Threads and synchronization
In the previous chapters, we learned a lot about memory as one of the major hardware resources. The other main hardware resource is of course the CPU itself, or more specifically the CPU cycles. We never really had to think about how to access CPU cycles because modern operating systems handle this for us. For many years however, processors have become faster not by increasing their clock rates, but instead by improving in their ability to execute multiple instructions in parallel. In this chapter, we will look at one way of accessing multiple CPU cores explicitly in our programs by using the operating system concept of a thread.
To understand threads, we will first look at how a modern CPU can execute instructions in parallel, and then move on to the role of the operating system, which provides the thread abstraction. Equipped with this knowledge, we will look at how to use threads in the Rust programming language, and which additional concepts are required to correctly use threads.
How your CPU runs instructions in parallel
As we saw in the chapter on memory management, there are physical limits to how fast we can compute things with electronic circuits (or any kind of circuit, really). To circumvent this problem for memory, we saw that cache hierarchies are used. How do we deal with the physical limitations when it comes to doing actual computations? Clearly, we can't just execute our instructions arbitrarily fast. So instead of running single instructions faster and faster, we try to run multiple instructions at the same time. This is called parallelism. Recall from chapter 2.2 that parallelism is a stronger form of concurrency. Where we did multiple things during the same time period with concurrency, parallelism implies that multiple things are happening at the same instant in time.
Modern processors have multiple ways of achieving parallelism. The most widely known concept is that of a multi-core processor, which is effectively one large processor made up of many smaller processors that can execute instructions (mostly) independent from each other. But even at the level of a single processor there are mechanisms in place to execute instructions in parallel. The major concepts here are called instruction-level parallelism, hyperthreading, and single instruction, multiple data (SIMD).
Instruction-level parallelism refers to the ability of a single processor core to execute multiple instructions at the same time. This is possible because executing a single instruction requires your processor to perform multiple steps, such as fetching the next instruction, decoding its binary representation, performing a computation, or loading data from memory. By running all these steps in a pipeline, multiple instructions can be in flight at the same time, as the following image shows:
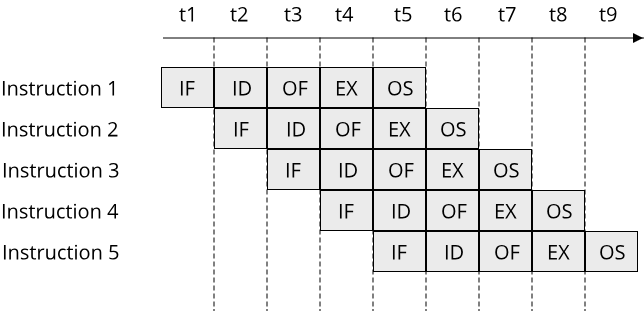
While using such a pipeline does not mean that a single instruction executes faster (it does not increase the latency of an instruction), it means that more instructions can be processed in the same time (increasing the throughput).
Hyperthreading moves beyond the pipelining concept and instead duplicates some parts of the circuits on a processor core. Not every instruction requires all parts of the processor all the time. An instruction might have to wait for a memory access, during which time it doesn't require the circuits which perform the actual computations (the arithmetic logical unit (ALU)). By duplicating certain parts of the processor circuits, in particular the registers and program counter, multiple sequences of instructions and be executed in parallel. If one sequence encounters an instruction that has to wait on memory, the other sequence might be able to continue with an instruction that needs the ALU.
The last concept is single instruction, multiple data (SIMD), and refers to special hardware which can process larger amounts of data with a single instruction. Think of a regular add instruction. On x86-64, add can use the general-purpose registers two add two values of up to 64 bits length to each other. SIMD introduces larger registers, such as the XMM registers, which can store 128 bits and thus up to four 32-bit floating point values at once. The special part about SIMD instructions is that a single instruction operates on all values in an XMM register at the same time. So with a single SIMD instruction, it is possible to add four 32-bit floating point values together at once. Used correctly, these instructions make it possible to process multiple pieces of data simultaneously, thus achieving parallelism.
What are threads and why are they useful?
We saw that there are many ways in which a CPU can run instructions in parallel. What does this mean for us as programmers? How can we access the latent potential for parallelism in our CPUs?
Instruction-level paralleism and hyperthreading are things that the CPU does automatically, we as developers have no control over these features. SIMD can be used by writing code that explicitly uses the SIMD registers and instructions. We can either do this ourselves by using the appropriate assembly instructions, or hope that our compiler will generate SIMD code. This leaves multiple CPU cores as the last area. How do we explicitly run our code on multiple cores at the same time?
When using a modern operating system, the operating system helps us here. When we run our code, we do so by asking the operating system to create a new process and execute the code from a given binary within the context of this process. So this code has to get onto the CPU somehow. Luckily for us, the operating system manages this by using the process scheduler, which is a piece of code that maps processes onto CPU cores. The details of this are usually covered in an introductory operating systems course, so here is the brief version:
A typical operating system scheduler runs each CPU core for a short amount of time, a few milliseconds for example, then interrupts the CPU core, effectively halting its current computation. At this point, a single process has been executing on this CPU core. What about all the other processes on this machine? It is not unusual for a modern computer to run hundreds of processes at the same time. If there are only 4 CPU cores available, clearly we can't run all processes on these CPU cores, because each CPU core can process one, maybe two (with hyperthreading) sequences of instructions at once. So all other processes are sitting idly on this machine, which their state (the content of the registers) being stored somewhere in memory. During the interruption of a CPU core, the scheduler now takes another process which hasn't run in some time and moves this process onto the CPU core. To not disturb the process that was running on the core before, the data of the old process is cached in memory, and the data for the new process is restored from memory. This process repeats very frequently, thus giving your computer the ability to run many more programs than there are CPU cores.
So there we have it: Our program is put onto an arbitrary CPU core automatically by the schedulerThis is only true for general-purpose operating systems such as Linux or Windows. There are also real-time operating systems where scheduling can be controlled more closely by the developer.. But only a single core at a time. What if we want our program to run on multiple cores at the same time? How would that even look like from our code?
To understand how to run a single program on multiple cores, we have to understand the concept of a thread of execution.
Bryant and O'Hallaron define a thread as a 'logical flow that runs in the context of a process' {{#cite Bryant03}}. In other terms, threads are sequences of instructions that can operate independently from each other. In a typical imperative program, we have exactly one sequence of instructions that gets executed, as the following image shows:
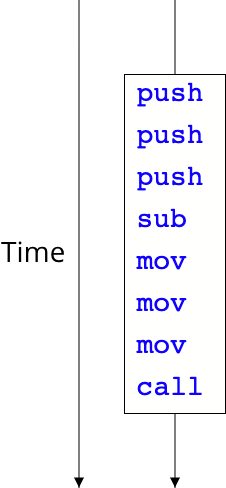
This sequence of instructions is defined by the program counter, the CPU register that always points to the next instruction that is to be executed. Just as we can have multiple processes that each have their own program counter, we can have multiple threads with their own program counter running within the same process. Where two processes have their own separate address spaces, two threads within a process share the same address space. Threads thus can be seen as a more light-weight alternative to processes.
Each thread has a unique thread context, which is simply all the information unique to each thread, such as the program counter, other CPU register values, a unique address range for the stack, the stack pointer, as well as a unique thread ID. Compared to a process, a thread is much more lightweight. Since all threads within a process share the same address space, it is also easier to share data between threads as it is to share data between processes.
How the operating system manages threads
Threads are a concept for concurrency realized on the level of the operating system, and they are thus managed by the operating system. A thread behaves similar to any other resource in that it can be acquired from the operating system and has to be released back to the operating system once it is no longer needed. For threads, creating a new thread is often called spawning a new thread, and releasing a thread back to the operating systems is done by joining with the thread.
The necessary resources attached to a thread, such as its stack space, are created on demand by the operating system when a new thread is created, and are released again when the thread is joined with. Similar to heap memory or file handles, if we forget to join with a thread, the operating system will clean up all remaining threads once its parent process terminates. This can have suprising effects, as these threads might still do some useful work, so we better make sure that we join with these threads.
In all of the major operating systems, each process starts out with exactly one active thread at startup, called the main thread.
On Linux, we can use the POSIX API for managing threads, which contains functions such as pthread_create and pthread_join that we can use for creating a thread and joining with another thread. The signature of pthread_create is interesting:
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
Besides a pointer to the resource handle for the thread (pthread_t* thread), pthread_create expects a function pointer (void*(*start_routine)(void*)). This pointer refers to the function that will be the entry point of the newly created thread. For this thread, execution will start with the function pointed to by start_routine, just as how the entry point for a process in a C program is the main function. Since threads in a process share an address space, it is also possible to pass data directly into the newly created thread, using the void* arg argument.
Working with these C functions can become cumbersome quickly for the same reasons that we saw when working with memory and files. For that reason, systems programming languages such as C++ or Rust provide abstractions for threads in their standard libraries that provide a safer interface and abstract over operating system details. In C++, threads are handled by the std::thread type, in Rust we use the std::thread module.
Threads in Rust
Here is an overview of the std::thread module in Rust:
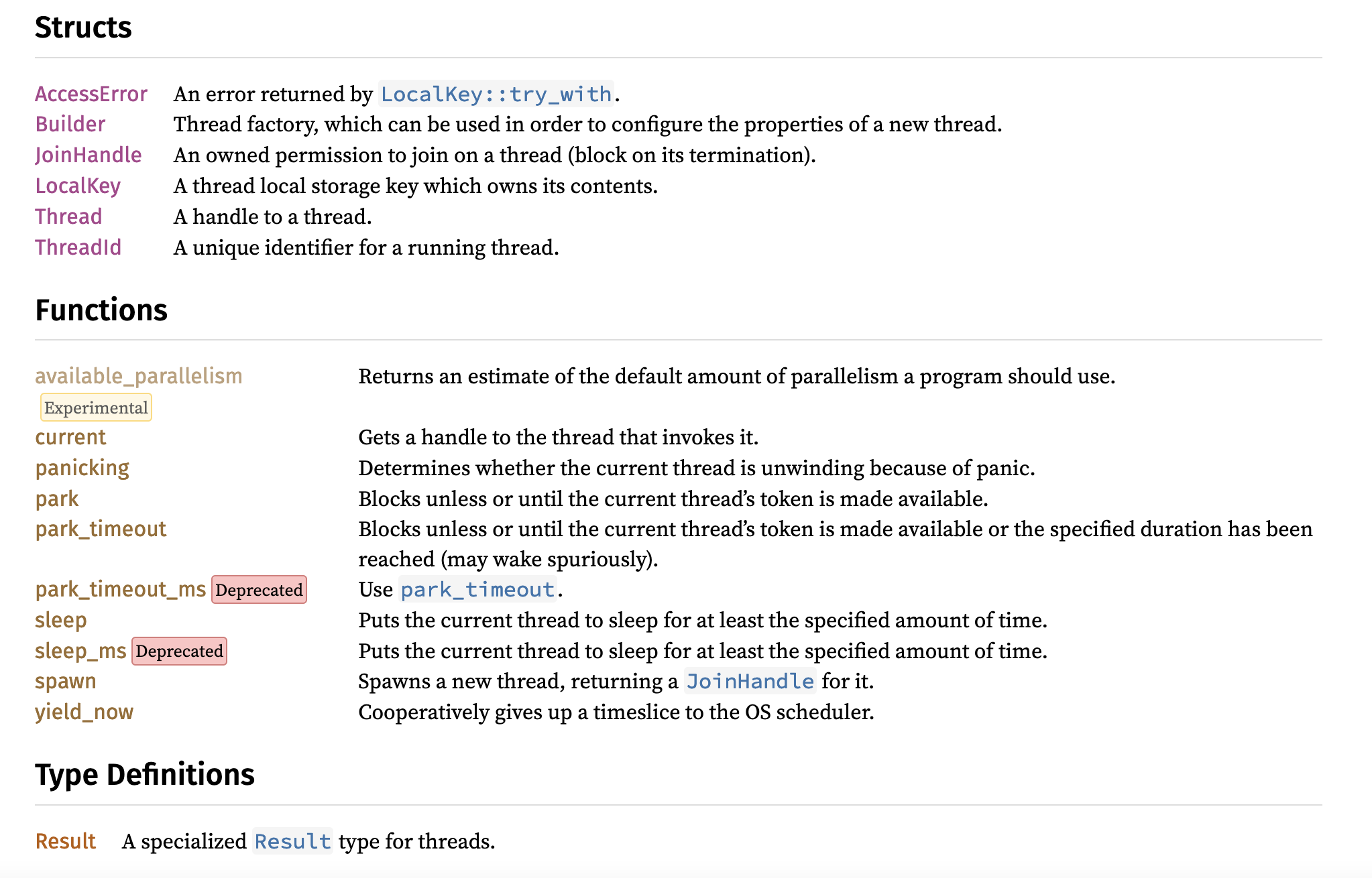
Spawning a new thread is a simple as calling std::thread::spawn in Rust:
pub fn main() { let join_handle = std::thread::spawn(|| { println!("Hello from new thread"); }); println!("Hello from main thread"); join_handle.join().unwrap(); }
Just as the low-level POSIX API, the Rust API for creating threads expects that we pass a function to spawn. This function is then executed on the newly created thread. To make sure that we actually clean up this new thread, spawn returns a handle to the thread that we can use to join with the thread. We do so by calling the join() function on this handle. join() waits for the new thread to finish its execution, which it does by waiting until the new thread exits the function that we provided to it, either successfully or with an error (e.g. by calling panic!). Because of this, join() returns a Result.
Let's try to do something more elaborate and do some computation on the newly created thread. In Rust, we can return a value from a thread and get access to this value as the return value of join() in the Ok case:
fn is_prime(n: &usize) -> bool { let upper_bound = (*n as f64).sqrt() as usize; !(2_usize..=upper_bound).any(|div| *n % div == 0) } fn nth_prime(n: usize) -> usize { (2_usize..).filter(is_prime).nth(n).unwrap() } pub fn main() { let prime_index = 1000; let join_handle = std::thread::spawn(|| { nth_prime(prime_index) }); let prime = join_handle.join().unwrap(); println!("The {}th prime number is: {}", prime_index, prime); }
Unfortunately, this example doesn't compile. Let's see what the compiler has to say:
error[E0373]: closure may outlive the current function, but it borrows `prime_index`, which is owned by the current function
--> <source>:12:42
|
12 | let join_handle = std::thread::spawn(|| {
| ^^ may outlive borrowed value `prime_index`
13 | nth_prime(prime_index)
| ----------- `prime_index` is borrowed here
|
note: function requires argument type to outlive `'static`
--> <source>:12:23
|
12 | let join_handle = std::thread::spawn(|| {
| _______________________^
13 | | nth_prime(prime_index)
14 | | });
| |______^
help: to force the closure to take ownership of `prime_index` (and any other referenced variables), use the `move` keyword
|
12 | let join_handle = std::thread::spawn(move || {
| ++++
The problem is that the function we pass to spawn might live longer than the current function (main). This makes sense, since a thread is an independent strand of execution, that might execute longer than main. In fact, we see this in the signature of spawn:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
The function f has to have 'static lifetime, and we know that a variable declared inside main does not have 'static lifetime.
Looking back at our error, the problem is not that the function might live longer than main, but that this function borrows a variable that we declared inside main (the variable prime_index). The Rust compiler gives us the solution: Instead of borrowing the value, we have to take ownership of the value. We do this by prefixing our anonymous function with the move keyword. This way, all data that was borrowed previously now gets moved into the body of the function. Since our prime_index is Copy, this is no problem. Fixing this little error makes our program run successfully:
pub fn main() { let prime_index = 1000; let join_handle = std::thread::spawn(move || { nth_prime(prime_index) }); let prime = join_handle.join().unwrap(); println!("The {}th prime number is: {}", prime_index, prime); }
Writing code with threads
With threads, we can write code that potentially executes in parallel, meaning that multiple instructions are executed at the same point in time. This of course requires that our CPU has more than a single logical core, but most modern CPUs have multiple cores. So how do we make good use of this power?
The study of concurrent and parallel code is a huge field that we can't possibly hope to cover as part of this course. We will cover some basics here and in the process illustrate some of the measures that Rust takes to make concurrent code safe to execute. At its core, working with threads (or any other concurrency concept) is typically about identifying parts of an algorithm that can be executed concurrently without changing the outcome of the algorithm. While not a strict requirement, we typically want the concurrent algorithm to run faster than the sequential algorithm. 'Running faster' is a losely defined term here, there are some more precise definitions that we won't cover because they are not necessary to our understanding of concurrent code.
Broadly speaking, we can use threads for two scenarios: Doing more things at once, or doing the same thing faster.
An example of doing more things at once is a server that wants to deal with multiple connections at the same time. We can put each connection onto a separate thread and thus handle multiple connections concurrently.
An example for making something faster through using threads would be a concurrent search algorithm. Instead of looking through a large collection sequentially, we can split the collection up into disjoint subsets and search each subset on a separate thread. In an ideal world, if we use N threads running in parallel, our algorithm will run N times faster because each thread only has one Nth of the work to do, but all threads perform their work at the same time, so the total runtime is 1 / N.
We will mainly cover the second type of concurrent code in the remainder of this chapter, by working through an example of a concurrent search algorithm.
A text search algorithm
To see how we can use threads to speed up a program, we will implement a simple text search application. The idea is to take a String and some keyword and count the number of non-overlapping occurrences of they keyword within the String. Here is how this might look like using the regex crate:
#![allow(unused)] fn main() { fn search_sequential(text: &str, keyword: &str) -> usize { let regex = Regex::new(keyword).expect("Can't build regex"); regex.find_iter(text).count() } }
Since neither the text nor the keyword need to be mutated, we use string slices for both arguments. The find_iter function of the Regex type then gives us an iterator over all non-overlapping occurrences of our keyword within text.
How would we go about implementing this algorithm using threads? One way is to use the fork-join pattern {{#cite mattson2004patterns}}. The idea of fork-join is to split up the data into several smaller units that can be processed independently ('fork'), and then combine the results of these parallel computations into the final result ('join'):
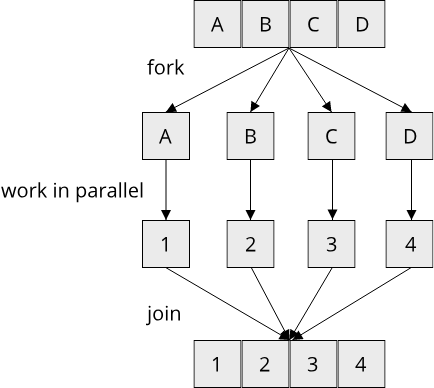
Applying the fork-join pattern to our text search application, we see that we first have to split our text into smaller chunks that we can process independently. To make our algorithm easier, we will restrict the keyword that we are looking for to be a single word that must not include any whitespace. Then, the order in which we search through our text becomes irrelevant. We could start at the beginning and move towards the end, or start at the end and move towards the beginning, or look at all words in random order. In all cases, the number of matches will stay the same. This is good news for our effort to parallelize the text search algorithm, as it means that we can process parts of the text in parallel without changing the outcome.
So let's split up our text into smaller chunks so that we can process each chunk on a separate thread. To make sure that all threads process an equal amount of data, we want to split our text into equally-sized chunks. We can't split in the middle of a word however, as this would change the outcome of the algorithm, so we have to split at a whitespace character.
We will simply assume that we have a magical function fn chunk_string_at_whitespace(text: &str, num_chunks: usize) -> Vec<&str> that splits a single string into num_chunks disjoint substrings at whitespace boundaries. If you want, you can try to implement this function yourself. With this function, we can then start to use threads to implement a parallel word search algorithm. The idea is to split the string first and run our sequential word search algorithm on each substring (the fork phase), then combine the results of each sequential word search into a single number using addition (the join phase):
#![allow(unused)] fn main() { fn search_parallel_fork_join(text: &str, keyword: &str, parallelism: usize) -> usize { let chunks = chunk_string_at_whitespace(text, parallelism); let join_handles = chunks .into_iter() .map(|chunk| std::thread::spawn(move || search_sequential(chunk, keyword))) .collect::<Vec<_>>(); join_handles .into_iter() .map(|handle| handle.join().expect("Can't join with worker thread")) .sum() } }
There is a lot to unpack here. First, we create our chunks using the chunk_string_at_whitespace function. Then, we want to run search_sequential for each chunk, so we use chunks.into_iter().map(). Inside the map function, we spawn a new thread and call search_sequential on this thread. We then collect the join handles for all threads into a collection. We then join() with all threads, which returns the result of each search_sequential call. To get the final number of matches, we sum() the individual results.
The fork-join pattern becomes clearly visible in this code: First we fork by mapping over our split data and creating a thread for each chunk, then we join by joining with the join handles of the threads and combining the results (in this case using the sum algorithm).
This would be great and fairly simple, except that there is a slight problem. Let's try to compile this code:
error[E0759]: `text` has an anonymous lifetime `'_` but it needs to satisfy a `'static` lifetime requirement
--> src/bin/chap7_textsearch.rs:72:18
|
71 | fn search_parallel_fork_join(text: &str, keyword: &str, parallelism: usize) -> usize {
| ---- this data with an anonymous lifetime `'_`...
72 | let chunks = chunk_string_at_whitespace(text, parallelism);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^----^^^^^^^^^^^^^^
| |
| ...is captured here...
...
76 | .map(|chunk| std::thread::spawn(move || search_sequential(chunk, keyword)))
| ------------------ ...and is required to live as long as `'static` here
Remember that std::thread::spawn required a function with 'static lifetime? Neither our text nor our keyword has 'static lifetime, so the compiler doesn't accept this code. This is a bit unfortunate, because we know that the threads only live as long as the search_parallel_fork_join function, because we are joining with them at the end of the function! But the Rust standard library doesn't know this and also has no way of figuring this out, so it makes the safest assumption, which is that everything that gets moved onto the thread has 'static lifetime.
The easiest (but not necessarily most efficient) way to fix this is to use String instead of &str and give each thread a unique copy of the data:
#![allow(unused)] fn main() { let chunks = chunk_string_at_whitespace(text, parallelism) .into_iter() .map(|str| str.to_owned()) .collect::<Vec<_>>(); let join_handles = chunks .into_iter() .map(|chunk| { let keyword = keyword.to_owned(); std::thread::spawn(move || search_sequential(chunk.as_str(), keyword.as_str())) }) .collect::<Vec<_>>(); }
So instead of splitting our text into a Vec<&str>, we now split into Vec<String>, which assures that we can move an owned chunk into each thread. For the keyword, we create a local owned copy by calling keyword.to_owned() prior to spawning the thread and move this copy into the thread as well.
Now lets reap the fruits of our labor and run our parallel text search algorithm. First, let's check for correctness. The following example searches for a specific genome sequence in the GRCh38 Reference Genome Sequence, which is about 3.3 GB large, so a good candidate for a fast text search algorithm.
fn get_large_text() -> Result<String> { let genome = std::fs::read_to_string("GRCh38_latest_genomic.fna")?; Ok(genome.to_uppercase()) } fn main() -> Result<()> { let text = get_large_text().context("Can't load text")?; let keyword = "TTAGGG"; //The telomere repeat sequence println!( "Matches (sequential): {}", search_sequential(text.as_str(), keyword) ); println!( "Matches (parallel): {}", search_parallel_fork_join(text.as_str(), keyword, 12) //12 is the number of cores on the test machine ); Ok(()) }
Running this code yields the following output:
Matches (sequential): 541684
Matches (parallel): 541684
Great, our code is correct! Now let's see if we actually got a performance improvement from running on multiple threads. We can do some simple performance measurements by using the std::time::Instant type, which can be used to measure elapsed time. We can write a little helper function that measures the execution time of another function:
#![allow(unused)] fn main() { fn time<F: FnOnce() -> ()>(f: F) -> Duration { let t_start = Instant::now(); f(); t_start.elapsed() } }
With this, let's check the runtime of our two algorithms:
fn main() -> Result<()> { let text = get_large_text().context("Can't load text")?; let keyword = "TTAGGG"; //The telomere repeat sequence println!( "Time (sequential): {:#?}", time(|| { search_sequential(text.as_str(), keyword); }) ); println!( "Time (parallel): {:#?}", time(|| { search_parallel_fork_join(text.as_str(), keyword, 12); }) ); Ok(()) }
Which gives the following output:
Time (sequential): 1.359097456s
Time (parallel): 1.942474468s
Well that's disappointing. Our parallel algorithm is a lot slower than our sequential algorithm. What is happening here? If we investigate closer, we will find that the majority of time is spent on splitting our text into chunks and converting those chunks to owned strings. Splitting the text at whitespace itself is super fast and takes less than a millisecond, but converting the Vec<&str> into a Vec<String> takes a whooping 1.7s. Here we see a good example of why copying data can have a large performance impact!
The good news is that there are ways to prevent copying the data, however we will have to postpone the study of these ways to a later chapter. First, we will look at a slightly different way of tackling the text search algorithm with multiple threads.
Mutating data from multiple threads
With the fork-join model, we worked exclusively with immutable data: All data that the threads worked on was immutable, and the thread results were immutable as well. The code for this was fairly clean, however it came at the cost of increased copying. Let's specifically look at the output data of our parallelized text search algorithm:
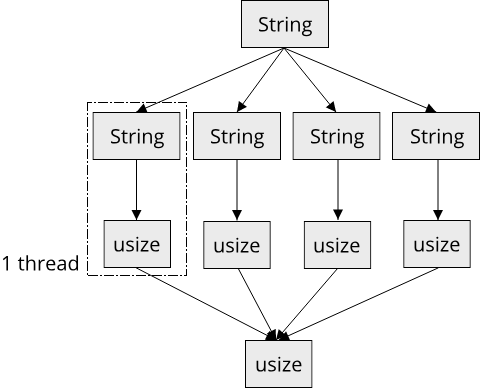
For our algorithm, the data that each thread generates is fairly small, a single usize value. Since we don't have a lot of threads, this is fine, compared to the sequential solution we do generate N times more output data, where N is the number of threads, but the difference is miniscule because each output value only takes 8 bytes on a 64-bit machine. But suppose we didn't want to only find all occurrences of a keyword in a string, but instead overwrite them with another string. Now the output of our algorithm becomes a mutated version of the input:
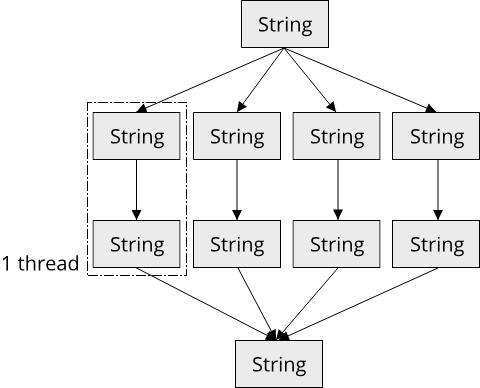
If our input data is a gigabyte large, duplicating it N times suddenly doesn't seem like such a good idea anymore. It would be better if each thread could simply mutate the original data. Unfortunately, overwriting strings in-place in Rust is almost impossible due to the fact that Rust strings are using Unicode as their encoding. So to make our lives easier, instead of overwriting strings, let's overwrite values in a Vec instead. The DNA example is neat, overwriting DNA sequences has a sort-of Frankenstein vibe, so we will use a Vec<Nucleobase>, where Nucleobase is a simple enum defining the four different nucleobases existing within the DNA:
#![allow(unused)] fn main() { #[derive(Copy, Clone, Debug, PartialEq, Eq)] enum Nucleobase { A, G, C, T, } }
We also implement TryFrom<char> for Nucleobase so that we can convert our human genome text into a Vec<Nucleobase>. Now let's try to write our magic DNA editing function:
#![allow(unused)] fn main() { fn dna_editing_sequential( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], ) { // ... omitted some checks for correctness of sequence lengths let sequence_len = old_sequence.len(); let mut start: usize = 0; let end = source.len() - sequence_len; while start < end { let is_match = { let cur_sequence = &source[start..start + sequence_len]; cur_sequence == old_sequence }; if is_match { source[start..start + sequence_len].copy_from_slice(new_sequence); start += sequence_len; } else { start += 1; } } } }
We can't use our Regex type anymore unfortunately, so we have to implement the sequence search manually. We go over the whole string and whenever we find a matching sequence, we use the copy_from_slice method to overwrite the old sequence with the new sequence within the source slice. Note how we don't have to pass a &mut Vec<Nucleobase> and instead can pass a mutable slice!
We now want to parallelize this algorithm using threads, just as we did with the text search before. But instead of using the fork-join pattern, we want to mutate the source value in-place. To make this work, we want to give each thread a unique subset of the source slice to work on. We can use a powerful method called chunks_mut which splits a single mutable slice into multiple disjoint chunks. That is exactly what we want, how nice of the Rust standard library to support something like this! Let's try it out:
#![allow(unused)] fn main() { fn dna_editing_parallel( source: &mut [Nucleobase], old_sequence: &[Nucleobase], new_sequence: &[Nucleobase], parallelism: usize, ) { if old_sequence.len() != new_sequence.len() { panic!("old_sequence and new_sequence must have the same length"); } let chunk_size = (source.len() + parallelism - 1) / parallelism; let chunks = source.chunks_mut(chunk_size).collect::<Vec<_>>(); let join_handles = chunks .into_iter() .map(|chunk| { std::thread::spawn(move || dna_editing_sequential(chunk, old_sequence, new_sequence)) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); } }
This almost works, but of course the compiler complains again because of wrong lifetimes. Our slices don't have 'static lifetime, so the thread function is not accepting them. Previously, we solved this by copying the data, but we saw that this can have quite the performance overhead. The problem is that every thread wants to own the data it works on. Do we know of a way to have multiple owners to the same data?
Turns out we do: Rc<T>! Maybe we can use reference counting to give each thread a clone of the Rc<T>? Let's try this:
#![allow(unused)] fn main() { fn dna_editing_parallel( source: Vec<Nucleobase>, old_sequence: Vec<Nucleobase>, new_sequence: Vec<Nucleobase>, parallelism: usize, ) { let source = Rc::new(RefCell::new(source)); let join_handles = (0..parallelism) .into_iter() .map(|chunk_index| { let source_clone = source.clone(); let old_sequence = old_sequence.clone(); let new_sequence = new_sequence.clone(); std::thread::spawn(move || { let mut source = source_clone.borrow_mut(); dna_editing_sequential( &mut *source, old_sequence.as_slice(), new_sequence.as_slice(), ) }) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); } }
For now, we ignore the splitting-up-into-chunks parts and only focus on getting each thread their own clone of the source data behind a Rc. We are also using RefCell so that we can get mutable access to the data within the Rc. If we compile this, we get an interesting error message:
error[E0277]: `Rc<RefCell<Vec<Nucleobase>>>` cannot be sent between threads safely
--> src/bin/chap7_textreplace.rs:108:13
|
108 | std::thread::spawn(move || {
| _____________^^^^^^^^^^^^^^^^^^_-
| | |
| | `Rc<RefCell<Vec<Nucleobase>>>` cannot be sent between threads safely
109 | | let mut source = source_clone.borrow_mut();
110 | | dna_editing_sequential(
111 | | &mut *source,
... |
114 | | )
115 | | })
| |_____________- within this `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`
|
= help: within `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`, the trait `Send` is not implemented for `Rc<RefCell<Vec<Nucleobase>>>`
= note: required because it appears within the type `[closure@src/bin/chap7_textreplace.rs:108:32: 115:14]`
We see a new requirement pop up, namely that our type Rc<RefCell<Vec<Nucleobase>>> does not implement a trait called Send, which is required in order for the type to be 'sent between threads safely'. Prepare for a deep dive into the world of Rust concurrency, this is where things are getting spicy!
Send and Sync - How Rust guarantees thread safety at compile-time
Remember that super-important rule in Rust that we can never have more than one mutable borrow to the same variable at the same time? How does this situation look like with threads?
If we have two threads running at the same time and they both access the same memory location, there are three possible scenarios, depending on whether each thread is reading from or writing to the memory location:

To understand these three scenarios, we have to understand what it means that the two threads are running at the same time. We don't generally know on which processor cores a thread is running, and since threads are scheduled by the operating system, we also can't be sure that threads are actually running in parallel or one after another. The way we tend to think about these scenarios is by assuming the worst case, namely that any possible order of operations is possible. If thread A is executing 5 instructions, and thread B is executing 5 different instructions, both instructions might be executed in parallel on different CPU cores, or thread A might get interrupted by thread B, meaning that only the first couple of instructions of thread A are executed, followed by some instructions of thread B and then the remaining instructions of thread A:
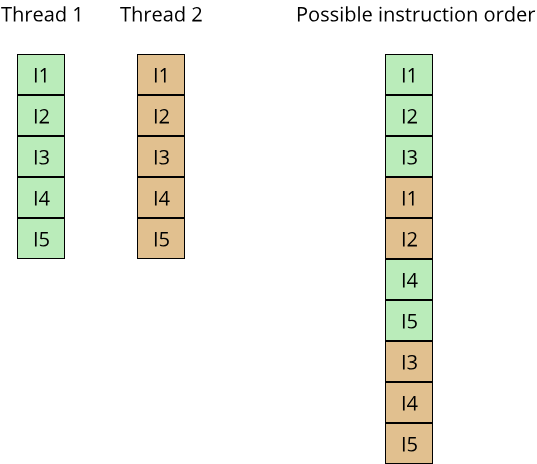
Armed with this knowledge, we can now make sense of the three scenarios for two concurrent threads accessing the same memory location. Scenario 1) (both threads are reading from the memory location) is simple to understand: Since no state is modified, the order of the read operations between the two threads does not change the outcome, as the following C++ code shows:
#include <thread>
#include <iostream>
#include <chrono>
int main() {
using namespace std::chrono_literals;
auto val = 42;
std::thread t1{[&val]() {
for(auto idx = 0; idx < 10; ++idx) {
std::this_thread::sleep_for(100ms);
std::cout << "Thread: " << val << std::endl;
}
}};
for(auto idx = 0; idx < 10; ++idx) {
std::this_thread::sleep_for(100ms);
std::cout << "Main: " << val << std::endl;
}
t1.join();
}
Scenario 2) (one thread reads, the other thread writes) is more interesting. We have again three different possibilities:
- a) Thread
Areads first, then threadBwrites - b) Thread
Bwrites first, then threadAreads - c) The read and write operations happen at the same instant in time
Clearly there is a difference in outcome between possibilities a) and b). In the case of a), thread A will read the old value of the memory location, whereas in the case of b), it will read the value that thread B has written. Since thread scheduling generally is not in our control in modern operating systems, it seems impossible to write a deterministic program with two threads accessing the same memory location. And what about option c)? How are simultaneous read and write requests to a single memory location resolved? This is heavily dependent on the processor architecture and CPU model, made even more complicated by the fact that modern CPUs have several levels of memory caches. Bryant and O'Hallaron go into more detail on how this cache coherency concept is realized {{#cite Bryant03}}, for us it is enough to know that simulatenous accesses to the same memory location from multiple threads become unpredictable as soon as one writer is involved.
The situation is similar when we have the two threads both write to the memory location (scenario 3): Either thread A overwrites the value of thread B or the other way around. Any such situation in code where two (or more) threads 'race' for the access of a shared memory location is called a race condition, and it is one category of nasty bugs that can happen in a multithreaded program.
Now the Rust borrow rules really make sense: By disallowing simultaneous mutable and immutable borrows, race conditions become impossible! But what does this all have to do with the Send trait?
As we saw from the error message, Send is a trait that signals to the Rust compiler that a type that implements Send is safe to be moved to another thread. At first, this might seem a pretty weird requirement. If we look at the primitive types in Rust (i32, usize etc.), we can't easily come up with a scenario where it might not be ok to move a value of one of these types onto another thread. Why is this even something that Rust cares about? You might have an intuition that it relates to preventing race conditions, but it is not trivial to see how moving a value from one thread to another could introduce a race condition.
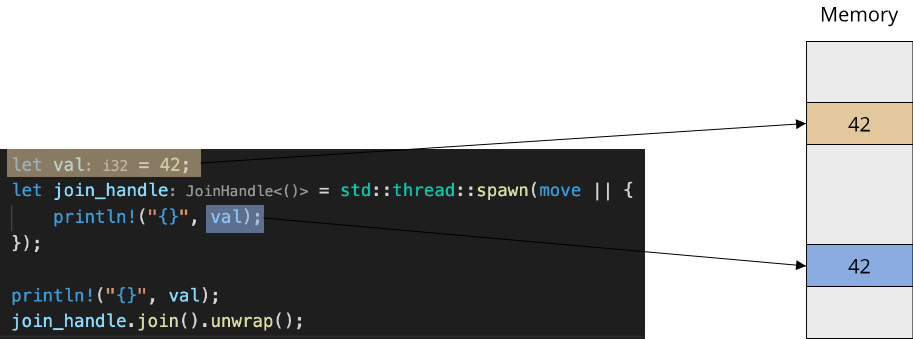
To understand Send, we have to think about ownership again. We saw that the Rust function std::thread::spawn accepts a move closure, which takes ownership of the captured values. For types that are Copy, this is fine, since the thread will receive a copy of the value, which lives in a different memory location:
For types that are not Copy, it gets more interesting. In general, a type is not Copy if it has some non-trivial internal state, possibly refering to some other memory location. Let's look at one such type, Vec<i32>. We know that a single Vec<i32> value contains an indirection in the form of a pointer to the dynamically allocated array on the heap. Vec<i32> is the owner of this region of heap memory, and by moveing it onto the thread, we move the ownership onto a different thread. This is ok, because Vec<i32> is a single-ownership type, meaning that no one else can have a reference to the underlying memory block:
fn main() { let vec = vec![1, 2, 3, 4]; std::thread::spawn(move || { println!("{:#?}", vec); }); println!("Main: {:#?}", vec); }
As expected, this example does not compile, because we can't use a value after it has been moved. And if we were to clone the Vec<i32>, the spawned thread would receive a completely disjoined region of memory. So Vec<i32> is Send because we can move it onto a different thread safely since it is a single-ownership type.
But we also know multiple-ownership types, for example Rc<T>! Remember back to chapter 3.4 where we looked at the implementation of Rc<T>. It's key component was a region of memory (the control block) that was shared between multiple Rc<T> values. We needed this to keep track of the number of active references to the actual value of type T, and the only way we found to implement this in Rust was by using unsafe code with raw pointers so that each Rc<T> instance could mutate the control block. So let's look at how Rust treats raw pointers when we try to move them between threads:
fn main() { let mut val = 42; let val_ptr = &mut val as *mut i32; std::thread::spawn(move || unsafe { *val_ptr = 43; }); println!("Main: {}", val); }
Since raw pointers have neither lifetime nor borrow rules associated with them, we can easily obtain a mutable pointer to a variable, which gives us more than one point of mutation for the variable (val and val_ptr). If we move the pointer onto a different thread, this thread now has mutable access to the memory location pointed to by val_ptr, and we could create a race condition! Interestingly enough, Rust disallows this, even though we are using unsafe code:
error[E0277]: `*mut i32` cannot be sent between threads safely
--> src/bin/send_sync.rs:7:5
|
7 | std::thread::spawn(move || unsafe {
| _____^^^^^^^^^^^^^^^^^^_-
| | |
| | `*mut i32` cannot be sent between threads safely
8 | | *val_ptr = 43;
9 | | });
| |_____- within this `[closure@src/bin/send_sync.rs:7:24: 9:6]`
|
= help: within `[closure@src/bin/send_sync.rs:7:24: 9:6]`, the trait `Send` is not implemented for `*mut i32`
= note: required because it appears within the type `[closure@src/bin/send_sync.rs:7:24: 9:6]`
note: required by a bound in `spawn`
--> /Users/pbormann/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/src/rust/library/std/src/thread/mod.rs:621:8
|
621 | F: Send + 'static,
| ^^^^ required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
We get the same error message as before when we tried to move an Rc<T> onto another thread: the trait 'Send' is not implemented. Because Rust can't make any assumptions about raw pointers in terms of who uses them to mutate a memory location, raw pointers cannot be moved to another thread in Rust! Rust models this by not implementing the Send trait for raw pointers. Curiously enough, the Rust language also prevents const pointers from being send to other threads, because we can still obtain a const pointer from a variable that is mut.
Notice how we never explicitly said that anything implements Send or not? Send is a marker trait, meaning that it has no methods, and is implemented automatically by the Rust compiler for suitable types! All primitive types and all composite types made up only of primitive types or other composite types automatically implement Send, but as soon as a type has a raw pointer as one of its fields, the whole type is no longer Send. Which explains why Rc<T> is not Send: It contains a raw pointer to the control block internally!
There is a second related trait called Sync, which is basically the stronger version of Send. Where Send states that it is safe to move a type from one thread onto another, Sync states that it is safe to access the same variable from multiple threads at the same time. There is a simple rule that relates Sync to Send: Whenever &T implements Send, T implements Sync! Let's think about this for a moment to understand why this rule exists: If we can send a borrow of T to another thread, the other thread can dereference that borrow to obtain a T, thus accessing the value of T. Since the borrow must come from outside the thread, we have at least two threads that can potentially access the same value of T. Thus the rule must hold.
Things that are not Send and Sync, and how to deal with them
We saw that Rc<T> was neither Send nor Sync. To make matters worse, the Cell<T> and RefCell<T> types also are not Sync, so even if Rc<T> were Send, we still couldn't use Rc<T> in any reasonable way in a multithreaded program, because we need Cell<T>/RefCell<T> to get mutable access to the underlying data. The reason why neither Cell<T> nor RefCell<T> are Sync is similar to the reason for Rc<T> not being Send: Both Cell<T> and RefCell<T> enable shared mutable state (through the concept of interior mutability), so accessing a value of one of these types from multiple threads simultaneously could lead to race conditions.
The problem that we face in all of these situations is not so much that we have shared mutable state, but that the order in which we might access this state from multiple threads is generally undefined. What we want is a way to synchronize accesses to the shared mutable state, to guarantee that we never get a data race! To make this possible, we can either ask the operating system for help, or use special CPU instructions that can never result in race conditions. The operating system provides us so-called synchronization primitives, the special CPU instructions are called atomic instructions.
Atomicity
Data races can happen because one thread might interrupt another thread in the middle of a computation, which might result in one thread seeing data in an incomplete state. This can happen because many interesting operations that we might perform in a program are not atomic. An atomic operation is any operation that can't be interrupted. What exactly this means depends heavily on context. In computer science, we find atomic operations in different domains, such as concurrent programming (what we are talking about right now) or databases.
A common example to illustrate the concept of atomic operations is addition. Let's look at a very simple line of code:
val += 1;
Assuming that val is an i32 value less than its maximum value, this single line of code adds 1 to val. This might look like an atomic operation, but it turns out that it typically isn't. Here is the assembly code for this line of codeCompiled with the clang compiler, version 13.0.0 for x86-64. Other compilers might give different results. On x86-64, the add instruction can add a value directly to a memory address, but it can't add the values of two memory addresses for example.:
mov eax, dword ptr [rbp - 8]
add eax, 1
mov dword ptr [rbp - 8], eax
Our single line of code resulted in three instructions! To add 1 to val, we first load the value of val into the register eax, then add 1 to the register value, then store the value of eax back into the memory address of val. It becomes clear that there are several points during this computation where another thread might interrupt this computation and either read or write a wrong value.
Exercise 7.1: Assume that two threads execute the three assembly instructions above on the same memory location in parallel on two processor cores. What are the possible values in the memory address [rbp - 8] after both threads have finished the computation?
As far as modern processors are concerned, looking at the assembly code is only half of the truth. As we saw, there are different memory caches, and a read/write operation might hit a cache instead of main memory. So even if our line of code resulted in a single instruction, we still couldn't be sure that multiple threads see the correct results, because we don't know how the caches behave.
Luckily, most CPU instruction sets provide dedicated atomic operations for things like addition, subtraction, or comparing two values. Even better, both C++ (since C++11) and Rust provide special types in their respective standard libraries that give us access to these atomic instructions without writing raw assembly code. In C++, this might look something like this:
#include <atomic>
int main() {
std::atomic<int> val{42};
val.fetch_add(1);
return val;
}
The relevant method is fetch_add, which will translate to the following assembly instruction:
lock xadd DWORD PTR [rax], edx
Here, the lock keyword makes sure that the operation executes atomically, making sure that it can never get interrupted by another thread, and no thread ever sees an intermediate result.
The corresponding Rust code is pretty similar:
use std::sync::atomic::{AtomicI32, Ordering}; pub fn main() { let val = AtomicI32::new(42); val.fetch_add(1, Ordering::SeqCst); println!("{}", val.load(Ordering::SeqCst)); }
The only difference is that fetch_add expects an Ordering as the second parameter. This Ordering defines how exactly memory accesses are synchronized when using atomic operations. The details are quite complicated, and even the Rust documentation just refers to the memory model of C++, going as far as to state that this memory model '[is] known to have several flaws' and 'trying to fully explain [it] [...] is fairly hopeless'. The only thing we have to know here is that Ordering::SeqCst (which stands for sequentially consistent) is the strongest synchronization guarantee that there is and makes sure that everyone always sees the correct results. Other memory orderings might give better performance while at the same time not giving correct results in all circumstances.
There is one little fact that might seem very weird with our current understanding of Rust. Notice how the val variable is declared as immutable (let val), but we can still modify it using fetch_add? Indeed, the signature of fetch_add accepts an immutable borrow to self: pub fn fetch_add(&self, val: i32, order: Ordering) -> i32. This is an interesting but necessary side-effect of atomicity. The Rust borrow checking rules and their distinction between immutable and mutable borrows are there to prevent mutating data while someone else might read the data, but for atomic operations this distinction is irrelevant: When an operation is atomic, no one will ever see an inconsistent state, so it is safe to mutate such a value through an immutable borrow!
Synchronization through locks
If we look at the atomic types that Rust offers, we see that only integer types (including bool and pointers) are supported for atomic operations. What can we do if we have a larger computation that we need to be performed atomically? Here, we can use tools that the operating system provides for us and use locking primitives. Arguably the most common locking primitive is the mutex, which stands for 'MUTual EXclusion'. A mutex works like a lock in the real world. The lock can either be unlocked, in which case whatever it protects can be accessed, or it can be locked, preventing all access to whatever it protects. Instead of protecting real objects, a mutex protects a region of code, making sure that only a single thread can execute this region of code at any time. This works by locking the mutex at the beginning of the critical piece of code (sometimes called a critical section) and unlocking it only after all relevant instructions have been executed. When another thread tries to enter the same piece of code, it tries to lock the mutex, but since the mutex is already locked, the new thread has to wait until the mutex is unlocked by the other thread. The implementation of the mutex is given to us by the operating system, and both C++ and Rust have a mutex type in their respective standard libraries. Here is an example of the usage of a mutex type in C++:
std::mutex mutex;
mutex.lock(); //<-- Acquire the lock
/**
* All code in here is protected by the mutex
* Only one thread at a time can execute this code!
*/
mutex.unlock(); //<-- Release the lock
Let's look at the Mutex type in Rust. Since we only need synchronization when we have shared state, the Mutex is a generic type that wraps another type, providing mutually exclusive access to the value of this wrapped type. So compared to the C++ std::mutex, the Rust Mutex type always protects data, but we can use this to also protect regions of code by extension. We get access to the data by calling the lock method on the Mutex, which returns a special type called MutexGuard. This type serves two purposes: First, it gives us access to the underlying data protected by the Mutex. A MutexGuard<T> implements both Deref and DerefMut for T. Second, MutexGuard is an RAII type that makes sure that we don't forget to unlock the Mutex. When MutexGuard goes out of scope, it automatically unlocks its associated Mutex. Notice that a mutex is just like any other resource (e.g. memory, files) and thus has acquire/release semantics.
Here is a bit of code that illustrates how a Mutex never allows accessing its protected data from more than one location at the same time:
use std::sync::Mutex; fn main() { let val = Mutex::new(42); { let mut locked_val = val.lock().unwrap(); *locked_val += 1; val.lock().unwrap(); println!("We never get here..."); } }
The first call to lock locks the Mutex, returning the MutexGuard object that we can use to modify the data. The second call to lock will block, because the Mutex is still locked. In this case, we created what is known as a deadlock: Our program is stuck in an endless waiting state because the second lock operation blocks until the Mutex gets unlocked, which can only happen after the second lock operation.
Does Mutex remind you of something? Its behaviour is very similar to that of RefCell! Both types prevent more than one (mutable) borrow to the same piece of data at the same time at runtime! Mutex is just a little bit more powerful than RefCell, because Mutex works with multiple threads!
Let's try to use Mutex in a multithreaded program:
use std::sync::Mutex; fn main() { let val = Mutex::new(42); let join_handle = std::thread::spawn(move || { let mut data = val.lock().unwrap(); *data += 1; }); { let data = val.lock().unwrap(); println!("From main thread: {}", *data); } join_handle.join().unwrap(); }
Unfortunately, this doesn't compile:
error[E0382]: borrow of moved value: `val`
--> src/bin/send_sync.rs:11:20
|
4 | let val = Mutex::new(42);
| --- move occurs because `val` has type `Mutex<i32>`, which does not implement the `Copy` trait
5 | let join_handle = std::thread::spawn(move || {
| ------- value moved into closure here
6 | let mut data = val.lock().unwrap();
| --- variable moved due to use in closure
...
11 | let data = val.lock().unwrap();
| ^^^^^^^^^^ value borrowed here after move
For more information about this error, try `rustc --explain E0382`.
Of course, we have to move data onto the thread, and this moves our val variable so that we can't access it anymore from the main thread. Our first instinct might be to move a borrow of val onto the thread, however we already know that this won't work because spawn requires all borrows to have 'static lifetime, because the thread might life longer than the function which called spawn. Realize what this implies: Both the main thread as well as our new thread have to own the Mutex! So our Mutex requires multiple ownership! So let's put the Mutex inside an Rc!
...except this also doesn't work, because we already saw that Rc does not implement Send! Rc has this shared reference count that might get mutated from multiple threads at the same time, and of course this isn't safe. But wait! Recall that the reference count is just an integer? We know a type that let's us safely manipulate an integer from multiple threads at the same time: AtomicI32 (or better yet, AtomicUsize). If we were to write an Rc implementation using atomic integers in the control block, then it would be safe to send an Rc to another thread!
Rust has got us covered. Enter Arc<T>! Where Rc stood for 'reference-counted', Arc stands for 'atomically reference-counted'! How cool is that? By wrapping our Mutex inside an Arc, we can safely have multiple threads that own the same Mutex:
use std::{ sync::{Arc, Mutex}, }; fn main() { let val = Arc::new(Mutex::new(42)); let val_clone = val.clone(); let join_handle = std::thread::spawn(move || { let mut data = val_clone.lock().unwrap(); *data += 1; }); { let data = val.lock().unwrap(); println!("From main thread: {}", *data); } join_handle.join().unwrap(); }
Arc works very much the same as Rc, so we already know how to use it! There is one small caveat when using Arc with std::thread::spawn: Since we have to move values into the closure but also want to use our val variable after the thread has been spawned, we have to create a second variable val_clone that contains a clone of the Arc before calling std::thread::spawn. The sole purpose of this variable is to be moved into the closure, so it might look a bit confusing in the code.
A closing note on the usage of Mutex: The code above is still not strictly deterministic, because we don't know which thread will acquire the lock first (the main thread or the spawned thread), so the println! statement might either print a value of 42 or 43. This seems like a critical flaw of Mutex, but instead it is simply an artifact of the way we wrote our code. Using a Mutex does not establish any order between threads, it only guarantees that the resource protected by the Mutex can never be accessed by two threads at the same time. The discussion of ordering of concurrent operations is beyond the scope of this course, but it is an interesting one, as many concurrent algorithms don't care all that much about the order of operations. In fact, this is one of the fundamental properties of concurrent programming: The fact that operations can run in parallel often means that we give up on knowing (or caring about) the explicit ordering of operations.
Our DNA editing algorithm using Arc and Mutex
We can now replace our usage of Rc<RefCell<...>> in our previous attempt to parallelize the DNA editing algorithm with Arc<Mutex<...>>:
#![allow(unused)] fn main() { fn dna_editing_parallel( mut source: Vec<Nucleobase>, old_sequence: Vec<Nucleobase>, new_sequence: Vec<Nucleobase>, parallelism: usize, ) -> Vec<Nucleobase> { let source = Arc::new(Mutex::new(source)); let join_handles = (0..parallelism) .into_iter() .map(|chunk_index| { let source_clone = source.clone(); let old_sequence = old_sequence.clone(); let new_sequence = new_sequence.clone(); std::thread::spawn(move || { let mut source = source_clone.lock().unwrap(); let sequence_start = chunk_size * chunk_index; let sequence_end = if chunk_index == parallelism - 1 { source.len() } else { (chunk_index + 1) * chunk_size }; dna_editing_sequential( &mut source[sequence_start..sequence_end], old_sequence.as_slice(), new_sequence.as_slice(), ) }) }) .collect::<Vec<_>>(); join_handles .into_iter() .for_each(|handle| handle.join().expect("Can't join with worker thread")); let mutex = Arc::try_unwrap(source).unwrap(); mutex.into_inner().unwrap() } }
With the Arc<Mutex<...>> pattern, we can then access the source vector from inside the thread functions and pass the appropriate range of elements to the dna_editing_sequential implementation. If we compile this, we get zero errors, and the program runs without any crashes! Is all well then? Did we write a correct, high-performance program in Rust?
Unfortunately, there are two major problems with our code, that stem from our lack of understanding of concurrent programming patterns at the moment. One is a correctness problem, the other a performance problem. The correctness problem arises because we split our DNA sequence into chunks and process each chunk concurrently on its own thread. But what if the pattern we are looking for spans two chunks? Then, neither thread will recognize the whole pattern, because it has only part of the data available:
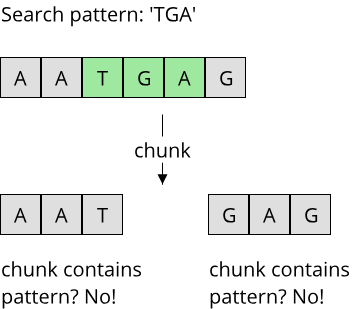
This is a fundamental problem of the way we structured our algorithm, and it is not easy to fix unfortunately. We could try to add a second phase to the algorithm that only checks the chunk borders for occurrences of the search pattern, but then we would have to make sure that our initial replacement of the pattern didn't yield new occurrences of the pattern in the edited DNA sequence. Even if we were to fix this issue, there is still the performance problem! Notice how each thread tries to lock the Mutex immediately after it starts running, and only releases the Mutex once it is finished? This means that there will never be two threads doing useful work at the same time, because the Mutex prevents this! So we effectively wrote a sequential algorithm using multiple threads and poor usage of a Mutex. This is not uncommon if we try to naively port a sequential algorithm to multiple threads.
Unfortunately, this chapter has to end with this disappointing realization: Our implementation is neither correct nor fast. Even with all the safety mechanisms that Rust provides for us, we still require knowledge of concurrent programming to come up with efficient and correct implementations. A more practical discussion of concurrent programming thus will have to wait until the next chapter.
Conclusion
In this chapter, we learned about the fundamental concepts for executing code concurrently in Rust. Threads are the main building blocks for running code concurrently within a single process. Since concurrent accesses to the same memory locations can result in race conditions, Rust provides the two traits Send and Sync to assure that concurrent accesses stay safe. We saw some caveats to using threads in Rust when it comes to lifetimes, namely that the default threads that the Rust standard library provides requires 'static lifetime for all borrows used from a thread. To circumvent these problems, we saw how we can use synchronization primitives such as the Mutex, together with thread-safe smart pointers (Arc) to make concurrent resource accesses from multiple threads safe.
While this chapter layed the groundwork of understanding concurrent programming in Rust, in reality these low-level concepts can be hard to use and several crates are utilized instead which provide easier mechanisms for concurrent programming. In the next chapter, we will therefore look at applied concurrent programming in Rust.