, which takes a lot of CPU resources. Let's try to put our main thread to sleep until the Future is ready to make progress:
#![allow(unused)] fn main() { fn block_on<T, F: Future<Output = T>>(f: F) -> T { // ... loop { if let Poll::Ready(result) = f.as_mut().poll(&mut context) { return result; } std::thread::park(); } } }
We can use std::thread::park to let the current thread sleep util it is woken up by some other thread. This is great, because then the thread won't get scheduled and doesn't take up CPU resources. Now we just need a way for the timer thread to wake up our main thread. This is where the Waker comes in again (the name even begins to make sense now!), because we can write a Waker that can wake up threads:
#![allow(unused)] fn main() { struct ThreadWaker { handle: Thread, } impl ArcWake for ThreadWaker { fn wake_by_ref(arc_self: &Arc<Self>) { arc_self.handle.unpark(); } } }
Our ThreadWaker takes a Thread handle and once it is awoken, it calls unpark on that handle, which in turn will wake up the thread. Now we just need a way to make this ThreadWaker accessible to the timer thread. The only location where our Timer has access to the ThreadWaker is within poll, because here it has access to the Context through which we can retrieve the Waker:
#![allow(unused)] fn main() { fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let mut state = self.shared_state.lock().unwrap(); if state.ready { return Poll::Ready(()); } let waker = cx.waker().clone(); state.waker = Some(waker); Poll::Pending } }
To make sure that the timer thread can access the Waker, we have to extend our shared state to also include an Option<Waker>. We have to use Option because intially, there is no Waker assigned to the Timer.
#![allow(unused)] fn main() { struct TimerState { ready: bool, waker: Option<Waker>, } impl Timer { pub fn new(duration: Duration) -> Self { let state = Arc::new(Mutex::new(TimerState { ready: false, waker: None, })); let state_clone = state.clone(); std::thread::spawn(move || { std::thread::sleep(duration); let mut state = state_clone.lock().unwrap(); state.ready = true; if let Some(waker) = state.waker.take() { // Wake up the other thread through the Waker (which internally is a ThreadWaker!) waker.wake(); } }); Self { shared_state: state, } } } }
Now our block_on executor is much more efficient: It tries to poll the Future and if it is not yet ready, puts itself to sleep until the Future signals that it is ready to make progress using the ThreadWaker, which then wakes up the thread again, causing block_on to loop and call poll again. Neat!
As a closing note: Our block_on function is almost identical to futures::executor::block_on, a very simple executor provided by the futures crate.
More sophisticated executors
block_on is a simple but not terribly useful executor, because it only executes a single future, so we can't really do anything asynchronous with it. In real production code, we want to use a more powerful executor that also supports things like mio::Poll for real asynchronous I/O. There are a bunch of executors available, the two most popular ones are found in the tokio and async_std crates. Since asynchronous applications often want to run everything inside main in an asynchronous manner, both tokio as well as async_std provide macros to turn main into an async function, here shown for tokio:
#[tokio::main] async fn main() { timer(Duration::from_secs(1)).await; }
If you are interested in more details on how the executors in these libraries are built, the Rust async book has some chapters on how to build executors.
Many I/O heavy libraries for writing network applications are built on top of tokio or async_std, at the moment of writing tokio is a bit more popular and has a larger ecosystem though.
Conclusion
This concludes the chapter on asynchronous code, and with it our discussion of fearless concurrency using Rust. In this chapter, we learned a lot about what asynchronous code is and how it differs from writing parallel code. We saw that we can use the technique of I/O mutiplexing to manage multiple I/O operations from a single thread without unnecessarily blocking. Built on top of that is the Rust async/.await construct, which uses the Future trait to turn any synchronous computation into an asynchronous one. To execute Futures, we use executors, for which we saw one simple example (block_on) and the more sophisticated runtimes of tokio and async_std.
Performance - How to write efficient systems software
In this chapter we will look at a topic that is near-and-dear to many systems programmers: Performance! Performance is this mythical attribute that a software can have which makes it go fast! Of course there is a bit more to performance than just 'running fast'. In this chapter we will take a look at what it means for a piece of software to have good performance, and how we can achieve this goal.
The topics covered in this chapter are:
- What is performance, and how do we know that we have it?
- Understanding performance through benchmarking and profiling
- Tips for writing efficient code for systems software
- Vectorization
What is performance, and how do we know that we have it?
Let's start our journey towards the mythical lands of high performance code. Instead of venturing into the unknown, let's take a moment to first understand what it is that we are actually aiming for. What is performance, in the context of (systems) software? Here is a definition of the term "performance" by The Free Dictionary:
"performance: The way in which someone or something functions"
This helps only a little. Clearly, performance is related to how a piece of software functions, but this definition is too broad. A better definition can be found in 'Model-based software performance analysis' by Cortellessa et al. {{#cite cortellessa2011model}}, where they talk about "[t]he quantitative behavior of a software system". Quantitative in this context means that there are numbers that we can associate with software performance. You might have an intuitive sense of what 'software performance' means, something along the lines of 'How fast does my program run?', and this definition fits with that intuition. Indeed, runtime performance is one aspect of software performance in general, and it can be expressed through numbers such as wall clock time - a fancy term for the time that a piece of software or code takes to execute.
Understanding performance through metrics
'How fast does my program run?' is a good question to ask, and it might prompt us to ask other similar questions, such as:
- 'How much memory does my program allocate?'
- 'How quickly does my program respond to user input?'
- 'How much data can my program read or write in a given amount of time?'
- 'How large is the executable for my program?'
Notice that all these questions are intimately tied to the usage of hardware resources! This is why software performance is especially important in the domain of systems programming: Systems software tries to make efficient use of hardware resources, and we can only know that our software achieves this goal if we have tangible evidence in the form of numbers for resource usage. We call such numbers metrics.
For all of the previous questions, we thus are looking for one or more metrics that we can measure in our software so that we can answer these questions:
- 'How much memory does my program allocate?' can be answered by measuring the memory footprint
- 'How quickly does my program respond to user input?' can be answered by measuring the response time of the software (which can be fairly complex to measure)
- 'How much data can my program read or write in a given amount of time?' can be answered by measuring the I/O throughput
- 'How large is the executable for my program?' is almost a metric in and of itself, and can be measured using the file size of the executable
These are only a few high-level concepts for assessing software performance, in reality there are tons of different metrics for various aspects of software performance and hardware resource usage. Here are a bunch of fancy metrics that you might track from your operating system and CPU:
- Branch misprediction rate
- L1 cache miss rate
- Page miss rate
- Number of instructions executed
- Number of context switches
We'll look at some of these metrics in the next chapter, where we will learn how to track metrics during execution of a piece of software.
Qualitative assessment of performance
For now, let us first try to understand what we gain from the quantitative analysis of software performance. Ultimately, we end up with a bunch of numbers that describe how a piece of software performs. By itself, these numbers are meaningless. "Running software A takes 7 minutes" is a statement without much usage due to a lack of context. If this software calculates 2+3, then 7 minutes seems like an unreasonably long time, if this software computes an earth-sized climate model with 10 meter resolution, 7 minutes would be a miracle. We thus see that performance metrics are often tied to some prior assumption about their expected values. Labels such as 'good performance' and 'bad performance' are qualitative in their nature and are ultimately the reason why we gather metrics in the first place.
To assess software performance, we thus have to compare metrics to some prior values. These can either be taken from experience ('adding numbers is fast, computing climate models is slow') or they can be previous versions of the same metric, obtained from a previous evaluation of software performance. The first kind of assessment is typically goal-driven, with a clear performance number in mind that implementors of the software try to reach. Examples include a target framerate in a video game, a target response time for a web application, or a target size for an executable so that it can fit on some embedded device. The second kind of assessment is often used to ensure that performance did not deteriorate after changes in the software, or to illustrate improvements in the software. The statement "The new version of our software now runs 3 times faster than the old version" is an example for the second kind of performance assessment.
Software performance assessment seldom is a singular process. In reality, it often induces a feedback-loop, where you collect your metrics for a certain piece of code, apply some changes, collect metrics again, compare the metrics to gain insight, and apply more code changes.
By gathering performance metrics repeatedly, for example as part of a build pipeline, your application's performance becomes a first-class citizen and can be tracked just as one typically does with unit tests or coding guidelines. The Rust compiler rustc tracks the results of various performance benchmarks with each commit to the main branch in the rust repository. The data can then be viewed in graph-form here.
Why should we care about performance?
Performance as a property can range from being a key functional requirement to a marginal note in the software development process. Real-time systems care most about performance, as they require a piece of code to execute in a given timeframe. On the opposite end of the spectrum one can find custom data analysis routines which are rarely executed but give tremendous insight into data. Here, the importance of performance is low: Why spend three hours optimizing a script that only runs for 15 minutes?. Most software falls somewhere inbetween, where the potential benefits of performance optimization have to be judged on a case-by-case basis. Here are some reasons why you might care about the performance of your software:
- Performance is a functional requirement (e.g. your software has to process X amount of data in Y seconds/minutes/hours)
- Performance is relevant to the user experience (e.g. your software needs to 'feel smooth/quick/snappy/responsive')
- Energy consumption is a concern (e.g. your software shouldn't drain the battery unnecessarily fast)
- Money is a concern (e.g. because your software runs on rented virtual machines in the cloud which are billed by CPU hours)
The last two points in particular are becoming more relevant as more software is run in the cloud and global energy usage for computers becomes an issue.
Exercise 8.1 Identify one piece of software that would benefit from better performance for each of the reasons stated above.
Understanding performance through benchmarking and profiling
In this chapter, we will look at how we can measure performance in systems software (though many of these techniques are not exclusive to systems software) by using a series of tools often provided by the operating system. When it comes to measuring performance, there are three terms that you might stumble upon: Benchmarking, profiling, and tracing. While they might be used interchangeably, the do mean different things and it is useful to know when to use which. Once we understand these terms, we will look at the tools available in modern operating systems (and the Rust programming language!) to understand the performance characteristics of our software.
Benchmarking vs. profiling vs. tracing
Benchmarking is perhaps the simplest to understand: When we employ benchmarking, we are looking for a single number that tells us something about the performance of our program. Executing this program takes 12 seconds on this machine, this function executes in 200 microseconds, the latency of this network application is about 200 milliseconds, or I get 60 frames per second in 'God of War' on my PC are all examples of benchmarking results (though the last is very high-level). The important thing is that the result of a benchmark is a single number.
Since modern computers are complex machines, performance is not always constant: The current system load, other programs running on your machine, thermal throttling, caching, all can have an effect on performance. This makes it hard to measure precise values when running a benchmark. Sticking with the previous examples, running program X might take 12 seconds when you run it the first time, but then only 10 seconds the second time, and then 13 seconds the third time, and so on. To deal with these uncertainties, benchmarking requires making use of statistics to quantify the uncertainty in a measurement. The amount of uncertainty that is to be expected depends on the system that you are benchmarking on: A microcontroller such as an Arduino might have very predictable performance, whereas running a program on a virtual machine in a Cloud environment where hardware is shared with thousands or millions of other programs and users can lead to much larger fluctuations in performance. The simplest way to get reliable results when benchmarking is thus to run the benchmark multiple times and performing statistical analysis on the results to calculate mean values and standard deviations.
The next performance measuring process is profiling. With profiling we try to understand how a system behaves. The result of profiling is - as the name suggest - a profile that describes various performance aspects of a system. An example is called 'time profiling', where the result is a table containing the runtime of each function in a program. If benchmarking tells you the number of seconds that your program takes to execute, profiling tells you how this number came to be. Profiling is immensely useful when developing modern systems software, as it helps us to make sense of the complexity of hardware and software. Where benchmarking answers the 'What?'-questions ('What is the runtime of this piece of code?'), profiling answers the 'Why?'-questions ('Why is the runtime of this piece of code X seconds? Because 80% of it is spent in this function and 20% in that function!'). Profiling can be overwhelming at first due to the increased amount of information compared to benchmarking, but it is an indispensable tool for systems programmers.
The last term is tracing, which is similar to profiling but not limited to performance measurements. It instead aims at understanding system behaviour as a whole and is often used whenever the system at hand is large and complex (such as operating systems or distributed systemsThe challenge with distributed systems is not that they are distributed, but instead that communication is asynchronous, which makes it difficult to understand cause/effect relationships. Incidentally, this is one of the reaons why distributed systems are considered 'hard' to develop for.). Tracing mainly helps to understand causal relationships in complex systems and as such the result of tracing (the trace) is most often a list of events with some relationship between them. Tracing can be used to understand system performance, but typically is used to understand causal relationships instead, for example to identify root failure causes in distributed systems.
An interesting property of benchmarking in contrast to profiling and tracing is that benchmarking in general is non-invasive, whereas profiling and tracing is invasive: Measuring a single number, such as program runtime, typically doesn't require an interference with the program itself, but understanding whole program behaviour requires some sort of introspection into the inner workings of the program and thus is invasive. As a result, benchmarking can almost always be done without affecting the behavior of the program, but gathering the necessary information for profiling and tracing might have some performance overhead itself. Simply put: The more detailed the information is that you want to gather about your system, the more resources you have to allocate to the information gathering, compared to actually running the program.
A first simple benchmark
Now that we know the difference between benchmarking, profiling, and tracing, how do we actually perform these actions? We saw that benchmarking is conceptually simple, so this is where we will start. In the previous chapter, we saw some performance metrics such as wall clock time or memory footprint. Let's try to write a benchmark that measures wall clock time, i.e. the amount of time that a piece of code takes to execute.
The first thing we need is some code that we want to write a benchmark for. Since we want to measure wall clock time, it should be a piece of code that takes a certain amount of time to run so that we get some nice values. For this first example, we will compute the value of the Ackermann function, which can be done in a few lines of Rust:
#![allow(unused)] fn main() { fn ackermann(m: usize, n: usize) -> usize { match (m, n) { (0, n) => n + 1, (m, 0) => ackermann(m - 1, 1), (m, n) => ackermann(m - 1, ackermann(m, n - 1)), } } }
We can write a very simple command line application that takes two integer values as arguments and calls ackermann to compute the value of the Ackermann function using the clap crate:
use clap::Parser; #[derive(Parser, Debug)] struct Args { #[clap(value_parser)] m: usize, #[clap(value_parser)] n: usize, } fn ackermann(m: usize, n: usize) -> usize { ... } fn main() { let args = Args::parse(); println!("A({},{}) = {}", args.m, args.n, ackermann(args.m, args.n)); }
The Ackermann function is an extremely fast-growing function. The Wikipedia article has a table showing values of the Ackermann function where we can see that even for very small numbers for m and n we quickly move beyond the realm of what our computers can handle. Try playing around with values for m and n and see how the program behaves! In particular notice the difference between ackermann(4,0) and ackermann(4,1) in terms of runtimeYou might have to run your program in release configuration to make ackermann(4,1) work!!
To measure the runtime of ackermann, we have a multiple options. We can measure the runtime of the whole program with a command-line tool such as time. A first try to do this might look like this: time cargo run --release -- 4 1. Notice that we run our code in release configuration! Always run the release build of your code when doing any kind of performance measurements! As we learned, building with release configuration allows the compiler to perform aggresive optimizations, causing code in release configuration to be significantly faster than code in debug configuration!
The output of time cargo run --release -- 4 1 might look like this:
Finished release [optimized] target(s) in 0.14s
Running `target/release/ackermann 4 1`
A(4,1) = 65533
cargo run --release --bin ackermann -- 4 1 3.00s user 0.07s system 95% cpu 3.195 total
Unfortunately, cargo run first builds the executable, so we get the runtime of both the build process and running the ackermann executable. It is thus better to run the executable manually when checking its runtime with time: time ./target/release/ackermann 4 1 might yield the following output:
A(4,1) = 65533
./target/release/ackermann 4 1 2.83s user 0.00s system 99% cpu 2.832 total
It tells us that the ackermann program took 2.832 seconds to execute.
time is an easy way to benchmark wall clock time for executables, but it is very restrictive as it only works for whole executables. If we want to know how long a specific function takes to execute within our program, we can't use time. Instead, we can add time measurement code within our program! If we had a very precise timer in our computer, we could ask it for the current time before we call our function, and the current time after the function returns, calculate the difference between the two timestamps and thus get the runtime of the function. Luckily, modern CPUs do have means to track elapsed time, and systems programming languages such as Rust or C++ typically come with routines to access these CPU functionalitiesIf you want to understand how the CPU keeps track of time, the documentation for the Linux clock_gettime system call is a good starting point.. In the case of Rust, we can use the std::time::Instant type from the standard library. As the name suggests, it represents an instant in time for some arbitrary clock, with the specific purpose of being comparable to other instants in time. Comparing two Instant types yields a std::time::Duration type, which can be converted to known time measurement units such as seconds, milliseconds etc. To use Instant for wall clock time measurement, we use the following pattern: At the start of the block of code that we want to measure, create an Instant using Instant::now(). Then at the end of the block, call elapsed on this Instant to receive a Duration, which we can convert to time values using various functions such as as_secs or as_millis. In code, it will look like this:
#![allow(unused)] fn main() { let timer = Instant::now(); println!("A({},{}) = {}", args.m, args.n, ackermann(args.m, args.n)); println!("Took {} ms", timer.elapsed().as_secs_f32() * 1000.0); }
Note that if you want to show the fractional part of the time value as we do here, instead of using as_millis we have to use as_secs_f32 (or as_micros) and manually convert to milliseconds, since as_millis returns an integer value and thus has no fractional part.
With this simple pattern, we can measure the wall clock time for any piece of code in our Rust programs!
Limitations of using std::time::Instant for wall clock time benchmarking
There are limitations when using the Instant type (or any related type in other programming languages) for wall clock time measurements:
- It requires changing the code and thus manual effort. It also will clutter the code, especially once you start to use it for more than one block of code at a time.
- The precision depends on the underlying timer that the standard library uses. In Rust, a high-precision timer is used, which typically has nanosecond resolution, but this might be different in other languages.
- On its own, benchmarking with
Instantdoes not perform any statistical analysis of the runtimes. It just measures runtime for one piece of code, which - as we saw - might vary from invocation to invocation.
Measuring time with Instant is very similar to debugging using print-statements: It is simple, works in many situations, but is also very limited. We generally have better tools at our disposal: Debuggers instead of print-statements and profilers instead of manual time measurements. We will see profilers in action shortly, but first we will see how we can write more sophisticated benchmarks!
Benchmarking in Rust with statistical analysis
We saw that benchmarking has its uses: Sometimes we really do want to know just how long a single function takes so that we can focus all our optimization efforts on this function. It would be great if we could easily take existing functions and write benchmarks for them which deal with all the statistical stuff. A good benchmark would run the piece of code that we want to measure multiple times, record all runtimes and then print a nice statistical analysis of the findings. Even more, due to the various caches in modern computers, running code for the first time or couple of times might be slower than running it for the fifth or tenth or hundreth time, so a 'warmup period' would also be nice. Oh and we have to make sure that we take enough samples to get a statistically significant result!
With your knowledge of systems programming and a bit of looking up the math in a statistics textbook you should be able to write code that does exactly this yourself. Or you could use the existing capabilities of Rust, namely cargo bench. Yes, cargo also includes functionalities for running benchmarks!
Benchmarks, similar to tests, are standalone functions that get run by a harness, which is a framework that orchestrates benchmark execution and gathering of information. With unit tests in Rust, you mark them with a #[test] attribute and when you type cargo test some magical framework finds all these tests, runs them and deals with any failures. This is a test harness, and the same thing exists for benchmarks. Since you typically want statistical analysis, warmups and whatnot, in practice you might use a sophisticated benchmark harness such as criterion.
Let's take a look at how a typical benchmark with criterion looks like. In rust benchmarks are stored in a folder called benches right in the root directory of your project:
benches/
benchmark_1.rs
...
src/
lib.rs
...
Cargo.toml
...
Here is an example of a typical benchmark function with criterion:
#![allow(unused)] fn main() { pub fn ackermann_bench(c: &mut Criterion) { c.bench_function("Ackermann(4,0)", |bencher| { bencher.iter(|| ackermann(4,0)); }); c.bench_function("Ackermann(4,1)", |bencher| { bencher.iter(|| ackermann(4,1)); }); } }
Two things are worth noting here: First we have a Criterion object which we can use to bench multiple functions at the same time. Second benching functions works through the bencher object which provides an iter which does exactly what we want, namely to run the function to benchmark multiple times. To run this benchmark we have to do a bit more: We have to add some boilerplate code that generates a main function and registers our benchmark function with criterion. We can do so like this:
#![allow(unused)] fn main() { // Add these imports up top: use criterion::{criterion_group, criterion_main, Criterion}; // Tell criterion the name for our benchmark and register the benchmark function as a group criterion_group!(bench, ackermann_bench); criterion_main!(bench); }
The other thing we have to do is to tell cargo that we want to use criterion as a benchmark harness. We have to do this in the Cargo.toml file like so:
[[bench]]
name = "ackermann_bench" # name of the benchmark file minus the file extension
harness = false
We can now execute our benchmarks by running cargo bench. Part of the output will look like this:
Ackermann(4,1) time: [2.8204 s 2.8524 s 2.8899 s]
Found 10 outliers among 100 measurements (10.00%)
5 (5.00%) high mild
5 (5.00%) high severe
We see that criterion ran the Ackermann(4,1) benchmark 100 times and computed statistical values for the resulting runtime. The values printed after time are what criterion calculated as the most likely candidates for the average runtime (specifically the lower bound, estimate, and upper bound, in that order). It also reported that there were some outliers whose runtime differed from the average runtime by some predefined percentage. Even better, criterion generates a visual analysis of the results and exports them to an HTML file that we can view. These files can be found in the target/criterion directory. For the Ackermann(4,1) test for example, there exists a file target/criterion/Ackermann(4,1)/report/index.html which looks like this:
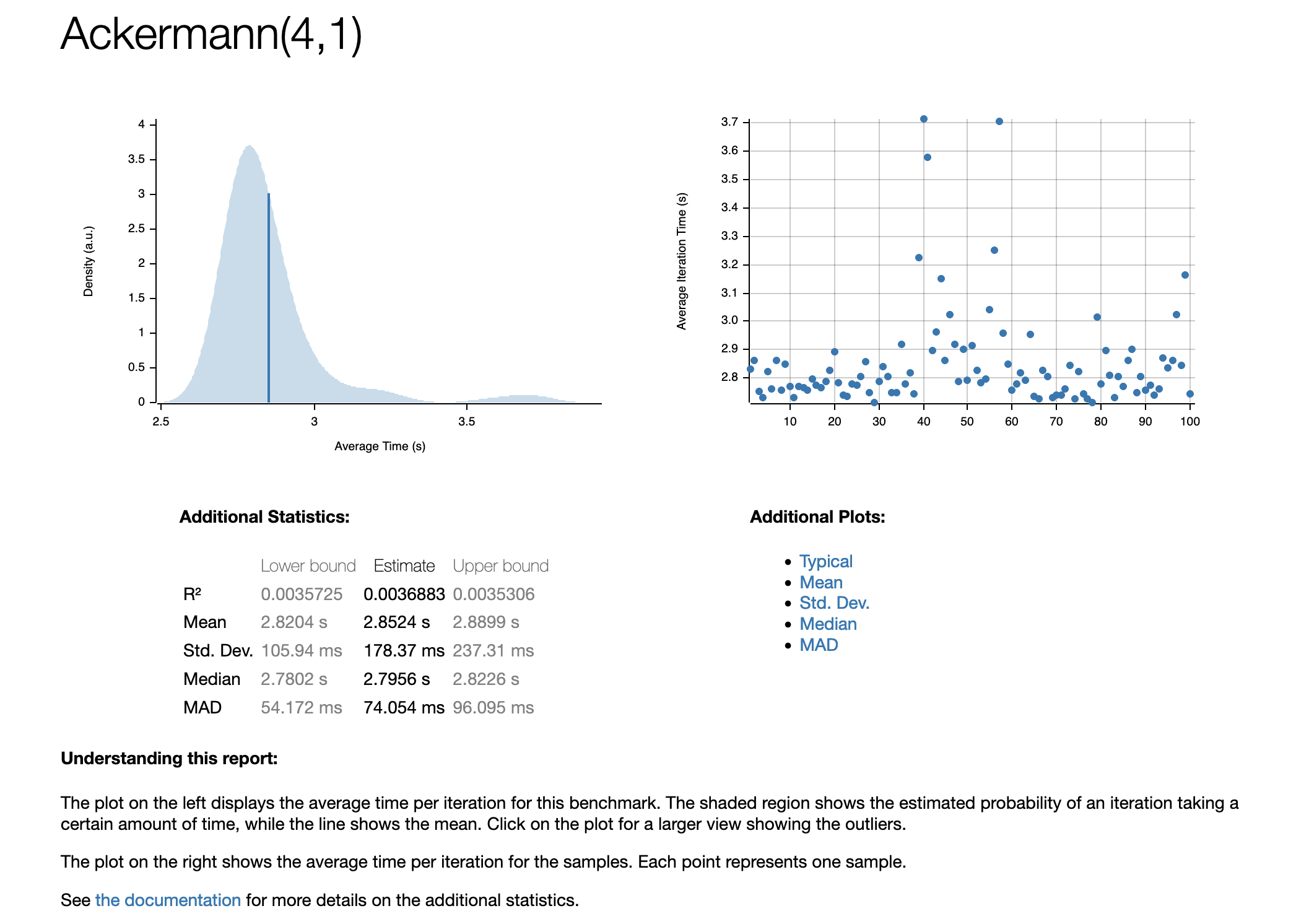
Another userful feature of criterion is that it memorizes the benchmark results and compares the current results to the previous results. Suppose we decide to optimize the function by explicitly stating one more case in the match statement:
#![allow(unused)] fn main() { (1, n) => ackermann(0, ackermann(1, n - 1)), }
We think this might speed up the function, but there is no need for guesswork. We can simply run cargo bench again and take a look at the output of criterion:
Ackermann(4,1) time: [1.0168 s 1.0213 s 1.0263 s]
change: [-64.689% -64.196% -63.756%] (p = 0.00 < 0.05)
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
2 (2.00%) high mild
3 (3.00%) high severe
This was indeed a good change, criterion figured out that the performance has improved by about 64% and it even tells us the probability that this change in performance is just a random fluctuation. p = 0.00 < 0.05 in this case tells us that the probability is basically zero (or at least below 1%) that this is a random-chance event.
If you want to familiarize yourself further with criterion, the criterion user documentation is a good read that goes into detail on a lot of the configuration options and the statistical analysis that criterion performs.
Profiling
After you have written a benchmark for a function, you might still not know precisely why that function is as fast or slow as it is. This is where profilers come in handy, as they create an in-depth profile of the behavior of a program which lets us examine all sorts of detail that we might need to understand where the performance characteristics of the program originate from. Profiling is a complex topic and we can only skim the surface here, but there are lots of resources out there for the various profiling tools that exist.
First, we will need a program that we want to profile. Our Ackermann function calculator is a bit too simple, so instead we will use a slightly more useful program that can find occurrences of strings in files. Something like grep, but with much less features so that it fits in this book. A crude version of grep, if you will. Introducing crap, the silly grep variant!
crap - grep with less features
The whole code is still a bit too large to easily fit here, you can look it up online here. In essence, crap does what grep does: It searches for occurrences of some pattern in one or more files. We can launch it like so: crap PATH PATTERN, where PATH points to a file or directory, and PATTERN is the pattern to search for. To search for all occurrences of the word Rust in the source code of this book, you would call crap /path/to/book/src Rust, which would print something like this:
Matches in file /Users/pbormann/data/lehre/advanced_systems_programming/skript/src/chap4/4_1.md:
61 - 284: ...f the Rust progr...
76 - 141: .... The Rust-type ...
76 - 251: ..., the Rust type ...
78 - 94: ...2` in Rust? What...
80 - 78: ...>` in Rust? We c...
...and so on
The heart of crap is the search_file function, which looks for matches in a single file. If you pass a directory to crap, it recursively searches all files within that directory! search_file looks like this:
#![allow(unused)] fn main() { fn search_file(path: &Path, pattern: &str) -> Result<Vec<Match>> { let file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; Ok(file .lines() .enumerate() .filter_map(|(line_number, line)| -> Option<Vec<Match>> { let line = line.ok()?; let matches = regex .find_iter(line.as_str()) .map(|m| { // Get matches as Vec<Match> from line }) .collect(); Some(matches) }) .flatten() .collect()) } }
It reads the file line-by-line and searches each line for occurrences of pattern (the pattern we passed as command-line argument!) using the regex crate. When a match is found, it is converted into a Match object like so:
#![allow(unused)] fn main() { let context_start = m.start().saturating_sub(NUM_CONTEXT_CHARS); let context_end = (m.end() + NUM_CONTEXT_CHARS).min(line.len()); // If the match is somewhere inbetween, print some ellipses around the context to make it more pretty :) let ellipse_before = if context_start < m.start() { "..." } else { "" }; let ellipse_after = if context_end < line.len() { "..." } else { "" }; // Make sure the context respects multi-byte unicode characters let context_start = line.floor_char_boundary(context_start); let context_end = line.ceil_char_boundary(context_end); Match { context: format!( "{}{}{}", ellipse_before, &line[context_start..context_end], ellipse_after ), line_number, position_in_line: m.start(), } }
This code extracts the match itself and some of its surrounding characters from the line (called context here), which is why crap always prints a bit more than just the pattern on each line. It also memorizes the line number and the position within the line, which are the two numbers that you see before the context:
61 - 284: ...f the Rust progr...
// Match in line 61, starting at character 284
Understanding the performance characteristics of crap
Now that we have our program, let's start to analyze the performance. We already saw that we can get a very rough estimate of the wall clock time by using time, so let's do that with crap. We also need some test data that is interesting enough and large enough so that we get usable performance data. We will use enwik8, which is a dump of the English Wikipedia containing the first 100MB of data. Let's see how crap fares to find all occurrences of the term Wikipedia. First, let's see how many matches we get. You can either run crap with logging enabled by setting the environment variable RUST_LOG to info, or use the command line tool wc, if you are on a Unix system:
crap enwik8 Wikipedia | wc -l
|> 2290
So 2290 matches. Technically, 2289 because crap also prints the file name of each file it searches. How long does it take?
time crap enwik8 Wikipedia
|> 0.25s user 0.03s system 86% cpu 0.316 total
0.3 seconds to search through 100MB of text, which gives us a throughput of about 330MB/s. Not bad. But can we do better? Let's compare it to some existing tools. First, grep:
time grep -o Wikipedia enwik8
|> 0.82s user 0.07s system 79% cpu 1.119 total
We use -o to print only the matching words, as otherwise grep prints a lot more (and nicer) context than crap. But hey, crap is about 3 times faster than grep! This is probably not a fair comparison though, as grep is much more powerful than crap. Let's try ripgrep, a faster grep alternative written in Rust!
time rg -o Wikipedia enwik8
|> 0.02s user 0.05s system 35% cpu 0.182 total
ripgrep is about twice as fast as crap, and it is also more powerful! Oh crap!!
Now it is time to whip out the big tools! We have to profile crap to understand where we can optimize! Profilers are system-specific tools, so we will only look at one profiler here - Instruments for MacOSWhy a profiler for MacOS and not Linux? The go-to profiler for Linux is perf, which is very powerful but runs only on the command line. Instruments for MacOS has a nice GUI and is similar to other GUI-based profilers such as the one shipped with Visual Studio on Windows. - but the workings are usually similar when using other profiling tools.
Instruments - A profiler
We saw that there are many metrics that we can gather for a program. If you launch a profiler such as Instruments, you typically will be greeted by a screen to select what type of profiling you want to do. Here is how it looks like for Instruments:
There are some MacOS-specific features here, but also some more general ones. We will look at the CPU Profiler and the Time Profiler in detail, but here is a list of what the most common profiling types are that you will find in profiling applications:
- Cycle- or time-based profilers that show how long each function in your code took to execute
- CPU counters, which show things like cache miss rates, branch mispredictions and other low-level counters that your CPU supports
- System tracing, showing a more general overview of the inner workings of the operating system while your application is running. This might show things like how thread are scheduled across CPU cores, or virtual memory page misses
- Network tracing, which shows network packages and network traffic generated by your application
- Memory tracing, which shows how memory is allocated and from which part of your code. This might also include detecting memory leaks
- GPU profiling, which shows what code is executed on your GPU, how long it takes, and might also include GPU counters similar to the CPU counters. If you are doing graphics programming, there might be dedicated graphics profilers that show things like draw calls, shader, buffer, and texture usage in more detail
We will choose the CPU Profiler option for now. If we do that, we have to select the executable that we want to profile, so make sure that you have a compiled binary available. Two things are important: We want a release build, because it is optimized and we typically want to measure performance of the optimized version of our program. And we want debug symbols, so that we can understand the names of the functions that were called. In Rust, you can add the following two lines to your Cargo.toml file to generate debug symbols even in a release build:
[profile.release]
debug = true
In Instruments, selecting the executable looks like this:
We can specify command line arguments with which to run this executable, and some other parameters such as environment variables. Once we have our executable selected, we will be greeted with the main screen for CPU profiling in Instruments. At the top left, there is a record button that we can press to run our program while the profiler is gathering its data. If we do that with our crap tool, this is what we might get:
There are three main areas of interest in this screen:
- A timeline at the top, with some graphs that show things like CPU usage over time. Here, you can filter for a specific region in time, which is helpful for narrowing in on critical sections of your program
- A call-hierarchy view at the bottom left. This shows the number of CPU cycles spent in each function over the whole runtime of your program, and this is where we will get most of the information the we care about from. It works like a stack-trace and allows us to 'dig in' to specific functions in our program
- A stack-trace view on the right, which gives a more condensed overview of the 'heaviest' functions, which is to say the functions that your program spent most of the time in
Let's start exploring the data we have available! Unsurprisingly, most of the CPU cycles of our program are spent in main, which doesn't tell us much. But we can start to drill down, until we end up in a function that calls multiple functions with significant numbers of CPU cycles spent. At this point, it is important to understand how to read these numbers. Instruments gives us two columns called 'Weight' and 'Self Weight'. 'Weight' is the total number of CPU cycles spent in this function and all functions called by this function, whereas 'Self Weight' refers only to the number of CPU cycles spent within this function alone. Let's look at a simple example:
Suppose we have two functions a() and b(), where a() calls b(). a() has a Weight of 100, b() a Weight of 80. Since 80 cycles of the full 100 cycles spent in a() come from the call to b(), we know that the remaining 20 must come from stuff that a() does that does not blong to any function call. So the Self Weight of a() would be 20.
So we can start to drill down until we find a function that either has a significant Self Weight, or calls multiple functions where at least one of them has a significant Weight. In our case, we will end up with a function called try_fold, which took about 600 million CPU cycles. This function calls two functions that both take about 300 million CPU cycles: BufRead::read_line and enumerate. Both functions take a little less than 50% of the CPU cycles of try_fold, so we know that try_fold itself is not interesting, but instead the two functions it calls are! BufRead::read_line makes sense, this is the function that is called to get the next line in the text-file that crap is searching in. So already we have gained a valuable piece of information: About half of the 622 million CPU cycles of our program are spent in reading a file line-by-line. This is also what the percentage number in the 'Weight' column tells us: 47.0% of the CPU cycles of the program are spent in the BufRead::read_line function. Another 46.9% are spent in this enumerate function.
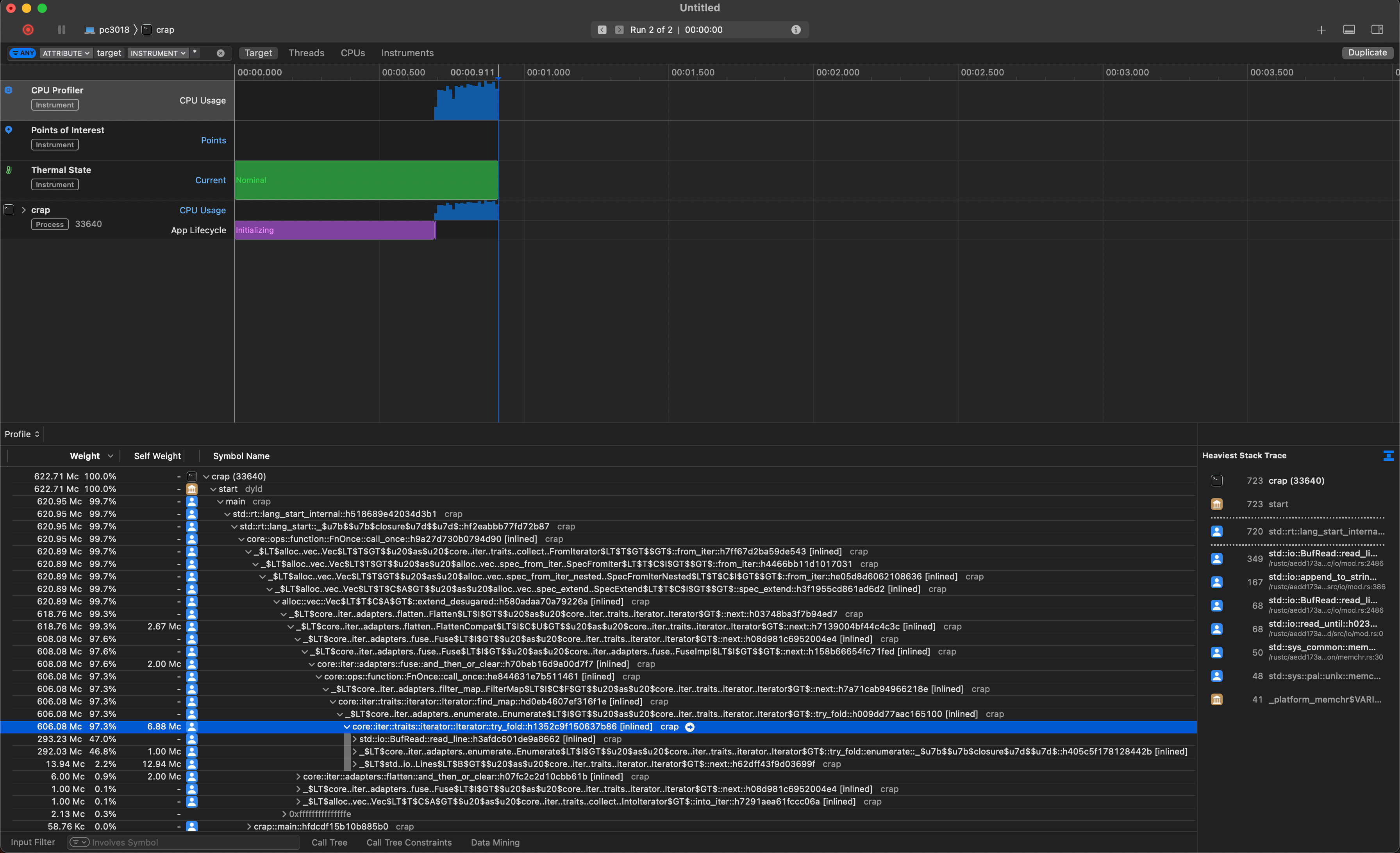
We now have a choice: Both BufRead::read_line and enumerate are responsible for about half of the program execution time each. Let's drill deeper into enumerate to understand this function. We might end up with a call tree like this:
Here we find two functions that are interesting: alloc::alloc::dealloc and the hard to read _$LT$alloc..vec..Vec$LT$T$GT$$u20$as$u20$core..iter..traits..collect..FromIterator$LT$T$GT$$GT$::from_iter, which we might parse as a call to collect::<Vec<_>>. The first function is interesting, as it again takes about half of the time of its parent function. 50% of enumerate goes to the deallocation of some memory? Understanding what exactly gets deallocated can be tricky, because we never see any stack traces pointing into our own code. Notice all the [inlined] labels at the end of each entry in the call tree? The compiler performed quite a lot of inlining, which improves performance but makes it harder to track the source of our function calls, since they are not actually function calls anymore. It helps to look at our code and trying to understand which variables contain dynamic memory allocations. A deallocation will typically happen when one of these variables goes out of scope. All the relevant code happens inside the function we pass to filter_map:
filter_map(|(line_number: usize, line: Result<String, std::io::Error>)| -> Option<Vec<Match>> { let line: String = line.ok()?; let matches: Vec<Match> = regex .find_iter(line.as_str()) .map(|m| { // Extract information about match Match { ... } }) .collect(); Some(matches) })
Adding some type annotations makes it clearer to see what goes on here. Within the closure, we have three types that manage dynamic memory allocations:
lineis aStringmatchesis aVec- Each entry in
matchesis aMatchobject, which has a fieldcontext: String
Since we return the Vec<Match> from this function, neither the vector nor the Match objects will be cleaned up at the end of the function. Which leaves only the line variable, which indeed goes out of scope, causing the String to be deallocated. So a quarter of the runtime of our program is spent for deallocating strings. Quite surprising, isn't it?
Reasoning based on profiler results
Now it is time to take a step back and process the information that we obtained by profiling our crap executable with Instruments. We saw that we could drill down quite easily through the call stack in our code and figure out which function takes how many CPU cycles. We ended up at the realization that a lot of time seems to be spent on deallocating String instances. From here, we are on our own, the work of the profiler is done (for now) and we have to understand how these numbers relate to our program.
During the development of crap, it is unlikely that we ever thought 'And with this piece of code, I want to deallocate a lot of Strings!' As it is more often the case, especially when using a programming language that has lots of abstractions, this is a byproduct of how we designed our code. Let's look at a (simplified) version of the search_file function again:
let file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; Ok(file .lines() .enumerate() .filter_map(|(line_number, line : Result<String, std::io::Error>)| -> Option<Vec<Match>> { let line = line.ok()?; let matches = regex .find_iter(line.as_str()) .map(|m| { // Omitted code that gets the context of the match, i.e. some characters around the matching word... Match { context: format!( "{}{}{}", ellipse_before, &line[context_start..context_end], ellipse_after ), line_number, position_in_line: m.start(), } }) .collect(); Some(matches) }) .flatten() .collect())
There are two locations where we are dealing with instances of the String type: The lines() function returns an iterator over Result<String, std::io::Error>, and we explicitly create a String for each match using format!, within the inner map() call. We already had a good reason to suspect that it is the line variable that gets cleaned up, and not the context field of the Match object that we create. To increase our certainty, we can do a bit of reasoning based on our data:
We know that the function passed to filter_map will be called one time for each line in the file, because we chain it to the file.lines() iterator. Within this function, we create one Match instance (with one context String) for each match of the pattern that we are searching for. What is the ratio of matches to lines? Two shell commands can help us here:
crap enwik8 Wikipedia | wc -l
cat enwik8 | wc -l
The first command counts the number of lines that crap outputs. Since crap prints each match in a separate line, this gives us the number of matches. The second command counts the number of lines in the enwik8 file. Here are the results:
crap enwik8 Wikipedia | wc -l
|> 2290
cat enwik8 | wc -l
|> 1128023
1.13 million lines versus 2290 matches. So unless each String in a match would be about 1000 times more expensive to deallocate than a String containing a line of the file, this is very strong evidence that the line strings are the culprit!
What we do with this information is up to us. We might start to think about whether we actually need each line as a full owning String, or if we couldn't use &str somewhere to reduce the overhead of allocating and deallocating all these String instances. From there we might figure out that a typical line in a text file is often not very long, a few hundred characters at the most, but in our example we have a very large number of lines, meaning lots of Strings get created and destroyed. So that might be an area for optimization. Most importantly, however, is the fact that using a profiler gave us the necessary information to figure out that we spend a lot of time in our program with the (de)allocation of String values. That is the power of a profiler: It gathers a lot of information and gives us the right tools to dig deep into our code, until we find the pieces of code that take the most CPU cycles or the longest time.
One closing remark regarding our investigation: We never checked the BufRead::read_line function, but we can now strongly suspect that there will be a lot of time spent on allocations as well, maybe even as much time as is spent on deallocating the line strings. Indeed this is what we will find:
An example optimization for crap
We will look at one potential optimization for crap based on the data we gathered, so you will get a feel for how profiler-guided optimization works.
Based on the data, our main goal is to get rid of the large number of allocations. Instead of allocating a new String for each line, we can pre-allocate one String that acts as a line buffer and read each line into this buffer. This means replacing the call to file.lines() with an explicit loop and manual calls to file.read_line:
fn search_file_optimized(path: &Path, pattern: &str) -> Result<Vec<Match>> { let mut file = BufReader::new(File::open(path)?); let regex = Regex::new(pattern)?; let mut line = String::with_capacity(1024); let mut matches = vec![]; let mut line_number = 0; while let Ok(count) = file.read_line(&mut line) { if count == 0 { break; } line_number += 1; // Get matches in line for match_within_line in regex.find_iter(line.as_str()) { // Extract data for match. Code is identical to before matches.push(Match { ... }); } // Clear line for next iteration line.clear(); } Ok(matches) }
We pre-allocate some memory for our line buffer. How much memory is up to us, if we allocate too little the read_line function will grow our string as needed. We go with 1KiB here, but you can experiment with this value and see if it makes a difference. Then we read the file line by line through file.read_line(&mut line), at which point the data for the current line is stored in line. Match extraction works like before, nothing fancy going on there. At the end of our loop body, we have to make sure that we clear the contents of the line buffer, otherwise the next line would be appended to the end of the buffer.
To make sure that this is a good optimization, we have to measure again! First, let's measure the runtime:
time crap enwik8 Wikipedia
|> 0.10s user 0.03s system 74% cpu 0.170 total
From 316ms down to 170ms, even lower than ripgrep! Of course we have to measure multiple times to get statistically relevant results. But we can also profile again and see where most of the runtime is spent now!
Here is a list of things that you might notice based on the new data, which can serve as a starting point for further optimizations:
- About 63% of the runtime is spent in
BufReader::read_line, which is a larger relative proportion than before, but lower absolute cycles (174M now vs. 293M before)- Almost all time is spent in
append_to_string, so appending the line data to our line buffer string- About 50% of that time is spent validating that the string is valid UTF-8 (
core::str::from_utf8) - 40% of that time is spent reading the actual data until the end of the line. Finding the end of the line is done using the
memchrcrate and takes about 25% of the total time ofappend_to_string
- About 50% of that time is spent validating that the string is valid UTF-8 (
- Almost all time is spent in
- The remaining runtime is spent in the
regexcrate, which finds the actual matches
hyperfine - A better alternative to time
We will conclude this section on benchmarking and profiling by introducing one last tool: hyperfine. hyperfine provides statistical benchmarking for command line applications and is thus similar to criterion which provided statistical benchmarking of Rust functions. The reasons for using a statistical benchmarking tool on the command line are the same as for benchmarking individual functions: It catches fluctuations in systems performance and provides a more reliable way of analyzing performance.
Of the many features that hyperfine provides, we will look at three: The default mode, warmup runs, and preparation commands.
The default invocation of hyperfine to benchmark our (optimized) crap executable looks like this:
hyperfine 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 131.3 ms ± 8.3 ms [User: 92.1 ms, System: 25.9 ms]
|> Range (min … max): 99.1 ms … 134.9 ms 21 runs
|>
|> Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
hyperfine executes the given command multiple times and performs a statistical analysis on the program runtime. We see the mean runtime and its standard deviation (131.3 ms ± 8.3 ms), a breakdown between time spent in user space and kernel space ([User: 92.1 ms, System: 25.9 ms]), the minimum and maximum recorded runtime (99.1 ms … 134.9 ms), and how many runs hyperfine performed (21).
hyperfine also prints a warning message that it found statistical outliers. In this case this happened because the disk cache was cleared prior to the call to hyperfine. crap is a very I/O heavy tool and benefits a lot from data being cached in the disk cache. If it is not, the first run might be a lot slower than successive runs (for which data will now be in the cache). hyperfine suggests two remedies for this: Warmup runs, or prepare commands.
Warmup runs introduce a small number of program executions for 'warming up' caches. After these runs have been executed, the actual benchmarking runs start. If your program accesses the same data (which in the case of our crap invocation it does), this will guarantee that this data is probably in the cache and subsequent runs all operate on cached data. This should keep fluctuations in the runtime due to caching effects to a minimum.
Prepare commands on the other hand execute a specific command or set of commands prior to every run of the benchmarked program. This allows manual preparation of the necessary environment for the program. Where warmup runs are helpful to ensure warm caches, prepare commands can be used to manually clear caches before every program run.
Running with warmup runs is as simple as this:
hyperfine --warmup 3 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 126.8 ms ± 0.3 ms [User: 93.3 ms, System: 25.5 ms]
|> Range (min … max): 126.4 ms … 127.4 ms 20 runs
Compared to our initial invocation of hyperfine, warmup runs drastically reduced the runtime fluctuations from 8.3ms (~6%) down to 0.3ms (~0.2%).
If we want to benchmark how crap behaves on a cold cache, we can use a prepare command that empties the disk cache prior to every run. This depends on the OS that we run on, for Linux it is typically sync; echo 3 | sudo tee /proc/sys/vm/drop_caches, on macOS you will use sync && purge:
hyperfine -p 'sync && purge' 'crap enwik8 Wikipedia'
|> Benchmark 1: crap enwik8 Wikipedia
|> Time (mean ± σ): 505.7 ms ± 183.3 ms [User: 92.5 ms, System: 56.4 ms]
|> Range (min … max): 328.4 ms … 968.7 ms 10 runs
Here we notice much higher runtimes and runtime fluctuations, which are to be expected when interacting with I/O devices like the disk.
This leaves us with an interesting question: Should we benchmark with a cold cache or hot cache? Which scenario more closely represents the actual runtime characteristics of our program? The answer to this question depends on the way the program is typically used. For a pattern searcher such as crap, it is reasonable to assume that the same files will be searched repeatedly, in which case the hot cache performance would more closely resemble the actual user experience. Other tools might operate on rarely used files, in which case cold cache performance will be more relevant.
Summary
In this section we learned about ways for measuring performance through benchmarking and profiling. The former is good for isolated functions and small pieces of code, is easy to set up, but does not give very detailed information. If we want to understand how larger programs function and want to understand which parts of the program affect performance in which way, profilers are the way to go.