What is performance, and how do we know that we have it?
Let's start our journey towards the mythical lands of high performance code. Instead of venturing into the unknown, let's take a moment to first understand what it is that we are actually aiming for. What is performance, in the context of (systems) software? Here is a definition of the term "performance" by The Free Dictionary:
"performance: The way in which someone or something functions"
This helps only a little. Clearly, performance is related to how a piece of software functions, but this definition is too broad. A better definition can be found in 'Model-based software performance analysis' by Cortellessa et al. {{#cite cortellessa2011model}}, where they talk about "[t]he quantitative behavior of a software system". Quantitative in this context means that there are numbers that we can associate with software performance. You might have an intuitive sense of what 'software performance' means, something along the lines of 'How fast does my program run?', and this definition fits with that intuition. Indeed, runtime performance is one aspect of software performance in general, and it can be expressed through numbers such as wall clock time - a fancy term for the time that a piece of software or code takes to execute.
Understanding performance through metrics
'How fast does my program run?' is a good question to ask, and it might prompt us to ask other similar questions, such as:
- 'How much memory does my program allocate?'
- 'How quickly does my program respond to user input?'
- 'How much data can my program read or write in a given amount of time?'
- 'How large is the executable for my program?'
Notice that all these questions are intimately tied to the usage of hardware resources! This is why software performance is especially important in the domain of systems programming: Systems software tries to make efficient use of hardware resources, and we can only know that our software achieves this goal if we have tangible evidence in the form of numbers for resource usage. We call such numbers metrics.
For all of the previous questions, we thus are looking for one or more metrics that we can measure in our software so that we can answer these questions:
- 'How much memory does my program allocate?' can be answered by measuring the memory footprint
- 'How quickly does my program respond to user input?' can be answered by measuring the response time of the software (which can be fairly complex to measure)
- 'How much data can my program read or write in a given amount of time?' can be answered by measuring the I/O throughput
- 'How large is the executable for my program?' is almost a metric in and of itself, and can be measured using the file size of the executable
These are only a few high-level concepts for assessing software performance, in reality there are tons of different metrics for various aspects of software performance and hardware resource usage. Here are a bunch of fancy metrics that you might track from your operating system and CPU:
- Branch misprediction rate
- L1 cache miss rate
- Page miss rate
- Number of instructions executed
- Number of context switches
We'll look at some of these metrics in the next chapter, where we will learn how to track metrics during execution of a piece of software.
Qualitative assessment of performance
For now, let us first try to understand what we gain from the quantitative analysis of software performance. Ultimately, we end up with a bunch of numbers that describe how a piece of software performs. By itself, these numbers are meaningless. "Running software A takes 7 minutes" is a statement without much usage due to a lack of context. If this software calculates 2+3, then 7 minutes seems like an unreasonably long time, if this software computes an earth-sized climate model with 10 meter resolution, 7 minutes would be a miracle. We thus see that performance metrics are often tied to some prior assumption about their expected values. Labels such as 'good performance' and 'bad performance' are qualitative in their nature and are ultimately the reason why we gather metrics in the first place.
To assess software performance, we thus have to compare metrics to some prior values. These can either be taken from experience ('adding numbers is fast, computing climate models is slow') or they can be previous versions of the same metric, obtained from a previous evaluation of software performance. The first kind of assessment is typically goal-driven, with a clear performance number in mind that implementors of the software try to reach. Examples include a target framerate in a video game, a target response time for a web application, or a target size for an executable so that it can fit on some embedded device. The second kind of assessment is often used to ensure that performance did not deteriorate after changes in the software, or to illustrate improvements in the software. The statement "The new version of our software now runs 3 times faster than the old version" is an example for the second kind of performance assessment.
Software performance assessment seldom is a singular process. In reality, it often induces a feedback-loop, where you collect your metrics for a certain piece of code, apply some changes, collect metrics again, compare the metrics to gain insight, and apply more code changes.
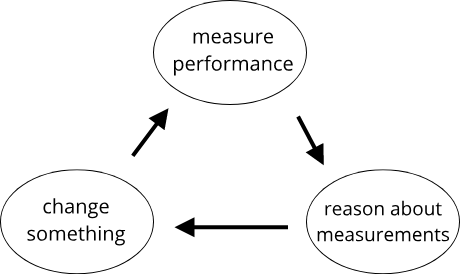
By gathering performance metrics repeatedly, for example as part of a build pipeline, your application's performance becomes a first-class citizen and can be tracked just as one typically does with unit tests or coding guidelines. The Rust compiler rustc tracks the results of various performance benchmarks with each commit to the main branch in the rust repository. The data can then be viewed in graph-form here.
Why should we care about performance?
Performance as a property can range from being a key functional requirement to a marginal note in the software development process. Real-time systems care most about performance, as they require a piece of code to execute in a given timeframe. On the opposite end of the spectrum one can find custom data analysis routines which are rarely executed but give tremendous insight into data. Here, the importance of performance is low: Why spend three hours optimizing a script that only runs for 15 minutes?. Most software falls somewhere inbetween, where the potential benefits of performance optimization have to be judged on a case-by-case basis. Here are some reasons why you might care about the performance of your software:
- Performance is a functional requirement (e.g. your software has to process X amount of data in Y seconds/minutes/hours)
- Performance is relevant to the user experience (e.g. your software needs to 'feel smooth/quick/snappy/responsive')
- Energy consumption is a concern (e.g. your software shouldn't drain the battery unnecessarily fast)
- Money is a concern (e.g. because your software runs on rented virtual machines in the cloud which are billed by CPU hours)
The last two points in particular are becoming more relevant as more software is run in the cloud and global energy usage for computers becomes an issue.
Exercise 8.1 Identify one piece of software that would benefit from better performance for each of the reasons stated above.